We switched to using v3 schema tables (in system_schema keyspace) in
2017, in 9eb91bc30b.
So no system should have the old schema any more.
No need to run legacy_schema_migrator on boot.
Closesscylladb/scylladb#27420
When generating CDC log mutations for some base mutation, use a CDC schema that is compatible with the base schema.
The compatible CDC schema has for every base column a corresponding CDC column with the same name. If using a non-compatible schema, we may encounter a situation, especially during ALTER, that we have a mutation with a base column set with some value, but the CDC schema doesn't have a column by that name. This would cause the user request to fail with an error.
We add to the schema object a schema_ptr that for CDC-enabled tables points to the schema object of the CDC table that is compatible with the schema. It is set by the schema merge algorithm when creating the schema for a table that is created or altered. We use the fact that a base table and its CDC table are created and altered in the same group0 operation, and this way we can find and set the cdc schema for a base table.
When transporting the base schema as a frozen schema between shards, we transport with it the frozen cdc schema as well.
The patch starts with a series of refactoring commits that make extending the frozen schema easier and cleans up some duplication in the code about the frozen schema. We combine the two types `frozen_schema_with_base_info` and `view_schema_and_base_info` to a single type `extended_frozen_schema` that holds a frozen schema with additional data that is not part of the schema mutations but needs to be transported with it to unfreeze it - base_info, and the frozen cdc schema which is added in a later commit.
Fixes https://github.com/scylladb/scylladb/issues/26405
backport not needed - enhancement
Closesscylladb/scylladb#24960
* github.com:scylladb/scylladb:
test: cdc: test cdc compatible schema
cdc: use compatiable cdc schema
db: schema_applier: create schema with pointer to CDC schema
db: schema_applier: extract cdc tables
schema: add pointer to CDC schema
schema_registry: remove base_info from global_schema_ptr
schema_registry: use extended_frozen_schema in schema load
schema_registry: replace frozen_schema+base_info with extended_frozen_schema
frozen_schema: extract info from schema_ptr in the constructor
frozen_schema: rename frozen_schema_with_base_info to extended_frozen_schema
Before this commit, when the underlying materialized view was created,
it didn't have the property `tombstone_gc` set to any value. We fix the
bug in this PR.
Implementation strategy:
1. Move code responsible for producing the schema
of a secondary index to the file that handles
`CREATE INDEX`.
2. Set the property when creating the view.
3. Add reproducer tests.
Fixesscylladb/scylladb#26542
Backport: we can discuss it.
Closesscylladb/scylladb#26543
* github.com:scylladb/scylladb:
index: Set tombstone_gc when creating secondary index
index: Make `create_view_for_index` method of `create_index_statement`
index: Move code for creating MV of secondary index to cql3
db, cql3: Move creation of underlying MV for index
When creating a schema for a non-CDC table in the schema_applier, find
its CDC schema that we created previously in the same operation, if any,
and create the schema with a pointer to the CDC schema.
We use the fact that for a base table with CDC enabled, its CDC schema
is created or altered together in the same group0 operation.
Similarly, in schema_tables, when creating table schemas from the
schema tables, first create all schemas that don't have CDC enabled,
then create schemas that have CDC enabled by extending them with the
pointer to the CDC schema that we created before.
There are few additional cases where we create schemas that we need to
consider how to handle.
When loading a schema from schema tables in the schema_loader we decide
not to set the CDC schema, because this schema is mostly used for tools
and it's not used for generating CDC mutations.
When transporting a schema by RPC in the migration manager, we don't
transport its CDC schema, and we always set it to null. Because we use
raft we expect this shouldn't have any effect, because the schema is
synchronized through raft and not through the RPC.
Add to the schema object a member that points to the CDC schema object
that is compatible with this schema, if any.
The compatible CDC schema is created and altered with its base schema in
the same group0 operation.
When generating CDC log mutations for some base mutation we want them to
be created using a compatible schema thas has a CDC column corresponding
to each base column. This change will allow us to find the right CDC
schema given a base mutation.
We also update the relevant structures in the schema registry that are
related to learning about schemas and transporting schemas across
shards or nodes.
When transporting a schema as frozen_schema, we need to transport the
frozen cdc schema as well, and set it again when unfreezing and
reconstructing the schema.
When adding a schema to the registry, we need to ensure its CDC schema
is added to the registry as well.
