Moves the config wrapper to own file (to reduce recompilation for modifying)
and refactors to handle extending this parameter to non-s3 endpoint configs.
This change is preparing ground for state update unification for raft bound subsystems. It introduces schema_applier which in the future will become generic interface for applying mutations in raft.
Pulling database::apply() out of schema merging code will allow to batch changes to subsystems. Future generic code will first call prepare() on all implementations, then single database::apply() and then update() on all implementations, then on each shard it will call commit() for all implementations, without preemption so that the change is observed as atomic across all subsystems, and then post_commit().
Backport: no, it's a new feature
Fixes: https://github.com/scylladb/scylladb/issues/19649
Fixes https://github.com/scylladb/scylladb/issues/24531Closesscylladb/scylladb#24886
[avi: adjust for std::vector<mutations> -> utils::chunked_vector<mutations>]
* github.com:scylladb/scylladb:
test: add type creation to test_snapshot
storage_service: always wake up load balancer on update tablet metadata
db: schema_applier: call destroy also when exception occurs
db: replica: simplify seeding ERM during shema change
db: remove cleanup from add_column_family
db: abort on exception during schema commit phase
db: make user defined types changes atomic
replica: db: make keyspace schema changes atomic
db: atomically apply changes to tables and views
replica: make truncate_table_on_all_shards get whole schema from table_shards
service: split update_tablet_metadata into two phases
service: pull out update_tablet_metadata from migration_listener
db: service: add store_service dependency to schema_applier
service: simplify load_tablet_metadata and update_tablet_metadata
db: don't perform move on tablet_hint reference
replica: split add_column_family_and_make_directory into steps
replica: db: split drop_table into steps
db: don't move map references in merge_tables_and_views()
db: introduce commit_on_shard function
db: access types during schema merge via special storage
replica: make non-preemptive keyspace create/update/delete functions public
replica: split update keyspace into two phases
replica: split creating keyspace into two functions
db: rename create_keyspace_from_schema_partition
db: decouple functions and aggregates schema change notification from merging code
db: store functions and aggregates change batch in schema_applier
db: decouple tables and views schema change notifications from merging code
db: store tables and views schema diff in schema_applier
db: decouple user type schema change notifications from types merging code
service: unify keyspace notification functions arguments
db: replica: decouple keyspace schema change notifications to a separate function
db: add class encapsulating schema merging
It's not a good usage as there is only one non-empty implementation.
Also we need to change it further in the following commit which
makes it incompatible with listener code.
This reverts commit 0b516da95b, reversing
changes made to 30199552ac. It breaks
cluster.random_failures.test_random_failures.test_random_failures
in debug mode (at least).
Fixes#24513
This change is preparing ground for state update unification for raft bound subsystems. It introduces schema_applier which in the future will become generic interface for applying mutations in raft.
Pulling `database::apply()` out of schema merging code will allow to batch changes to subsystems. Future generic code will first call `prepare()` on all implementations, then single `database::apply()` and then `update()` on all implementations, then on each shard it will call `commit()` for all implementations, without preemption so that the change is observed as atomic across all subsystems, and then `post_commit()`.
Backport: no, it's a new feature
Fixes: https://github.com/scylladb/scylladb/issues/19649Closesscylladb/scylladb#20853
* github.com:scylladb/scylladb:
storage_service: always wake up load balancer on update tablet metadata
db: schema_applier: call destroy also when exception occurs
db: replica: simplify seeding ERM during shema change
db: remove cleanup from add_column_family
db: abort on exception during schema commit phase
db: make user defined types changes atomic
replica: db: make keyspace schema changes atomic
db: atomically apply changes to tables and views
replica: make truncate_table_on_all_shards get whole schema from table_shards
service: split update_tablet_metadata into two phases
service: pull out update_tablet_metadata from migration_listener
db: service: add store_service dependency to schema_applier
service: simplify load_tablet_metadata and update_tablet_metadata
db: don't perform move on tablet_hint reference
replica: split add_column_family_and_make_directory into steps
replica: db: split drop_table into steps
db: don't move map references in merge_tables_and_views()
db: introduce commit_on_shard function
db: access types during schema merge via special storage
replica: make non-preemptive keyspace create/update/delete functions public
replica: split update keyspace into two phases
replica: split creating keyspace into two functions
db: rename create_keyspace_from_schema_partition
db: decouple functions and aggregates schema change notification from merging code
db: store functions and aggregates change batch in schema_applier
db: decouple tables and views schema change notifications from merging code
db: store tables and views schema diff in schema_applier
db: decouple user type schema change notifications from types merging code
service: unify keyspace notification functions arguments
db: replica: decouple keyspace schema change notifications to a separate function
db: add class encapsulating schema merging
It's not a good usage as there is only one non-empty implementation.
