Convert tasks::task_manager::task::impl::release_resources() to a coroutine
to prepare for upcoming changes that will implement asynchronous resource
release.
This is a preparatory refactoring that enables future coroutine-based
implementation of resource cleanup logic.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
(cherry picked from commit 4c1f1baab4)
Replace remaining uses of boost::adaptors::transformed with std::views::transform
to reduce Boost dependencies, following the migration pattern established in
bab12e3a. This change addresses recently merged code that reintroduced Boost
header dependencies through boost::adaptors::transformed usage.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22365
now that we are allowed to use C++23. we now have the luxury of using
`std::views::reverse`.
- replace `boost::adaptors::transformed` with `std::views::transform`
- remove unused `#include <boost/range/adaptor/reversed.hpp>`
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
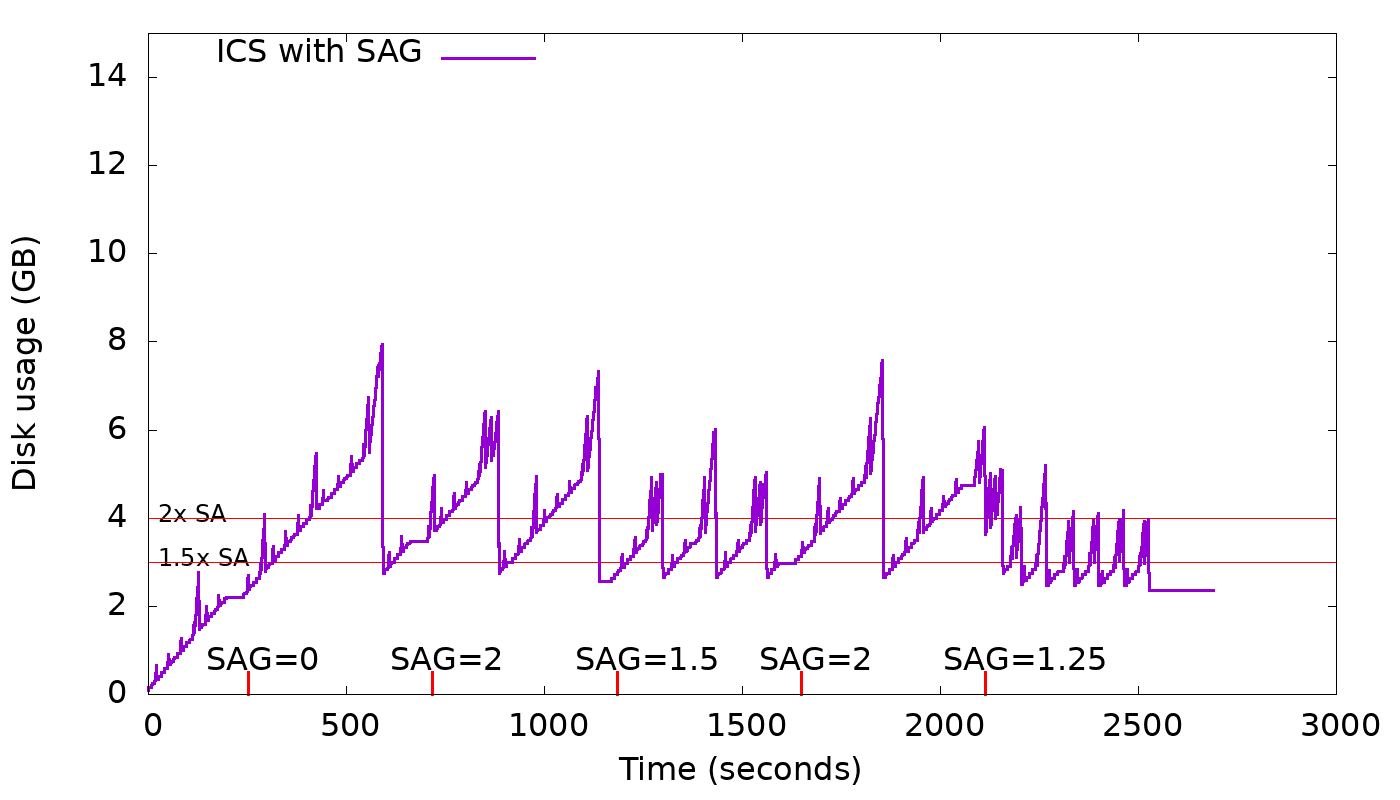
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
now that we are allowed to use C++23. we now have the luxury of using
`std::ranges::to`.
in this change, we:
- replace `boost::copy_range` to `std::ranges::to`
- remove unused `#include` of boost headers
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21880
now that we are allowed to use C++23. we now have the luxury of using
`std::views::transform`.
in this change, we:
- replace `boost::adaptors::transformed` with `std::views::transform`
- use `fmt::join()` when appropriate where `boost::algorithm::join()`
is not applicable to a range view returned by `std::view::transform`.
