The doc about DDL statements claims that an `ALTER KEYSPACE` will fail
in the presence of an ongoing global topology operation.
This limitation was specifically referring to RF changes, which Scylla
implements as global topology requests (`keyspace_rf_change`), and it
was true when it was first introduced (1b913dd880) because there was
no global topology request queue at that time, so only one ongoing
global request was allowed in the cluster.
This limitation was lifted with the introduction of the global topology
request queue (6489308ebc), and it was re-introduced again very
recently (2e7ba1f8ce) in a slightly different form; it now applies only
to RF changes (not to any request type) and only those that affect the
same keyspace. None of these two changes were ever reflected in the doc.
Synchronize the doc with the current state.
Fixes#27776.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
Closesscylladb/scylladb#27786
Currently some things are not supported for colocated tables: it's not
possible to repair a colocated table, and due to this it's also not
possible to use the tombstone_gc=repair mode on a colocated table.
Extend the documentation to explain what colocated tables are and
document these restrictions.
Fixesscylladb/scylladb#27261Closesscylladb/scylladb#27516
The PRUNE MATERALIZED VIEW statement is performed as follows:
1. Perform a range scan of the view table from the view replicas based
on the ranges specified in the statement.
2. While reading the paged scan above, for each view row perform a read
from all base replicas at the corresponding primary key. If a discrepancy
is detected, delete the row in the view table.
When reading multiple rows, this is very slow because for each view row
we need to performe a single row query on multiple replicas.
In this patch we add an option to speed this up by performing many of the
single base row reads concurrently, at the concurrency specified in the
USING CONCURRENCY clause.
Aside from the unit test, I checked manually on a 3-node cluster with 10M rows, using vnodes. There were actually no ghost rows in the test, but we still had to iterate over all view rows and read the corresponding base rows. And actual ghost rows, if there are any, should be a tiny fraction of all rows. I compared concurrencies 1,2,10,100 and the results were:
* Pruning with concurrency 1 took total 1416 seconds
* Pruning with concurrency 2 took total 731 seconds
* Pruning with concurrency 10 took total 234 seconds
* Pruning with concurrency 100 took total 171 seconds
So after a concurrency of 10 or so we're hitting diminishing returns (at least in this setup). At that point we may be no longer bottlenecked by the reads, but by CPU on the shard that's handling the PRUNE
Fixes https://github.com/scylladb/scylladb/issues/27070Closesscylladb/scylladb#27097
* github.com:scylladb/scylladb:
mv: allow setting concurrency in PRUNE MATERIALIZED VIEW
cql: add CONCURRENCY to the USING clause
The PRUNE MATERALIZED VIEW statement is performed as follows:
1. Perform a range scan of the view table from the view replicas based
on the ranges specified in the statement.
2. While reading the paged scan above, for each view row perform a read
from all base replicas at the corresponding primary key. If a discrepancy
is detected, delete the row in the view table.
When reading multiple rows, this is very slow because for each view row
we need to performe a single row query on multiple replicas.
In this patch we add an option to speed this up by performing many of the
single base row reads concurrently, at the concurrency specified in the
USING CONCURRENCY clause.
Fixes https://github.com/scylladb/scylladb/issues/27070
This commit fixes the information about object storage:
- Object storage configuration is no longer marked as experimental.
- Redundant information has been removed from the description.
- Information related to object storage for SStabels has been removed
as the feature is not working.
Fixes https://github.com/scylladb/scylladb/issues/26985Closesscylladb/scylladb#26987
This patch adds the missing warning about the lack of possibility
to return the similarity distance. This will be added in the next
iteration.
Fixes#27086
It has to be backported to 2025.4 as this is the limitation in 2025.4.
Closesscylladb/scylladb#27096
This patch series re-enables support for speculative retry values `0` and `100`. These values have been supported some time ago, before [schema: fix issue 21825: add validation for PERCENTILE values in speculative_retry configuration. #21879
](https://github.com/scylladb/scylladb/pull/21879). When that PR prevented using invalid `101PERCENTILE` values, valid `100PERCENTILE` and `0PERCENTILE` value were prevented too.
Reproduction steps from [[Bug]: drop schema and all tables after apply speculative_retry = '99.99PERCENTILE' #26369](https://github.com/scylladb/scylladb/issues/26369) are unable to reproduce the issue after the fix. A test is added to make sure the inclusive border values `0` and `100` are supported.