Currently we always set the CDC schema to nullptr and maintain the
previous behavior. We will change it in a later commit. Until then, we
mark all places where CDC schema is passed clearly so we don't forget
it.
In 380f243986 we added support for rack
lists in replication options. Drivers which are not prepared to parse
that (as of now, all of them), will not create metadata object for
that keyspace. This breaks, for example, the "copy to/from" cqlsh
command. Potentially other things too.
To fix that, keep the "replication" column in the old format, and
store numeric RF there, which corresponds to the number of
replicas. Accurate options in the new format are put in
"replication_v2".
We set replication_v2 in the schema only when it differs from the old
"replication" so that the new column is not set during upgrade,
otherwise downgrade would fail. Partition tombstone is added to ensure
that pre-alter replication_v2 value is deleted on alters which change
replication to a value which is the same as the post-alter
"replication" value.
Fixes#26415Closesscylladb/scylladb#26429
The main goal of this patch is to give more control over the creation
of the underlying view on an index to `create_index_statement.cc`.
That goal is in line with how the other statements are executed:
the schema is built in the cql3 module and only the ready schema_ptr
is passed further. That should also make the code cleaner and easier
to understand.
There are a few important things to note here:
* A call to `service::prepare_new_view_announcement` appears out of nowhere.
Aside from some validation checks and logging, that function does pretty
much the same as the pre-existing code we remove:
a. It creates Raft mutations based on the passed `view_ptr`.
b. It creates Raft mutations responsible for view building tasks.
c. It notifies about a new column family.
* We seemingly get rid of the code that creates view building tasks. That's not
true: we still do that via `service::prepare_new_view_announcement`.
That should explain why the change doesn't remove any relevant logic.
On the other hand, it might be more difficult to explain why moving the
code is correct. I'll touch on it below.
Before that, it may also be important to highlight that this commit only
affects the logic responsible for creating an index. There should be no
effect on any other part of how Scylla behaves.
---
Proving the correctness of the solution would take quite a lot of space,
so I'll only summarize it. It relies on a few things:
1. Two schema changes cannot happen in one operation. We allow for more
but only when those changes are dependent on each other and when
the additional ones are internal for Scylla, e.g. creating an index
leads to creating the underlying materialized view.
2. There are no entities or components that rely on indexes.
3. Each index is uniquely defined by the keyspace it belongs to
and the name of the index.
4. There is a bijection between rows in `system_schema.indexes`
and the currently existing indexes.
5. The name of an unnamed index depends on the name of the base table
and the names of the indexed columns. The name of an unnamed index
may have a number attached to it, but that number only depends on
the state of the schema at the time of creation of the index, and
it never changes later on. There are no other things the name of
an unnamed index depends on.
6. Scylla doesn't allow for changing any column in the base table
that has an index depending on it.
Based on that, we conclude that every existing index has exactly one
entry in `system_schema.indexes`, and the primary key of that entry
never changes.
The columns of `system_schema.indexes` that are not part of the primary
key are: `kind` and `options`. Both values are only decided at the time
of creation of an index, and currently there's no way to modify them.
That implies that there are only two events when an entry in the system
table can change: when creating an index and when dropping an index.
---
When we consider the previous place of the logic that this commit moves
to `cql3/statements/create_index_statement.cc`, it works like this:
1. We compare the sets of indexes defined on a specific table
(in the form of a structure called `index_metadata`) before and
after an operation.
2. We divide the entries into three sets: those present in both sets
and those present in only one of them.
3. We handle each of those three sets separately.
The structure `index_metadata` is a reflection of entries in
`system_schema.indexes`. It stores one more parameter -- `local` --
but its value depends on the other values of an entry, so we can ignore
it in this reasoning.
Because an index cannot be modified -- it can only be created or dropped
-- there are at most two non-empty sets: the set of new indexes and the
set of dropped indexes. Those sets are only non-empty during an operation
like `CREATE INDEX`, `DROP INDEX`, `DROP TABLE (base table)`,
`DROP KEYSPACE`. Note that it's impossible to drop an index by dropping
the underlying materialized view -- Scylla doesn't allow for that.
However, the code in `migration_manager.cc` we call
(`prepare_column_family_update_announcement`) and the code that we call
in `schema_tables.cc` (`make_update_table_mutations`) is only triggered
by *updates* related to the base table. In the context of `DROP TABLE`
or `DROP KEYSPACE`, we'd call `prepare_column_family_drop_announcement`
instead. In other words, we're only concerned with `CREATE INDEX` and
`DROP INDEX`.
