File based stream is a new feature that optimizes tablet movement
significantly. It streams the entire SSTable files without deserializing
SSTable files into mutation fragments and re-serializing them back into
SSTables on receiving nodes. As a result, less data is streamed over the
network, and less CPU is consumed, especially for data models that
contain small cells.
The following patches are imported from the scylla enterprise:
*) Merge 'Introduce file stream for tablet' from Asias He
This patch uses Seastar RPC stream interface to stream sstable files on
network for tablet migration.
It streams sstables instead of mutation fragments. The file based
stream has multiple advantages over the mutation streaming.
- No serialization or deserialization for mutation fragments
- No need to read and process each mutation fragments
- On wire data is more compact and smaller
In the test below, a significant speed up is observed.
Two nodes, 1 shard per node, 1 initial_tablets:
- Start node 1
- Insert 10M rows of data with c-s
- Bootstrap node 2
Node 1 will migration data to node2 with the file stream.
Test results:
1) File stream: bytes on wire = 1132006250 bytes, bw = 836MB/s
[shard 0:stre] stream_blob - stream_sstables[eadaa8e0-a4f2-4cc6-bf10-39ad1ce106b0]
Finished sending sstable_nr=2 files_nr=18 files={} range=(-1,9223372036854775807] bytes_sent=1132006250 stream_bw=836MB/s
[shard 0:stre] storage_service - Streaming for tablet migration of a4f68900-568a-11ee-b7b9-c2b13945eed2:1 took 1.08004s seconds
2) Mutation stream: bytes on wire = 3030004736 bytes, bw = 125410.87 KiB/s = 128MB/s
[shard 0:stre] stream_session - [Stream #406dc8b0-56b5-11ee-bc2d-000bf4871058]
Streaming plan for Tablet migration-ks1-index-0 succeeded, peers={127.0.0.1}, tx=0 KiB, 0.00 KiB/s, rx=2958989 KiB, 125410.87 KiB/s
[shard 0:stre] storage_service - Streaming for tablet migration of a4f68900-568a-11ee-b7b9-c2b13945eed2:1 took 23.5992s seconds
Test Summary:
File stream v.s. Mutation stream improvements
- Stream bandwidth = 836 / 128 (MB/s) = 6.53X
- Stream time = 23.60 / 1.08 (Seconds) = 21.85X
- Stream bytes on wire = 3030004736 / 1132006250 (Bytes)= 2.67X
Closes scylladb/scylla-enterprise#3438
* github.com:scylladb/scylla-enterprise:
tests: Add file_stream_test
streaming: Implement file stream for tablet
*) streaming: Use new take_storage_snapshot interface
The new take_storage_snapshot returns a file object instead of a file
name. This allows the file stream sender to read from the file even if
the file is deleted by compaction.
Closes scylladb/scylla-enterprise#3728
*) streaming: Protect unsupported file types for file stream
Currently, we assume the file streamed over the stream_blob rpc verb is
a sstable file. This patch rejects the unsupported file types on the
receiver side. This allows us to stream more file types later using the
current file stream infrastructure without worrying about old nodes
processing the new file types in the wrong way.
- The file_ops::noop is renamed to file_ops::stream_sstables to be
explicit about the file types
- A missing test_file_stream_error_injection is added to the idl
Fixes: #3846
Tests: test_unsupported_file_ops
Closesscylladb/scylla-enterprise#3847
*) idl: Add service::session_id id to idl
It will be used in the next patch.
Refs #3907
*) streaming: Protect file stream with topology_guard
Similar to "storage_service, tablets: Use session to guard tablet
streaming", this patch protects file stream with topology_guard.
Fixes#3907
*) streaming: Take service topology_guard under the try block
Taking the service::topology_guard could throw. Currently, it throws
outside the try block, so the rpc sink will not be closed, causing the
following assertion:
```
scylla: seastar/include/seastar/rpc/rpc_impl.hh:815: virtual
seastar::rpc::sink_impl<netw::serializer,
streaming::stream_blob_cmd_data>::~sink_impl() [Serializer =
netw::serializer, Out = <streaming::stream_blob_cmd_data>]: Assertion
`this->_con->get()->sink_closed()' failed.
```
To fix, move more code including the topology_guard taking code to the
try block.
Fixes https://github.com/scylladb/scylla-enterprise/issues/4106Closesscylladb/scylla-enterprise#4110
*) Merge 'Preserve original SSTable state with file based tablet migration' from Raphael "Raph" Carvalho
We're not preserving the SSTable state across file based migration, so
staging SSTables for example are being placed into main directory, and
consequently, we're mixing staging and non-staging data, losing the
ability to continue from where the old replica left off.
It's expected that the view update backlog is transferred from old
into new replica, as migration doesn't wait for leaving replica to
complete view update work (which can take long). Elasticity is preferred.
So this fix guarantees that the state of the SSTable will be preserved
by propagating it in form of subdirectory (each subdirectory is
statically mapped with a particular state).
The staging sstables aren't being registered into view update generator
yet, as that's supposed to be fixed in OSS (more details can be found
at https://github.com/scylladb/scylladb/issues/19149).
Fixes#4265.
Closesscylladb/scylla-enterprise#4267
* github.com:scylladb/scylla-enterprise:
tablet: Preserve original SSTable state with file based tablet migration
sstables: Add get method for sstable state
*) sstable: (Re-)add shareabled_components getter
*) Merge 'File streaming sstables: Use sstable source/sink to transfer snapshots' from Calle Wilund
Fixes#4246
Alternative approach/better separation of concern, transport vs. sstable layer. Builds on #4472, but fancier.
Ensures we transfer and pre-process scylla metadata for streamed
file blobs first, then properly apply receiving nodes local config
by using a source and sink layer exported from sstables, which
handles things like ordering, metadata filtering (on source) as well
as handling metadata and proper IO paths when writing data on
receiver node (sink).
This implementation maintains the statelessness of the current
design, and the delegated sink side will re-read and re-write the
metadata for each component processed. This is a little wasteful,
but the meta is small, and it is less error prone than trying to do
caching cross-shards etc. The transport is isolated from the
knowledge.
