The change is mostly mechanical: update all compactor instances to the
_v2 variant and update all call-sites, of which there is not that many.
As a consequence of this patch, queries -- both single-partition and
range-scans -- now do the v2->v1 conversion in the consumers, instead of
in the compactor.
The series overhauls the compaction_manager::task design and implementation
by properly layering the functionality between the compaction_manager
that deals with generic task execution, and the per-task business logic that is defined
in a set of classes derived from the generic task class.
While at it, the series introduces `task::state` and a set of helper functions to manage it
to prevent leaks in the statistics, fixing #9974.
Two more stats counter were exposed: `completed_tasks` and a new `postponed_tasks`.
Test: sstable_compaction_test
Dtest: compaction_test.py compaction_additional_test.py
Fixes#9974Closes#10122
* github.com:scylladb/scylla:
compaction_manager: use coroutine::switch_to
compaction_manager::task: drop _compaction_running
compaction_manager: move per-type logic to derived task
compaction_manager: task: add state enum
compaction_manager: task: add maybe_retry
compaction_manager: reevaluate_postponed_compactions: mark as noexcept
compaction_manager: define derived task types
compaction_manager: register_metrics: expose postponed_compactions
compaction_manager: register_metrics: expose failed_compactions
compaction_manager: register_metrics: expose _stats.completed_tasks
compaction: add documentation for compaction_type to string conversions
compaction: expose to_string(compaction_type)
compaction_manager: task: standardize task description in log messages
compaction_manager: refactor can_proceed
compaction_manager: pass compaction_manager& to task ctor
compaction_manager: use shared_ptr<task> rather than lw_shared_ptr
compaction_manager: rewrite_sstables: acquire _maintenance_ops_sem once
compaction_manager: use compaction_state::lock only to synchronize major and regular compaction
Move the business logic into the task specific classes.
Separating initialization during task construction,
from the compaction_done task, moved into
a do_run() method, and in some cases moving
a lambda function that was called per table (as in
rewrite_sstables) into a private method of the
derived class.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Reading data from sstables without compacting first puts
unnecessary pressure on the cache. The mutation streams
need to be resolved anyway before passing to subsequent
consumers, so it's better to do it as close to the
source as possible.
Fixes: #3568Closes#10188
Define task::describe and use it via operator<<
to print the task metadata to the log in a standard way.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
And use it to get the compaction state of the
table to compact.
It will be used in a later patch
to manage the task state from task
methods.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
The sstables::sstable class has two methods for writing sstables:
1) sstable_writer get_writer(...);
2) future<> write_components(flat_mutation_reader, ...);
(1) directly exposes the writer type, so we have to update all users of
it (there is not that many) in this same patch. We defer updating
users of (2) to a follow-up commits.
Although we have a log in run_mutation_reader_tests(), it is useful to
know where it was called from, when trying to find the test scenario
that failed.
"
Also convert the foreign_reader used by it in the process.
Tests: unit(dev)
"
* 'multishard-writer-v2/v1' of https://github.com/denesb/scylla:
mutation_writer/multishard_writer: remove now unused v1 factory overloads
test/boost/mutation_writer_test: test the v2 variant of distribute_reader_and_consume_on_shards()
flat_mutation_reader: add v2 variant of make_generating_reader()
mutation_reader: multishard_writer: migrate implementation to v2
mutation_reader: convert foreign_reader to v2
streaming/consumer: convert to v2
mutation_writer/multishard_writer: add v2 variant of distribute_reader_and_consume_on_shards()
There are two issues with current implementation of remove/remove_if:
1) If it happens concurrently with get_ptr(), the latter may still
populate the cache using value obtained from before remove() was
called. remove() is used to invalidate caches, e.g. the prepared
statements cache, and the expected semantic is that values
calculated from before remove() should not be present in the cache
after invalidation.
2) As long as there is any active pointer to the cached value
(obtained by get_ptr()), the old value from before remove() will be
still accessible and returned by get_ptr(). This can make remove()
have no effect indefinitely if there is persistent use of the cache.