Documentation is updated to give more information to the users. It now states that these border values are inclusive, and also that the precision, with automatic rounding, is 1 decimal digit.
Fixes#26369
This is a bug fix. If at any time a client tries to use value >= 99.5 and < 100, the raft error will happen. Backport is needed. The code which introduced inconsistency is introduced in 2025.2, so no backporting to 2025.1.
Closesscylladb/scylladb#26909
* github.com:scylladb/scylladb:
test: cqlpy: add test case for non-numeric PERCENTILE value
schema: speculative_retry: update exception type for sstring ops
docs: cql: ddl.rst: update speculative-retry-options
test: cqlpy: add test for valid speculative_retry values
schema: speculative_retry: allow 0 and 100 PERCENTILE values
Clarify how the value of `XPERCENTILE` is handled:
- Values 0 and 100 are supported
- The percentile value is rounded to the nearest 0.1 (1 decimal place)
Refs #26369
Auto-exands numeric RF in CREATE/ALTER KEYSPACE statements for
new DCs specified in the statement.
Doesn't auto-expand existing options, as the rack choice may not be in
line with current replica placement. This requires co-locating tablet
replicas, and tracking of co-location state, which is not implemented yet.
Signed-off-by: Tomasz Grabiec <tgrabiec@scylladb.com>
We want to add strongly consistent tables as an option. We will have
two kind of strongly consistent tables: globally consistent and locally
consistent. The former means that requests from all DCs will be globally
linearisable while the later - only requests to the same DCs will be
linearisable. To allow configuring all the possibilities the patch
adds new parameter to a keyspace definition "consistency" that can be
configured to be `eventual`, `global` or `local`. Non eventual setting
is supported for tablets enabled keyspaces only. Since we want to start
with implementing local consistency configuring global consistency will
result in an error for now.
This patch adds the missing documentation for the SELECT ... ANN
statement that allows performing vector queries. This is just the
basic explanation of the grammar and how to use it. More
comprehensive documentation about vector search will be added
separately in Scylla Cloud documentation and features description.
Links to this additional documentation will be added as part of
VECTOR-244.
Fixes: VECTOR-247.
This patch adds CQL documentation about creating vector search
indexes. It includes the syntax and description of parameters.
It does not cover VECTOR type that is already supported and
documented and it does not cover querying vectors which will be
covered by a separate PR.
Fixes: VECTOR-217
Closesscylladb/scylladb#26233
This patch updates the create keyspace statement docs. It explains how
the `replication` option in the create keyspace statement is now optional,
and behaves the same as if we specified an empty set as following:
`WITH replication = {}`.
An example with no `replication` option specified has also been added.
Refs #25145
Update create-keyspace-statement section of ddl.rst since replication factor is no longer mandatory.
Add an example for keyspace creation without specifying replication factor.
Add an example for keyspace creation without specifying both `class` and replication factor.
Refs: #16028
Update create-keyspace-statement section of ddl.rst since `class` is no longer mandatory.
Add an example for keyspace creation without specifying `class`.
Refs: #16029
ScyllaDB supports non-frozen UDTs since 3.2, no need to keep referencing
this limitation in the current docs. Replace the description of the
limitation with general description of frozen semantics for UDTs.
Fixes: #22929Closesscylladb/scylladb#24763
This commit removes the Non-Reserved CQL Keywords and Reserved CQL Keywords pages-keyword
as that content is already covered on the Appendices page.
Redirections are added to avoid 404s for the removed pages.
In addition, the Appendices page title is extended with "Reserved CQL Keywords and Types"
to help users understand what those appendices are about.
Fixes https://github.com/scylladb/scylladb/issues/24319Closesscylladb/scylladb#24320
This commit increases the maximum length of names for keyspaces, tables, materialized views, and indexes from 48 to 192 bytes.
The previous 48-bytes limit was inherited from Cassandra 3 for compatibility. However, this validation was removed in Cassandra 4 and 5 (see CASSANDRA-20389)
and some usage scenarios (such as some feature store workflows generating long table names) now depend on this relaxed constraint.
This change brings ScyllaDB's behavior in line with modern Cassandra versions and better supports these use cases.
The new limit of 192 bytes is derived from underlying filesystem limitations to prevent runtime errors when creating directories for table data.
