The namespace usage in this directory is very inconsistent, with files
and classes scattered in:
* global namespace
* namespace compaction
* namespace sstables
With cases, where all three used in the same file. This code used to
live in sstables/ and some of it still retains namespace sstables as a
heritage of that time. The mismatch between the dir (future module) and
the namespace used is confusing, so finish the migration and move all
code in compaction/ to namespace compaction too.
This patch, although large, is mechanic and only the following kind of
changes are made:
* replace namespace sstable {} with namespace compaction {}
* add namespace compaction {}
* drop/add sstables::
* drop/add compaction::
* move around forward-declarations so they are in the correct namespace
context
This refactoring revealed some awkward leftover coupling between
sstables and compaction, in sstables/sstable_set.cc, where the
make_sstable_set() methods of compaction strategies are implemented.
This will allow upcoming work to gently produce a sstable set for
each compaction group view. Example: repaired and unrepaired.
Locking strategy for compaction's sstable selection:
Since sstable retrieval path became futurized, tasks in compaction
manager will now hold the write lock (compaction_state::lock)
when retrieving the sstable list, feeding them into compaction
strategy, and finally registering selected sstables as compacting.
The last step prevents another concurrent task from picking the
same sstable. Previously, all those steps were atomic, but
we have seen stall in that area in large installations, so
futurization of that area would come sooner or later.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Since table_state is a view to a compaction group, it makes sense
to rename it as so.
With upcoming incremental repair, each replica::compaction_group
will be actually two compaction groups, so there will be two
views for each replica::compaction_group.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
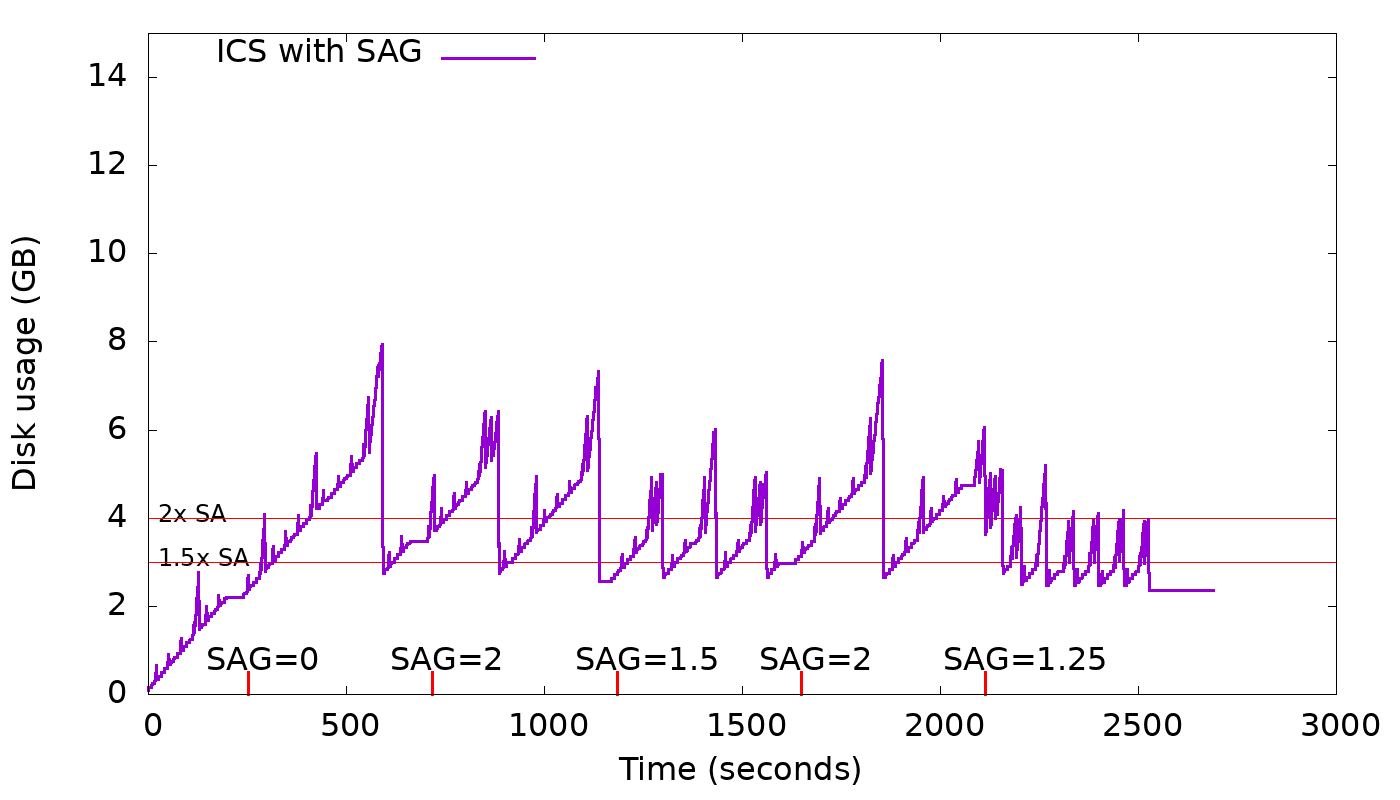
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
When off-strategy is disabled, data segregation is not postponed,
meaning that getting partition estimate right is important to
decrease filter's false positives. With streaming, we don't
have min and max timestamps at destination, well, we could have
extended the RPC verb to send them, but turns out we can deduce
easily the amount of windows using default TTL. Given partitioner
random nature, it's not absurd to assume that a given range being
streamed may overlap with all windows, meaning that each range
will yield one sstable for each window when segregating incoming
data. Today, we assume the worst of 100 windows (which is the
max amount of sstables the input data can be segregated into)