- use `std::ranges::fold_left()` to accumulate the range returned by
`std::view::transform`
- use `std::ranges::fold_left()` to get the maximum element in the
range returned by `std::view::transform`
- use `std::ranges::min()` to get the minimal element in the range
returned by `std::view::transform`
- use `std::ranges::equal()` to compare the range views returned
by `std::view::transform`
- remove unused `#include <boost/range/adaptor/transformed.hpp>`
- use `std::ranges::subrange()` instead of `boost::make_iterator_range()`,
to feed `std::views::transform()` a view range.
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
limitations:
there are still a couple places where we are still using
`boost::adaptors::transformed` due to the lack of a C++23 alternative
for `boost::join()` and `boost::adaptors::uniqued`.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21700
these unused includes are identified by clang-include-cleaner. after
auditing the source files, all of the reports have been confirmed.
please note, because `mutation/mutation.hh` does not include
`seastar/coroutine/maybe_yield.hh` anymore, and quite a few source
files were relying on this header to bring in the declaration of
`maybe_yield()`, we have to include this header in the places where
this symbol is used. the same applies to `seastar/core/when_all.hh`.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
tombstone_gc.hh is relatively lightweight and is used in many places,
but it includes the heavyweight boost/icl/interval_map.hh. Lighten
the load for its users by wrapping lw_shared_ptr<some icl map type>
in a forward-declared class. Define the class in a new header
tombstone_gc-internals.hh, to be used by the two translation units
that need it.
Ref #1.
Closesscylladb/scylladb#21706
When users start an operation asynchronously with API, they are expected to check the operation's status. Hence, the status should be kept in task manager for reasonable time after the operation is done. The operations that are started internally usually don't need to stay in task manager for that long.
Add api_task_ttl that will be used for tasks started with API. By default it's 1 hour. The time for which non-API tasks stay in task manager isn't changed.
Fixes: #21499.
Refs: #21425.
No backport needed - previous versions may use task_ttl
Closesscylladb/scylladb#21505
* github.com:scylladb/scylladb:
test: add test to check user_task_ttl
tasks: api: move make_task method
docs: nodetool: update backup and restore commands docs
docs: update task manager docs
nodetool: add nodetool tasks user-ttl command
node_ops: use user task ttl for node ops virtual task
tasks: use user_task_ttl for tasks started by user
api: task_manager: add /task_manager/user_ttl to get and set user task ttl
tasks: add task_manager::task::is_user_task method
tasks: keep updateable_value of task_ttl in task manager
db: config: add user_task_ttl_seconds named value
Modernize the codebase by replacing Boost range adaptors with C++23 standard library views,
reducing external dependencies and leveraging modern C++ language features.
Key Changes:
- Replace `boost::adaptors::filtered` with `std::views::filter`
- Remove `#include <boost/range/adaptor/filtered.hpp>`
- Utilize standard library range views
Motivation:
- Reduce project's external dependency footprint
- Leverage standard library's range and view capabilities
- Improve long-term code maintainability
- Align with modern C++ best practices
Implementation Challenges and Considerations:
1. Range Conversion and Move Semantics
- `std::ranges::to` adaptor requires rvalue references
- Necessitated updates to variable and parameter constness
- Example: `cql3/restrictions/statement_restrictions.cc` modified to remove `const`
from `common` to enable efficient range conversion
2. Range Iteration and Mutation
- Range views may mutate internal state during iteration
- Cannot pass ranges by const reference in some scenarios
- Solution: Pass ranges by rvalue reference to explicitly indicate
state invalidation
Limitations:
- One instance of `boost::adaptors::filtered` temporarily preserved
due to lack of a C++23 alternative for `boost::join()`
- A comprehensive replacement will be addressed in a follow-up change
This change is part of our ongoing effort to modernize the codebase,
reducing external dependencies and adopting modern C++ practices.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21648
This PR enables compaction tasks to verify the integrity of the input data through checksum and digest checks. The mechanism for integrity checking was introduced in previous PRs (#20207, #20720) as a built-in functionality of the input streams. This PR integrates this mechanism with compaction. The change applies to all compaction types and covers both compressed and uncompressed SSTables adhering to the 3.x format. If a compaction task reads only part of an SSTable, then only the per-chunk checksums are verified, not the digest.
The PR consists of:
* Changes to mx readers to support integrity checking. The kl readers, considered as compatibility-only, were left unchanged. Also, integrity checking on single-partition reversed reads (`data_consume_reversed_partition()`) remains unsupported by mx readers as this is not used in compaction.