This is an alternative/complement to #4436 and #4472, fixing the
underlying issue. Note that while the layers/API:s here allows easy
fixing of other fundamental problems in the feature (such as
destination location etc), these are not included in the PR, to keep
it as close to the current behaviour as possible.
Closesscylladb/scylla-enterprise#4646
* github.com:scylladb/scylla-enterprise:
raft_tests: Copy/add a topology test with encryption
file streaming: Use sstable source/sink to transfer snapshots
sstables: Add source and sink objects + producers for transfering a snapshot
sstable::types: Add remove accessor for extension info in metadata
*) The change for error injection in merge commit 966ea5955dd8760:
File streaming now has "stream_mutation_fragments" error injection points
so test_table_dropped_during_streaming works with file streaming.
*) doc: document file-based streaming
This commit adds a description of the file-based streaming feature to the documentation.
It will be displayed in the docs using the scylladb_include_flag directive after
https://github.com/scylladb/scylladb/pull/20182 is merged, backported to branch-6.0,
and, in turn, branch-2024.2.
Refs https://github.com/scylladb/scylla-enterprise/issues/4585
Refs https://github.com/scylladb/scylla-enterprise/issues/4254Closesscylladb/scylla-enterprise#4587
*) doc: move File-based streaming to the Tablets source file-based-streaming
This commit moves the description of file-based streaming from a common include file
to the regular doc source file where tablets are described.
Closesscylladb/scylla-enterprise#4652
*) streaming: sstable_stream_sink_impl: abort: prevent null pointer dereference
Closesscylladb/scylladb#22467
In order to reduce the dependency on external libraries, and for better integration with ranges in C++ standard library. let's use the homebrew `utils::views::unique()` before unique is accepted by the C++ standard.
---
it's a cleanup, hence no need to backport.
Closesscylladb/scylladb#22393
* github.com:scylladb/scylladb:
cql3, test: switch from boost::adaptors::uniqued to utils::views:unique
utils: implement drop-in replacement for replacing boost::adaptors::uniqued
Add a custom implementation of boost::adaptors::uniqued that is compatible
with C++20 ranges library. This bridges the gap between Boost.Range and
the C++ standard library ranges until std::views::unique becomes available
in C++26. Currently, the unique view is included in
[P2214](https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2023/p2760r0.html)
"A Plan for C++ Ranges Evolution", which targets C++26.
The implementation provides:
- A lazy view adaptor that presents unique consecutive elements
- No modification of source range
- Compatibility with C++20 range views and concepts
- Lighter header dependencies compared to Boost
This resolves compilation errors when piping C++20 range views to
boost::adaptors::uniqued, which fails due to concept requirements
mismatch. For example:
```c++
auto range = std::views::take(n) | boost::adaptors::uniqued; // fails
```
This change also offers us a lightweight solution in terms of smaller
header dependency.
While std::ranges::unique exists in C++23, it's an eager algorithm that
modifies the source range in-place, unlike boost::adaptors::uniqued which
is a lazy view. The proposed std::views::unique (P2214) targeting C++26
would provide this functionality, but is not yet available.
This implementation serves as an interim solution for filtering consecutive
duplicate elements using range views until std::views::unique is
standardized.
For more details on the differences between `std::ranges::unique` and
`boost::adaptors::uniqued`:
- boost::adaptors::uniqued is a view adaptor that creates a lazy view over the original range. It:
* Doesn't modify the source range
* Returns a view that presents unique consecutive elements
* Is non-destructive and lazy-evaluated
* Can be composed with other views
- std::ranges::unique is an algorithm that:
* Modifies the source range in-place
* Removes consecutive duplicates by shifting elements
* Returns an iterator to the new logical end
* Cannot be used as a view or composed with other range adaptors
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Update configure.py to use wasm32-wasip1 as an alternative to wasm32-wasi,
matching the behavior previously implemented for CMake builds in 8d7786cb0e.
This ensures consistent WASI target handling across both build systems.
Refs #20878
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22386
File based stream is a new feature that optimizes tablet movement
significantly. It streams the entire SSTable files without deserializing
SSTable files into mutation fragments and re-serializing them back into
SSTables on receiving nodes. As a result, less data is streamed over the
network, and less CPU is consumed, especially for data models that
contain small cells.
The following patches are imported from the scylla enterprise:
*) Merge 'Introduce file stream for tablet' from Asias He
This patch uses Seastar RPC stream interface to stream sstable files on
network for tablet migration.
It streams sstables instead of mutation fragments. The file based
stream has multiple advantages over the mutation streaming.
- No serialization or deserialization for mutation fragments
- No need to read and process each mutation fragments
- On wire data is more compact and smaller
In the test below, a significant speed up is observed.
Two nodes, 1 shard per node, 1 initial_tablets:
- Start node 1
- Insert 10M rows of data with c-s
- Bootstrap node 2
Node 1 will migration data to node2 with the file stream.
Test results:
1) File stream: bytes on wire = 1132006250 bytes, bw = 836MB/s
[shard 0:stre] stream_blob - stream_sstables[eadaa8e0-a4f2-4cc6-bf10-39ad1ce106b0]
Finished sending sstable_nr=2 files_nr=18 files={} range=(-1,9223372036854775807] bytes_sent=1132006250 stream_bw=836MB/s
[shard 0:stre] storage_service - Streaming for tablet migration of a4f68900-568a-11ee-b7b9-c2b13945eed2:1 took 1.08004s seconds
2) Mutation stream: bytes on wire = 3030004736 bytes, bw = 125410.87 KiB/s = 128MB/s
[shard 0:stre] stream_session - [Stream #406dc8b0-56b5-11ee-bc2d-000bf4871058]
Streaming plan for Tablet migration-ks1-index-0 succeeded, peers={127.0.0.1}, tx=0 KiB, 0.00 KiB/s, rx=2958989 KiB, 125410.87 KiB/s
[shard 0:stre] storage_service - Streaming for tablet migration of a4f68900-568a-11ee-b7b9-c2b13945eed2:1 took 23.5992s seconds
Test Summary:
File stream v.s. Mutation stream improvements
- Stream bandwidth = 836 / 128 (MB/s) = 6.53X
- Stream time = 23.60 / 1.08 (Seconds) = 21.85X
- Stream bytes on wire = 3030004736 / 1132006250 (Bytes)= 2.67X
Closes scylladb/scylla-enterprise#3438
* github.com:scylladb/scylla-enterprise:
tests: Add file_stream_test
streaming: Implement file stream for tablet
*) streaming: Use new take_storage_snapshot interface
The new take_storage_snapshot returns a file object instead of a file
name. This allows the file stream sender to read from the file even if
the file is deleted by compaction.