Also we need to change it further in the following commit which
makes it incompatible with listener code.
CQLv5 introduced metadata_id, which is a checksum computed from column
names and types, to track schema changes in prepared statements. This
commit introduces calculate_metadata_id to compute such id for given
metadata.
Please note that calculate_metadata_id() produces different hashes
than Cassandra's computeResultMetadataId(). We use SHA256 truncated to
128 bits instead of MD5. There are also two smaller technical
differences: calculate_metadata_id() doesn't add unneeded zeros and it
adds a length of a string when an sstring is being fed to the hasher.
The difference is intentional because MD5 has known vulnerabilities,
moreover we don't want to introduce any dependency between our
metadata_id and Cassandra's.
This change:
- Add cql_metadata_id_type
- Implement metadata::calculate_metadata_id()
- Add boost tests to confirm correctness of the function
That map became redundant once we added
object_storage_endpoints in the config, this patch removes
it and switches all the user code to use the new option.
Signed-off-by: Robert Bindar <robert.bindar@scylladb.com>
Replace boost::copy() with the standard library's std::ranges::copy()
to reduce external dependencies and simplify the codebase. This change
eliminates the requirement for boost::range and makes the implementation
more maintainable.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22789
Unlike with vnodes, each tablet is served only by a single
shard, and it is associated with a memtable that, when
flushed, it creates sstables which token-range is confined
to the tablet owning them.
On one hand, this allows for far better agility and elasticity
since migration of tablets between nodes or shards does not
require rewriting most if not all of the sstables, as required
with vnodes (at the cleanup phase).
Having too few tablets might limit performance due not
being served by all shards or by imbalance between shards
caused by quantization. The number of tabelts per table has to be
a power of 2 with the current design, and when divided by the
number of shards, some shards will serve N tablets, while others
may serve N+1, and when N is small N+1/N may be significantly
larger than 1. For example, with N=1, some shards will serve
2 tablet replicas and some will serve only 1, causing an imbalance
of 100%.
Now, simply allocating a lot more tablets for each table may
theoretically address this problem, but practically:
a. Each tablet has memory overhead and having too many tablets
in the system with many tables and many tablets for each of them
may overwhelm the system's and cause out-of-memory errors.
b. Too-small tablets cause a proliferation of small sstables
that are less efficient to acces, have higher metadata overhead
(due to per-sstable overhead), and might exhaust the system's
open file-descriptors limitations.
The options introduced in this change can help the user tune
the system in two ways:
1. Sizing the table to prevent unnecessary tablet splits
and migrations. This can be done when the table is created,
or later on, using ALTER TABLE.
