This commit prepares `auth_passwords_test` for using coroutines,
because later in this patch series `auth::passwords::check` and other
similar functions will return Seastar futures.
Refs: scylladb/scylladb#26859
Refactor the way we decide the sstable belong to a tablet, fully or partially to simplify the flow and make it more readable. Also extract the logic and make it testable, add tests to cover changes
The change is purely aesthetic, no need to backport
Closesscylladb/scylladb#27101
* github.com:scylladb/scylladb:
streaming: remove unnecessary lambda creating sstable token range
streaming: simplify get_sstables_for_tablets logic
streaming: switch to range-based for loop
streaming: drop sstable skip microoptimization in tablet loop
streaming: replace reverse iterators with reverse view in sstables scan
streaming: return from get_sstables_for_tablets earlier
streaming: add get_sstables_by_tablet_range tests
test,sstables: add helper to set sstable first and last keys
streaming: refactor get_sstables_for_tablets to make it accessible
streaming: refactor get_sstables_for_tablets to make it testable
streaming: refactor tablet_sstable_streamer::stream by extracting SST filtering logic
Add a comprehensive test suite that exercises various combinations of
SSTable containment within tablet ranges. These cases cover boundary
conditions, partial overlaps, and full containment to validate all
recent changes made to `get_sstables_by_tablet_range`.
Fixes#27366
A URL with numeric host part formats special in case of ipv6,
to avoid confusion with port part.
The parser should handle this.
I.e.
http://[2001:db8:4006:812::200e]:8080
v2:
* Include scheme agnostic parse + case insensitive scheme matching
Key goals:
- efficient (batching updates)
- reliable (no lost updates)
Will be used in data structures maintained on one designed owning
shard and replicated to other shards.
Before this patch, every expression in Alternator's requests was parsed from string to adequate structure.
This patch enables caching, where input expression strings are mapped to parsed template structures.
Every new valid (parsable) expression is added to the cache. The cache has limited (configurable) size - when it is reached, the least recently used entry is removed.
When requested expression is in the cache, the copy of the template is returned - individual instances still need to be resolved (placeholders substituted with names and values).
Caching is implemented for all expression types. The cache is per shard - shared for all operations, expression types, tables, users.
Default cache size is 2000 entries per shard and it has configuration option `alternator_max_expression_cache_entries_per_shard` (0 means cache disabled).
Basic metrics (total count of hits and misses for each expression type and number of evicted enries) are implemented.
Cache features are tested in boost unit tests and overall expression caching is tested with Python tests - both mostly rely on metrics.
refs #5023
`perf-alternator` test shows improvement (median):
| test | throughput | instructions_per_op | cpu_cycles_per_op | allocs_per_op |
| ------ | ---------------- | ----------------------------- | --------------------------- | ------------------- |
| read | +6.0% | -8.5% | -7.0% | -4.9% |
| write | +13.4% | -17.6% | -14.7% | -7.4% |
| write(lwt) | +12.7% | -7.9% | -6.9% | -2.8% |
| write_rwm | +5.4% | -10.5% | -7.3% | -4.1% |
"read" had a ProjectionExpression with 10 column names, "write" had a UpdateExpression with 10 column names and "write_rmw" had both ConditionExpression and UpdateExpression.
This patch also includes minor refactoring of other expressions related tests (https://github.com/scylladb/scylladb/issues/22494) - use `test_table_ss` instead of `test_table`.
Fixes#25855.
This is new feature - no backporting.
Closesscylladb/scylladb#25176
* github.com:scylladb/scylladb:
alternator: use expression caching
alternator: adds expression cache implementation
utils: extend lru_string_map
utils: add lru_string_map
alternator/expressions: error on parsing empty update expression
alternator/expressions: fix single value condition expression parsing
test/alternator: use `test_table_ss` instead of `test_table` in expressions related tests.
The code in `multishard_mutation_query.cc` implements the replica-side of range scans and as such it belongs in the replica module. Take the opportunity to also rename it to `multishard_query`, the code implements both data and mutation queries for a long time now.
Code cleanup, no backport required.
Closesscylladb/scylladb#26279
* github.com:scylladb/scylladb:
test/boost: rename multishard_mutation_query_test to multishard_query_test
replica/multishard_query: move code into namespace replica
replica/multishard_query.cc: update logger name
docs/paged-queries.md: update references to readers
root,replica: move multishard_mutation_query to replica/
ScyllaDB offers the `compression` DDL property for configuring compression per user table (compression algorithm and chunk size). If not specified, the default compression algorithm is the LZ4Compressor with a 4KiB chunk size. The same default applies to system tables as well.
This series introduces a new configuration option to allow customizing the default for user tables. It also adds some tests for the new functionality.
Fixes#25195.
Closesscylladb/scylladb#26003
* github.com:scylladb/scylladb:
test/cluster: Add tests for invalid SSTable compression options
test/boost: Add tests for SSTable compression config options
main: Validate SSTable compression options from config
db/config: Add SSTable compression options for user tables
db/config: Prepare compression_parameters for config system
compressor: Validate presence of sstable_compression in parameters
compressor: Add missing space in exception message
Every expression in Alternator's requests is parsed from string to adequate structure.
This patch implements a caching structure (input expression strings mapping to parsed 'template' structures), which will be used for handling requests in following commits.
If the reqested expression is valid (parsable) the cache will always return a value - if it is not already in the cache it will be created and stored.
The cache has limited (live configurable) size - when it is reached, the least recently used entry is removed.
The copy of the template in cache is returned - individual instances still need to be resolved (placeholders substituted with names and values).
Invalid requests will have no effect on the cache - the parser throws an exception.
Caching is implemented for all expression types. Internally it is based on helper structure `lru_string_map`.
Basic metrics (total count of hits and misses for each expression type and number of evictions) are implemented.
Metrics are used in boost unit tests.
Adds a lru_string_map definition.
This structure maps a string keys to templated arguments, allowing efficient lookup and adding keys.
Each lookup (and adding) puts the keys on internal LRU list and the entires may be efficiently removed in a LRU order.
It will be a base for the expression cache in Alternator.
Since patch 03461d6a54, all boost unit tests depending on `cql_test_env`
are compiled into a single executable (`combined_tests`). Add the new
test in there.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
The `vector_store_client_test` is moved from `test/boost` to a new
`test/vector_search` directory.
This change prepares a dedicated location for all upcoming tests
related to the vector search feature.
Vector search related implementation moved to a new module vector_search.
As the vector search functionality is going to be extended, it is
better to keep it in a separate module.