* Changes to `sstable` and `sstable_set` APIs to allow toggling integrity checks for mx readers.
* Activation of integrity checking for all compaction types.
* Tests for all compaction types with corrupted SSTables.
Integrity checks come at a cost. For uncompressed SSTables, the cost is the loading of the CRC and Digest components from disk, and the calculation of checksums and digest from the actual data. For compressed SSTables, checksums are stored in-place and they are being checked already on all reads, so the only extra cost is the loading and calculation of the digest. The measurements show a ~5% regression in compaction performance for uncompressed SSTables, and a negligible regression for compressed SSTables.
Command: `perf-sstable --smp=1 --cpuset=1 --poll-mode --mode=compaction --iterations=1000 --partitions 10000 --sstables=1 --key_size=4096 --num_columns=15 --column_size={32, 1024, 3500, 7000, 14500}`
Uncompressed SSTables:
```
+--------------+-----------------------+----------------------+------------+
| SSTable Size | No Integrity (p/sec) | Integrity (p/sec) | Regression |
+--------------+-----------------------+----------------------+------------+
| 50 MiB | 65175.59 +- 80.82 | 61814.63 +- 72.88 | 5.16% |
| 200 MiB | 41795.10 +- 60.39 | 39686.28 +- 45.05 | 5.05% |
| 500 MiB | 21087.41 +- 30.72 | 20092.93 +- 25.05 | 4.72% |
| 1 GiB | 12781.64 +- 21.77 | 12233.94 +- 21.71 | 4.29% |
| 2 GiB | 6629.99 +- 9.40 | 6377.13 +- 8.28 | 3.81% |
+--------------+-----------------------+----------------------+------------+
```
Compressed SSTables:
```
+--------------+-----------------------+----------------------+------------+
| SSTable Size | No Integrity (p/sec) | Integrity (p/sec) | Regression |
+--------------+-----------------------+----------------------+------------+
| 50 MiB | 53975.05 +- 63.18 | 53825.93 +- 62.28 | 0.28% |
| 200 MiB | 28687.94 +- 26.58 | 28689.41 +- 26.91 | 0% |
| 500 MiB | 13865.35 +- 15.50 | 13790.41 +- 14.88 | 0.54% |
| 1 GiB | 7858.10 +- 7.71 | 7829.75 +- 9.66 | 0.36% |
| 2 GiB | 4023.11 +- 2.43 | 4010.54 +- 2.55 | 0.31% |
+--------------+-----------------------+----------------------+------------+
(p/sec = partitions/sec)
```
Refs #19071.
New feature, no backport is needed.
Closesscylladb/scylladb#21153
* github.com:scylladb/scylladb:
test: Add test for compaction with corrupted SSTables
compaction: Enable integrity checks for all compaction types
sstables: Add integrity option to factories for sstable_set readers
sstables: Add integrity option to sstable::make_reader()
sstables: Add integrity option to mx::make_reader()
sstables: Load checksums and digests in mx full-scan reader
sstables: Add integrity option to data_consume_single_partition()
sstables: Disengage integrity_check from sstable class
sstables: Allow data sources to disable digest check
Compaction tasks create mutation readers to read SSTables from disk.
Each compaction type defines its own reader creation logic by
implementing the pure virtual function `compaction::make_sstable_reader()`.
Modify all implementations of `make_sstable_reader()` to enable
integrity checking on the created readers. This way, all compaction
tasks will be able to detect corruption issues on the compacting
SSTables.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
Split compaction divides the partitions in an existing sstable into two
groups and writes them into two new sstables, which replace the original
one. The partition count from the original sstable is used as an
estimate when writing the new ones, but this estimate is not accurate as
the partitions are split between the two new sstables and each will
contain only a portion of the original partition count. This also causes
the bloom filters to be rebuilt at the end of compaction, as they were
initially built with inaccurate estimates.
Fix this by using a better estimate for the output sstables based on the
token ranges written to them.
Fixes scylladb#20253
Signed-off-by: Lakshmi Narayanan Sreethar <lakshmi.sreethar@scylladb.com>
we don't use `std::list` in compaction/compaction_manager.hh, neither
is this header responsible for exposing the declarations in `<list>`.
so let's stop `#include` this header.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21436
now that we are allowed to use C++23. we now have the luxury of using
`std::ranges::any_of`.
in this change, we replace `boost::algorithm::any_of` with
`std::ranges::any_of`
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
The current condition that consults the compaction manager
state for awaiting `_stop_future` works since _stop_future
is assigned after the state is set to `stopped`, but it is
incidental. What matters is that `_stop_future` is engaged.