One of the user-perceived effects of this bug is that some prepared
statements may not get invalidated after a schema change and still use
the old schema (until next invalidation). If the schema change was
modifying UDT, this can cause statement execution failures. CQL
coordinator will try to interpret bound values using old set of
fields. If the driver uses the new schema, the coordinaotr will fail
to process the value with the following exception:
User Defined Type value contained too many fields (expected 5, got 6)
The patch fixes the problem by making remove()/remove_if() erase old
entries from _loading_values immediately.
The predicate-based remove_if() variant has to also invalidate values
which are concurrently loading to be safe. The predicate cannot be
avaluated on values which are not ready. This may invalidate some
values unnecessarily, but I think it's fine.
Fixes#10117
Message-Id: <20220309135902.261734-1-tgrabiec@scylladb.com>
This patch gets rid annoying pytest configuration warnings when running
test/cql-pytest/run. These started to happen after commit
afab1a97c6, due to a pytest bug:
In that commit, we added new "--scylla-path" and "--workdir" parameters
to our pytest tests, and test/cql-pytest/run started passing them,
and test/cql-pytest/run sometest runs pytest as:
pytest --host something --workdir somedir --scylla-path somepath sometest
Pytest wants to find a configuration file (pytest.ini or tox.ini) in the
directory where the tests live, but its logic to find that directory is
buggy: It (_pytest/config/findpaths.py::determine_setup()) looks at
the command line for directory names, and looks for config files in
these directories or any of their parents. It ignores parameters
beginning with "-", but in our case the various arguments like
"--scylla-path" are each followed by another option, and this one is
not ignored! So instead of looking for the config file in sometest's
parent directories (and finding test/cql-pytest/pytest.ini), pytest
sees the directory given after "scylla-path", and finds the completely
irrelevant tox.ini there - and uses that, which (depending what you
have installed) can generate warnings.
The solution is to change the run script to use "--scylla-path=..."
as one parameter instead of "--scylla-path ..." as two parameters.
When it's just one parameter, the pytest determine_setup() logic skips
it entirely, and finds just the actual test directory.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20220309132726.2311721-1-nyh@scylladb.com>
This case is a regression test for issue #10181, where it turned out
that a clustering column with descending order is not properly
recognized as a string.
This test case used to fail with:
cassandra.InvalidRequest:
Error from server: code=2200 [Invalid query]
message="LIKE is allowed only on string types, which b is not"
...until it got fixed by the previous commit.
The problem was incompatibility with cassandra, which accepts bool
as a string in `fromJson()` UDF. The difference between Cassandra and
Scylla now is Scylla accepts whitespaces around word in string,
Cassandra don't. Both are case insensitive.
Fixes: https://github.com/scylladb/scylla/issues/7915Closes#10134
* github.com:scylladb/scylla:
CQL3/pytest: Updating test_json
CQL3: fromJson accepts string as bool
Cassandra generally does not allow empty strings as partition keys (note, by the way, that empty strings are allowed as clustering keys, as well as in individual components of a compound partition key).
However, Cassandra does allow empty strings in _regular_ columns - and those regular columns can be indexed by a secondary index, or become an empty partition-key column in a materialized view. As noted in issues #9375 and #9364 and verified in a few xfailing cql-pytest tests, Scylla didn't allow these cases - and this patch series fixes that.
Before the last patch in this series finally enables empty-string partition keys in materialized views, we first need to solve a couple of bugs in our code related to handling empty partition keys:
The first patch fixes issue #10178 - a bug in `key_view::tri_compare()` where comparing two empty keys returned a random result instead of "equal".
The second patch fixes issue #9352: our tokenizer has an inconsistency where for an empty string key, two variants of the same function return different results:
1. One variant `murmur3_partitioner::get_token(bytes_view key)` returned `minimum_token()` for the empty string.
2. Another variant `murmur3_partitioner::get_token(const schema& s, partition_key_view key)` did not have this special case, and called the normal hash-function calculation on the empty string (the resulting token is 0).