Closes scylladb/scylla-enterprise#3728
*) streaming: Protect unsupported file types for file stream
Currently, we assume the file streamed over the stream_blob rpc verb is
a sstable file. This patch rejects the unsupported file types on the
receiver side. This allows us to stream more file types later using the
current file stream infrastructure without worrying about old nodes
processing the new file types in the wrong way.
- The file_ops::noop is renamed to file_ops::stream_sstables to be
explicit about the file types
- A missing test_file_stream_error_injection is added to the idl
Fixes: #3846
Tests: test_unsupported_file_ops
Closesscylladb/scylla-enterprise#3847
*) idl: Add service::session_id id to idl
It will be used in the next patch.
Refs #3907
*) streaming: Protect file stream with topology_guard
Similar to "storage_service, tablets: Use session to guard tablet
streaming", this patch protects file stream with topology_guard.
Fixes#3907
*) streaming: Take service topology_guard under the try block
Taking the service::topology_guard could throw. Currently, it throws
outside the try block, so the rpc sink will not be closed, causing the
following assertion:
```
scylla: seastar/include/seastar/rpc/rpc_impl.hh:815: virtual
seastar::rpc::sink_impl<netw::serializer,
streaming::stream_blob_cmd_data>::~sink_impl() [Serializer =
netw::serializer, Out = <streaming::stream_blob_cmd_data>]: Assertion
`this->_con->get()->sink_closed()' failed.
```
To fix, move more code including the topology_guard taking code to the
try block.
Fixes https://github.com/scylladb/scylla-enterprise/issues/4106Closesscylladb/scylla-enterprise#4110
*) Merge 'Preserve original SSTable state with file based tablet migration' from Raphael "Raph" Carvalho
We're not preserving the SSTable state across file based migration, so
staging SSTables for example are being placed into main directory, and
consequently, we're mixing staging and non-staging data, losing the
ability to continue from where the old replica left off.
It's expected that the view update backlog is transferred from old
into new replica, as migration doesn't wait for leaving replica to
complete view update work (which can take long). Elasticity is preferred.
So this fix guarantees that the state of the SSTable will be preserved
by propagating it in form of subdirectory (each subdirectory is
statically mapped with a particular state).
The staging sstables aren't being registered into view update generator
yet, as that's supposed to be fixed in OSS (more details can be found
at https://github.com/scylladb/scylladb/issues/19149).
Fixes#4265.
Closesscylladb/scylla-enterprise#4267
* github.com:scylladb/scylla-enterprise:
tablet: Preserve original SSTable state with file based tablet migration
sstables: Add get method for sstable state
*) sstable: (Re-)add shareabled_components getter
*) Merge 'File streaming sstables: Use sstable source/sink to transfer snapshots' from Calle Wilund
Fixes#4246
Alternative approach/better separation of concern, transport vs. sstable layer. Builds on #4472, but fancier.
Ensures we transfer and pre-process scylla metadata for streamed
file blobs first, then properly apply receiving nodes local config
by using a source and sink layer exported from sstables, which
handles things like ordering, metadata filtering (on source) as well
as handling metadata and proper IO paths when writing data on
receiver node (sink).
This implementation maintains the statelessness of the current
design, and the delegated sink side will re-read and re-write the
metadata for each component processed. This is a little wasteful,
but the meta is small, and it is less error prone than trying to do
caching cross-shards etc. The transport is isolated from the
knowledge.
This is an alternative/complement to #4436 and #4472, fixing the
underlying issue. Note that while the layers/API:s here allows easy
fixing of other fundamental problems in the feature (such as
destination location etc), these are not included in the PR, to keep
it as close to the current behaviour as possible.
Closesscylladb/scylla-enterprise#4646
* github.com:scylladb/scylla-enterprise:
raft_tests: Copy/add a topology test with encryption
file streaming: Use sstable source/sink to transfer snapshots
sstables: Add source and sink objects + producers for transfering a snapshot
sstable::types: Add remove accessor for extension info in metadata
*) The change for error injection in merge commit 966ea5955dd8760:
File streaming now has "stream_mutation_fragments" error injection points
so test_table_dropped_during_streaming works with file streaming.
*) doc: document file-based streaming
This commit adds a description of the file-based streaming feature to the documentation.
It will be displayed in the docs using the scylladb_include_flag directive after
https://github.com/scylladb/scylladb/pull/20182 is merged, backported to branch-6.0,
and, in turn, branch-2024.2.
Refs https://github.com/scylladb/scylla-enterprise/issues/4585
Refs https://github.com/scylladb/scylla-enterprise/issues/4254Closesscylladb/scylla-enterprise#4587
*) doc: move File-based streaming to the Tablets source file-based-streaming
This commit moves the description of file-based streaming from a common include file
to the regular doc source file where tablets are described.
Closesscylladb/scylla-enterprise#4652
*) streaming: sstable_stream_sink_impl: abort: prevent null pointer dereference
Closesscylladb/scylladb#22034
Introduces a comprehensive audit system to track database operations for security
and compliance purposes. This change includes:
Core Components:
- New audit subsystem for logging database operations
- Service level integration for proper resource management
- CQL statement tracking with operation categories
- Login process integration for tenant management
Key Features:
- Configurable audit logging (syslog/table)
- Operation categorization (QUERY/DML/DDL/DCL/AUTH/ADMIN)
- Selective auditing by keyspace/table
- Password sanitization in audit logs
- Service level shares support (1-1000) for workload prioritization
- Proper lifecycle management and cleanup
I ran the dtests for audit (manually enabled) and they pass.