2. Controlling min_per_shard_tablet_count to improve
tablet balancing, for hot tables.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
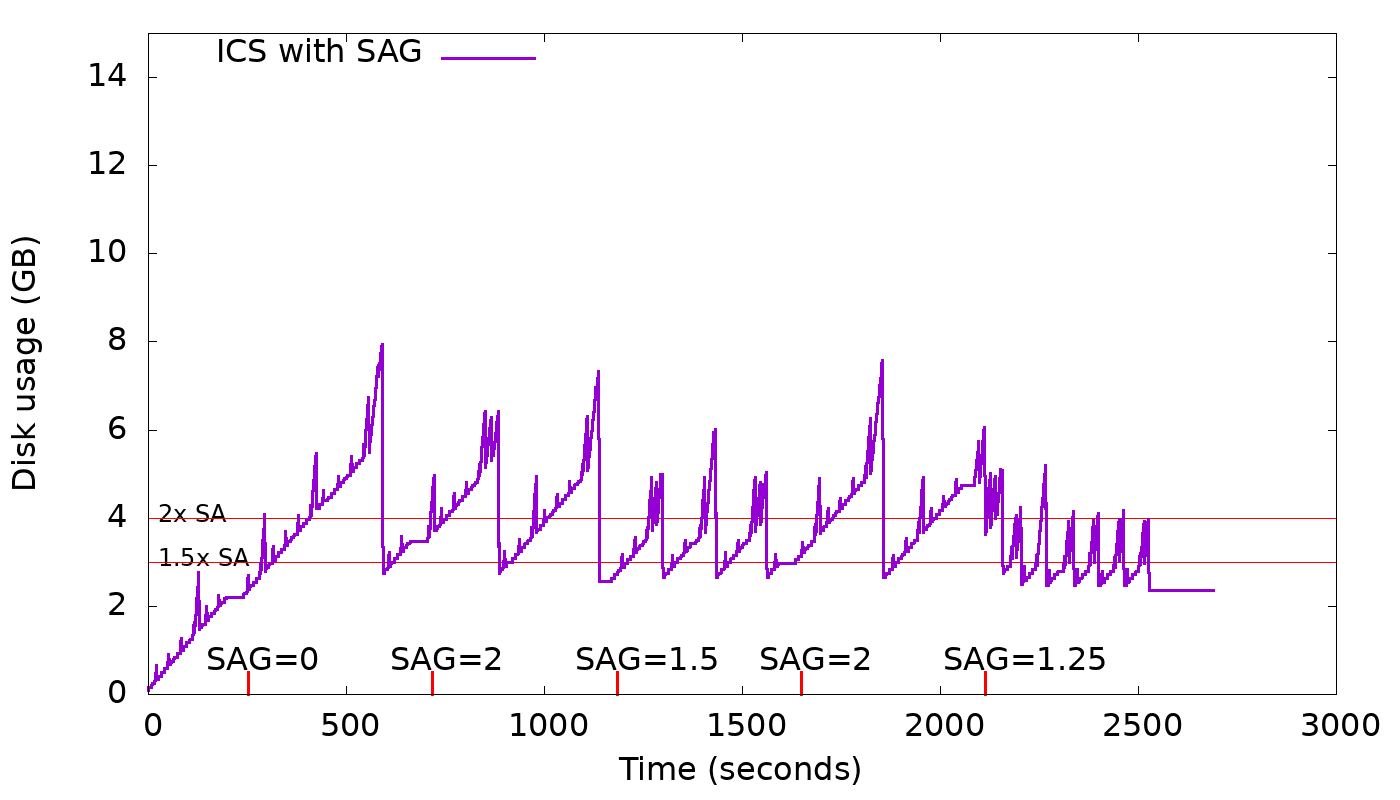
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
To reduce test executable size and speed up compilation time, compile unit
tests into a single executable.
Here is a file size comparison of the unit test executable:
- Before applying the patch
$ du -h --exclude='*.o' --exclude='*.o.d' build/release/test/boost/ build/debug/test/boost/
11G build/release/test/boost/
29G build/debug/test/boost/
- After applying the patch
du -h --exclude='*.o' --exclude='*.o.d' build/release/test/boost/ build/debug/test/boost/
5.5G build/release/test/boost/
19G build/debug/test/boost/
It reduces executable sizes 5.5GB on release, and 10GB on debug.
Closes#9155Closesscylladb/scylladb#21443
This depends on the previous change to the schema_builder
which makes version computation depend on definition only
instead of being new time uuid.
This way we avoid the possibility for a common mistake
when schema of a system table is extended but we forget
to bump up its version passed to .with_version().
To reduce the dependency load, replace use of boost ranges
with the std equivalent.
Files that lost the indirect boost dependency have it added as a
direct dependency.
The hint contains information related to what exactly changed, allowing
listeners to do partial updates, instead of reloading all metadata on
each notification.
thrift support was deprecated since ScyllaDB 5.2
> Thrift API - legacy ScyllaDB (and Apache Cassandra) API is
> deprecated and will be removed in followup release. Thrift has
> been disabled by default.
so let's drop it. in this change,
* thrift protocol support is dropped
* all references to thrift support in document are dropped
* the "thrift_version" column in system.local table is
preserved for backward compatibility, as we could load
from an existing system.local table which still contains
this clolumn, so we need to write this column as well.