---
A conclusion from this reasoning is that we only need to consider those
two situations when talking about correctness of this change. The impact
of this commit is that we may have potentially reordered mutations in the
resulting vector that will be applied to the Raft log.
The only mutations we may have reordered are the mutations responsible for
creating the underlying view and the mutations responsible for updating
columns in the base table. It's clear then that this commit brings no change
at all: we only give `cql3/statements/create_index_statement.cc` more
control over creating the underlying view.
---
We leave a remnant of the code in `db/schema_tables.cc` responsible
for dropping an index along with its underlying view. It would require
changing a bit more of the logic, and we don't need it for the rest
of this sequence of changes.
Refs scylladb/scylladb#16454
The series adds an experimental flag for strongly consistent tables and extends "CREATE KEYSPACE" ddl with `consistency` option that allows specifying the consistency mode for the keyspace.
Closesscylladb/scylladb#26116
* github.com:scylladb/scylladb:
schema: Allow configuring consistency setting for a keyspace
db: experimental consistent-tablets option
We want to add strongly consistent tables as an option. We will have
two kind of strongly consistent tables: globally consistent and locally
consistent. The former means that requests from all DCs will be globally
linearisable while the later - only requests to the same DCs will be
linearisable. To allow configuring all the possibilities the patch
adds new parameter to a keyspace definition "consistency" that can be
configured to be `eventual`, `global` or `local`. Non eventual setting
is supported for tablets enabled keyspaces only. Since we want to start
with implementing local consistency configuring global consistency will
result in an error for now.
Allows per-DC replication factor to be either a string, holding a
numerical value, or a list of strings, holding a list of rack names.
The rack list is not respected yet by the tablet allocator, this is
achieved in subsequent commit.
This changes the format of options stored in the flattened map
in system_schema.keyspaces#replication. Values which are rack lists,
are converted into multiple entries, with the list index appended to
the key with ':' as the separator:
For example, this extended map:
{
'dc1': '3',
'dc2': ['rack1', 'rack2']
}
is stored as a flattened map:
{
'dc1': '3',
'dc2:0': 'rack1',
'dc2:1': 'rack2'
}
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Signed-off-by: Tomasz Grabiec <tgrabiec@scylladb.com>
In preparation for changing their structure.
1) std::map<sstring, sstring> -> replication_strategy_config_options
Parsed options. Values will become std::variant<sstring, rack_list>
2) std::map<sstring, sstring> -> property_definitions::map_type
Flattened map of options, as stored system tables.
Currently, the function unfreezes each schema mutation partition
and then checks if it's for a system keyspace.
This isn't really needed since we can check the partition key
using the frozen_mutation, skip it if the partition is for a system keyspace.
Note that the constructed partition_key just copies
the frozen partition_key_view, without copying or deserializing the
actual key contents.
Also, reserve `results` capacity using the queried
partitions' size to prevent reallocations of the results
vector.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
The namespace usage in this directory is very inconsistent, with files
and classes scattered in:
* global namespace
* namespace compaction
* namespace sstables
With cases, where all three used in the same file. This code used to
live in sstables/ and some of it still retains namespace sstables as a
heritage of that time. The mismatch between the dir (future module) and
the namespace used is confusing, so finish the migration and move all
code in compaction/ to namespace compaction too.
This patch, although large, is mechanic and only the following kind of
changes are made:
* replace namespace sstable {} with namespace compaction {}
* add namespace compaction {}
* drop/add sstables::
* drop/add compaction::
* move around forward-declarations so they are in the correct namespace
context
This refactoring revealed some awkward leftover coupling between
sstables and compaction, in sstables/sstable_set.cc, where the
make_sstable_set() methods of compaction strategies are implemented.
The latter is recommended in seastar, and the former was left as
compatibility alias. Latest seastar explicitly marks it as deprecated so
once the submodule is updated, compilation logs will explode.
Most of the patch is generated with
for f in $(git grep -l '\<distributed<[A-Za-z0-9:_]*>') ; do sed -e 's/\<distributed<\([A-Za-z0-9:_]*\)>/sharded<\1>/g' -i $f; done
for f in $(git grep -l distributed.hh); do sed -e 's/distributed.hh/sharded.hh/' -i $f ; done
and a small manual change in test/perf/perf.hh
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Closesscylladb/scylladb#26136
As requested in #22120, moved the files and fixed other includes and build system.