Upcoming changes in Seastar cause `rest::simple_send` to move the
`http::request` into `seastar::http::experimental::client::make_request`
when called multiple times. This leaves the original request in an
invalid state. Specifically, the `_version` field becomes empty,
causing request validation to fail. This patch ensures `version` is
explicitly set to prevent such failures.
Fixes: https://github.com/scylladb/scylladb/issues/26018Closesscylladb/scylladb#26066
This is yet another part in the BTI index project.
Overarching issue: https://github.com/scylladb/scylladb/issues/19191
Previous part: https://github.com/scylladb/scylladb/pull/25506/
Next part: plugging the BTI index readers and writers into sstable readers and writers.
The new code added in this PR isn't used outside of tests yet, but it's posted as a separate PR for reviewability.
This series implements, on top of the key translation logic, and abstract trie writing and traversal logic, a writer and a reader of sstable index files (which map primary keys to positions in Data.db), as described in f16fb6765b/src/java/org/apache/cassandra/io/sstable/format/bti/BtiFormat.md.
Caveats:
1. I think the added test has reasonable coverage, but that depends on running it multiple times. (Though it shouldn't need more than a few runs to catch any bug it covers). It's somewhat awkward as a test meant for running in CI, it's better as something you run many times after a relevant change.
2. These readers and writers are intended to be compatible with Cassandra, but I did *NOT* do any compatibility testing. The writers and readers added here have only been tested against each other, not against Cassandra's readers and writers.
3. This didn't undergo any proper benchmarking and optimization work. I was doing some measurements in the past, but everything was rewritten so much since then that the my old measurements are effectively invalidated. Frankly I have no idea what the performance of all this branchy-branchy logic is now.
No backports needed, new functionality.
Closesscylladb/scylladb#25626
* github.com:scylladb/scylladb:
test/manual: add bti_cassandra_compatibility_test
test/lib/random_schema: add some constraints for generated uuid and time/date values
test/lib/random_utils: add a variant of get_bytes which takes an `engine&`
test/boost: add bti_index_test
sstables/writer: add an accessor for the current write position in Data.db
sstables/trie: introduce bti_index_reader
sstables/trie: add bti_partition_index_writer.cc
sstables/trie: add bti_row_index_writer.cc
utils/bit_cast: add a new overload of write_unaligned()
sstables/trie: add trie_writer::add_partial()
sstables/consumer: add read_56()
sstables/trie: make bti_node_reader::page_ptr copy-constructible
sstables: extract abstract_index_reader from index_reader.hh to its own header
sstables/trie: add an accessor to the file_writer under bti_node_sink
sstables/types: make `deletion_time::operator tombstone()` const
sstables/types: add sstables::deletion_time::make_live()
sstables/trie: fix a special case in max_offset_from_child
sstables/trie: handle `partition_region`s other than `clustered` in BTI position encoding
sstables/trie: rewrite lcb_mismatch to handle fragment invalidation
test/boost/bti_key_translation_test: fix a compilation error hidden behind `if constexpr`
Adds a fat unit test (integration test?) for BTI index writers and readers.
The test generates a small random dataset for the index writer, writes
it to a BTI file, and then attempts to run all possible (and legal)
sequences (up to a certain length) of index reader operations and check
that the results match the expectation (dictated by a "simple"
reference index reader).
It is currently the only test for this new feature, but I think it's reasonably
good. (I validated the coverage by looking at LLVM coverage reports
and by manually adding bugs in various places and checking that the test
catches it after a reasonably small number of runs).
(Note that in a later series, when we hook up BTI indexes
to Data.db readers/writers, the feature will also be indirectly
tested by the corresponding integration tests).
This is a randomized test. As such, its power grows with the number of runs.
In particular, a single run has a decently high probability of
not exercising parts of the code at all. (E.g. the generated dataset
might have no clustering keys).
Also this is a slow test. (With the default parameters,
~1s in release mode on my PC, several seconds in
debug mode. (And note that this is after a custom parameter
downsizing for debug mode, because this test is slowed extremely
badly by debug mode, due to the forced preemption after every future)).
For those two reasons, I'm not glad to include it in the test suite that runs in CI.
Instead of running it once in every CI run, I'd very much rather
have it run 10000 times after the tested feature is touched,
and before releases. Unfortunately we don't have a precedent for
something like that.
Allows testing using either local mock server (installed or using docker),
or real GCP project (not tested as of writing this).
v2: Try podman if docker unavail
v3: Ensure we check log output on fake-gcs, because when using podman, the
published port will be connectible even though the actual server is not
up yet.
v4: Use ephermal port forward in docker/podman to allow us running parallel
instances. Also adjust credentials and port finding in test.
v5: Re-ensure no parallel tests for this: We seem to time out in podman
trying to fetch image for X parallel tests
v6: Remove the ephermal port stuff. Because of course this does not work
with our podman-in-podman. Do brute-force port speculation instead.
v7: Up timeout for server start to allow docker pull.
v8: Fix string check error
v9: Add explicit docker image version
Introduce the `subscribe` method to disk_space_monitor, allowing clients to
register callbacks triggered when disk utilization crosses a configurable
threshold.
The API supports flexible trigger options, including notifications on threshold
crossing and direction (above/below). This enables more granular and efficient
disk space monitoring for consumers.
This file provides translation routines for ring positions and clustering positions
from Scylla's native in-memory structures to BTI's byte-comparable encoding.
This translation is performed whenever a new decorated key or clustering block
are added to a BTI index, and whenever a BTI index is queried for a range of positions.
For a description of the encoding, see
fad1f74570/src/java/org/apache/cassandra/utils/bytecomparable/ByteComparable.md (multi-component-sequences-partition-or-clustering-keys-tuples-bounds-and-nulls)
The translation logic, with all the fragment awareness, lazy
evaluation and avoidable copies, is fairly bloated for the common cases
of simple and small keys. This is a potential optimization target for later.
`trie::node_reader`, added in a previous series, contains
encoding-aware logic for traversing a single node
(or a batch of nodes) during a trie search.
This commits adds encoding-agnostic functions which drive the
the `trie::node_reader` in a loop to traverse the whole branch.
Together, the added functions (`traverse`, `step`, `step_back`)
and the data structure they modify (`ancestor_trail`) constitute
a trie cursor. We might later wrap them into some `trie_cursor`
class, but regardless of whether we are going to do that,
keeping them (also) as free functions makes them easier to test.
Closesscylladb/scylladb#25396
This is the next part in the BTI index project.