* "/storage_service/rpc_server" is only preserved for
backward compatibility with java-based nodetool.
* `rpc_port` and `start_rpc` options are preserved, but
they are marked as "Unused". so that the new release
of scylladb can consume existing scylla.yaml configurations
which might contain these settings. by making them
deprecated, user will be able get warned, and update
their configurations before we actually remove them
in the next major release.
Fixes#3811Fixes#18416
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
The PER_TABLE_PARTITIONERS feature was added in 90df9a44ce (2020; 4.0)
and can now be assumed to be always present. We also remove the associated
schema_feature.
The first digest tested was generated without the PER_TABLE_PARTITIONERS
schema feature. We're about to make that feature mandatory, so we won't
be able (and won't need) to generate a digest without it.
Update the digest to include the feature. Note it wasn't untested before,
we have a test with schema_features::full().
The VIEW_VIRTUAL_COLUMNS feature was added in a108df09f9 (2019; 3.1)
and can now be assumed to be always present.
The corresponding schema_feature is removed. Note schema_features are not sent
over the wire. A digest calculation without VIEW_VIRTUAL_COLUMNS is no longer tested.
In the following commit, we make the `consistent-topology-changes`
experimental feature unused. Then, all unit tests in the boost suite
will start using the raft-based topology by default. Unfortunately,
tests with multiple `single_node_cql_env::run_in_thread` calls
(usually coming from the `do_with_cql_env_thread` calls) would fail.
In a noninitial `run_in_thread` call, a node is started as if it
booted for the first time. On the other hand, it has its persistent
state from previous boots. Hence, the node can behave strangely and
unexpectedly. In particular, `SYSTEM.TOPOLOGY` is not empty and the
assertion that expects it to be empty when we boot for the first
time fails.
We fix this issue by making noninitial `run_in_thread` calls
behave as normal restarts.
After this change,
`test_schema_digest_does_not_change_with_disabled_features` starts
failing. This test copies the data directory before booting for the
first time, so the new
`_sys_ks.local().build_bootstrap_info().get();` makes the node
incorrectly think it restarts. Then, after noticing it is not a part
of group 0, the node would start the raft upgrade procedure if we
didn't run it in the raft RECOVERY mode. This procedure would get
stuck because it depends on messaging being enabled even if the node
communicates only with itself and messaging is disabled in boost tests.
before this change, we rely on the default-generated fmt::formatter
created from operator<<, but fmt v10 dropped the default-generated
formatter.
in this change, we include `fmt/ranges.h` and/or `fmt/std.h`
for formatting the container types, like vector, map
optional and variant using {fmt} instead of the homebrew
formatter based on operator<<.
with this change, the changes adding fmt::formatter and
the changes using ostream formatter explicitly, we are
allowed to drop `FMT_DEPRECATED_OSTREAM` macro.
Refs scylladb#13245
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
get0() dates back from the days where Seastar futures carried tuples, and
get0() was a way to get the first (and usually only) element. Now
it's a distraction, and Seastar is likely to deprecate and remove it.
Replace with seastar::future::get(), which does the same thing.
Code that executed only when consistent_cluster_management=false is
removed. In particular, after this patch:
- raft_group0 and raft_group_registry are always enabled,
- raft_group0::status_for_monitoring::disabled becomes unused,
- topology tests can only run with consistent_cluster_management.
In the following commits, we make consistent cluster management
mandatory. This will make disable_raft_schema_config unusable,
so we need to get rid of it. However, we don't want to remove
tests that use it.
The idea is to use the Raft RECOVERY mode instead of disabling
consistent cluster management directly.
As promised in earlier commits:
Fixes: #7620Fixes: #13957
Also modify two test cases in `schema_change_test` which depend on
the digest calculation method in their checks. Details are explained in
the comments.
Now its plain updateable_value, but without the ..._source object the
updateable_value is just a no-op value holder. In order for the
observers to operate there must be the value source, updating it would
update the attached updateable values _and_ notify the observers.