Variant 2 was an unintentional bug, because Cassandra always does what variant does 1. So the "obvious" fix here would be to fix variant 2 to do what variant 1 does. Nevertheless, we decided to do the opposite: Change variant 1 to match variant 2. The reasoning is as follows:
The `minimum_token()` is `token{token::kind::before_all_keys, 0 }` - it's not a real token. Since we intend in this patch allow real data to exist with the empty key, we need this real data to have a real token. For example, this token needs to be located on the token ring (so the empty-key partition will have replicas) and also belong to one of the shards, and it's not clear that `minimum_token()` will be handled correctly in this context.
After changing the token of the empty string to 0, we note that some places in the code assume that `dht::decorated_key(dh
t::minimum_token(), partition_key::make_empty())` is a legal decorated key. However, as far as I can tell, none of these places actually assume that the partition-key part (the `make_empty()`) really matches the token - this decorated key is only used to start an iteration (ignoring this key itself) or to indicate a non-existent key (in modern code `std::optional` should be used for that).
While normally changing the token of a key is a big faux-pas, which can result in old data no longer being readable, in this case this change is safe because:
1. Scylla previously disallowed empty partition keys (in both base tables and views), so we cannot have had such a partition key saved in any sstable.
3. Cassandra does allow empty partition keys in _views_ and _secondary indexes_, but we do not support migrating sstables of those into Scylla - users are expected to only migrate the base table and then re-create the view or index. So however Cassandra writes those empty-key partitions, we don't care.
The third patch finally fixes the materialized views implementation to not drop view rows with an empty-string partition key (#9375). This means we basically revert commit ec8960df45 - which fixed#3262 by disallowing empty partition keys in views, whereas this patch fixes the same problem by handling the empty partition keys correctly.
The fix for the secondary index bug (#9364) comes "for free" because it is based on materialized views.
We already had xfailing test cases for empty strings in materialized views and indexes, and after this series they begin to pass so the "xfail" mark is removed. The series also adds additional test cases that validate additional corner cases discovered during the debugging.
Fixes#9352Fixes#9364Fixes#9375Fixes#10178Closes#10170
* github.com:scylladb/scylla:
compound_compat.hh: add missing methods of iterator
materialized views: allow empty strings in views and indexes
murmur3: fix inconsistent token for empty partition key
compound_compat.hh: fix bug iterating on empty singular key
Although Cassandra generally does not allow empty strings as partition
keys (note they are allowed as clustering keys!), it *does* allow empty
strings in regular columns to be indexed by a secondary index, or to
become an empty partition-key column in a materialized view. As noted in
issues #9375 and #9364 and verified in a few xfailing cql-pytest tests,
Scylla didn't allow these cases - and this patch fixes that.
The patch mostly *removes* unnecessary code: In one place, code
prevented an sstable with an empty partition key from being written.
Another piece of removed code was a function is_partition_key_empty()
which the materialized-view code used to check whether the view's
row will end up with an empty partition key, which was supposedly
forbidden. But in fact, should have been allowed like they are allowed
in Cassandra and required for the secondary-index implementation, and
the entire function wasn't necessary.
Note that the removed function is_partition_key_empty() was *NOT* required
for the "IS NOT NULL" feature of materialized views - this continues to
work as expected after this patch, and we add another test to confirm it.
Being null and being an empty string are two different things.
This patch also removes a part of a unit test which enshrined the
wrong behavior.
After this patch we are left with one interesting difference from
Cassandra: Though Cassandra allows a user to create a view row with an
empty-string partition key, and this row is fully visible in when
scanning the view, this row can *not* be queried individually because
"WHERE v=''" is forbidden when v is the partition key (of the view).
Scylla does not reproduce this anomaly - and such point query does work
in Scylla after this patch. We add a new test to check this case, and mark
it "cassandra_bug", i.e., it's a Cassandra behavior which we consider
wrong and don't want to emulate.
This patch relies on #9352 and #10178 having been fixed in previous patches,
otherwise the WHERE v='' does not work when reading from sstables.
We add to the already existing tests we had for empty materialized-views
keys a lookup with WHERE v='' which failed before fixing those two issues.