due to the lack of metadata for estimating the window count.
But given that users are recommended to target a max of ~20
windows, it means partition estimate is being downsized 5x more
than needed. Let's improve it by using default TTL when
estimating window count, so even on absence of timestamp
metadata, the partition estimation won't be way off.
Fixes#15704.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Now everything is prepared for the switch, let's do it.
Now let's wait for ICS to enjoy the set of changes.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
This is the last step of deprecation dance of DTCS.
In Scylla 5.1, users were warned that DTCS was deprecated.
In 5.2, altering or creation of tables with DTCS was forbidden.
5.3 branch was already created, so this is targetting 5.4.
Users that refused to move away from DTCS will have Scylla
falling back to the default strategy, either STCS or ICS.
See:
WARN 2023-07-14 09:49:11,857 [shard 0] schema_tables - Falling back to size-tiered compaction strategy after the problem: Unable to find compaction strategy class 'DateTieredCompactionStrategy
Then user can later switch to a supported strategy with
alter table.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closes#14559
In that level no io_priority_class-es exist. Instead, all the IO happens
in the context of current sched-group. File API no longer accepts prio
class argument (and makes io_intent arg mandatory to impls).
So the change consists of
- removing all usage of io_priority_class
- patching file_impl's inheritants to updated API
- priority manager goes away altogether
- IO bandwidth update is performed on respective sched group
- tune-up scylla-gdb.py io_queues command
The first change is huge and was made semi-autimatically by:
- grep io_priority_class | default_priority_class
- remove all calls, found methods' args and class' fields
Patching file_impl-s is smaller, but also mechanical:
- replace io_priority_class& argument with io_intent* one
- pass intent to lower file (if applicatble)
Dropping the priority manager is:
- git-rm .cc and .hh
- sed out all the #include-s
- fix configure.py and cmakefile
The scylla-gdb.py update is a bit hairry -- it needs to use task queues
list for IO classes names and shares, but to detect it should it checks
for the "commitlog" group is present.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Closes#13963
once compaction_strategy is made staless, the state must be retrieved
in notify_completion() through table_state.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Schema related files are moved there. This excludes schema files that
also interact with mutations, because the mutation module depends on
the schema. Those files will have to go into a separate module.