Overarching issue: https://github.com/scylladb/scylladb/issues/19191
Previous part: https://github.com/scylladb/scylladb/pull/25154
Next part: implementing a trie cursor (the "set to key, step forwards, step backwards" thing) on top of the `node_reader` added here.
The new code added here is not used for anything yet, but it's posted as a separate PR
to keep things reviewably small.
This part implements the BTI trie node encoding, as described in https://github.com/apache/cassandra/blob/trunk/src/java/org/apache/cassandra/io/sstable/format/bti/BtiFormat.md#trie-nodes.
It contains the logic for encoding the abstract in-memory `writer_node`s (added in the previous PR)
into the on-disk format, and the logic for traversing the on-disk nodes during a read.
New functionality, no backporting needed.
Closesscylladb/scylladb#25317
* github.com:scylladb/scylladb:
sstables/trie: add tests for BTI node serialization and traversal
sstables/trie: implement BTI node traversal
sstables/trie: implement BTI serialization
utils/cached_file: add get_shared_page()
utils/cached_file: replace a std::pair with a named struct
Adds tests which check that nodes serialized by `bti_node_sink`
are readable by `bti_node_reader` with the right result.
(Note: there are no tests which check compatibility of the encoded nodes
with Cassandra or with handwritten hexdumps. There are only tests
for mutual compatibility between Scylla's writers and readers.
This can be considered a gap in testing.)
Before this series, the "system.clients" virtual table lists active connections (and their various properties, like client address, logged in username and client version) only for CQL requests. This series adds also Alternator clients to system.clients. One of the interesting use cases of this new feature is understanding exactly which SDK a user is using -without inspecting their application code. Different SDKs pass different "User-Agent" headers in requests, and that User-Agent will be visible in the system.clients entries for Alternator requests as the "driver_name" field.
Unlike CQL where logged in username, driver name, etc. applies to a complete connection, in the Alternator API, different requests can theoretically be signed by different users and carry different headers but still arrive over the same HTTP connection. So instead of listing the currently open Alternator *connections*, we will list the currently active *requests*.
The first three patches introduce utilities that will be useful in the implementation. The fourth patch is the implementation itself (which is quite simple with the utility introduced in the second patch), and the fifth patch a regression test for the new feature. The sixth patch adds documentation, the seventh patch refactors generic_server to use the newly introduced utility class and reduce code duplication, and the eighth patch adds a small check to an existing check of CQL's system.clients.
Fixes#24993
This patch adds a new feature, so doesn't require a backport. Nevertheless, if we want it to get to existing customers more quickly to allow us to better understand their use case by reading the system.clients table, we may want to consider backporting this patch to existing branches. There is some risk involved in this patch, because it adds code that gets run on every Alternator request, so a bug on it can cause problems for every Alternator request.
Closesscylladb/scylladb#25178
* github.com:scylladb/scylladb:
test/cqlpy: slightly strengthen test for system.clients
generic_server: use utils::scoped_item_list
docs/alternator: document the system.clients system table in Alternator
alternator: add test for Alternator clients in system.clients
alternator: list active Alternator requests in system.clients
utils: unit test for utils::scoped_item_list
utils: add a scoped_item_list utility class
utils: add "fatal" version of utils::on_internal_error()
This is the first part of a larger project meant to implement a trie-based
index format. (The same or almost the same as Cassandra's BTI).
As of this patch, the new code isn't used for anything yet,
but we introduced separately from its users to keep PRs small enough
for reviewability.
This commit introduces trie_writer, a class responsible for turning a
stream of (key, value) pairs (already sorted by key) into a stream of
serializable nodes, such that:
1. Each node lies entirely within one page (guaranteed).
2. Parents are located in the same page as their children (best-effort).
3. Padding (unused space) is minimized (best-effort).
It does mostly what you would expect a "sorted keys -> trie" builder to do.
The hard part is calculating the sizes of nodes (which, in a well-packed on-disk
format, depend on the exact offsets of the node from its children) and grouping
them into pages.
This implementation mostly follows Cassandra's design of the same thing.
There are some differences, though. Notable ones:
1. The writer operates on chains of characters, rather than single characters.
In Cassandra's implementation, the writer creates one node per character.
A single long key can be translated to thousands of nodes.
We create only one node per key. (Actually we split very long keys into
a few nodes, but that's arbitrary and beside the point).
For BTI's partition key index this doesn't matter.
Since it only stores a minimal unique prefix of each key,
and the trie is very balanced (due to token randomness),
the average number of new characters added per key is very close to 1 anyway.
(And the string-based logic might actually be a small pessimization, since
manipulating a 1-byte string might be costlier than manipulating a single byte).
But the row index might store arbitrarily long entries, and in that case the
character-based logic might result in catastrophically bad performance.
For reference: when writing a partition index, the total processing cost
of a single node in the trie_writer is on the order of 800 instructions.
Total processing cost of a single tiny partition during a `upgradesstables`
operation is on the order of 10000 instructions. A small INSERT is on the
order of 40000 instructions.
So processing a single 1000-character clustering key in the trie_writer
could cost as much as 20 INSERTs, which is scary. Even 100-character keys
can be very expensive. With extremely long keys like that, the string-based
logic is more than ~100x cheaper than character-based logic.
(Note that only *new* characters matter here. If two index entries share a
prefix, that prefix is only processed once. And the index is only populated
with the minimal prefix needed to distinguish neighbours. So in practice,
long chains might not happen often. But still, they are possible).
I don't know if it makes sense to care about this case, but I figured the
potential for problems is too big to ignore, so I switched to chain-based logic.
2. In the (assumed to be rare) case when a grouped subtree turns out to be bigger
than a full page after revising the estimate, Cassandra splits it in a
different way than us.
For testability, there is some separation between the logic responsible
for turning a stream of keys into a stream of nodes, and the logic
responsible for turning a stream of nodes into a stream of bytes.
This commit only includes the first part. It doesn't implement the target
on-disk format yet.
The serialization logic is passed to trie_writer via a template parameter.
There is only one test added in this commit, which attempts to be exhaustive,
by testing all possible datasets up to some size. The run time of the test
grows exponentially with the parameter size. I picked a set of parameters
which runs fast enough while still being expressive enough to cover all
the logic. (I checked the code coverage). But I also tested it with greater parameters
on my own machine (and with DEVELOPER_BUILD enabled, which adds extra sanitization).
Refs scylladb/scylladb#19191
New functionality, no backporting needed.
Closesscylladb/scylladb#25154
* github.com:scylladb/scylladb:
sstables: introduce trie_writer
utils/bit_cast: add object_representation()
The previous test introduced a new utility class, utils::scoped_item_list.