When a new table is created, ScyllaDB generates a directory for its SSTables. The directory name is constructed from the table name, a dash, and a 32-character UUID.
For a CDC-enabled table, an associated log table is also created, which has the suffix `_scylla_cdc_log` appended to its name.
The directory name for this log table becomes the longest possible representation.
Additionally we reserve 15 bytes for future use, allowing for potential future extensions without breaking existing schemas.
To guarantee that directory creation never fails due to exceeding filesystem name limits, the maximum name length is calculated as follows:
255 bytes (common filesystem limit for a path component)
- 32 bytes (for the 32-character UUID string)
- 1 byte (for the '-' separator)
- 15 bytes (for the '_scylla_cdc_log' suffix)
- 15 bytes (reserved for future use)
----------
= 192 bytes (Maximum allowed name length)
This calculation is similar in principle to the one proposed for Cassandra to fix related directory creation failures (see apache/cassandra/pull/4038).
This patch also updates/adds all associated tests to validate the new 192-byte limit.
The documentation has been updated accordingly.
There is a difference how ScyllaDB and Cassandra handle conditional
batches with different IF statements (such as "IF EXISTS" and "IF NOT
EXISTS").
This commit explicitly documents the differences in the behavior.
Refs: #13011
Current protocol extension that sends tablet info to drivers only does
that if the driver selects a non-replica coordinator for a routable
request. It works well if some node on the replica list is replaced by
other node, or if some replicas are removed from the list. Driver will
at some point send a request to stale replica, and receive new list in
response.
The issue is with extending the list with new replicas. In that case old
replicas are all still correct, so driver will not select any wrong
replica, and will not receive the new list. As far as I know that only
scenario where this could happen is RF increase.
It could be to some degree worked around in the drivers, but it would
add significant complexity (definitely more than any other invalidations
we introduced) while still not being ideal solution. This scenario
should be rare enough, and the consequences of not handling it minor
enough (new replicas not being used as coordinators) that it does not
warrant driver-side solution. Instead this commit adds info about this
to documentation, advising users to restart applications after replica
lists are extended.
It is worth noting that if new tablet feedback protocol extension is
implemented then this problem goes away. See issue #21664.
Closesscylladb/scylladb#23447
We introduce a new term in the glossary: RF-rack-valid keyspace.
We also highlight in our user documentation that all keyspaces
must remain RF-rack-valid throughout their lifetime, and failing
to guarantee that may result in data inconsistencies or other
issues. We base that information on our experience with materialized
views in keyspaces using tablets, even though they remain
an experimental feature.
Along with the new term, we introduce a new configuration option
called `rf_rack_valid_keyspaces`, which, when enabled, will enforce
preserving all keyspaces RF-rack-valid. That functionality will be
implemented in upcoming commits. For now, we materialize the
restriction in form of a named requirement: a function verifying
that the passed keyspace is RF-rack-valid.
The option is disabled by default. That will change once we adjust
the existing tests to the new semantics. Once that is done, the option
will first be enabled by default, and then it will be removed.
Fixesscylladb/scylladb#20356
Before this patch we silently allowed and ignored PER PARTITION LIMIT.
While using aggregate functions in conjunction with PER PARTITION LIMIT
can make sense, we want to disable it until we can offer proper
implementation, see #9879 for discussion.
We want to match Cassandra, and for queries with aggregate functions it
behaves as follows:
- it silently ignores PER PARTITION LIMIT if GROUP BY is present, which
matches our previous implementation.
- rejects PER PARTITION LIMIT when GROUP BY is *not* present.
This patch adds rejection of the second group.
Fixes#9879Closesscylladb/scylladb#23086
This commit adds a link to the Limitations section on the Tablets page
to the CQL pag, the tablets option.
This is actually the place where the user will need the information:
when creating a keyspace.
In addition, I've reorganized the section for better readability
(otherwise, the section about limitations was easy to miss)
and moved the section up on the page.
Note that I've removed the updated content from the `_common` folder
(which I deleted) to the .rst page - we no longer split OSS and Enterprise,
so there's no need to keep using the `scylladb_include_flag` directive
to include OSS- and Ent-specific content.
Fixes https://github.com/scylladb/scylladb/issues/22892
Fixes https://github.com/scylladb/scylladb/issues/22940Closesscylladb/scylladb#22939
This series extends the table schema with per-table tablet options.