Fixes#9364Fixes#9375
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
When iterating over a compound key with legacy_compound_view<>, when the
key is "singular" (i.e., a single column) we need to iterate over just the
component's actual bytes - without the two length bytes or end-of-component
byte. In particular, when the component is an *empty string*, the iteration
should return zero bytes. In other words, we should have begin() == end().
Unfortunately, this is not what happened - for an empty singular key, the
iterator returned for begin() was slightly different from end() - so
code using this iterator would not know there is nothing to iterate.
So in this patch we fix begin() and end() to return the same thing
if we have an empty singular key.
The bug in legacy_compound_view<> (which we fix here) caused a bug in
sstables::key_view::tri_compare(const schema& s, partition_key_view other),
causing it to return wrong results when comparing two empty keys. As a
result we were unable to retrieve a partition with an empty key from the
sstable index. So this patch is necessary to fix support for
empty-string keys in sstables (part of issue #9375).
This patch also includes a unit-test for this bug. We test it in the
context of sstables::key_view::tri_compare(), where it was first
discovered, and also test the legacy_compound_view itself. The included
test used to fail in both places before this patch, and pass after it.
Fixes#10178
Refs #9375
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Following up on a57c087c89,
compare_atomic_cell_for_merge should compare the ttl value in the
reverse order since, when comparing two cells that are identical
in all attributes but their ttl, we want to keep the cell with the
smaller ttl value rather than the larger ttl, since it was written
at a later (wall-clock) time, and so would remain longer after it
expires, until purged after gc_grace seconds.
Fixes#10173
Test: mutation_test.test_cell_ordering, unit(dev)
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220302154328.2400717-1-bhalevy@scylladb.com>
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220306091913.106508-1-bhalevy@scylladb.com>
When a node starts it does not immediately becomes a candidate since it
waits to learn about already existing leader and randomize the time it
becomes a candidate to prevent dueling candidates if several nodes are
started simultaneously.
If a cluster consist of only one node there is no point in waiting
before becoming a candidate though because two cases above cannot
happen. This patch checks that the node belongs to a singleton cluster
where the node itself is the only voting member and becomes candidate
immediately. This reduces the starting time of a single node cluster
which are often used in testing.
Message-Id: <YiCbQXx8LPlRQssC@scylladb.com>
When setting up clusters in regression tests, a bunch of servers were
created, each starting with a singleton configuration containing itself.
This is wrong: servers joining to an existing cluster should be started
with an empty configuration.
It 'worked' because the first server, which we wait for to become a leader
before creating the other servers, managed to override the logs and
configurations of other servers before they became leaders in their
configurations.
But if we want to change the logic so that servers in single-server clusters
elect themselves as leaders immediately, things start to break. So fix
the bug.
Message-Id: <20220303100344.6932-1-kbraun@scylladb.com>
Referring to issue #7915, cassandra also works with unprepared
statement. There was missing `fromJson()`, the test was inserting
string into boolean column.
Unlike atomic_cell_or_collection::equals, compare_atomic_cell_for_merge
currently returns std::strong_ordering::equal if two cells are equal in
every way except their ttl:s.
The problem with that is that the cells' hashes are different and this
will cause repair to keep trying to repair discrepancies caused by the
ttl being different.
This may be triggered by e.g. the spark migrator that computes the ttl
based on the expiry time by subtracting the expiry time from the current
time to produce a respective ttl.
If the cell is migrated multiple times at different times, it will generate
cells that the same expiry (by design) but have different ttl values.
Fixes#10156
Test: mutation_test.test_cell_ordering, unit(dev)
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220302154328.2400717-1-bhalevy@scylladb.com>
Passing integer which exceeds corresponding type's bounds to
`fromJson()` was causing silent overflow, e.g. inserting
`fromJson('2147483648')` to `int` coulmn stored `-2147483648`.
Now, this will cause marshal_exception. All integer types are testing agains their bounds.
Tests referring issue https://github.com/scylladb/scylla/issues/7914 in `test/cql-pytest/cassandra_tests/validation/entities/json_test.py` won't pass because the expected error's messages differ from the thrown ones. I was wondering what the message should be, because expected messages in tests aren't consistent, for instance:
- bigint overflow expects `Expected a bigint value, but got a` message
- short overflow expects `Unable to make short from` message
For now the message is `Value {} out of bound`.