Moved files:
- query.cc
- query-request.hh
- query-result.hh
- query-result-reader.hh
- query-result-set.cc
- query-result-set.hh
- query-result-writer.hh
- query_id.hh
- query_result_merger.hh
Fixes: #22120
This is a cleanup, no need to backport
Closesscylladb/scylladb#25105
Add parsing of `ANN OF` queries to the `select_statement` and
`indexed_table_select_statement` classes.
Add a placeholder for the implementation of external ANN queries.
Rename `should_create_view` to `view_should_exist` as it is used
not only to check if the view should be created but also if
the view has been created.
Co-authored-by: Dawid Pawlik <dawid.pawlik@scylladb.com>
As requested in #22114, moved the files and fixed other includes and build system.
Moved files:
- interval.hh
- Map_difference.hh
Fixes: #22114
This is a cleanup, no need to backport
Closesscylladb/scylladb#25095
This PR adds a way for custom indexes to decide whether a view should be created for them, as for the vector_index the view is not needed, because we store it in the external service. To allow this, custom logic for describing indexes using custom classes was added (as it used to depend on the view corresponding to an index).
Fixes: VECTOR-10
Closesscylladb/scylladb#24438
* github.com:scylladb/scylladb:
custom_index: do not create view when creating a custom index
custom_index: refactor describe for custom indexes
custom_index: remove unneeded duplicate of a static string
This change is preparing ground for state update unification for raft bound subsystems. It introduces schema_applier which in the future will become generic interface for applying mutations in raft.
Pulling database::apply() out of schema merging code will allow to batch changes to subsystems. Future generic code will first call prepare() on all implementations, then single database::apply() and then update() on all implementations, then on each shard it will call commit() for all implementations, without preemption so that the change is observed as atomic across all subsystems, and then post_commit().
Backport: no, it's a new feature
Fixes: https://github.com/scylladb/scylladb/issues/19649
Fixes https://github.com/scylladb/scylladb/issues/24531Closesscylladb/scylladb#24886
[avi: adjust for std::vector<mutations> -> utils::chunked_vector<mutations>]
* github.com:scylladb/scylladb:
test: add type creation to test_snapshot
storage_service: always wake up load balancer on update tablet metadata
db: schema_applier: call destroy also when exception occurs
db: replica: simplify seeding ERM during shema change
db: remove cleanup from add_column_family
db: abort on exception during schema commit phase
db: make user defined types changes atomic
replica: db: make keyspace schema changes atomic
db: atomically apply changes to tables and views
replica: make truncate_table_on_all_shards get whole schema from table_shards
service: split update_tablet_metadata into two phases
service: pull out update_tablet_metadata from migration_listener
db: service: add store_service dependency to schema_applier
service: simplify load_tablet_metadata and update_tablet_metadata
db: don't perform move on tablet_hint reference
replica: split add_column_family_and_make_directory into steps
replica: db: split drop_table into steps
db: don't move map references in merge_tables_and_views()
db: introduce commit_on_shard function
db: access types during schema merge via special storage
replica: make non-preemptive keyspace create/update/delete functions public
replica: split update keyspace into two phases
replica: split creating keyspace into two functions
db: rename create_keyspace_from_schema_partition
db: decouple functions and aggregates schema change notification from merging code
db: store functions and aggregates change batch in schema_applier
db: decouple tables and views schema change notifications from merging code
db: store tables and views schema diff in schema_applier
db: decouple user type schema change notifications from types merging code
service: unify keyspace notification functions arguments
db: replica: decouple keyspace schema change notifications to a separate function
db: add class encapsulating schema merging
The same order of creation/destruction is preserved as in the
original code, looking from single shard point of view.
create_types() is called on each shard separately, while in theory
we should be able reuse results similarly as diff_rows(). But we
don't introduce this optimization yet.
Once we create types atomically the code which is before commit
may depend on newly added types, so it has to access both old and
new types. New storage called in_progress_types_storage was added.
Currently we create a view for every index, however
for currently supported custom index classes (vector_index)
that work is redundant, as we store the index in the external
service.
This patch adds a way for custom indexes to choose whether to
create a view when creating the index and makes it so that
for vector indexes the view is not created.