The in-repo tests pass.
Notably, there should be no non-whitespace changes between this and scylla-enterprise
Fixesscylladb/scylla-enterprise#4999Closesscylladb/scylladb#22147
* github.com:scylladb/scylladb:
audit: Add shares support to service level management
audit: Add service level support to CQL login process
audit: Add support to CQL statements
audit: Integrate audit subsystem into Scylla main process
audit: Add documentation for the audit subsystem
audit: Add the audit subsystem
cmake doesn't set a `-ffile-prefix-map` for source files. Among other things,
this results in absolute paths in Scylla logs:
```
Jan 11 09:59:11.462214 longevity-tls-50gb-3d-master-db-node-2dcd4a4a-5 scylla[16339]: scylla: /jenkins/workspace/scylla-master/next/scylla/utils/refcounted.hh:23: utils::refcounted::~refcounted(): Assertion `_count == 0' failed.
```
And it results in absolute paths in gdb, which makes it a hassle to get gdb to display
source code during debugging. (A build-specific `substitute-path` has to be
configured for that).
There is a `-file-prefix-map` rule for `CMAKE_BINARY_DIR`,
but it's wrong.
Patch dbb056f4f7, which added it,
was misguided.
What we want is to strip the leading components of paths up to
the repository directory, both in __FILE__ macros and in debug info.
For example, we want to convert /home/michal/scylla/replica/table.cc to
replica/table.cc or ./replica/table.cc, both in Scylla logs and in gdb.
What the current rule does is it maps `/home/michal/scylla/build` to `.`,
which is wrong: it doesn't do anything about the paths outside of `build`,
which are the ones we actually care about.
This patch fixes the problem.
Closesscylladb/scylladb#22311
This change introduces a new audit subsystem that allows tracking and logging of database operations for security and compliance purposes. Key features include:
- Configurable audit logging to either syslog or a dedicated system table (audit.audit_log)
- Selective auditing based on:
- Operation categories (QUERY, DML, DDL, DCL, AUTH, ADMIN)
- Specific keyspaces
- Specific tables
- New configuration options:
- audit: Controls audit destination (none/syslog/table)
- audit_categories: Comma-separated list of operation categories to audit
- audit_tables: Specific tables to audit
- audit_keyspaces: Specific keyspaces to audit
- audit_unix_socket_path: Path for syslog socket
- audit_syslog_write_buffer_size: Buffer size for syslog writes
The audit logs capture details including:
- Operation timestamp
- Node and client IP addresses
- Operation category and query
- Username
- Success/failure status
- Affected keyspace and table names
Fixes https://github.com/scylladb/scylla-enterprise/issues/5016#issuecomment-2558464631
EAR - encryption at rest. Allows on-disk file encryption of sstables and commitlog data.
Introduces OpenSSL based file level encrypted storage, managed via a set of providers
ranging from local files to cloud KMS providers.
For a more comprehensive explanation, see the included docs (or if possible, original
source tree).
Manual bulk merge of EAR feature from enterprise repo to main scylla repo.
Breaks some features apart, but main EAR is still a humongous commit, because to separate this
I would have to mess with code incrementally, adding time and risk.
This PR includes the local file gen tool, tests and also p11 validation.
Note: CI will not execute the full tests unless master CI is set to provide the same environment
as the enterprise one. Not sure about the status of this ATM.
Note: Includes code to compile against cryptsoft kmipc SDK, but not the SDK. If you happen to
check out this tree in the scylla folder and configure, it will be linked against and KMIP functionality
will be enabled, otherwise not.
Closesscylladb/scylladb#22233
* github.com:scylladb/scylladb:
docs: Add EAR docs
main/build: Add p11-kit and initialize
tools: Add local-file-key-generator tool
tests: Add EAR tests
tmpdir: shorten test tempdir path
EAR: port the ear feature from enterprise
cql_test_env: Add optional query timeout
schema/migration_manager: Add schema validate
sstables: add get_shared_components accessor
config/config_file: Add exports and definitions of config_type_for<>
Instantiated only on shard 0.
Currently, only subscribe from unit test
Manual unit test using loop mount was added.
Note that the test requires sudo access
and root access to /dev/loop, so it cannot
run in rootless podman instance, and it'd
fail with Permission denied.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Closesscylladb/scylladb#21523
This PR extends authentication with 2 mechanisms:
- a new role_manager subclass, which allows managing users via
LDAP server,
- a new authenticator, which delegates plaintext authentication
to a running saslauthd daemon.
The features have been ported from the enterprise repository
with their test.py tests and the documentation as part of
changing license to source available.
Fixes: scylladb/scylla-enterprise#5000Fixes: scylladb/scylla-enterprise#5001Closesscylladb/scylladb#22030
Bulk transfer of EAR functionality. Includes all providers etc.
Could maybe break up into smaller blocks, but once it gets down to
the core of it, would require messing with code instead of just moving.
So this is it.
Note: KMIP support is disabled unless you happen to have the kmipc
SDK in your scylla dir.
Adds optional encryption of sstables and commitlog, using block
level file encryption. Provides key sourcing from various sources,
such as local files or popular KMS systems.