This patch adds a comprehensive unit test for the new class.
We test basic usage of scoped_item_list, its size() and empty() methods,
how items are removed from the list when their handle goes out of scope,
how a handle's move constructor works, how items can be read and written
through their handles, and finally that removing an item during a
for_each_gently() iteration doesn't break the iteration.
One thing I still didn't figure out how to properly test is how removing
an item during *multiple* iterations that run concurrently fixes
multiple iterators. I believe the code is correct there (we just have a
list of ongoing iterations - instead of just one), but haven't found
yet a way to reproduce this situation in a test.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
This is the first part of a larger project meant to implement a trie-based
index format. (The same or almost the same as Cassandra's BTI).
As of this patch, the new code isn't used for anything yet,
but we introduced separately from its users to keep PRs small enough
for reviewability.
This commit introduces trie_writer, a class responsible for turning a
stream of (key, value) pairs (already sorted by key) into a stream of
serializable nodes, such that:
1. Each node lies entirely within one page (guaranteed).
2. Parents are located in the same page as their children (best-effort).
3. Padding (unused space) is minimized (best-effort).
It does mostly what you would expect a "sorted keys -> trie" builder to do.
The hard part is calculating the sizes of nodes (which, in a well-packed on-disk
format, depend on the exact offsets of the node from its children) and grouping
them into pages.
This implementation mostly follows Cassandra's design of the same thing.
There are some differences, though. Notable ones:
1. The writer operates on chains of characters, rather than single characters.
In Cassandra's implementation, the writer creates one node per character.
A single long key can be translated to thousands of nodes.
We create only one node per key. (Actually we split very long keys into
a few nodes, but that's arbitrary and beside the point).
For BTI's partition key index this doesn't matter.
Since it only stores a minimal unique prefix of each key,
and the trie is very balanced (due to token randomness),
the average number of new characters added per key is very close to 1 anyway.
(And the string-based logic might actually be a small pessimization, since
manipulating a 1-byte string might be costlier than manipulating a single byte).
But the row index might store arbitrarily long entries, and in that case the
character-based logic might result in catastrophically bad performance.
For reference: when writing a partition index, the total processing cost
of a single node in the trie_writer is on the order of 800 instructions.
Total processing cost of a single tiny partition during a `upgradesstables`
operation is on the order of 10000 instructions. A small INSERT is on the
order of 40000 instructions.
So processing a single 1000-character clustering key in the trie_writer
could cost as much as 20 INSERTs, which is scary. Even 100-character keys
can be very expensive. With extremely long keys like that, the string-based
logic is more than ~100x cheaper than character-based logic.
(Note that only *new* characters matter here. If two index entries share a
prefix, that prefix is only processed once. And the index is only populated
with the minimal prefix needed to distinguish neighbours. So in practice,
long chains might not happen often. But still, they are possible).
I don't know if it makes sense to care about this case, but I figured the
potential for problems is too big to ignore, so I switched to chain-based logic.
2. In the (assumed to be rare) case when a grouped subtree turns out to be bigger
than a full page after revising the estimate, Cassandra splits it in a
different way than us.
For testability, there is some separation between the logic responsible
for turning a stream of keys into a stream of nodes, and the logic
responsible for turning a stream of nodes into a stream of bytes.
This commit only includes the first part. It doesn't implement the target
on-disk format yet.
The serialization logic is passed to trie_writer via a template parameter.
There is only one test added in this commit, which attempts to be exhaustive,
by testing all possible datasets up to some size. The run time of the test
grows exponentially with the parameter size. I picked a set of parameters
which runs fast enough while still being expressive enough to cover all
the logic. (I checked the code coverage). But I also tested it with greater parameters
on my own machine (and with DEVELOPER_BUILD enabled, which adds extra sanitization).
This patch is a part of vector_store_client sharded service
implementation for a communication with vector-store service.
It adds a `services/vector_store_client.{cc|hh}` sharded service and a
configuration parameter `vector_store_uri` with a
`http://vector-store.dns.name:port` format. If there will be an error
during parsing that parameter there will be an exception during
construction.
For the future unit testing purposes the patch adds
`vector_store_client_tester` as a way to inject mockup functionality.
This service will be used by the select statements for the Vector search
indexes (see VS-46). For this reason I've added vector_store_client
service in the query processor.
Reference: VS-47 VS-45
This patch implements a new class, `comparable_bytes`, designed to
implement methods for converting data values to and from byte-comparable
formats. The class stores the comparable bytes as `managed_bytes` and
currently provides the structure for all required methods. The actual
logic for converting various data types will be implemented in subsequent
patches.
Signed-off-by: Lakshmi Narayanan Sreethar <lakshmi.sreethar@scylladb.com>
Currently if raft is enabled all nodes are voters in group0. However it
is not necessary to have all nodes to be voters - it only slows down
the raft group operation (since the quorum is large) and makes
deployments with asymmetrical DCs problematic (2 DCs with 5 nodes along
1 DC with 10 nodes will lose the majority if large DC is isolated).
The topology coordinator will now maintain a state where there are only
limited number of voters, evenly distributed across the DCs and racks.
After each node addition or removal the voters are recalculated and
rebalanced if necessary. That means:
* When a new node is added, it might become a voter depending on the
current distribution of voters - either if there are still some voter
"slots" available, or if the new node is a better candidate than some
existing voter (in which case the existing node voter status might be
revoked).
* When a voter node is removed or stopped (shut down), its voter status
is revoked and another node might become a voter instead (this can also
depend on other circumstances, like e.g. changing the number of DCs).
* If a node addition or removal causes a change in number of datacenters
(DCs) or racks, the rebalance action might become wider (as there are
some special rules applying to 1 vs 2 vs more DCs, also changing the
number of racks might cause similar effects in the voters distribution)
Special conditions for various number of DCs:
* 1 DC: Can have up to the maximum allowed number of voters (5 - see below)
* 2 DCs: The distribution of the voters will be asymmetric (if possible),
meaning that we can tolerate a loss of the DC with the smaller number
of voters (if both would have the same number of voters we'd lose the
majority if any of the DCs is lost).
For example, if we have 2 DCs with 2 nodes each, one of them will only
have 1 voter (despite the limit of 5). Also, if one of the 2 DCs has
more racks than the other and the node count allows it, the DC with
the more racks will have more voters.
* 3 and more DCs: The distribution of the voters will be so that every
DC has strictly less than half of the total voters (so a loss of any
of the DCs cannot lead to the majority loss). Again, DCs with more
racks are being preferred in the voter distribution.