This reverts commit 0b516da95b, reversing
changes made to 30199552ac. It breaks
cluster.random_failures.test_random_failures.test_random_failures
in debug mode (at least).
Fixes#24513
Once we create types atomically the code which is before commit
may depend on newly added types, so it has to access both old and
new types. New storage called in_progress_types_storage was added.
Blobs can be large, and unfragmented blobs can easily exceed 128k
(as seen in #23903). Rename get_blob() to get_blob_unfragmented()
to warn users.
Note that most uses are fine as the blobs are really short strings.
Closesscylladb/scylladb#24102
In the following patch we plan to remove the base schema from the base_info
to make the base_info immutable. To do that, we first prepare the schema
registry for the change; we need to be able to create view schemas from
frozen schemas there and frozen schemas have no information about the base
table. Unless we do this change, after base schemas are removed from the
base info, we'll no longer be able to load a view schema to the schema registry
without looking up the base schema in the database.
This change also required some updates to schema building:
* we add a method for unfreezing a view schema with base info instead of
a base schema
* we make it possible to use schema_builder with a base info instead of
a base schema
* we add a method for creating a view schema from mutations with a base info
instead of a base schema
* we add a view_info constructor withat base info instead of a base schema
* we update the naming in schema_registry to reflect the usage of base info
instead of base schema
Currently, the base_info may or may not be set in view schemas.
Even when it's set, it may be modified. This necessitates extra
checks when handling view schemas, as well as potentially causing
errors when we forget to set it at some point.
Instead, we want to make the base info an immutable member of view
schemas (inside view_info). The first step towards that is making
sure that all newly created schemas have the base info set.
We achieve that by requiring a base schema when constructing a view
schema. Unfortunately, this adds complexity each time we're making
a view schema - we need to get the base schema as well.
In most cases, the base schema is already available. The most
problematic scenario is when we create a schema from mutations:
- when parsing system tables we can get the schema from the
database, as regular tables are parsed before views
- when loading a view schema using the schema loader tool, we need
to load the base additionally to the view schema, effectively
doubling the work
- when pulling the schema from another node - in this case we can
only get the current version of the base schema from the local
database
Additionally, we need to consider the base schema version - when
we generate view updates the version of the base schema used for
reads should match the version of the base schema in view's base
info.
This is achieved by selecting the correct (old or new) schema in
`db::schema_tables::merge_tables_and_views` and using the stored
base schema in the schema_registry.
schema_extension allows making invisible changes to system_schema
that evade upgrade rollback tests. They appear in system_schema
as an encoded blob which reduces serviceability, as they cannot
be read.
Deprecate it and point users to adding explicit columns in scylla_tables.
We could probably make use of the data structure, after we teach it
to encode its payload into proper named and typed columns instead of
using IDL.
Closesscylladb/scylladb#23151
There are few more places left that can use all_table_infos() as a
replacement for all_table_names(), patch them.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
There are convert_schema_to_mutations() and calculate_schema_digest()
that collect table names and then use them to find schema and query
mutations from the table.
Both can use the newly introduced all_table_infos() and use the returned
table_id-s to do the same, thus avoiding re-lookups (which are fast
anyway, but still).
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
This method is like all_table_names(), but returns a vector of
table_info-s which is effectively a pair of string name and uuid id.
To be used later, and the string-returning all_table_name() will be
removed very soon too.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
result_set_row is a heavyweight object containing multiple cell types:
regular columns, partition keys, and static values. To prevent expensive
accidental copies, delete the copy constructor and replace it with:
1. A move constructor for efficient vector reallocation
2. An explicit copy() method when copies are actually needed
This change reduces overhead in some non-hot paths by eliminating implicit
deep copies. Please note, previously, in `create_view_from_mutation()`,
we kept a copy of `result_set_row`, and then reused `table_rs` for
holding the mutation for `scylla_tables`. Because we don't copy
the `result_set_row` in this change, in order to avoid invalidating
the `row` after reusing `table_rs` in the outer scope, we define a
new `table_rs` shadowing the one in the out scope.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22741
This series extends the table schema with per-table tablet options.
The options are used as hints for initial tablet allocation on table creation and later for resize (split or merge) decisions,
when the table size changes.