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
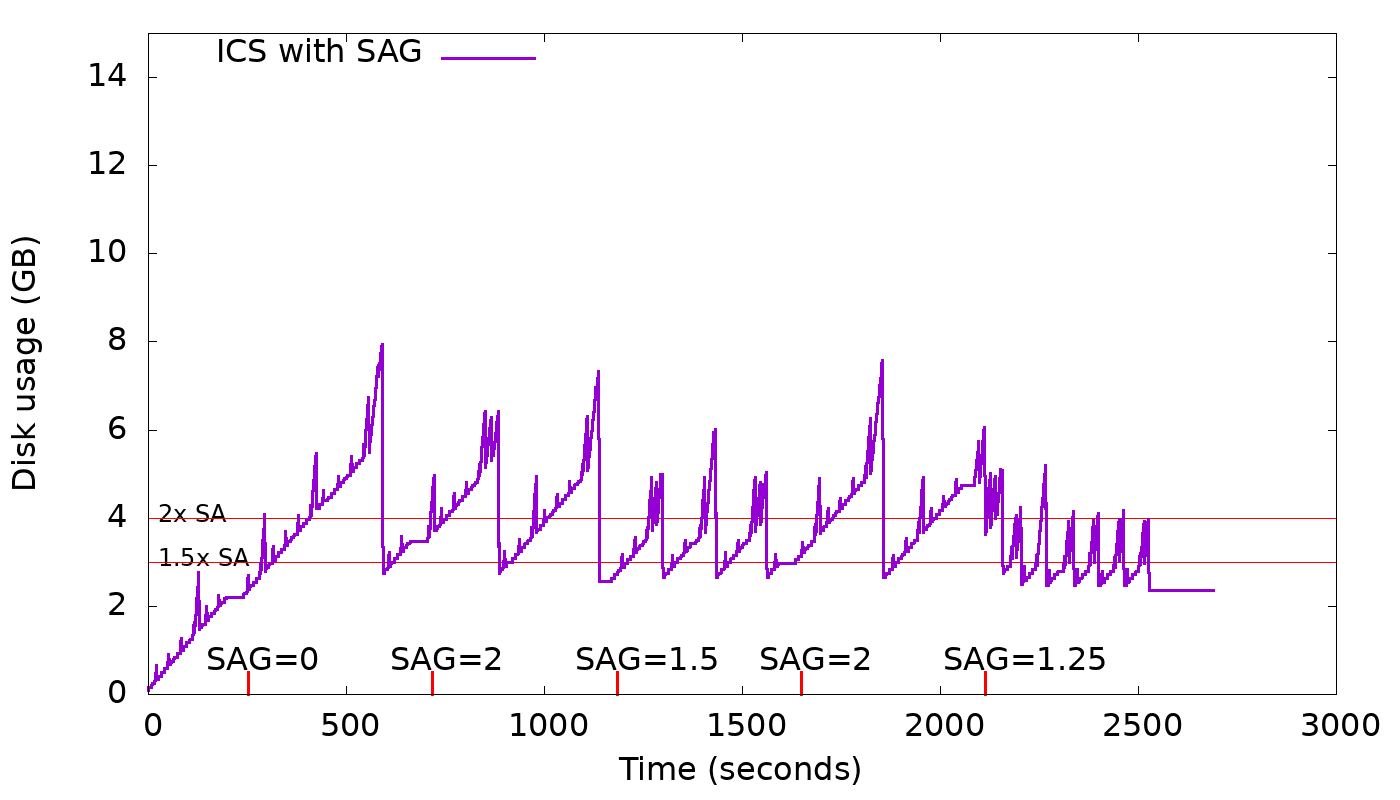
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
This series introduces workload prioritization: an extension of the service levels feature which allows specifying "shares" per service level. The number of shares determines the priority of the user which has this service level attached (if multiple are attached then the one with the lowest shares wins).
Different service levels will be isolated in the following way:
- Each service level gets its own scheduling group with the number of shares (corresponding to the service level's number of shares), which controls the priority of the CPU and I/O used for user operations running on that service level.
- Each service level gets two reader concurrency semaphores, one for user reads and the other for read-before-write done for view updates.
- Each service level gets its own TCP connections for RPC to prevent priority inversion issues.
Because of the mandatory use of scheduling groups, which are a globally limited resource, the number of service levels is now limited to 7 user created service levels + 1 created by default that cannot be removed.
This feature has been previously only available in ScyllaDB Enterprise but has been made available for the source available ScyllaDB. The series was created by comparing the master branch with source-available-workbranch / enterprise branch and taking the workload prioritization related parts from the diff, then molding the resulting diff into a proper series. Some very minor changes were made such as fixing whitespace, removing unused or unnecessary code, adding some boilerplate (in api/) which was missing, but otherwise no major changes have been made.
No backport is required.
Closesscylladb/scylladb#22031
* github.com:scylladb/scylladb:
tracing: record scheduling group in trace event record
qos: un-shared-from-this standard_service_level_distributed_data_accessor
alternator: execute under scheduling group for service level
test.py: support multiple commands in prepare_cql in suite.yml
docs: add documentation for workload prioritization
docs/dev: describe workload prioritization features in service_levels
test/auth_cluster: test workload prioritization in service level tests
cqlpy/test_service_levels: add workload prioritization tests
api: introduce service levels specific API
api/cql_server_test: add information about scheduling group
db/virtual_tables: add scheduling group column to system.clients
test/boost: update service_level_controller_test for workload prio
qos: include number of shares in DESCRIBE
cql3/statements: update SL statements for workload prioritization
transport/server: use scheduling group assigned to current user
messaging_service: use separate set of connections per service levels
replica/database: add reader concurrency semaphore groups
qos: manage and assign scheduling groups to service levels
qos: use the shares field in service level reads/writes
qos: add shares to service_level_options
qos: explicitly specify columns when querying service level tables
db/system_distributed_keyspace: add shares column and upgrade code
db/system_keyspace: adjust SL schema for workload prioritization
gms: introduce WORKLOAD_PRIORITIZATION cluster feature
build: increase the max number of scheduling groups
qos: return correct error code when SL does not exist
Introduces two endpoints with operations specific to service levels:
- switch_tenants: updates the scheduling group of all connections to be
aligned with the service level specific to the logged in user. This is
mostly legacy API, as with service levels on raft this is done
automatically.
- count_connections: for each user and for each scheduling group, counts
how many connections are assigned to that user and scheduling group.
This API is used in tests.
Replace the reader concurrency semaphores for user reads and view
updates with the newly introduced reader concurrency semaphore group,
which assigns a semaphore for each service level.