At the moment we will be handling the zero-token nodes in the same way
as the regular nodes (i.e. the zero-token nodes will not take any
priority in the voter distribution). Technically it doesn't make much
sense to have a zero-token node that is not a voter (when there are
regular nodes in the same DC being voters), but currently the intended
purpose of zero-token nodes is to form an "arbiter DC" (in case of 2 DCs,
creating a third DC with zero-token nodes only), so for that intended
purpose no special handling is needed and will work out of the box.
If a preference of zero token nodes will eventually be needed/requested,
it will be added separately from this PR.
Currently the voter limits will not be configurable (we might introduce
configurable limits later if that would be needed/requested).
The feature is enabled by the `group0_limited_voters` feature flag
to avoid issues with cluster upgrade (the feature will be only enabled
once all nodes in the cluster are upgraded to the version supporting
the feature).
Fixes: scylladb/scylladb#18793
A wrapper around a shared service allowing
safe plug and unplug of the service from its user
using a phased-barrier operation permit guarding
the service while in use.
Also add a unit test for this class.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
File based stream is a new feature that optimizes tablet movement
significantly. It streams the entire SSTable files without deserializing
SSTable files into mutation fragments and re-serializing them back into
SSTables on receiving nodes. As a result, less data is streamed over the
network, and less CPU is consumed, especially for data models that
contain small cells.
The following patches are imported from the scylla enterprise:
*) Merge 'Introduce file stream for tablet' from Asias He
This patch uses Seastar RPC stream interface to stream sstable files on
network for tablet migration.
It streams sstables instead of mutation fragments. The file based
stream has multiple advantages over the mutation streaming.
- No serialization or deserialization for mutation fragments
- No need to read and process each mutation fragments
- On wire data is more compact and smaller
In the test below, a significant speed up is observed.
Two nodes, 1 shard per node, 1 initial_tablets:
- Start node 1
- Insert 10M rows of data with c-s
- Bootstrap node 2
Node 1 will migration data to node2 with the file stream.
Test results:
1) File stream: bytes on wire = 1132006250 bytes, bw = 836MB/s
[shard 0:stre] stream_blob - stream_sstables[eadaa8e0-a4f2-4cc6-bf10-39ad1ce106b0]
Finished sending sstable_nr=2 files_nr=18 files={} range=(-1,9223372036854775807] bytes_sent=1132006250 stream_bw=836MB/s
[shard 0:stre] storage_service - Streaming for tablet migration of a4f68900-568a-11ee-b7b9-c2b13945eed2:1 took 1.08004s seconds
2) Mutation stream: bytes on wire = 3030004736 bytes, bw = 125410.87 KiB/s = 128MB/s
[shard 0:stre] stream_session - [Stream #406dc8b0-56b5-11ee-bc2d-000bf4871058]
Streaming plan for Tablet migration-ks1-index-0 succeeded, peers={127.0.0.1}, tx=0 KiB, 0.00 KiB/s, rx=2958989 KiB, 125410.87 KiB/s
[shard 0:stre] storage_service - Streaming for tablet migration of a4f68900-568a-11ee-b7b9-c2b13945eed2:1 took 23.5992s seconds
Test Summary:
File stream v.s. Mutation stream improvements
- Stream bandwidth = 836 / 128 (MB/s) = 6.53X
- Stream time = 23.60 / 1.08 (Seconds) = 21.85X
- Stream bytes on wire = 3030004736 / 1132006250 (Bytes)= 2.67X
Closes scylladb/scylla-enterprise#3438
* github.com:scylladb/scylla-enterprise:
tests: Add file_stream_test
streaming: Implement file stream for tablet
*) streaming: Use new take_storage_snapshot interface
The new take_storage_snapshot returns a file object instead of a file
name. This allows the file stream sender to read from the file even if
the file is deleted by compaction.
Closes scylladb/scylla-enterprise#3728
*) streaming: Protect unsupported file types for file stream
Currently, we assume the file streamed over the stream_blob rpc verb is
a sstable file. This patch rejects the unsupported file types on the
receiver side. This allows us to stream more file types later using the
current file stream infrastructure without worrying about old nodes
processing the new file types in the wrong way.
- The file_ops::noop is renamed to file_ops::stream_sstables to be
explicit about the file types
- A missing test_file_stream_error_injection is added to the idl
Fixes: #3846
Tests: test_unsupported_file_ops
Closesscylladb/scylla-enterprise#3847
*) idl: Add service::session_id id to idl
It will be used in the next patch.
Refs #3907
*) streaming: Protect file stream with topology_guard
Similar to "storage_service, tablets: Use session to guard tablet
streaming", this patch protects file stream with topology_guard.
Fixes#3907
*) streaming: Take service topology_guard under the try block
Taking the service::topology_guard could throw. Currently, it throws
outside the try block, so the rpc sink will not be closed, causing the
following assertion:
```
scylla: seastar/include/seastar/rpc/rpc_impl.hh:815: virtual
seastar::rpc::sink_impl<netw::serializer,
streaming::stream_blob_cmd_data>::~sink_impl() [Serializer =
netw::serializer, Out = <streaming::stream_blob_cmd_data>]: Assertion
`this->_con->get()->sink_closed()' failed.
```
To fix, move more code including the topology_guard taking code to the
try block.
Fixes https://github.com/scylladb/scylla-enterprise/issues/4106Closesscylladb/scylla-enterprise#4110
*) Merge 'Preserve original SSTable state with file based tablet migration' from Raphael "Raph" Carvalho
We're not preserving the SSTable state across file based migration, so
staging SSTables for example are being placed into main directory, and
consequently, we're mixing staging and non-staging data, losing the
ability to continue from where the old replica left off.
It's expected that the view update backlog is transferred from old
into new replica, as migration doesn't wait for leaving replica to
complete view update work (which can take long). Elasticity is preferred.
So this fix guarantees that the state of the SSTable will be preserved
by propagating it in form of subdirectory (each subdirectory is
statically mapped with a particular state).
The staging sstables aren't being registered into view update generator
yet, as that's supposed to be fixed in OSS (more details can be found
at https://github.com/scylladb/scylladb/issues/19149).
Fixes#4265.
Closesscylladb/scylla-enterprise#4267
* github.com:scylladb/scylla-enterprise:
tablet: Preserve original SSTable state with file based tablet migration
sstables: Add get method for sstable state
*) sstable: (Re-)add shareabled_components getter
*) Merge 'File streaming sstables: Use sstable source/sink to transfer snapshots' from Calle Wilund
Fixes#4246
Alternative approach/better separation of concern, transport vs. sstable layer. Builds on #4472, but fancier.