* New feature, no backport required
Closesscylladb/scylladb#22090
* github.com:scylladb/scylladb:
tablets: resize_decision: get rid of initial_decision
tablet_allocator: consider tablet options for resize decision
tablet_allocator: load_balancer: table_size_desc: keep target_tablet_size as member
network_topology_strategy: allocate_tablets_for_new_table: consider tablet options
network_topology_strategy: calculate_initial_tablets_from_topology: precalculate shards per dc using for_each_token_owner
network_topology_strategy: calculate_initial_tablets_from_topology: set default rf to 0
cql3: data_dictionary: format keyspace_metadata: print "enabled":true when initial_tablets=0
cql3/create_keyspace_statement: add deprecation warning for initial tablets
test: cqlpy: test_tablets: add tests for per-table tablet options
schema: add per-table tablet options
feature_service: add TABLET_OPTIONS cluster schema feature
Unlike with vnodes, each tablet is served only by a single
shard, and it is associated with a memtable that, when
flushed, it creates sstables which token-range is confined
to the tablet owning them.
On one hand, this allows for far better agility and elasticity
since migration of tablets between nodes or shards does not
require rewriting most if not all of the sstables, as required
with vnodes (at the cleanup phase).
Having too few tablets might limit performance due not
being served by all shards or by imbalance between shards
caused by quantization. The number of tabelts per table has to be
a power of 2 with the current design, and when divided by the
number of shards, some shards will serve N tablets, while others
may serve N+1, and when N is small N+1/N may be significantly
larger than 1. For example, with N=1, some shards will serve
2 tablet replicas and some will serve only 1, causing an imbalance
of 100%.
Now, simply allocating a lot more tablets for each table may
theoretically address this problem, but practically:
a. Each tablet has memory overhead and having too many tablets
in the system with many tables and many tablets for each of them
may overwhelm the system's and cause out-of-memory errors.
b. Too-small tablets cause a proliferation of small sstables
that are less efficient to acces, have higher metadata overhead
(due to per-sstable overhead), and might exhaust the system's
open file-descriptors limitations.
The options introduced in this change can help the user tune
the system in two ways:
1. Sizing the table to prevent unnecessary tablet splits
and migrations. This can be done when the table is created,
or later on, using ALTER TABLE.
2. Controlling min_per_shard_tablet_count to improve
tablet balancing, for hot tables.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
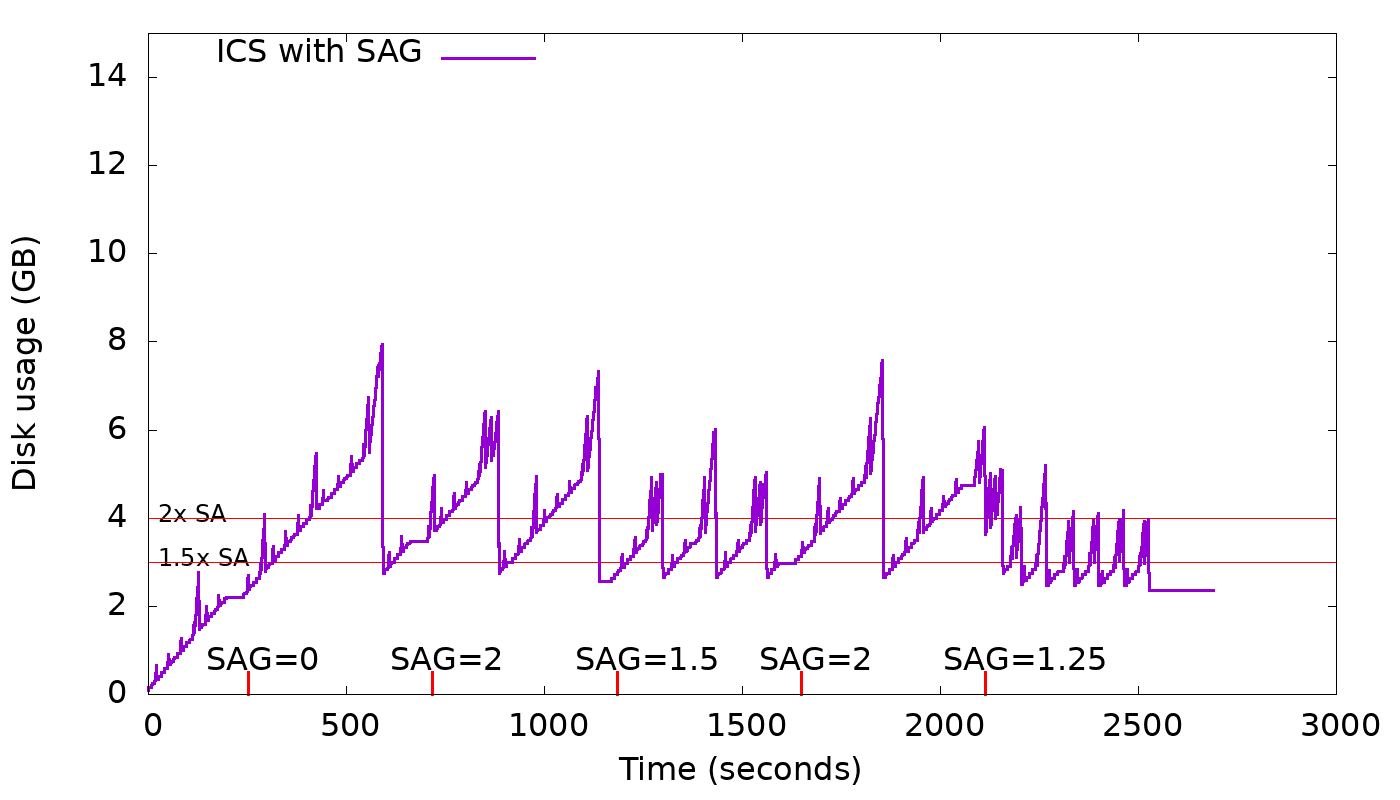
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
now that we are allowed to use C++23. we now have the luxury of using
`std::views::transform`.
in this change, we:
- replace `boost::adaptors::transformed` with `std::views::transform`
- use `fmt::join()` when appropriate where `boost::algorithm::join()`