Fixes: https://github.com/scylladb/scylla/issues/7914Closes#10145
* github.com:scylladb/scylla:
CQL3/pytest: Updating test_json
CQL3: fromJson out of range integer cause as error
Introduced in commit: ddd693c6d7
We're not emplacing newer windows in the tracker, causing
std::out_of_range when replacing sstables for windows.
Let's fix the logic and add an unit test to cover this.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220301194944.95096-1-raphaelsc@scylladb.com>
The underlying implementation behind the v1 and v2 variants if said
methods is the same, but we want to move to using the v2 variant in the
test as the v1 variant is going away soon.
This series contains:
- lister: move to utils
- tidy up the clutter in the root dir
Based on Avi's feedback to `[PATCH 1/1] utils: directory_lister: close: always abort queue` that was sent to the mailing list:
- directory_lister: drop abort method
- lister: do not require get after close to fail
- test: lister_test: test_directory_lister_close simplify indentation
- cosmetic cleanup
Closes#10142
* github.com:scylladb/scylla:
test: lister_test: test_directory_lister_close simplify indentation
lister: do not require get after close to fail
directory_lister: drop abort method
lister: move to utils
This PR consists of two changes.
The first fixes the flat_mutation_reader and flat_mutation_reader_v2, so that they can be destructed without being closed (if no action has been initiated). This has been discussed in the referenced issue.
The second one changes scanning and flush readers so that they implement the second version of the API.
It also contains unit test fixes, dealing with flat mutation reader assertions (where the v1 asserter failed to consume range tombstones intelligently enough in some flows) and several sstable_3_x tests (where sstables that contain range tombstones were expected to be byte-by-byte equivalent to a reference, aside from semantic validation).
Fixes#9065.
Closes#9669
* github.com:scylladb/scylla:
flat_reader_assertions: do not accumulate out-of-range tombstones
flat_reader_assertions: refactor resetting accumulated tombstone lists
flat_mutation_reader_test: fix "test_flat_mutation_reader_consume_single_partition"
memtable::make_flush_reader(): return flat_mutation_reader_v2
memtable::make_flat_reader(): return flat_mutation_reader_v2
flat_mutation_reader_v2: add consume_partitions()
introduce the MutationConsumer concept
mutation_source: clone shortcut constructors for flat_mutation_reader_v2
flat_mutation_reader_v2: add delegating_reader_v2
memtable: upgrade scanning_reader and flush_reader to v2
flat_mutation_reader: allow destructing readers which are not closed and didn't initiate any IO.
tests: stop comparing sstables with range tombstones to C* reference
tests: flat_reader_assertions: improve range tombstone checking
Also remove the incorrect difference in range tombstone checking
behavior between `produces_range_tombstone()` and `produces(const
range_tombstone&)` by having both turn on checking.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
Since `flat_reader_assertions::produces(const range_tombstone&,...)`
records the range tombstone for checking, be sure to explicitly pass
in a clustering range that does not extend beyond the mock-read part
of the mutation.
Also (provisionally) change the assertion method to accept clustering
ranges.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
In functions such as upgrade_to_v2 (excerpt below), if the constructor
of transforming_reader throws, r needs to be destroyed, however it
hasn't been closed. However, if a reader didn't start any operations, it
is safe to destruct such a reader. This issue can potentially manifest
itself in many more readers and might be hard to track down. This commit
adds a bool indicating whether a close is anticipated, thus avoiding
errors in the destructor.
Code excerpt:
flat_mutation_reader_v2 upgrade_to_v2(flat_mutation_reader r) {
class transforming_reader : public flat_mutation_reader_v2::impl {
// ...
};
return make_flat_mutation_reader_v2<transforming_reader>(std::move(r));
}
Fixes#9065.
As flat mutation reader {up,down}grades get added to the write path,
comparing range-tombstone-containing (at least) sstables byte-by-byte
to a reference is starting to seem like a fool's errand.