Each group is statically assigned to some pool of memory on startup and
dynamically distribute this memory between the semaphores, relative to
the number of shares of the corresponding scheduling group.
The intent of having a separate reader concurrency semaphore for each
scheduling group is to prevent priority inversion issues due to reads
with different priorities waiting on the same semaphore, as well as make
memory allocation more fair between service levels due to the adjusted
number of shares.
Workload prioritization assigns scheduling groups to service levels, and
the number of scheduling groups that can exist at the same time is
limited with a compile-time parameter in seastar. The documentation for
workload prioritization says that we currently support 7 user-managed
service levels and 1 created by default. Increase the current
compile-time limit in order to align with the documentation.
This is a forward port (from scylla-enterprise) of additional compression options (zstd, dictionaries shared across messages) for inter-node network traffic. It works as follows:
After the patch, messaging_service (Scylla's interface for all inter-node communication)
compresses its network traffic with compressors managed by
the new advanced_rpc_compression::tracker. Those compressors compress with lz4,
but can also be configured to use zstd as long as a CPU usage limit isn't crossed.
A precomputed compression dictionary can be fed to the tracker. Each connection
handled by the tracker will then start a negotiation with the other end to switch
to this dictionary, and when it succeeds, the connection will start being compressed using that dictionary.
All traffic going through the tracker is passed as a single merged "stream" through dict_sampler.
dictionary_service has access to the dict_sampler.
On chosen nodes (in the "usual" configuration: the Raft leader), it uses the sampler to maintain
a random multi-megabyte sample of the sampler's stream. Every several minutes,
it copies the sample, trains a compression dictionary on it (by calling zstd's
training library via the alien_worker thread) and publishes the new dictionary
to system.dicts via Raft's write_mutation command.
This update triggers (eventually) a callback on all nodes, which feeds the new dictionary
to advanced_rpc_compression::tracker, and this switches (eventually) all inter-node connections
to this dictionary.
Closesscylladb/scylladb#22032
* github.com:scylladb/scylladb:
messaging_service: use advanced_rpc_compression::tracker for compression
message/dictionary_service: introduce dictionary_service
service: make Raft group 0 aware of system.dicts
db/system_keyspace: add system.dicts
utils: add advanced_rpc_compressor
utils: add dict_trainer
utils: introduce reservoir_sampling
utils: introduce alien_worker
utils: add stream_compressor
- "Scylla_BUILD_INSTRUMENTED" option
Scylla_BUILD_INSTRUMENTED allows us to instrument the code at
different level, namely, IR, and CSIR. this option mirrors
"--pgo" and "--cspgo" options in `configure.py` . please note,
the instrumentation at the frontend is not supported, as the IR
based instrumentation is better when it comes to the use case of
optimization for performance.
see https://lists.llvm.org/pipermail/llvm-dev/2015-August/089044.html
for the rationales.
- "Scylla_PROFDATA_FILE" option
this option allows us to specify the profile data previous generated
with the "Scylla_BUILD_INSTRUMENTED" option. this option mirrors
the `--use-profile` option in `configure.py`, but it does not
take the empty option as a special case and consider it as a file
fetched from Git LFS. that will be handled by another option in a
follow-up change. please note, one cannot use
-DScylla_BUILD_INSTRUMENTED=PGO and -DScylla_PROFDATA_FILE=...
at the same time. clang just does not allow this. but CSPGO is fine.
- "Scylla_PROFDATA_COMPRESSED_FILE" option
this option allows us to specify the compressed profile data previouly
generated with the "Scylla_BUILD_INSTRUMENTED" option. along with
"Scylla_PROFDATA_FILE", this option mirros the functionality of
`--use-profile` in `configure.py`. the goal is to ensure user always
gets the result with the specified options. if anything goes wrong,
we just error out.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
add an option named "Scylla_ENABLE_LTO", which is off by default.
if it is on, build the whole tree with ThinLTO enabled.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
This change extends scylla commit 7cb74df to scylla-enterprise-commit
4ece7e1.
we recently started building Seastar as an external project, so
we need to prepare its compilation flags separately. in enterprise
scylla, we prepare the LTO and PGO related cflags in
`prepare_advanced_optimizations()`. this function is called when
preparing the build rules directly from `configure.py`, and despite
we have equivalant settings in CMake, they cannot be applied to Seastar
due to the reason above.
in this change, we set up the the LTO and PGO compilation flags when
generating the buiding system for Seastar when building using CMake.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
This patch adds the following logic to the release build:
pgo/profiles/profile.profdata.xz is the default profile file, compressed.
This file is stored in version control using git LFS.
A ninja rule is added which creates build/profile.profdata by decompressing it.
If no profile file is explicitly specified, ./configure.py checks whether
the compressed default profile file exists and is compressed.
(If it exists, but isn't compressed, the user most likely has
git lfs disabled or not installed. In this case, the file visible in the working
tree will be the LFS placeholder text file describing the LFS metadata.)
If the compressed file exists, build/profile.profdata is chosen as the used
profile file.
If it doesn't exist, a warning is printed and configure.py falls back
to a profileless build.
The default profile file can be explicitly disabled by passing the empty
--use-profile="" to configure.py
A script is added which re-generates the profile.
After the script is run, the re-generated compressed profile can be staged,
committed, pushed and merged to update the default profile.
This commit enables profile-guided optimizations (PGO) in the Scylla build.
A full LLVM PGO requires 3 builds:
1. With -fprofile-generate to generate context-free (pre-inlining) profile. This
profile influences inlining, indirect-call promotion and call graph
simplifications.
2. With -fprofile-use=results_of_build_1 -fcs-profile-generate to generate
context-sensitive (post-inlining) profile. This profile influences post-inline
and codegen optimizations.
3. With -fprofile-use=merged_results_of_builds_1_2 to build the final binary
with both profiles.