is not applicable to a range view returned by `std::view::transform`.
- use `std::ranges::fold_left()` to accumulate the range returned by
`std::view::transform`
- use `std::ranges::fold_left()` to get the maximum element in the
range returned by `std::view::transform`
- use `std::ranges::min()` to get the minimal element in the range
returned by `std::view::transform`
- use `std::ranges::equal()` to compare the range views returned
by `std::view::transform`
- remove unused `#include <boost/range/adaptor/transformed.hpp>`
- use `std::ranges::subrange()` instead of `boost::make_iterator_range()`,
to feed `std::views::transform()` a view range.
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
limitations:
there are still a couple places where we are still using
`boost::adaptors::transformed` due to the lack of a C++23 alternative
for `boost::join()` and `boost::adaptors::uniqued`.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21700
Once e.g. `ALTER KEYSPACE` is performed, all in-memory objects should be updated accordingly, but this is not entirely true for keyspace metadata object. The reason for that is that keyspace metadata are stored in 2 system tables: `system_schema.keyspaces` and `system_schema.scylla_keyspaces`. Up until now the in-memory keyspace metadata object has been updated only with entries from the first table, and missed updates when entries from the 2nd table changed. These entries were e.g. initial tablets or storage options.
This change fixes this oversight by considering both tables when checking if keyspace metadata need to be updated. From the implementation point of view, the change is simple: we're considering `system_schema.scylla_keyspaces` also in `merge_keyspaces()` and if old and new schemas have any differences, we include that when altering ks.
Fixes#20768
Backport: no need, I don't think the issue is severe, atm it seems like it can only influence the tablets number, which should not bring the cluster down nor result in returning bad data, it can mostly influence the speed of the db.
Closesscylladb/scylladb#20852
This depends on the previous change to the schema_builder
which makes version computation depend on definition only
instead of being new time uuid.
This way we avoid the possibility for a common mistake
when schema of a system table is extended but we forget
to bump up its version passed to .with_version().
now that we are allowed to use C++23. we now have the luxury of using
`std::views::values`.
in this change, we:
- replace `boost::adaptors::map_values` with `std::views::values`
- update affected code to work with `std::views::values`
- the places where we use `boost::join()` are not changed, because
we cannot use `std::views::concat` yet. this helper is only
available in C++26.
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21265
It's somewhat common to ask for the partition key and clustering key
columns, or for the static and regular columsn. Provide accessors for them
rather than requiring the user to glue them.
Some callers are converted.
Closesscylladb/scylladb#21191
{kind=link}