The options are used as hints for initial tablet allocation on table creation and later for resize (split or merge) decisions,
when the table size changes.
* New feature, no backport required
Closesscylladb/scylladb#22090
* github.com:scylladb/scylladb:
tablets: resize_decision: get rid of initial_decision
tablet_allocator: consider tablet options for resize decision
tablet_allocator: load_balancer: table_size_desc: keep target_tablet_size as member
network_topology_strategy: allocate_tablets_for_new_table: consider tablet options
network_topology_strategy: calculate_initial_tablets_from_topology: precalculate shards per dc using for_each_token_owner
network_topology_strategy: calculate_initial_tablets_from_topology: set default rf to 0
cql3: data_dictionary: format keyspace_metadata: print "enabled":true when initial_tablets=0
cql3/create_keyspace_statement: add deprecation warning for initial tablets
test: cqlpy: test_tablets: add tests for per-table tablet options
schema: add per-table tablet options
feature_service: add TABLET_OPTIONS cluster schema feature
This pull request is an implementation of vector data type similar to one used by Apache Cassandra.
The patch contains:
- implementation of vector_type_impl class
- necessary functionalities similar to other data types
- support for serialization and deserialization of vectors
- support for Lua and JSON format
- valid CQL syntax for `vector<>` type
- `type_parser` support for vectors
- expression adjustments such as:
- add `collection_constructor::style_type::vector`
- rename `collection_constructor::style_type::list` to `collection_constructor::style_type::list_or_vector`
- vector type encoding (for drivers)
- unit tests
- cassandra compatibility tests
- necessary documentation
Co-authored-by: @janpiotrlakomy
Fixes https://github.com/scylladb/scylladb/issues/19455Closesscylladb/scylladb#22488
* github.com:scylladb/scylladb:
docs: add vector type documentation
cassandra_tests: translate tests covering the vector type
type_codec: add vector type encoding
boost/expr_test: add vector expression tests
expression: adjust collection constructor list style
expression: add vector style type
test/boost: add vector type cql_env boost tests
test/boost: add vector type_parser tests
type_parser: support vector type
cql3: add vector type syntax
types: implement vector_type_impl
Use the keyspace initial_tablets for min_tablet_count, if the latter
isn't set, then take the maximum of the option-based tablet counts:
- min_tablet_count
- and expected_data_size_in_gb / target_tablet_size
- min_per_shard_tablet_count (via
calculate_initial_tablets_from_topology)
If none of the hints produce a positive tablet_count,
fall back to calculate_initial_tablets_from_topology * initial_scale.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Per-table hints should be used instead.
Note: the warning is produced by check_against_restricted_replication_strategies
which is called also from alter_keyspace_statement.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Unlike with vnodes, each tablet is served only by a single
shard, and it is associated with a memtable that, when
flushed, it creates sstables which token-range is confined
to the tablet owning them.
On one hand, this allows for far better agility and elasticity
since migration of tablets between nodes or shards does not
require rewriting most if not all of the sstables, as required
with vnodes (at the cleanup phase).
Having too few tablets might limit performance due not
being served by all shards or by imbalance between shards
caused by quantization. The number of tabelts per table has to be
a power of 2 with the current design, and when divided by the
number of shards, some shards will serve N tablets, while others
may serve N+1, and when N is small N+1/N may be significantly
larger than 1. For example, with N=1, some shards will serve
2 tablet replicas and some will serve only 1, causing an imbalance
of 100%.
Now, simply allocating a lot more tablets for each table may
theoretically address this problem, but practically:
a. Each tablet has memory overhead and having too many tablets
in the system with many tables and many tablets for each of them
may overwhelm the system's and cause out-of-memory errors.
b. Too-small tablets cause a proliferation of small sstables
that are less efficient to acces, have higher metadata overhead
(due to per-sstable overhead), and might exhaust the system's
open file-descriptors limitations.
The options introduced in this change can help the user tune
the system in two ways:
1. Sizing the table to prevent unnecessary tablet splits
and migrations. This can be done when the table is created,
or later on, using ALTER TABLE.
2. Controlling min_per_shard_tablet_count to improve
tablet balancing, for hot tables.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Add missing vector type documentation including: definition of vector,
adjustment of term definition, JSON encoding, Lua and cql3 type
mapping, vector dimension limit, and keyword specification.