Ensures we transfer and pre-process scylla metadata for streamed
file blobs first, then properly apply receiving nodes local config
by using a source and sink layer exported from sstables, which
handles things like ordering, metadata filtering (on source) as well
as handling metadata and proper IO paths when writing data on
receiver node (sink).
This implementation maintains the statelessness of the current
design, and the delegated sink side will re-read and re-write the
metadata for each component processed. This is a little wasteful,
but the meta is small, and it is less error prone than trying to do
caching cross-shards etc. The transport is isolated from the
knowledge.
This is an alternative/complement to #4436 and #4472, fixing the
underlying issue. Note that while the layers/API:s here allows easy
fixing of other fundamental problems in the feature (such as
destination location etc), these are not included in the PR, to keep
it as close to the current behaviour as possible.
Closesscylladb/scylla-enterprise#4646
* github.com:scylladb/scylla-enterprise:
raft_tests: Copy/add a topology test with encryption
file streaming: Use sstable source/sink to transfer snapshots
sstables: Add source and sink objects + producers for transfering a snapshot
sstable::types: Add remove accessor for extension info in metadata
*) The change for error injection in merge commit 966ea5955dd8760:
File streaming now has "stream_mutation_fragments" error injection points
so test_table_dropped_during_streaming works with file streaming.
*) doc: document file-based streaming
This commit adds a description of the file-based streaming feature to the documentation.
It will be displayed in the docs using the scylladb_include_flag directive after
https://github.com/scylladb/scylladb/pull/20182 is merged, backported to branch-6.0,
and, in turn, branch-2024.2.
Refs https://github.com/scylladb/scylla-enterprise/issues/4585
Refs https://github.com/scylladb/scylla-enterprise/issues/4254Closesscylladb/scylla-enterprise#4587
*) doc: move File-based streaming to the Tablets source file-based-streaming
This commit moves the description of file-based streaming from a common include file
to the regular doc source file where tablets are described.
Closesscylladb/scylla-enterprise#4652
*) streaming: sstable_stream_sink_impl: abort: prevent null pointer dereference
Closesscylladb/scylladb#22467
In order to reduce the dependency on external libraries, and for better integration with ranges in C++ standard library. let's use the homebrew `utils::views::unique()` before unique is accepted by the C++ standard.
---
it's a cleanup, hence no need to backport.
Closesscylladb/scylladb#22393
* github.com:scylladb/scylladb:
cql3, test: switch from boost::adaptors::uniqued to utils::views:unique
utils: implement drop-in replacement for replacing boost::adaptors::uniqued
Add a custom implementation of boost::adaptors::uniqued that is compatible
with C++20 ranges library. This bridges the gap between Boost.Range and
the C++ standard library ranges until std::views::unique becomes available
in C++26. Currently, the unique view is included in
[P2214](https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2023/p2760r0.html)
"A Plan for C++ Ranges Evolution", which targets C++26.
The implementation provides:
- A lazy view adaptor that presents unique consecutive elements
- No modification of source range
- Compatibility with C++20 range views and concepts
- Lighter header dependencies compared to Boost
This resolves compilation errors when piping C++20 range views to
boost::adaptors::uniqued, which fails due to concept requirements
mismatch. For example:
```c++
auto range = std::views::take(n) | boost::adaptors::uniqued; // fails
```
This change also offers us a lightweight solution in terms of smaller
header dependency.
While std::ranges::unique exists in C++23, it's an eager algorithm that
modifies the source range in-place, unlike boost::adaptors::uniqued which
is a lazy view. The proposed std::views::unique (P2214) targeting C++26
would provide this functionality, but is not yet available.
This implementation serves as an interim solution for filtering consecutive
duplicate elements using range views until std::views::unique is
standardized.
For more details on the differences between `std::ranges::unique` and
`boost::adaptors::uniqued`:
- boost::adaptors::uniqued is a view adaptor that creates a lazy view over the original range. It:
* Doesn't modify the source range
* Returns a view that presents unique consecutive elements
* Is non-destructive and lazy-evaluated
* Can be composed with other views
- std::ranges::unique is an algorithm that:
* Modifies the source range in-place
* Removes consecutive duplicates by shifting elements
* Returns an iterator to the new logical end
* Cannot be used as a view or composed with other range adaptors
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
File based stream is a new feature that optimizes tablet movement
significantly. It streams the entire SSTable files without deserializing
SSTable files into mutation fragments and re-serializing them back into
SSTables on receiving nodes. As a result, less data is streamed over the
network, and less CPU is consumed, especially for data models that
contain small cells.
The following patches are imported from the scylla enterprise:
*) Merge 'Introduce file stream for tablet' from Asias He
This patch uses Seastar RPC stream interface to stream sstable files on
network for tablet migration.
It streams sstables instead of mutation fragments. The file based
stream has multiple advantages over the mutation streaming.
- No serialization or deserialization for mutation fragments
- No need to read and process each mutation fragments
- On wire data is more compact and smaller
In the test below, a significant speed up is observed.
Two nodes, 1 shard per node, 1 initial_tablets:
- Start node 1
- Insert 10M rows of data with c-s
- Bootstrap node 2
Node 1 will migration data to node2 with the file stream.
Test results:
1) File stream: bytes on wire = 1132006250 bytes, bw = 836MB/s
[shard 0:stre] stream_blob - stream_sstables[eadaa8e0-a4f2-4cc6-bf10-39ad1ce106b0]
Finished sending sstable_nr=2 files_nr=18 files={} range=(-1,9223372036854775807] bytes_sent=1132006250 stream_bw=836MB/s
[shard 0:stre] storage_service - Streaming for tablet migration of a4f68900-568a-11ee-b7b9-c2b13945eed2:1 took 1.08004s seconds
2) Mutation stream: bytes on wire = 3030004736 bytes, bw = 125410.87 KiB/s = 128MB/s
[shard 0:stre] stream_session - [Stream #406dc8b0-56b5-11ee-bc2d-000bf4871058]
Streaming plan for Tablet migration-ks1-index-0 succeeded, peers={127.0.0.1}, tx=0 KiB, 0.00 KiB/s, rx=2958989 KiB, 125410.87 KiB/s
[shard 0:stre] storage_service - Streaming for tablet migration of a4f68900-568a-11ee-b7b9-c2b13945eed2:1 took 23.5992s seconds
Test Summary:
File stream v.s. Mutation stream improvements
- Stream bandwidth = 836 / 128 (MB/s) = 6.53X
- Stream time = 23.60 / 1.08 (Seconds) = 21.85X
- Stream bytes on wire = 3030004736 / 1132006250 (Bytes)= 2.67X
Closes scylladb/scylla-enterprise#3438
* github.com:scylladb/scylla-enterprise:
tests: Add file_stream_test
streaming: Implement file stream for tablet
*) streaming: Use new take_storage_snapshot interface
The new take_storage_snapshot returns a file object instead of a file
name. This allows the file stream sender to read from the file even if
the file is deleted by compaction.