In order for the config to be the u.v._source, config entries should be
comparable to each other, thus the <=> operator for it
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Sstables in transitional states are marked with the respective 'status' in the registry. Currently there are two of such -- 'creating' and 'removing'. And the 'sealed' status for sstables in use.
On boot the distributed loader tries to garbage collect the dangling sstables. For filesystem storage it's done with the help of temorary sstables' dirs and pending deletion logs. For s3-backed sstables, the garbage collection means fetching all non-sealed entries and removing the corresponding objects from the storage.
Test included (last patch)
fixes#13024Closesscylladb/scylladb#15318
* github.com:scylladb/scylladb:
test: Extend object_store test to validate GC works
sstable_directory: Garbage collect S3 sstables on reboot
sstable_directory: Pass storage to garbage_collect()
sstable_directory: Create storage instance too
As promised in earlier commits:
Fixes: #7620Fixes: #13957
Also modify two test cases in `schema_change_test` which depend on
the digest calculation method in their checks. Details are explained in
the comments.
Right now the directory instance only creates lister, but lister is
unaware on exact objects manipulations. The storage is, so create it
too, it's going to be used by garbage collector in next patches
This change also needs fixing the way cql_test_env is configured for
schema_change_test. There are cases that try to pick up keyspace with S3
storage option from the pre-created sstables, and populating those would
need to provide some (even empty) object storage endpoint
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
In the next commit, we remove the default value for the
description parameter of migration_manager::announce to avoid
using it in the future. However, many calls to announce in tests
use the default value. We have to change it, but we don't really
care about descriptions in the tests, so we pass the empty string
everywhere.
The `migration_manager` service is responsible for schema convergence in
the cluster - pushing schema changes to other nodes and pulling schema
when a version mismatch is observed. However, there is also a part of
`migration_manager` that doesn't really belong there - creating
mutations for schema updates. These are the functions with `prepare_`
prefix. They don't modify any state and don't exchange any messages.
They only need to read the local database.
We take these functions out of `migration_manager` and make them
separate functions to reduce the dependency of other modules (especially
`query_processor` and CQL statements) on `migration_manager`. Since all
of these functions only need access to `storage_proxy` (or even only
`replica::database`), doing such a refactor is not complicated. We just
have to add one parameter, either `storage_proxy` or `database` and both
of them are easily accessible in the places where these functions are
called.
This refactor makes `migration_manager` unneeded in a few functions:
- `alternator::executor::create_keyspace`,
- `cql3::statements::alter_type_statement::prepare_announcement_mutations`,
- `cql3::statements::schema_altering_statement::prepare_schema_mutations`,
- `cql3::query_processor::execute_thrift_schema_command:`,
- `thrift::handler::execute_schema_command`.
We remove the `migration_manager&` parameter from all these functions.
Fixes#14339Closes#14875
* github.com:scylladb/scylladb:
cql3: query_processor::execute_thrift_schema_command: remove an unused parameter
cql3: schema_altering_statement::prepare_schema_mutations: remove an unused parameter
cql3: alter_type_statement::prepare_announcement_mutations: change parameters
alternator: executor::create_keyspace: remove an unused parameter
service: migration_manager: change the prepare_ methods to functions
The migration_manager service is responsible for schema convergence
in the cluster - pushing schema changes to other nodes and pulling
schema when a version mismatch is observed. However, there is also
a part of migration_manager that doesn't really belong there -
creating mutations for schema updates. These are the functions with
prepare_ prefix. They don't modify any state and don't exchange any
messages. They only need to read the local database.
We take these functions out of migration_manager and make them
separate functions to reduce the dependency of other modules
(especially query_processor and CQL statements) on
migration_manager. Since all of these functions only need access
to storage_proxy (or even only replica::database), doing such a
refactor is not complicated. We just have to add one parameter,
either storage_proxy or database and both of them are easily
accessible in the places where these functions are called.