* When a flat mutation reader is {up,down}graded, information may get
lost while splitting range tombstones. Making those splits revertable
should in theory be possible but would surely make {up,down}graders
slower and more complex, and may also possibly entail adding
information to in-memory representation of range tombstones and
range rombstone changes. Such investment for the sake of 7 unit tests
does not seem wise, given that the plan is to get rid of reader
{up,down}grade logic once the move to flat mutation reader v2 is
completed.
* All affected tests also validate their written sstables
semantically.
* At least some of the offending reference sstables are not
"canonical" wrt range tombstones to begin with -- they contain range
tombstones that overlap with clustering rows. The fact that Scylla
does not "canonicalize" those in some way seems purely incidental.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
`produces_range_tombstone()` is smart enough to not just try to read
one range tombstone from the input and compare it to the passed
reference, but to read as many range tombstones as the reader is
looking at (including none) using `may_produce_tombstones()` and
record those appropriately.
When `produces(const schema&, const mutation_fragment&)` is passed a
range tombstone as the second argument, it does not do anything
special -- it just reads one fragment, disregards it (!), and applies
its second argument to both "expected" and "encountered" range
tombstone lists. The right thing here is to use the same logic as
`produces_range_tombstone()`; upcoming memtable-related reader
changes (which result in more split range tombstones) cause some unit
tests to fail without fixing this.
Refactor the relevant logic into a private method (`apply_rt()`) and
use that in both places.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
In a previous patch, we added a test for the case of Scylla trying to
assign the JSON value 1e6 into an integer - which should be allowed
because 1e6 is indeed a whole number, in the range of int.
We already fixed that in commit efe7456f0a,
but this patch adds another test which demonstrates that an even more
esoteric problem remains:
If we are reading a JSON value into a bigint (CQL's 64-bit integer),
*and* if the number is between 2^53 and 2^63-1 *and* if the number
is written using scientific notation, e.g., 922337203685477580.7e1
(which is 2^63-1), then the bigint is set incorrectly, with some
digits being lost. The problem is that RapidJSON reads this integer
into the "double" type, which only keeps 53 significant bits.
Because this is an open issue (#10137), the test included here is
marked as expected failure (xfail). The test is also known to
fail in Cassandra - which doesn't allow scientific notation for
JSON integers at all despite the JSON standard - so the test is
also marked "cassandra_bug".
Refs #10137
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
There's no need anymore for an indented block
to destroy tnhe directory_lister since the other
sub-case was deleted.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Currently, the lister test expected get() to
always fail after close(), but it unexpectedly
succeeded if get() was never called before close,
as seen in https://jenkins.scylladb.com/view/master/job/scylla-master/job/next/4587/artifact/testlog/x86_64_debug/lister_test.test_directory_lister_close.4001.log
```
random-seed=1475104835
Generated 719 dir entries
Getting 565 dir entries
Closing directory_lister
Getting 0 dir entries
Closing directory_lister
test/boost/lister_test.cc(190): fatal error: in "test_directory_lister_close": exception std::exception expected but not raised
```
This change relaxes this requirement to keep
close() simple, based on Avi's feedback:
> The user should call close(), and not do it while get() is running, and
> that's it.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Based on Avi's feedback:
> We generally have a public abort() only if we depend on an external
> event (like data from a tcp socket) that we don't control. But here
> there are no such external events. So why have a public abort() at all?
If needed in the future, we can consider adding
get(abort_source&) to allow aborting get() via
an external event.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
There's nothing specific to scylla in the lister
classes, they could (and maybe should) be part of
the seastar library.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
We add a `peers()` method to `discovery` which returns the peers
discovered until now (including seeds). The caller of functions which
return an output -- `tick` or `request` -- is responsible for persisting
`peers()` before returning the output of `tick`/`request` (e.g. before
sending the response produced by `request` back). The user of
`discovery` is also responsible for restoring previously persisted peers
when constructing `discovery` again after a restart (e.g. if we
previously crashed in the middle of the algorithm).
The `persistent_discovery` class is a wrapper around `discovery` which
does exactly that.
For storage we use a simple local table.
A simple bugfix is also included in the first patch.