Closes scylladb/scylla-enterprise#3728
*) streaming: Protect unsupported file types for file stream
Currently, we assume the file streamed over the stream_blob rpc verb is
a sstable file. This patch rejects the unsupported file types on the
receiver side. This allows us to stream more file types later using the
current file stream infrastructure without worrying about old nodes
processing the new file types in the wrong way.
- The file_ops::noop is renamed to file_ops::stream_sstables to be
explicit about the file types
- A missing test_file_stream_error_injection is added to the idl
Fixes: #3846
Tests: test_unsupported_file_ops
Closesscylladb/scylla-enterprise#3847
*) idl: Add service::session_id id to idl
It will be used in the next patch.
Refs #3907
*) streaming: Protect file stream with topology_guard
Similar to "storage_service, tablets: Use session to guard tablet
streaming", this patch protects file stream with topology_guard.
Fixes#3907
*) streaming: Take service topology_guard under the try block
Taking the service::topology_guard could throw. Currently, it throws
outside the try block, so the rpc sink will not be closed, causing the
following assertion:
```
scylla: seastar/include/seastar/rpc/rpc_impl.hh:815: virtual
seastar::rpc::sink_impl<netw::serializer,
streaming::stream_blob_cmd_data>::~sink_impl() [Serializer =
netw::serializer, Out = <streaming::stream_blob_cmd_data>]: Assertion
`this->_con->get()->sink_closed()' failed.
```
To fix, move more code including the topology_guard taking code to the
try block.
Fixes https://github.com/scylladb/scylla-enterprise/issues/4106Closesscylladb/scylla-enterprise#4110
*) Merge 'Preserve original SSTable state with file based tablet migration' from Raphael "Raph" Carvalho
We're not preserving the SSTable state across file based migration, so
staging SSTables for example are being placed into main directory, and
consequently, we're mixing staging and non-staging data, losing the
ability to continue from where the old replica left off.
It's expected that the view update backlog is transferred from old
into new replica, as migration doesn't wait for leaving replica to
complete view update work (which can take long). Elasticity is preferred.
So this fix guarantees that the state of the SSTable will be preserved
by propagating it in form of subdirectory (each subdirectory is
statically mapped with a particular state).
The staging sstables aren't being registered into view update generator
yet, as that's supposed to be fixed in OSS (more details can be found
at https://github.com/scylladb/scylladb/issues/19149).
Fixes#4265.
Closesscylladb/scylla-enterprise#4267
* github.com:scylladb/scylla-enterprise:
tablet: Preserve original SSTable state with file based tablet migration
sstables: Add get method for sstable state
*) sstable: (Re-)add shareabled_components getter
*) Merge 'File streaming sstables: Use sstable source/sink to transfer snapshots' from Calle Wilund
Fixes#4246
Alternative approach/better separation of concern, transport vs. sstable layer. Builds on #4472, but fancier.
Ensures we transfer and pre-process scylla metadata for streamed
file blobs first, then properly apply receiving nodes local config
by using a source and sink layer exported from sstables, which
handles things like ordering, metadata filtering (on source) as well
as handling metadata and proper IO paths when writing data on
receiver node (sink).
This implementation maintains the statelessness of the current
design, and the delegated sink side will re-read and re-write the
metadata for each component processed. This is a little wasteful,
but the meta is small, and it is less error prone than trying to do
caching cross-shards etc. The transport is isolated from the
knowledge.
This is an alternative/complement to #4436 and #4472, fixing the
underlying issue. Note that while the layers/API:s here allows easy
fixing of other fundamental problems in the feature (such as
destination location etc), these are not included in the PR, to keep
it as close to the current behaviour as possible.
Closesscylladb/scylla-enterprise#4646
* github.com:scylladb/scylla-enterprise:
raft_tests: Copy/add a topology test with encryption
file streaming: Use sstable source/sink to transfer snapshots
sstables: Add source and sink objects + producers for transfering a snapshot
sstable::types: Add remove accessor for extension info in metadata
*) The change for error injection in merge commit 966ea5955dd8760:
File streaming now has "stream_mutation_fragments" error injection points
so test_table_dropped_during_streaming works with file streaming.
*) doc: document file-based streaming
This commit adds a description of the file-based streaming feature to the documentation.
It will be displayed in the docs using the scylladb_include_flag directive after
https://github.com/scylladb/scylladb/pull/20182 is merged, backported to branch-6.0,
and, in turn, branch-2024.2.
Refs https://github.com/scylladb/scylla-enterprise/issues/4585
Refs https://github.com/scylladb/scylla-enterprise/issues/4254Closesscylladb/scylla-enterprise#4587
*) doc: move File-based streaming to the Tablets source file-based-streaming
This commit moves the description of file-based streaming from a common include file
to the regular doc source file where tablets are described.