Schema digest is calculated by querying for mutations of all schema
tables, then compacting them so that all tombstones in them are
dropped. However, even if the mutation becomes empty after compaction,
we still feed its partition key. If the same mutations were compacted
prior to the query, because the tombstones expire, we won't get any
mutation at all and won't feed the partition key. So schema digest
will change once an empty partition of some schema table is compacted
away.
Tombstones expire 7 days after schema change which introduces them. If
one of the nodes is restarted after that, it will compute a different
table schema digest on boot. This may cause performance problems. When
sending a request from coordinator to replica, the replica needs
schema_ptr of exact schema version request by the coordinator. If it
doesn't know that version, it will request it from the coordinator and
perform a full schema merge. This adds latency to every such request.
Schema versions which are not referenced are currently kept in cache
for only 1 second, so if request flow has low-enough rate, this
situation results in perpetual schema pulls.
After ae8d2a550d, it is more liekly to
run into this situation, because table creation generates tombstones
for all schema tables relevant to the table, even the ones which
will be otherwise empty for the new table (e.g. computed_columns).
This change inroduces a cluster feature which when enabled will change
digest calculation to be insensitive to expiry by ignoring empty
partitions in digest calculation. When the feature is enabled,
schema_ptrs are reloaded so that the window of discrepancy during
transition is short and no rolling restart is required.
A similar problem was fixed for per-node digest calculation in
18f484cc753d17d1e3658bcb5c73ed8f319d32e8. Per-table digest calculation
was not fixed at that time because we didn't persist enabled features
and they were not enabled early-enough on boot for us to depend on
them in digest calculation. Now they are enabled before non-system
tables are loaded so digest calculation can rely on cluster features.
Fixes#4485.
As described in https://github.com/scylladb/scylladb/issues/8638,
we're moving away from `SimpleStrategy`, in the future
it will become deprecated.
We should remove all uses of it and replace them
with `NetworkTopologyStrategy`.
This change replaces `SimpleStrategy` with
`NetworkTopologyStrategy` in all unit tests,
or at least in the ones where it was reasonable to do so.
Some of the tests were written explicitly to test the
`SimpleStrategy` strategy, or changing the keyspace from
`SimpleStrategy` to `NetworkTopologyStrategy`.
These tests were left intact.
It's still a feature that is supported,
even if it's slowly getting deprecated.
The typical way to use `NetworkTopologyStrategy` is
to specify a replication factor for each datacenter.
This could be a bit cumbersome, we would have to fetch
the list of datacenters, set the repfactors, etc.
Luckily there is another way - we can just specify
a replication factor to use for or each existing
datacenter, like this:
```cql
CREATE KEYSPACE {} WITH REPLICATION =
{'class' : 'NetworkTopologyStrategy', 'replication_factor' : 1};
```
This makes the change rather straightforward - just replace all
instances of `'SimpleStrategy'', with `'NetworkTopologyStrategy'`.
Refs: https://github.com/scylladb/scylladb/issues/8638
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Closes#13990
This PR introduces an experimental feature called "tablets". Tablets are
a way to distribute data in the cluster, which is an alternative to the
current vnode-based replication. Vnode-based replication strategy tries
to evenly distribute the global token space shared by all tables among
nodes and shards. With tablets, the aim is to start from a different
side. Divide resources of replica-shard into tablets, with a goal of
having a fixed target tablet size, and then assign those tablets to
serve fragments of tables (also called tablets). This will allow us to
balance the load in a more flexible manner, by moving individual tablets
around. Also, unlike with vnode ranges, tablet replicas live on a
particular shard on a given node, which will allow us to bind raft
groups to tablets. Those goals are not yet achieved with this PR, but it
lays the ground for this.
Things achieved in this PR:
- You can start a cluster and create a keyspace whose tables will use
tablet-based replication. This is done by setting `initial_tablets`
option:
```
CREATE KEYSPACE test WITH replication = {'class': 'NetworkTopologyStrategy',
'replication_factor': 3,
'initial_tablets': 8};
```
All tables created in such a keyspace will be tablet-based.
Tablet-based replication is a trait, not a separate replication
strategy. Tablets don't change the spirit of replication strategy, it
just alters the way in which data ownership is managed. In theory, we
could use it for other strategies as well like
EverywhereReplicationStrategy. Currently, only NetworkTopologyStrategy
is augmented to support tablets.