* kbr/discovery-persist-v3:
service: raft: raft_group0: persist discovered peers and restore on restart
db: system_keyspace: introduce discovery table
service: raft: discovery: rename `get_output` to `tick`
service: raft: discovery: stop returning peer_list from `request` after becoming leader
cached_page::on_evicted() is invoked in the LSA allocator context, set in the
reclaimer callback installed by the cache_tracker. However,
cached_pages are allocated in the standard allocator context (note:
page content is allocated inside LSA via lsa_buffer). The LSA region
will happily deallocate these, thinking that they these are large
objects which were delegated to the standard allocator. But the
_non_lsa_memory_in_use metric will underflow. When it underflows
enough, shard_segment_pool.total_memory() will become 0 and memory
reclamation will stop doing anything, leading to apparent OOM.
The fix is to switch to the standard allocator context inside
cached_page::on_evicted(). evict_range() was also given the same
treatment as a precaution, it currently is only invoked in the
standard allocator context.
The series also adds two safety checks to LSA to catch such problems earlier.
Fixes#10056
\cc @slivne @bhalevy
Closes#10130
* github.com:scylladb/scylla:
lsa: Abort when trying to free a standard allocator object not allocated through the region
lsa: Abort when _non_lsa_memory_in_use goes negative
tests: utils: cached_file: Validate occupancy after eviction
test: sstable_partition_index_cache_test: Fix alloc-dealloc mismatch
utils: cached_file: Fix alloc-dealloc mismatch during eviction
"
Problem statement
=================
Today, compaction can act much more aggressive than it really has to, because
the strategy and its definition of backlog are completely decoupled.
The backlog definition for size-tiered, which is inherited by all
strategies (e.g.: LCS L0, TWCS' windows), is built on the assumption that the
world must reach the state of zero amplification. But that's unrealistic and
goes against the intent amplification defined by the compaction strategy.
For example, size tiered is a write oriented strategy which allows for extra
space amplification for compaction to keep up with the high write rate.
It can be seen today, in many deployments, that compaction shares is either
close to 1000, or even stuck at 1000, even though there's nothing to be done,
i.e. the compaction strategy is completely satisfied.
When there's a single sstable per tier, for example.
This means that whenever a new compaction job kicks in, it will act much more
aggressive because of the high shares, caused by false backlog of the existing
tables. This translates into higher P99 latencies and reduced throughput.
Solution
========
This problem can be fixed, as proposed in the document "Fixing compaction
aggressiveness due to suboptimal definition of zero backlog by controller" [1],
by removing backlog of tiers that don't have to be compacted now, like a tier
that has a single file. That's about coupling the strategy goal with the
backlog definition. So once strategy becomes satisfied, so will the controller.
Low-efficiency compaction, like compacting 2 files only or cross-tier, only
happens when system is under little load and can proceed at a slower pace.
Once efficient jobs show up, ongoing compactions, even if inefficient, will get
more shares (as efficient jobs add to the backlog) so compaction won't fall
behind.
With this approach, throughput and latency is improved as cpu time is no longer
stolen (unnecessarily) from the foreground requests.