Closesscylladb/scylla-enterprise#4652
*) streaming: sstable_stream_sink_impl: abort: prevent null pointer dereference
Closesscylladb/scylladb#22034
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
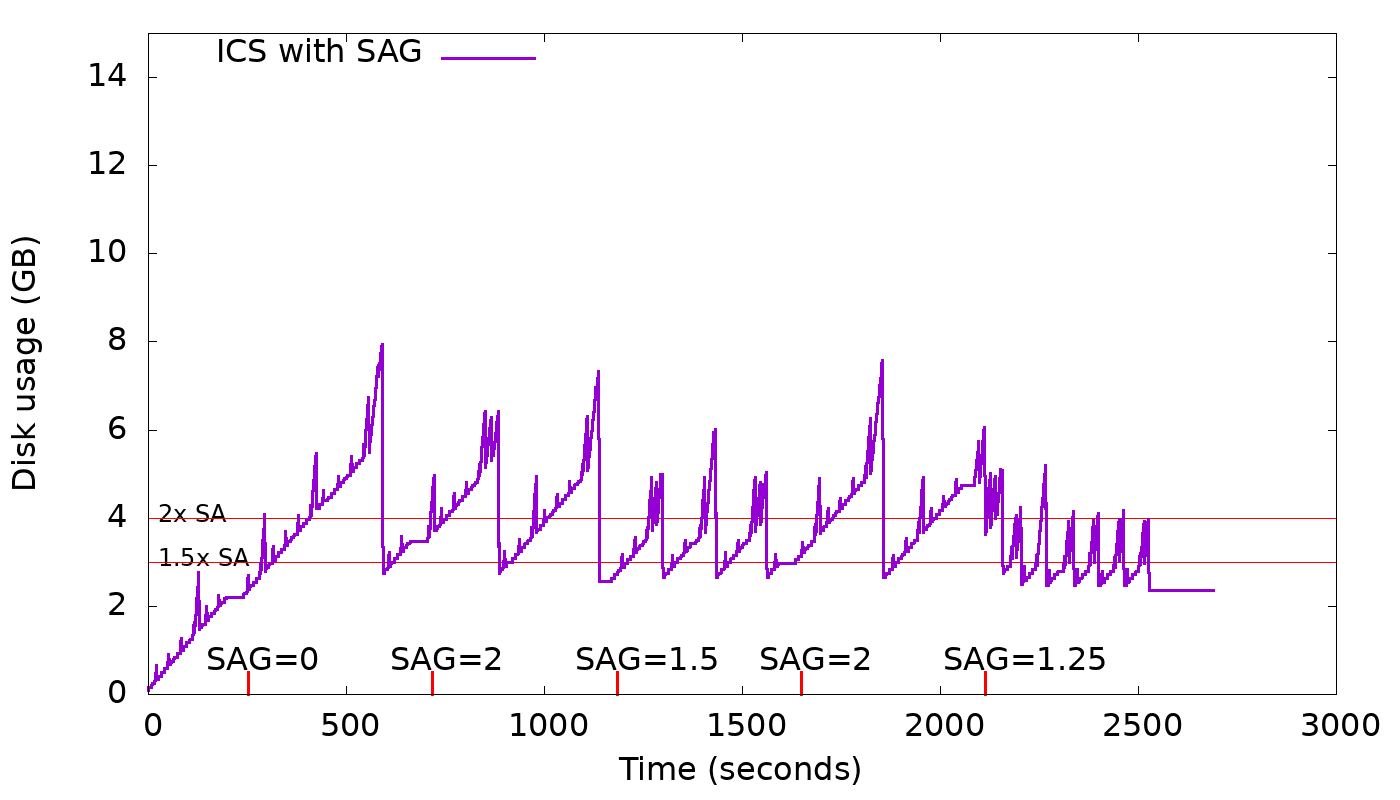
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
Adds glue needed to pass lz4 and zstd with streaming and/or dictionaries
as the network traffic compressors for Seastar's RPC servers.
The main jobs of this glue are:
1. Implementing the API expected by Seastar from RPC compressors.
2. Expose metrics about the effectiveness of the compression.
3. Allow dynamically switching algorithms and dictionaries on a running
connection, without any extra waits.
The biggest design decision here is that the choice of algorithm and dictionary
is negotiated by both sides of the connection, not dictated unilaterally by the
sender.
The negotiation algorithm is fairly complicated (a TLA+ model validating
it is included in the commit). Unilateral compression choice would be much simpler.
However, negotiation avoids re-sending the same dictionary over every
connection in the cluster after dictionary updates (with one-way communication,
it's the only reliable way to ensure that our receiver possesses the dictionary
we are about to start using), lets receivers ask for a cheaper compression mode
if they want, and lets them refuse to update a dictionary if they don't think
they have enough free memory for that.
In hindsight, those properties probably weren't worth the extra complexity and
extra development effort.
Zstd can be quite expensive, so this patch also includes a mechanism which
temporarily downgrades the compressor from zstd to lz4 if zstd has been
using too much CPU in a given slice of time. But it should be noted that
this can't be treated as a reliable "protection" from negative performance
effects of zstd, since a downgrade can happen on the sender side,
and receivers are at the mercy of senders.
We are planning to improve some usages of compression in Scylla
(in which we compress small blocks of data) by pre-training
compression dictionaries on similar data seen so far.
For example, many RPC messages have similar structure
(and likely similar data), so the similarity could be exploited
for better compression. This can be achieved e.g. by training
a dictionary on the RPC traffic, and compressing subsequent
RPC messages against that dictionary.
To work well, the training should be fed a representative sample
of the compressible data. Such a sample can be approached by
taking a random subset (of some given reasonable size) of the data,
with uniform probability.
For our purposes, we need an online algorithm for this -- one
which can select the random k-subset from a stream of arbitrary
size (e.g. all RPC traffic over an hour), while requiring only
the necessary minimum of memory.
This is a known problem, called "reservoir sampling".
This PR introduces `reservoir_sampler`, which implements
an optimal algorithm for reservoir sampling.
Additionally, it introduces `page_sampler` -- a wrapper for `reservoir_sampler`,
which uses it to select a random sample of pages from a stream of bytes.
Adds utilities for "advanced" methods of compression with lz4
and zstd -- with streaming (a history buffer persisted across messages)
and/or precomputed dictionaries.
This patch is mostly just glue needed to use the underlying
libraries with discontiguous input and output buffers, and for reusing the
same compressor context objects across messages. It doesn't contain
any innovations of its own.
There is one "design decision" in the patch. The block format of LZ4
doesn't contain the length of the compressed blocks. At decompression
time, that length must be delivered to the decompressor by a channel
separate to the compressed block itself. In `lz4_cstream`, we deal
with that by prepending a variable-length integer containing the
compressed size to each compressed block. This is suboptimal for
single-fragment messages, since the user of lz4_cstream is likely
going to remember the length of the whole message anyway,
which makes the length prepended to the block redundant.
But a loss of 1 byte is probably acceptable for most uses.
To reduce test executable size and speed up compilation time, compile unit
tests into a single executable.
Here is a file size comparison of the unit test executable:
- Before applying the patch
$ du -h --exclude='*.o' --exclude='*.o.d' build/release/test/boost/ build/debug/test/boost/
11G build/release/test/boost/
29G build/debug/test/boost/
- After applying the patch
du -h --exclude='*.o' --exclude='*.o.d' build/release/test/boost/ build/debug/test/boost/
5.5G build/release/test/boost/
19G build/debug/test/boost/
It reduces executable sizes 5.5GB on release, and 10GB on debug.
Closes#9155Closesscylladb/scylladb#21443
{kind=link}