Closes#12858
Today, compaction_backlog_tracker is managed in each compaction_strategy
implementation. So every compaction strategy is managing its own
tracker and providing a reference to it through get_backlog_tracker().
But this prevents each group from having its own tracker, because
there's only a single compaction_strategy instance per table.
To remove this limitation, compaction_strategy impl will no longer
manage trackers but will instead provide an interface for trackers
to be created, such that each compaction group will be allowed to
have its own tracker, which will be managed by compaction manager.
On compaction strategy change, table will update each group with
the new tracker, which is created using the previously introduced
ompaction_group_sstable_set_updater.
Now table's backlog will be the sum of all compaction_group backlogs.
The normalization factor is applied on the sum, so we don't have
to adjust each individual backlog to any factor.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
flat_mutation_reader make_scrubbing_reader no longer exists
and there is no need to include flat_mutation_reader.hh
nor forward declare the class.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Then caller can decide whether to copy or move candidate set into the
function. cleanup_sstables_compaction_task can move candidates as
it's no longer needed once it retrieves all descriptors.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Today, all compaction strategies will clean up their files using the
incremental approach of one sstable being rewritten at a time.
Turns out that's not the best approach performance wise. Let's take
STCS for example. As cleanup finishes rewriting one file, the output
file is placed into the sstable set. Regular now can compact that
file with another that was already there (e.g. produced by flush after
cleanup started). Inefficient compactions like this can keep happening
as cleanup incrementally places output file into the candidate list
for regular.
This method will allow strategies to clean up their files in batches.
For example, STCS can clean up all files in smallest tiers in single
round, allowing the output data to be added at once. So next compaction
rounds can be more efficient in terms of writeamp. Another benefit is
that deduplication and GC can happen more efficiently.
The drawback is the space requirement, as we no longer compact one file
a a time. However, the impact is minimized by cleaning up the smallest
tier first. With leveled strategy for example, even though 90% of data
is in highest level, the space requirement is not a problem because
we can apply the incremental compaction on its behalf. The same applies
to ICS. With STCS, the requirement is the size of the tier being
compacted, but that's already expected by its users anyway.
By the time being, all strategies have it unimplemented. so they still
use the old behavior where files are rewritten on at a time.
This will allow us to incrementally implement the cleanup method for
all compaction strategies.
Refs #10097.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
The flat_mutation_reader files were conflated and contained multiple
readers, which were not strictly necessary. Splitting optimizes both
iterative compilation times, as touching rarely used readers doesn't
recompile large chunks of codebase. Total compilation times are also
improved, as the size of flat_mutation_reader.hh and
flat_mutation_reader_v2.hh have been reduced and those files are
included by many file in the codebase.
With changes
real 29m14.051s
user 168m39.071s
sys 5m13.443s
Without changes
real 30m36.203s
user 175m43.354s
sys 5m26.376s
Closes#10194
Instead of lengthy blurbs, switch to single-line, machine-readable
standardized (https://spdx.dev) license identifiers. The Linux kernel
switched long ago, so there is strong precedent.
Three cases are handled: AGPL-only, Apache-only, and dual licensed.
For the latter case, I chose (AGPL-3.0-or-later and Apache-2.0),
reasoning that our changes are extensive enough to apply our license.
The changes we applied mechanically with a script, except to
licenses/README.md.
Closes#9937
This strategy method was introduced unnecessarily. We assume it was
going to be needed, but turns out it was never needed, not even
for ICS. Also it's built on a wrong assumption as an output
sstable run being generated can never be compacted in parallel
as the non-overlapping requirement can be easily broken.
LCS for example can allow parallel compaction on different runs
(levels) but correctness cannto be guaranteed with same runs
are compacted in parallel.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Last method in compaction_strategy using table. From now on,
compaction strategy no longer works directly with table.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
From now on, get_major_compaction_job() will use table_state instead of
a plain reference to table.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
From now on, get_sstables_for_compaction() will use table_state.
With table_state, we avoid layer violations like strategy using
manager and also makes testing easier.
Compaction unit tests were temporarily disabled to avoid a giant
commit which is hard to parse.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
{kind=link}