We do all three in one ninja call by adding release-pgo and release-cs-pgo
"stages" to release. They are a copy of regular release mode, just with the
flags described above added. With the full course, release objects depend on the
profile file produced by build/release-cs-pgo/scylla, while release-cs-pgo
depends on the profile file generated by build/release-pgo/scylla.
The stages are orthogonal and enabled with separate options. It's recommended
to run them both for full performance, but unfortunately each one adds a full
build of scylla to the compile time, so maybe we can drop one of them in the
future if it turns out e.g. that regular PGO doesn't have a big effect.
It's strongly recommended to combine PGO with LTO. The latter enables the entire
class of binary layout optimizations, which for us is probably the most
important part of the entire thing.
This patch introduces link-time optimization (LTO) to the build.
The performance gains from LTO alone are modest (~7%), but it's vital ingredient
of effective profile-guided optimization, which will be introduced later.
In general, use of LTO is quite simple and transparent to build systems.
It is sufficient to add the -flto flag to compile and link steps, and use a
LTO-aware linker.
At compile time, -ffat-lto-objects will cause the compiler to emit .o
files both LTO-ready LLVM IR for main executable optimization and machine
code for fast test linking. At link time, those pieces of IR will be
compiled together, allowing cross-object optimization of the main
executable and the fast linking of test executables.
Due to it's high compile time cost, the optimization can be toggled with a
configure.py option. As of this patch, it's disabled by default.
benchmark sort_by_proximity
Baseline results on my desktop for sorting 3 nodes:
single run iterations: 0
single run duration: 1.000s
number of runs: 5
number of cores: 1
random seed: 20241224
test iterations median mad min max allocs tasks inst cycles
sort_by_proximity_topology.perf_sort_by_proximity 12808773 77.368ns 0.062ns 77.300ns 77.873ns 0.000 0.000 1194.2 231.6
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
This "service" is a bag for code responsible for dictionary training,
created to unclutter main() from dictionary-specific logic.
It starts the RPC dictionary training loop when the relevant cluster feature is enabled,
pauses and unpauses it appropriately whenever relevant config or leadership
status are updated, and publishes new dictionaries whenever the training fiber produces them.
Adds glue needed to pass lz4 and zstd with streaming and/or dictionaries
as the network traffic compressors for Seastar's RPC servers.
The main jobs of this glue are:
1. Implementing the API expected by Seastar from RPC compressors.
2. Expose metrics about the effectiveness of the compression.
3. Allow dynamically switching algorithms and dictionaries on a running
connection, without any extra waits.
The biggest design decision here is that the choice of algorithm and dictionary
is negotiated by both sides of the connection, not dictated unilaterally by the
sender.
The negotiation algorithm is fairly complicated (a TLA+ model validating
it is included in the commit). Unilateral compression choice would be much simpler.
However, negotiation avoids re-sending the same dictionary over every
connection in the cluster after dictionary updates (with one-way communication,
it's the only reliable way to ensure that our receiver possesses the dictionary
we are about to start using), lets receivers ask for a cheaper compression mode
if they want, and lets them refuse to update a dictionary if they don't think
they have enough free memory for that.
In hindsight, those properties probably weren't worth the extra complexity and
extra development effort.
Zstd can be quite expensive, so this patch also includes a mechanism which
temporarily downgrades the compressor from zstd to lz4 if zstd has been
using too much CPU in a given slice of time. But it should be noted that
this can't be treated as a reliable "protection" from negative performance
effects of zstd, since a downgrade can happen on the sender side,
and receivers are at the mercy of senders.
We are planning to improve some usages of compression in Scylla
(in which we compress small blocks of data) by pre-training
compression dictionaries on similar data seen so far.
For example, many RPC messages have similar structure
(and likely similar data), so the similarity could be exploited
for better compression. This can be achieved e.g. by training
a dictionary on the RPC traffic, and compressing subsequent
RPC messages against that dictionary.
To work well, the training should be fed a representative sample
of the compressible data. Such a sample can be approached by
taking a random subset (of some given reasonable size) of the data,
with uniform probability.
For our purposes, we need an online algorithm for this -- one
which can select the random k-subset from a stream of arbitrary
size (e.g. all RPC traffic over an hour), while requiring only
the necessary minimum of memory.
This is a known problem, called "reservoir sampling".
This PR introduces `reservoir_sampler`, which implements
an optimal algorithm for reservoir sampling.
Additionally, it introduces `page_sampler` -- a wrapper for `reservoir_sampler`,
which uses it to select a random sample of pages from a stream of bytes.
Introduces a util which launches a new OS thread and accepts
callables for concurrent execution.
Meant to be created once at startup and used until shutdown,
for running nonpreemptible, 3rd party, non-interactive code.
Note: this new utility is almost identical to wasm::alien_thread_runner.
Maybe we should unify them.
Adds utilities for "advanced" methods of compression with lz4
and zstd -- with streaming (a history buffer persisted across messages)
and/or precomputed dictionaries.
This patch is mostly just glue needed to use the underlying
libraries with discontiguous input and output buffers, and for reusing the
same compressor context objects across messages. It doesn't contain
any innovations of its own.
There is one "design decision" in the patch. The block format of LZ4
doesn't contain the length of the compressed blocks. At decompression
time, that length must be delivered to the decompressor by a channel
separate to the compressed block itself. In `lz4_cstream`, we deal
with that by prepending a variable-length integer containing the
compressed size to each compressed block. This is suboptimal for
single-fragment messages, since the user of lz4_cstream is likely
going to remember the length of the whole message anyway,
which makes the length prepended to the block redundant.
But a loss of 1 byte is probably acceptable for most uses.
To reduce test executable size and speed up compilation time, compile unit
tests into a single executable.
Here is a file size comparison of the unit test executable:
- Before applying the patch
$ du -h --exclude='*.o' --exclude='*.o.d' build/release/test/boost/ build/debug/test/boost/
11G build/release/test/boost/
29G build/debug/test/boost/
- After applying the patch
du -h --exclude='*.o' --exclude='*.o.d' build/release/test/boost/ build/debug/test/boost/
5.5G build/release/test/boost/
19G build/debug/test/boost/
It reduces executable sizes 5.5GB on release, and 10GB on debug.