While at it, exchange _stop_future with a ready future
so that stop() can be safely called multiple times.
And dropped the superfluous co_return.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
stop_ongoing_compactions now ignores any errors returned
by tasks, and it should leave no task left behind.
Assert that here, before the compaction_manager is destroyed.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
stop() methods, like destructors must always succeed,
and returning errors from them is futile as there is
nothing else we can do with them but continue with shutdown.
Leaked errors on the stop path may cause termination
on shutdown, when called in a deferred action destructor.
Fixesscylladb/scylladb#21298
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Stopped tasks currently linger in _tasks until the fiber that created
the task is scheduled again and unlinks the task. This window between
stop and remove prevents reliable checks for empty _tasks list after all
tasks are stopped.
Unlink the task early so really_do_stop() can safely check for an empty
_tasks list (next patch).
_tasks is currently std::list<shared_ptr<compaction_task_executor>>, but
it has no role in keeping the instances alive, this is done by the
fibers which create the task (and pin a shared ptr instance).
This lends itself to an intrusive list, avoiding that extra
allocation upon push_back().
Using an intrusive list also makes it simpler and much cheaper (O(1) vs.
O(N)) to remove tasks from the _tasks list. This will be made use of in
the next patch.
Code using _task has to be updated because the value_type changes from
shared_ptr<compaction_task_executor> to compaction_task_executor&.
This pattern is -- if requested (by test) suspend code execution until requestor (the test) explicitly wakes it up. For that the injected place should inject a lambda that is called with so called "handler" at hand and try to read message from the handler. In many cases the inner lambda additionally prints a message into logs that tests waits upon to make sure injection was stepped on. In the end of the day this "breakpoint" is injected like
```
co_await inject("foo", [] (auto& handler) {
log.info("foo waiting");
co_await handler.wait_for_message(timeout);
});
```
This PR makes breakpoints shorter and more unified, like this
```
co_await inject("foo", wait_for_message(timeout));
```
where `wait_for_message` is a wrapper structure used to pick new `inject()` overload.
Closesscylladb/scylladb#21342
* github.com:scylladb/scylladb:
sstables: Use inject(wait_for_message_overload)
treewide,error_injection: Use inject(wait_for_message) and fix tests
treewide,error_injection: Use inject(wait_for_message) overload
error_injection: Add inject() overload with wait_for_message wrapper
When a compaction_group is removed via `compaction_manager::remove`,
it is erase from `_compaction_state`, and therefore compaction
is definitely not enabled on it.
This triggers an internal error if tablets are cleaned up
during drop/truncate, which checks that compaction is disabled
in all compaction groups.
Note that the callers of `compaction_disabled` aren't really
interested in compaction being actively disabled on the
compaction_group, but rather if it's enabled or not.
A follow-up patch can be consider to reverse the logic
and expose `compaction_enabled` rather than `compaction_disabled`.
Fixesscylladb/scylladb#20060
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Closesscylladb/scylladb#21378
Many places want to inject a handler that waits for external kick. Now
there's convenience inject() method overload for this. It will result in
extra messages in logs, but so far no code/test cares about it.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Add documentation to clarify the purpose and behavior of
make_interpose_consumer() in the compaction_strategy_impl class. This
method is crucial for building layered processing pipelines but its
semantics were previously undocumented.
The added documentation explains how:
- It decorates end consumers with additional processing steps
- It enables construction of processing pipelines
- The original consumer's semantics are preserved
This improves code maintainability by making the pipeline construction
pattern more apparent to developers.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21336
now that we are allowed to use C++23. we now have the luxury of using
`std::views::values`.
in this change, we:
- replace `boost::adaptors::map_values` with `std::views::values`
- update affected code to work with `std::views::values`
- the places where we use `boost::join()` are not changed, because
we cannot use `std::views::concat` yet. this helper is only
available in C++26.
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21265
Currently, running the `nodetool compactionhistory` command or using the rest api `curl -X GET --header "Accept: application/json" "http://localhost:10000/compaction_manager/compaction_history"` return compaction history without the `row_merged` field.
The series computes rows merged during compaction and provides this information to users via both the nodetool command and the rest api. The `rows_merged` field contains information on merged clustering keys across multiple sstable files. For instance, compacting two sstables of a table consisting of 7 rows where two rows are part of the both sstables, the output would have the following format: {1: 5, 2: 2}.
No backport is required. It extends the existing compaction history output.