- You can create and drop tablet-based tables (no DDL language changes)
- DML / DQL work with tablet-based tables
Replicas for tablet-based tables are chosen from tablet metadata
instead of token metadata
Things which are not yet implemented:
- handling of views, indexes, CDC created on tablet-based tables
- sharding is done using the old method, it ignores the shard allocated in tablet metadata
- node operations (topology changes, repair, rebuild) are not handling tablet-based tables
- not integrated with compaction groups
- tablet allocator piggy-backs on tokens to choose replicas.
Eventually we want to allocate based on current load, not statically
Closes#13387
* github.com:scylladb/scylladb:
test: topology: Introduce test_tablets.py
raft: Introduce 'raft_server_force_snapshot' error injection
locator: network_topology_strategy: Support tablet replication
service: Introduce tablet_allocator
locator: Introduce tablet_aware_replication_strategy
locator: Extract maybe_remove_node_being_replaced()
dht: token_metadata: Introduce get_my_id()
migration_manager: Send tablet metadata as part of schema pull
storage_service: Load tablet metadata when reloading topology state
storage_service: Load tablet metadata on boot and from group0 changes
db, migration_manager: Notify about tablet metadata changes via migration_listener::on_update_tablet_metadata()
migration_notifier: Introduce before_drop_keyspace()
migration_manager: Make prepare_keyspace_drop_announcement() return a future<>
test: perf: Introduce perf-tablets
test: Introduce tablets_test
test: lib: Do not override table id in create_table()
utils, tablets: Introduce external_memory_usage()
db: tablets: Add printers
db: tablets: Add persistence layer
dht: Use last_token_of_compaction_group() in split_token_range_msb()
locator: Introduce tablet_metadata
dht: Introduce first_token()
dht: Introduce next_token()
storage_proxy: Improve trace-level logging
locator: token_metadata: Fix confusing comment on ring_range()
dht, storage_proxy: Abstract token space splitting
Revert "query_ranges_to_vnodes_generator: fix for exclusive boundaries"
db: Exclude keyspace with per-table replication in get_non_local_strategy_keyspaces_erms()
db: Introduce get_non_local_vnode_based_strategy_keyspaces()
service: storage_proxy: Avoid copying keyspace name in write handler
locator: Introduce per-table replication strategy
treewide: Use replication_strategy_ptr as a shorter name for abstract_replication_strategy::ptr_type
locator: Introduce effective_replication_map
locator: Rename effective_replication_map to vnode_effective_replication_map
locator: effective_replication_map: Abstract get_pending_endpoints()
db: Propagate feature_service to abstract_replication_strategy::validate_options()
db: config: Introduce experimental "TABLETS" feature
db: Log replication strategy for debugging purposes
db: Log full exception on error in do_parse_schema_tables()
db: keyspace: Remove non-const replication strategy getter
config: Reformat
There's one place where test case calls for storage proxy and currently
does it via global refernece. Time to switch it to cql_test_env's one.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
This series aims to allow users to set permissions on user-defined functions.
The implementation is based on Cassandra's documentation and should be fully compatible: https://cassandra.apache.org/doc/latest/cassandra/cql/security.html#cql-permissionsFixes: #5572Fixes: #10633Closes#12869
* github.com:scylladb/scylladb:
cql3: allow UDTs in permissions on UDFs
cql3: add type_parser::parse() method taking user_types_metadata
schema_change_test: stop using non-existent keyspace
cql3: fix parameter names in function resource constructors
cql3: handle complex types as when decoding function permissions
cql3: enforce permissions for ALTER FUNCTION
cql-pytest: add a (failing) test case for UDT in UDF
cql-pytest: add a test case for user-defined aggregate permissions
cql-pytest: add tests for function permissions
cql3: enforce permissions on function calls
selection: add a getter for used functions
abstract_function_selector: expose underlying function
cql3: enforce permissions on DROP FUNCTION
cql3: enforce permissions for CREATE FUNCTION
client_state: add functions for checking function permissions
cql-pytest: add a case for serializing function permissions
cql3: allow specifying function permissions in CQL
auth: add functions_resource to resources
{kind=link}