[1]: https://docs.google.com/document/d/1EQnXXGWg6z7VAwI4u8AaUX1vFduClaf6WOMt2wem5oQ
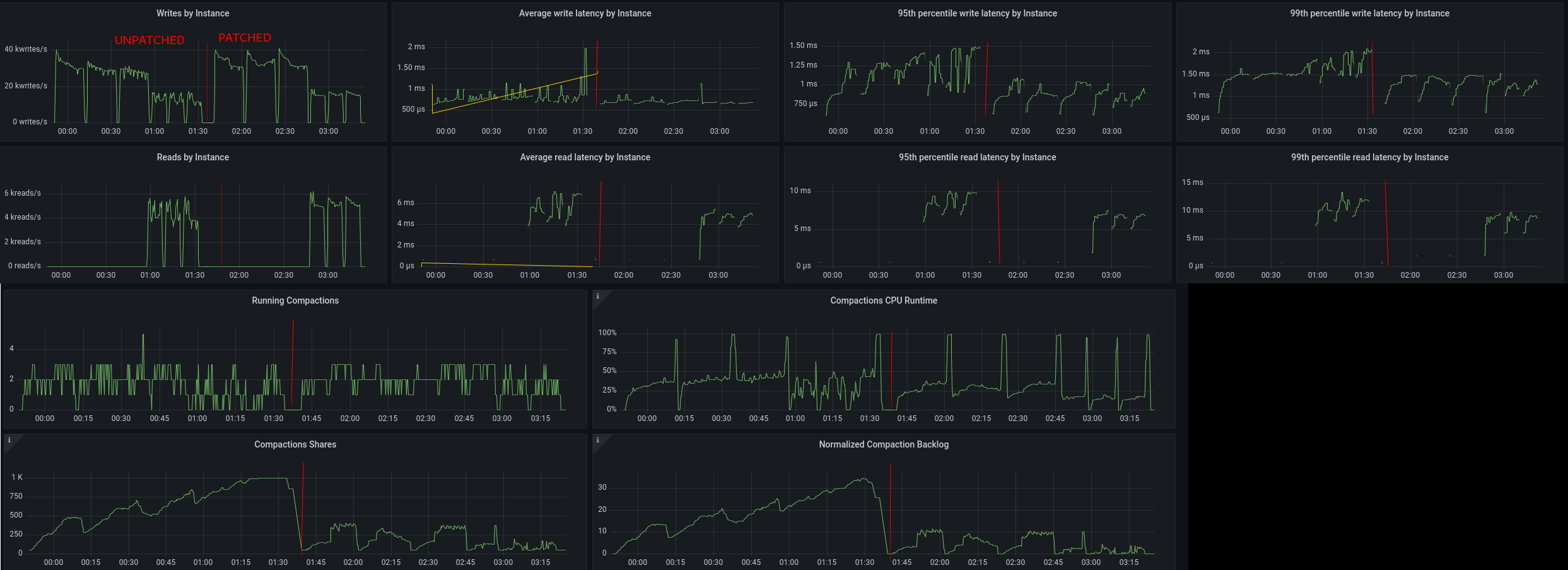
Results
=======
Test sequentially populates 3 tables and then run a mixed workload on them,
where disk:memory ratio (usage) reaches ~30:1 at the peak.
Please find graphs here:
https://user-images.githubusercontent.com/1409139/153687219-32368a35-ac63-461b-a362-64dbe8449a00.png
1) Patched version started at ~01:30
2) On population phase, throughput increase and lower P99 write latency can be
clearly observed.
3) On mixed phase, throughput increase and lower P99 write and read latency can
also be clearly observed.
4) Compaction CPU time sometimes reach ~100% because of the delay between each
loader.
5) On unpatched version, it can be seen that backlog keeps growing even when
though strategies become satisfied, so compaction is using much more CPU time
in comparison. Patched version correctly clears the backlog.
Can also be found at:
github.com/raphaelsc/scylla.git compaction-controller-v5
tests: UNIT(dev, debug).
"
* 'compaction-controller-v5' of https://github.com/raphaelsc/scylla:
tests: Add compaction controller test
test/lib/sstable_utils: Set bytes_on_disk for fake SSTables
compaction/size_tiered_backlog_tracker.hh: Use unsigned type for inflight component
compaction: Redefine compaction backlog to tame compaction aggressiveness
compaction_backlog_tracker: Batch changes through a new replacement interface
table: Disable backlog tracker when stopping table
compaction_backlog_tracker: make disable() public
compaction_backlog_tracker: Clear tracker state when disabled
compaction: Add normalized backlog metric
compaction: make size_tiered_compaction_strategy static
This patch adds a reproducing test for issue #10081. That issue is about
a conditional (LWT) UPDATE operation that chose a non-existent row via WHERE,
and its condition refers to both static and regular columns: In that case,
the code incorrectly assumes that because it didn't read any row, all columns
are null - and forgets that the static column is *not* null.
The test, test_lwt.py::test_lwt_missing_row_with_static
passes on Cassandra but fails on Scylla, so is marked xfail.
Refs #10081
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20220215215243.660087-1-nyh@scylladb.com>
{kind=link}