Add a paragraph documenting the decision to deprecate
the COMPACT STORAGE feature, and instruct the user
how to enable the feature despite that.
Note that we don't have an official migration strategy
for users like `DROP COMPACT STORAGE`, which is not
implemented at this time (See #3882).
Fixes#16375
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
As part of #18750, we added a CQL statement CREATE ROLE WITH SALTED HASH that prevented hashing a password when creating a role, effectively leading to inserting a hash given by the user directly into the database. In #21350, we noticed that Cassandra had implemented a CQL statement of similar semantics but different syntax. We decided to rename Scylla's statement to be compatible with Cassandra. Unfortunately, we didn't notice one more difference between what we had in Scylla and what was part of Cassandra.
Scylla's statement was originally supposed to only be used when restoring the schema and the user needn't have to be aware of its existence at all: the database produced a sequence of CQL statements that the user saved to a file and when a need to restore the schema arose, they would execute the contents of the file. That's why that although we documented the feature, it was only done in the necessary places. Those that weren't related to the backup & restore procedure were deliberately skipped.
Cassandra, on the other hand, added the statement for a different purpose (for details, see the relevant issue) and it was supposed to be used by the user by design. The statement is also documented as such.
Since we want to preserve compatibility with Cassandra, we document the statement and its semantics in the user documentation, explicitly implying that it can be used by the user.
We also add a test verifying that logging in works correctly.
Fixesscylladb/scylladb#21691
Backport: not needed. The relevant code didn't make it to 6.2 or any previous version of OSS.
Closesscylladb/scylladb#21752
* github.com:scylladb/scylladb:
docs: Update documentation on CREATE ROLE WITH HASHED PASSWORD
test/boost: Add test for creating roles with hashed passwords
remove the "ScyllaDB Enterprise" labels in document. because
there is no need to differentiate ScyllaDB Enterprise from its OSS
variant, let's stop adding the "ScyllaDB Enterprise" labels to
enterprise-only features. this helps to reduce the confusion.
as we are still in the process of porting the enterprise features
to this repo, this change does not fixscylladb/scylladb#22175.
we will review the document again when completing the migration.
we also take this opportunity to stop referencing "Enterprise" in
the changed paragraph.
Refs scylladb/scylladb#22175
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22177
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
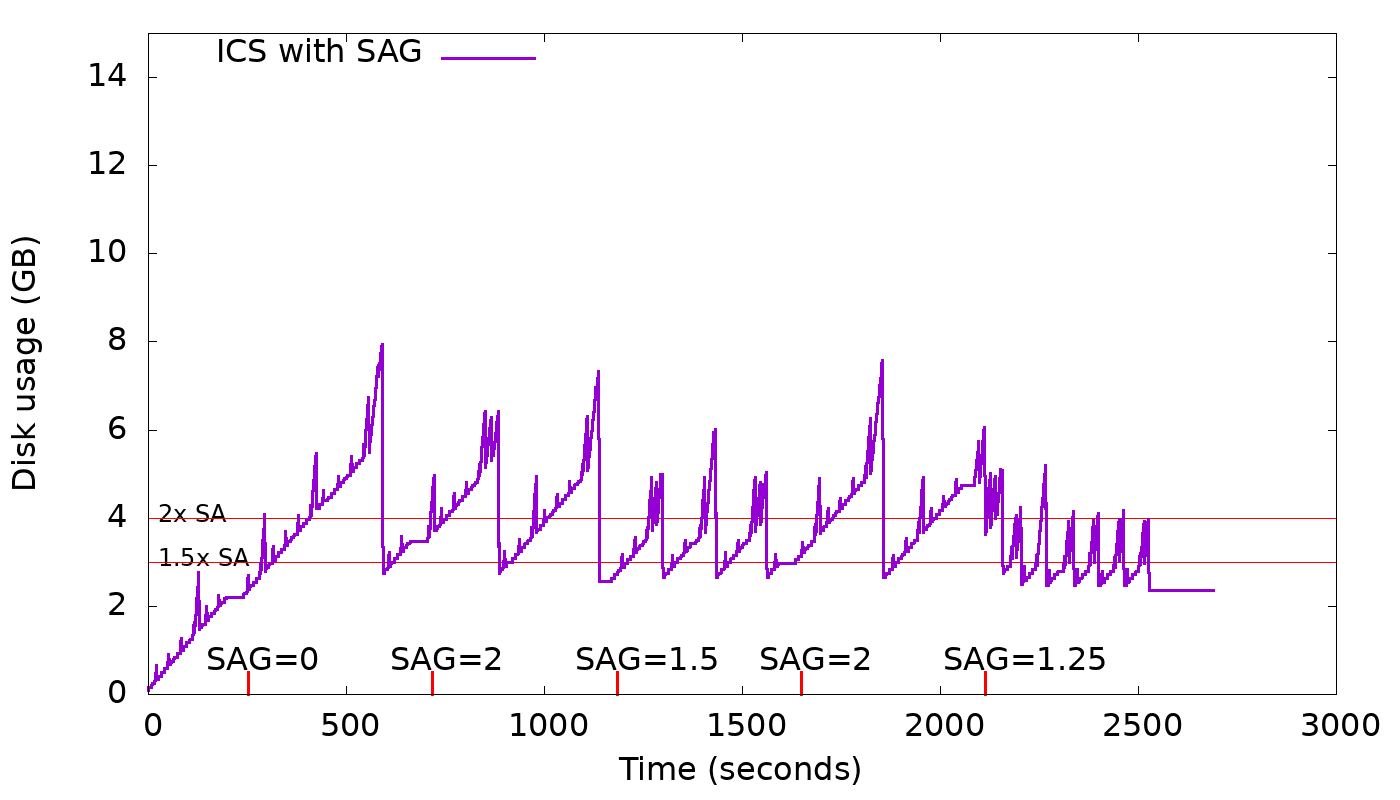
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
This adds to the grammar the option to SELECT a specific key in a
collection column using subscript syntax.
For example:
SELECT map['key'] FROM table
SELECT map['key1']['key2'] FROM table