Fixes https://github.com/scylladb/scylladb/issues/666Closesscylladb/scylladb#20481
* github.com:scylladb/scylladb:
test/rest_api: Add tests for compactionhistory
nodetool: Add rows merged stats into compactionhistory output
compaction: Update compaction history with collected histogram
compaction: Remove const qualifier from methods creating sstable readers
sstable_set: Add optional statistics to make_local_shard_sstable_reader
make_combined_reader: Add optional parameter, combined_reader_statistics
reader_selector: Extend with maximum reader count
mutation_fragment_merger: Create histogram while consuming mutation fragment batches
A new field has been added to the compaction_stats structure to hold
collected combined reader statistics. The struct is than used to update
the compaction_history table.
Compaction classes start mutate their internal members to be used
in methods setup_sstable_reader and make_sstable_reader creating
sstable reades that are marked as const.
Remove the const qualifier from these methods. Even though it made
sense initially to mark them as const, it is no longer applicable.
the log.hh under the root of the tree was created keep the backward
compatibility when seastar was extracted into a separate library.
so log.hh should belong to `utils` directory, as it is based solely
on seastar, and can be used all subsystems.
in this change, we move log.hh into utils/log.hh to that it is more
modularized. and this also improves the readability, when one see
`#include "utils/log.hh"`, it is obvious that this source file
needs the logging system, instead of its own log facility -- please
note, we do have two other `log.hh` in the tree.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
since chrono allows dividion between durations with different units. let
use it instead for rounding down to the nearest multiple of the window
size, for better readability.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#20476
This includes way too much, including <boost/regex.hpp>, which is huge.
Drop includes of adaptors.hpp and replace by what is needed.
Closesscylladb/scylladb#21187
Add the gossip state for broadcasting the nodes state_id.
Implemented the Group0 state broadcaster (based on the gossip) that will broadcast the state id of each node and check the minimal state id for the tombstone GC.
When there is a change in the tombstone GC minimal state id, the state broadcaster will update the tombstone GC time for the group0-managed tables.
The main component of the change is the newly added `group0_state_id_handler` that keeps track, broadcasts and receives the last group0 state_ids across all nodes and sets the tombstone GC deletion time accordingly:
* on each group0 change applied, the state_id handler broadcasts the state_id as a gossip state (only if the value has changed)
* the handler checks for the node state ids every refresh period (configurable, 1h by default)
* on every check, the handler figures out the lowest state_id (timeuuid), which is state_id that all of the nodes already have
* the timestamp of this minimum state_id is then used to set the tombstone GC deletion time
* the tombstone GC calculation then uses that deletion time to provide the GC time back to the callers, e.g. when doing the compaction
* (as the time for tombstone GC calculation has the 1s granularity we actually deduce 1s from the determined timestamp, because it can happen that there were some newer mutations received in the same second that were not distributed across the nodes yet)
This change introduces a new flag to the static schema descriptor (`is_group0_table`) that is being checked for this newly added mode in the tombstone GC. We also add a check (in non-release builds only) on every group0 modification that the table has this flag set.
The group0 tombstone GC handling is similar to the "repair" tombstone GC mode in a sense (that the tombstone GC time is determined according to a reconciliation action), however it is not explicitly visible to (nor editable by) the user. And also the tombstone GC calculation is much simpler than the "repair" mode calculation - for example, we always use the whole range (as opposed to the "repair" mode that can have specific repair times set for specific ranges).
We use the group0 configuration to determine the set of nodes (both current and previous in case of joint configuration) - we need to make sure that we account for all the group0 nodes (if any node didn't provide the state_id yet, the current check round will be skipped, i.e. no GC will be done until all known nodes provide their state_id timestamp value).
Also note that the group0 state_id handling works on all nodes independently, i.e. each node might have its own (possibly different) state depending on the gossip application state propagation. This is however not a problem, as some nodes might be behind, but they will catch up eventually, and this solution has the benefit of being distributed (as opposed to having a central point to handle the state, like for example the topology coordinator that has been considered in the early stages of the design).
Fixes: scylladb/scylla#15607
New feature, should not be backported.
Closesscylladb/scylladb#20394
* github.com:scylladb/scylladb:
raft: add the check for the group0 tables
raft: fast tombstone GC for group0-managed tables
tombstone_gc: refactor the repair map
raft: flag the group0-managed tables
gossip: broadcast the group0 state id
raft/test: add test for the group0 tombstone GC
treewide: code cleanup and refactoring
This PR builds upon the PR for checksum validation (#20207) to further enhance scrub's corruption detection capabilities by validating digests as well. The digest (full checksum) is the checksum over the entire data, as opposed to per-chunk checksums which apply to individual chunks. Until now, digests were not examined on any code paths. This PR integrates digest checking into the compressed/checksummed data sources as an optional feature and enables it only through the validation path of the sstable layer (`sstable::validate()`). The validation path is used by the following tools:
* scrub in validate mode
* `sstable validate`
All other reads, including normal user reads, are unaffected by this change.