Closes#9155Closesscylladb/scylladb#21443
"
The series moves node ops, repair and streaming verbs to IDL. Also
contains IDL related cleanups.
In addition to the CI tested manually by bootstrapping a node with the
series into a cluster of old nodes with repair and streaming both in
gossiper and raft mode. This exercises repair, streaming and node_ops
paths.
"
* 'gleb/move-more-rpcs-to-idl-v3' of github.com:scylladb/scylla-dev:
repair: repair_flush_hints_batchlog_request::target_nodes is not used any more, so mark it as such
streaming: move streaming verbs to IDL
messaging_service: move repair verbs to IDL
node_ops: move node_ops_cmd to IDL
idl: rename partition_checksum.dist.hh to repair.dist.hh
idl: move node_ops related stuff from the repair related IDL
To be used by the tool apps -- also change the backend selected in
tools::utils::configure_tool_mode().
We keep using the more mature AIO backend in ScyllaDB itself, so main.cc
sets the linux_aio backend as the default one (the user can still change
this, same as before).
"
This rather large patch series moves storage proxy and some adjacent
services (like migration manager) to use host ids to identify nodes rather
than ips. Messaging service gains a capability to address nodes by host
ids (which allows dropping translations from topology coordinator code
that worked on host ids already) and also makes sure that a node with
incorrect host id will reject a message (can happen during address
changes).
The series gets rid of the raft address map completely and replaces it with
the gossiper address map which is managed by the gossiper since translation
is now done in the layer below raft.
Fixes: scylladb/scylladb#6403
perf-simple-query -- smp 1 -m 1G output
Before:
enable-cache=1
Running test with config: {partitions=10000, concurrency=100, mode=read, frontend=cql, query_single_key=no, counters=no}
Disabling auto compaction
Creating 10000 partitions...
64336.82 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41291 insns/op, 24485 cycles/op, 0 errors)
62669.58 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41277 insns/op, 24695 cycles/op, 0 errors)
69172.12 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.2 tasks/op, 41326 insns/op, 24463 cycles/op, 0 errors)
56706.60 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41143 insns/op, 24513 cycles/op, 0 errors)
56416.65 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41186 insns/op, 24851 cycles/op, 0 errors)
throughput: mean=61860.35 standard-deviation=5395.48 median=62669.58 median-absolute-deviation=5153.75 maximum=69172.12 minimum=56416.65
instructions_per_op: mean=41244.62 standard-deviation=76.90 median=41276.94 median-absolute-deviation=58.55 maximum=41326.19 minimum=41142.80
cpu_cycles_per_op: mean=24601.35 standard-deviation=167.39 median=24512.64 median-absolute-deviation=116.65 maximum=24851.45 minimum=24462.70
After:
enable-cache=1
Running test with config: {partitions=10000, concurrency=100, mode=read, frontend=cql, query_single_key=no, counters=no}
Disabling auto compaction
Creating 10000 partitions...
65237.35 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.2 tasks/op, 40733 insns/op, 23145 cycles/op, 0 errors)
59283.09 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40624 insns/op, 23948 cycles/op, 0 errors)
70851.03 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40625 insns/op, 23027 cycles/op, 0 errors)
70549.61 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40650 insns/op, 23266 cycles/op, 0 errors)
68634.96 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40622 insns/op, 22935 cycles/op, 0 errors)
throughput: mean=66911.21 standard-deviation=4814.60 median=68634.96 median-absolute-deviation=3638.40 maximum=70851.03 minimum=59283.09
instructions_per_op: mean=40650.89 standard-deviation=47.55 median=40624.60 median-absolute-deviation=27.11 maximum=40733.37 minimum=40622.33
cpu_cycles_per_op: mean=23264.16 standard-deviation=402.12 median=23145.29 median-absolute-deviation=237.63 maximum=23947.96 minimum=22934.59
CI: https://jenkins.scylladb.com/job/scylla-master/job/scylla-ci/13531/
SCT (longevity-100gb-4h with nemesis_selector: ['topology_changes']): https://jenkins.scylladb.com/view/staging/job/scylla-staging/job/gleb/job/move-to-host-id/3/
Tested mixed cluster manually.
"
* 'gleb/move-to-host-id-v2' of github.com:scylladb/scylla-dev: (55 commits)
group0: drop unused field from replace_info struct
test: rename raft_address_map_test to address_map_test and move if from raft tests
raft_address_map: remove raft address map
topology coordinator: do not modify expire state for left/new nodes any more in raft address map
topology coordinator: drop expiring entries in gossiper address map on error injections since raft one is no longer used
group0: drop raft address map dependency from raft_rpc
group0: move raft_ticker_type definition from raft_address_map.hh
storage_service: do not update raft address map on gossiper events
group0: drop raft address map dependency from raft_server_with_timeouts
group0: move group0 upgrade code to host ids
repair: drop raft address map dependency
group0: remove unused raft address map getter from raft_group0
group0: drop raft address map from group0_state_machine dependency since it is not used there any more
group0: remove dependency on raft address map from group0_state_id_handler
gossiper: add get_application_state_ptr that searches by host_id
gossiper: change get_live_token_owners to return host ids
view: move view building to host id
hints: use host id to send hints
storage_proxy: remove id_vector_to_addr since it is no longer used
db: consistency_level: change is_sufficient_live_nodes to work on host ids
...
Add tablet task manager module and keep it in storage_service.
Introduce tablet_virtual_task that covers tablet repair.
Thanks to a repair virtual task, a user can check the list of pending
repairs, get the status of a specific repair, or abort it using the task
manager API.
Fixes: #21368.
No backport, new feature
Closesscylladb/scylladb#21624
* github.com:scylladb/scylladb:
test: add test to check tablet repair tasks
test: topology_tasks: enable tablets
service: keep tablets module in storage_service
service: rename storage_service::_task_manager_module
service: add tablet_virtual_task
tasks: utilize preliminary virtual task lookup
{kind=link}