The key can also be parameterized in a prepared query. For this we need
to pass the query options to result_set_builder where we process the
selectors.
Fixesscylladb/scylladb#7751
Where the grammar supports IN, we add NOT IN. This includes the WHERE
clause and LWT IF clause.
Evaluation of NOT IN follows from IN.
In statement_restrictions analysis, they are different, as NOT IN
doesn't enable any clever query plan and must filter.
Some tests are added. An error message was changed ('in' changed to 'IN'),
so some tests are adjusted.
Closesscylladb/scylladb#21992
As part of #18750, we added a CQL statement CREATE ROLE WITH SALTED HASH
that prevented hashing a password when creating a role, effectively leading
to inserting a hash given by the user directly into the database. In #21350,
we noticed that Cassandra had implemented a CQL statement of similar semantics
but different syntax. We decided to rename Scylla's statement to be compatible
with Cassandra. Unfortunately, we didn't notice one more difference between
what we had in Scylla and what was part of Cassandra.
Scylla's statement was originally supposed to only be used when restoring
the schema and the user needn't have to be aware of its existence at all:
the database produced a sequence of CQL statements that the user saved to
a file and when a need to restore the schema arose, they would execute
the contents of the file. That's why that although we documented the feature,
it was only done in the necessary places. Those that weren't related to
the backup & restore procedure were deliberately skipped.
Cassandra, on the other hand, added the statement for a different purpose
(for details, see the relevant issue) and it was supposed to be used by
the user by design. The statement is also documented as such.
Since we want to preserve compatibility with Cassandra, we document
the statement and its semantics in the user documentation, explicitly
implying that it can be used by the user.
Fixesscylladb/scylladb#21691
Although `crc_check_chance` is accepted as a configuration option in ScyllaDB,
the value is currently ignored during runtime. This change makes this behavior
explicit in the documentation to prevent potential user misunderstandings.
Changes:
- Explicitly document that the option is currently a no-op
- Provide clear guidance on the current implementation
- Prevent confusion about the option's actual functionality
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21794
Python and Python developers don't like directory names to include a
minus sign, like "cql-pytest". In this patch we rename test/cql-pytest
to test/cqlpy, and also change a few references in other code (e.g., code
that used test/cql-pytest/run.py) and also references to this test suite
in documentation and comments.
Arguably, the word "test" was always redundant in test/cql-pytest, and
I want to leave the "py" in test/cqlpy to emphasize that it's Python-based
tests, contrasting with test/cql which are CQL-request-only approval
tests.
Fixes#20846
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
{kind=link}