The PR consists of:
* Extensions to the compressed and checksummed data sources to support digest checking. The data sources receive the expected digest as a parameter and calculate the actual digest incrementally across multiple get() calls. The check happens on the get() call that reaches EOF and results to an exception if the digest is invalid. A digest check requires reading the whole file range. Therefore, a partial read or skip() is treated as an internal error.
* A new shareable digest component loaded on demand by the validation code. No lifecycle management.
* Grouping of old scrub/validate tests for compressed and uncompressed SSTables to reduce code duplication.
* scrub/validate tests for SSTables with valid checksums but invalid digests, and SSTables with no digests at all.
* scrub/validate tests with 3.x Cassandra SSTables to ensure compatibility.
Refs #19058.
New feature, no backport is needed.
Closesscylladb/scylladb#20720
* github.com:scylladb/scylladb:
test: Test scrub/validate with SSTables from Cassandra
compaction: Make quarantine optional for perform_sstable_scrub()
test: Make random schema optional in scrub_test_framework
test: Add tests for invalid digests
test: Merge scrub/validate tests for compressed and uncompressed cases
sstables: Verify digests on validation path
sstables: Check if digest component exists
sstables: Add digest in the SSTable components
sstables: Add digest check in compressed data source
sstables: Add digest check in checksummed data source
During shutdown, the compaction_manager starts stopping ongoing
compaction tasks through `really_do_stop()` method as soon as it
receives a signal from the abort source. Later, when the database object
shuts down, it calls `compaction_manager::drain` to ensure that all
compaction tasks have stopped. However, `compaction_manager::drain` is
currently implemented in such a way that, during shutdown, it
effectively becomes a no-op because the compaction_manager has already
initiated the stopping of tasks. As a result the caller assumes that all
the compaction tasks have stopped and proceeds to close all the tables.
This can lead to race conditions where table closures overlap with
compaction tasks that are still running, resulting in exceptions like :
```
exception during mutation write to 127.0.0.1:
utils::internal::nested_exception<std::runtime_error> (Could not write
mutation system:compaction_history
(pk{0010b70d31705e0411efb2edf6467f094c8b}) to commitlog):
seastar::gate_closed_exception (gate closed)
```
This commit fixes the issue by updating `compaction_manager::drain` to
invoke `stop_ongoing_compactions` even during shutdown to ensure that it
waits for the ongoing compaction tasks to complete. The
`stop_ongoing_compactions` method will also send a stop request to these
tasks before waiting, but the request will be ignored by the tasks as
they would have already received one earlier from `really_do_stop()`.
Fixes#20197
Signed-off-by: Lakshmi Narayanan Sreethar <lakshmi.sreethar@scylladb.com>
Closesscylladb/scylladb#20715
Move the repair_map definition to the tombstone_gc file where it is
mostly being used.
Refactor and add the accessors and setters for the group0 tombstone GC
time.
Currently, `estimated_pending_compactions` uses a precalculated value calculated by `update_estimated_compaction_by_tasks`, which, in turn, is called by `get_compaction_candidates`. That means that, if `estimated_pending_compactions` is called, e.g. right after major compaction, it will return an outdated value that was calculated prior to major compaction, and so, it is no longer relevant.
Instead, just recalculate the value in `estimated_pending_compactions` and drop `update_estimated_compaction_by_tasks`.
* Enhancement, no backport required
Closesscylladb/scylladb#20892
* github.com:scylladb/scylladb:
test: cql-pytest: test_compaction: add test_compactionstats_after_major_compaction
test/cql-pytest: rename test_compaction{_tombstone_gc,}
time_window_compaction_strategy: estimated_pending_compactions: reestimate compactions rather than using cached value
Allow `perform_sstable_scrub()` to disable quarantine for invalid
SSTables detected by scrub in validate mode. This is already supported
by the lower-level function `scrub_sstables_validate_mode()` via the
flag `quarantine_sstables` and is being used by sstable-scrub.
Propagate the flag up to `perform_sstable_scrub()`. This will allow to
test scrub/validate against read-only SSTables from the source tree.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
simpler this way. `sst` does not help with the readability or
performance, but let's drop it. simpler this way. also, remove the
unused parameter.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#20961
Currently, `estimated_pending_compactions` uses a precalculated value
calculated by `update_estimated_compaction_by_tasks`, which, in turn,
is called by `get_compaction_candidates`. That means that, if
`estimated_pending_compactions` is called, e.g. right after
major compaction, it will return an outdated value that was
calculated prior to major compaction, and so, it is no longer
relevant.
Instead, just recalculate the value in `estimated_pending_compactions`
and drop `update_estimated_compaction_by_tasks`.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
During split prepare phase, there will be more than 1 compaction group with
overlapping token range for a given replica.
Assume tablet 1 has sstable A containing deleted data, and sstable B containing
a tombstone that shadows data in A.
Then split starts:
1) sstable B is split first, and moved from main (unsplit) group to a
split-ready group
2) now compaction runs in split-ready group before sstable A is split
tombstone GC logic today only looks at underlying group, so compaction is step
2 will discard the deleted data in A, since it belongs to another group (the
unsplit one), and so the tombstone can be purged incorrectly.
To fix it, compaction will now work with all uncompacting sstables that belong
to the same replica, since tombstone GC requires all sstables that possibly
contain shadowed data to be available for correct decision to be made.
Fixes https://github.com/scylladb/scylladb/issues/20044.
Branches 6.0, 6.1 and 6.2 are vulnerable, so backport is needed.
Closesscylladb/scylladb#20939
* github.com:scylladb/scylladb:
replica: Fix tombstone GC during tablet split preparation
service: Improve error handling for split
when building scylla with the standard library from GCC-14.2, shipped by
fedora 41, we have following build failure:
```
/home/kefu/.local/bin/clang++ -DDEBUG -DDEBUG_LSA_SANITIZER -DFMT_SHARED -DSANITIZE -DSCYLLA_BUILD_MODE=debug -DSCYLLA_ENABLE_ERROR_INJECTION -DSEASTAR_API_LEVEL=7 -DSEASTAR_DEBUG -DSEASTAR_DEBUG_PROMISE -DSEASTAR_DEBUG_SHARED_PTR -DSEASTAR_DEFAULT_ALLOCATOR -DSEASTAR_LOGGER_COMPILE_TIME_FMT -DSEASTAR_LOGGER_TYPE_STDOUT -DSEASTAR_SCHEDULING_GROUPS_COUNT=16 -DSEASTAR_SHUFFLE_TASK_QUEUE -DSEASTAR_SSTRING -DSEASTAR_TYPE_ERASE_MORE -DXXH_PRIVATE_API -DCMAKE_INTDIR=\"Debug\" -I/home/kefu/dev/scylladb -I/home/kefu/dev/scylladb/build/gen -I/home/kefu/dev/scylladb/seastar/include -I/home/kefu/dev/scylladb/build/seastar/gen/include -I/home/kefu/dev/scylladb/build/seastar/gen/src -isystem /home/kefu/dev/scylladb/abseil -g -Og -g -gz -std=gnu++23 -fvisibility=hidden -Wall -Werror -Wextra -Wno-error=deprecated-declarations -Wimplicit-fallthrough -Wno-c++11-narrowing -Wno-deprecated-copy -Wno-mismatched-tags -Wno-missing-field-initializers -Wno-overloaded-virtual -Wno-unsupported-friend -Wno-unused-parameter -ffile-prefix-map=/home/kefu/dev/scylladb/build=. -march=x86-64-v3 -mpclmul -Xclang -fexperimental-assignment-tracking=disabled -Werror=unused-result -fstack-clash-protection -fsanitize=address -fsanitize=undefined -MD -MT CMakeFiles/scylla-main.dir/Debug/init.cc.o -MF CMakeFiles/scylla-main.dir/Debug/init.cc.o.d -o CMakeFiles/scylla-main.dir/Debug/init.cc.o -c /home/kefu/dev/scylladb/init.cc
In file included from /home/kefu/dev/scylladb/init.cc:12:
In file included from /home/kefu/dev/scylladb/db/config.hh:20:
In file included from /home/kefu/dev/scylladb/locator/abstract_replication_strategy.hh:26:
/home/kefu/dev/scylladb/locator/tablets.hh:410:30: error: unexpected type name 'size_t': expected expression
410 | return boost::irange<size_t>(0, tablet_count()) | boost::adaptors::transformed([] (size_t i) {
| ^
/home/kefu/dev/scylladb/locator/tablets.hh:410:23: error: no member named 'irange' in namespace 'boost'
410 | return boost::irange<size_t>(0, tablet_count()) | boost::adaptors::transformed([] (size_t i) {
| ~~~~~~~^
/home/kefu/dev/scylladb/locator/tablets.hh:410:38: error: left operand of comma operator has no effect [-Werror,-Wunused-value]
410 | return boost::irange<size_t>(0, tablet_count()) | boost::adaptors::transformed([] (size_t i) {
| ^
3 errors generated.
[16/782] Building CXX object CMakeFiles/scylla-main.dir/Debug/keys.cc.o
[17/782] Building CXX object CMakeFiles/scylla-main.dir/Debug/counters.cc.o
[18/782] Building CXX object CMakeFiles/scylla-main.dir/Debug/partition_slice_builder.cc.o
[19/782] Building CXX object CMakeFiles/scylla-main.dir/Debug/mutation_query.cc.o
FAILED: CMakeFiles/scylla-main.dir/Debug/mutation_query.cc.o
/home/kefu/.local/bin/clang++ -DDEBUG -DDEBUG_LSA_SANITIZER -DFMT_SHARED -DSANITIZE -DSCYLLA_BUILD_MODE=debug -DSCYLLA_ENABLE_ERROR_INJECTION -DSEASTAR_API_LEVEL=7 -DSEASTAR_DEBUG -DSEASTAR_DEBUG_PROMISE -DSEASTAR_DEBUG_SHARED_PTR -DSEASTAR_DEFAULT_ALLOCATOR -DSEASTAR_LOGGER_COMPILE_TIME_FMT -DSEASTAR_LOGGER_TYPE_STDOUT -DSEASTAR_SCHEDULING_GROUPS_COUNT=16 -DSEASTAR_SHUFFLE_TASK_QUEUE -DSEASTAR_SSTRING -DSEASTAR_TYPE_ERASE_MORE -DXXH_PRIVATE_API -DCMAKE_INTDIR=\"Debug\" -I/home/kefu/dev/scylladb -I/home/kefu/dev/scylladb/build/gen -I/home/kefu/dev/scylladb/seastar/include -I/home/kefu/dev/scylladb/build/seastar/gen/include -I/home/kefu/dev/scylladb/build/seastar/gen/src -isystem /home/kefu/dev/scylladb/abseil -g -Og -g -gz -std=gnu++23 -fvisibility=hidden -Wall -Werror -Wextra -Wno-error=deprecated-declarations -Wimplicit-fallthrough -Wno-c++11-narrowing -Wno-deprecated-copy -Wno-mismatched-tags -Wno-missing-field-initializers -Wno-overloaded-virtual -Wno-unsupported-friend -Wno-unused-parameter -ffile-prefix-map=/home/kefu/dev/scylladb/build=. -march=x86-64-v3 -mpclmul -Xclang -fexperimental-assignment-tracking=disabled -Werror=unused-result -fstack-clash-protection -fsanitize=address -fsanitize=undefined -MD -MT CMakeFiles/scylla-main.dir/Debug/mutation_query.cc.o -MF CMakeFiles/scylla-main.dir/Debug/mutation_query.cc.o.d -o CMakeFiles/scylla-main.dir/Debug/mutation_query.cc.o -c /home/kefu/dev/scylladb/mutation_query.cc
In file included from /home/kefu/dev/scylladb/mutation_query.cc:12:
In file included from /home/kefu/dev/scylladb/schema/schema_registry.hh:17:
In file included from /home/kefu/dev/scylladb/replica/database.hh:11:
In file included from /home/kefu/dev/scylladb/locator/abstract_replication_strategy.hh:26:
/home/kefu/dev/scylladb/locator/tablets.hh:410:30: error: unexpected type name 'size_t': expected expression
410 | return boost::irange<size_t>(0, tablet_count()) | boost::adaptors::transformed([] (size_t i) {
| ^
/home/kefu/dev/scylladb/locator/tablets.hh:410:23: error: no member named 'irange' in namespace 'boost'
410 | return boost::irange<size_t>(0, tablet_count()) | boost::adaptors::transformed([] (size_t i) {
| ~~~~~~~^
/home/kefu/dev/scylladb/locator/tablets.hh:410:38: error: left operand of comma operator has no effect [-Werror,-Wunused-value]
410 | return boost::irange<size_t>(0, tablet_count()) | boost::adaptors::transformed([] (size_t i) {
| ^
In file included from /home/kefu/dev/scylladb/mutation_query.cc:12:
In file included from /home/kefu/dev/scylladb/schema/schema_registry.hh:17:
In file included from /home/kefu/dev/scylladb/replica/database.hh:37:
In file included from /home/kefu/dev/scylladb/db/snapshot-ctl.hh:20:
/home/kefu/dev/scylladb/tasks/task_manager.hh:403:54: error: no member named 'irange' in namespace 'boost'
403 | co_await coroutine::parallel_for_each(boost::irange(0u, smp::count), [&tm, id, &res, &func] (unsigned shard) -> future<> {
| ~~~~~~~^
4 errors generated.
```
so let's take the opportunity to switch from `boost::irange` to
`std::views::iota`.
in this change, we:
- switch from boost::irange to std::views::iota for better standard library compatibility
- retain boost::irange where step parameter is used, as std::views::iota doesn't support it
- this change partially modernizes our range usage while maintaining
- existing functionality
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#20924
{kind=link}