Before this patch, granting a user MODIFY permissions on ALL KEYSPACES allowed the user to write to system tables, where the user could also set himself to "superuser" granting him all other permissions. After this patch, MODIFY permissions on ALL KEYSPACES is limited only to non-system keyspaces.
Fixes: scylladb/scylladb#23218
(cherry picked from commit fee50f287c)
Parent PR: #23219Closesscylladb/scylladb#23594
On short-pages, cut short because of a tombstone prefix.
When page-results are filtered and the filter drops some rows, the
last-position is taken from the page visitor, which does the filtering.
This means that last partition and row position will be that of the last
row the filter saw. This will not match the last position of the
replica, when the replica cut the page due to tombstones.
When fetching the next page, this means that all the tombstone suffix of
the last page, will be re-fetched. Worse still: the last position of the
next page will not match that of the saved reader left on the replica, so
the saved reader will be dropped and a new one created from scratch.
This wasted work will show up as elevated tail latencies.
Fix by always taking the last position from raw query results.
Fixes: #22620Closesscylladb/scylladb#22622
(cherry picked from commit 7ce932ce01)
Closesscylladb/scylladb#22719
Currently, when we load a frozen schema into the registry, we lose
the base info if the schema was of a view. Because of that, in various
places we need to set the base info again, and in some codepaths we
may miss it completely, which may make us unable to process some
requests (for example, when executing reverse queries on views).
Even after setting the base info, we may still lose it if the schema
entry gets deactivated due to all `schema_ptr`s temporarily dying.
To fix this, this patch adds the base schema to the registry, alongside
the view schema. We store just the frozen base schema, so that we can
transfer it across shards. With the base schema, we can now set the base
info when returning the schema from the registry. As a result, we can now
assume that all view schemas returned by the registry have base_info set.
In this series we also make sure that the view schemas in the registry are
kept up-to-date in regards to base schema changes.
Fixes https://github.com/scylladb/scylladb/issues/21354
This issue is a bug, so adding backport labels 6.1 and 6.2
Closesscylladb/scylladb#21862
* github.com:scylladb/scylladb:
test: add test for schema registry maintaining base info for views
schema_registry: avoid setting base info when getting the schema from registry
schema_registry: update cached base schemas when updating a view
schema_registry: cache base schemas for views
db: set base info before adding schema to registry
As discussed in
https://github.com/scylladb/scylladb/issues/12263#issuecomment-1853576813,
compact storage tables are deprecated.
Yet, there's is nothing in the code that prevents users
from creating such tables.
This patch adds a live-updateable config option:
`enable_create_table_with_compact_storage`, set to
`false` by default, that require users to opt-in
in order to create new tables WITH COMPACT STORAGE.
Refs scylladb/scylladb#12263, scylladb/scylladb#16375
* Since this guardrail is an enhancement, no backport is needed
Closesscylladb/scylladb#16403
* github.com:scylladb/scylladb:
docs: ddl: document the deprecation of compact tables
test: enable_create_table_with_compact_storage for tests that need it
config: add enable_create_table_with_compact_storage
The way that the "test/cqlpy/run --release" feature runs older Scylla
releases is that it takes *today*'s command line parameters and "fixes"
it to conform to what old releases took. This approach was easy to
implement (and the resulting "--release" feature is super useful), but
the downside is that we need to update this fixup code whenever we add
new options to the Scylla command line used by test/cqlpy/run.py.
Commit d04f376 made test/cqlpy/run.py use a new option
"--experimental-features=views-with-tablets", so now we need to remove
it when running older versions of Scylla. So this is what we do in this
patch.
Fixes#22349
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closesscylladb/scylladb#22350
The small cqlpy test in this patch is a regression test for issue #14390,
which claimed that the Scylla-only "tombstone_gc" option is missing from
the output of "describe table".
This test shows that this report is *not* true, at least not when the
"server-side describe" is used. "test/cqlpy/run --release ..." shows
that this test passes on master and also for Scylla versions all the
way back to Scylla 5.2 (Scylla 5.1 did not support server-side
describe, so the test fails for that reason).
This suggests that the report in issue #14390 was for old-style
client-side (cqlsh) describe, which we no longer support, so this
issue can be closed.
Fixes#14390.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closesscylladb/scylladb#22354
As discussed in
https://github.com/scylladb/scylladb/issues/12263#issuecomment-1853576813,
compact storage tables are deprecated.
Yet, there's is nothing in the code that prevents users
from creating such tables.
This patch adds a live-updateable config option:
`enable_create_table_with_compact_storage` that require users
to opt-in in order to create new tables WITH COMPACT STORAGE.
The option is currently set to `true` by default in db/config
to reduce the churn to tests and to `false` in scylla.yaml,
for new clusters.
TODO: once regressions tests that use compact storage
are converted to enable the option, change the default in
db/config to false.
A unit test was added to test/cql-pytest that
checks that the respective cql query fails as expected
with the default option or when it is explicitly set to `false`,
and that the query succeeds when the option is set to `true`.
Note that `check_restricted_table_properties` already
returns an optional warning, but it is only logged
but not returned in the `prepared_statement`.
Fixing that is out of the scope of this patch.
See https://github.com/scylladb/scylladb/issues/20945
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
We still have a number of issues to be solved for views with tablets.
Until they are fixed, we should prevent users from creating them,
and use the vnode-based views instead.
This patch prepares the feature for enabling views with tablets. The
feature is disabled by default, but currently it has no effect.
After all tests are adjusted to use the feature, we should depend
on the feature for deciding whether we can create materialized views
in tablet-enabled keyspaces.
The unit tests are adjusted to enable this feature explicitly, and it's
also added to the scylla sstable tool config - this tool treats all
tables as if they were tablet-based (surprisingly, with SimpleStrategy),
so for it to work on views, the new feature must be enabled.
Refs scylladb/scylladb#21832Closesscylladb/scylladb#21833
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
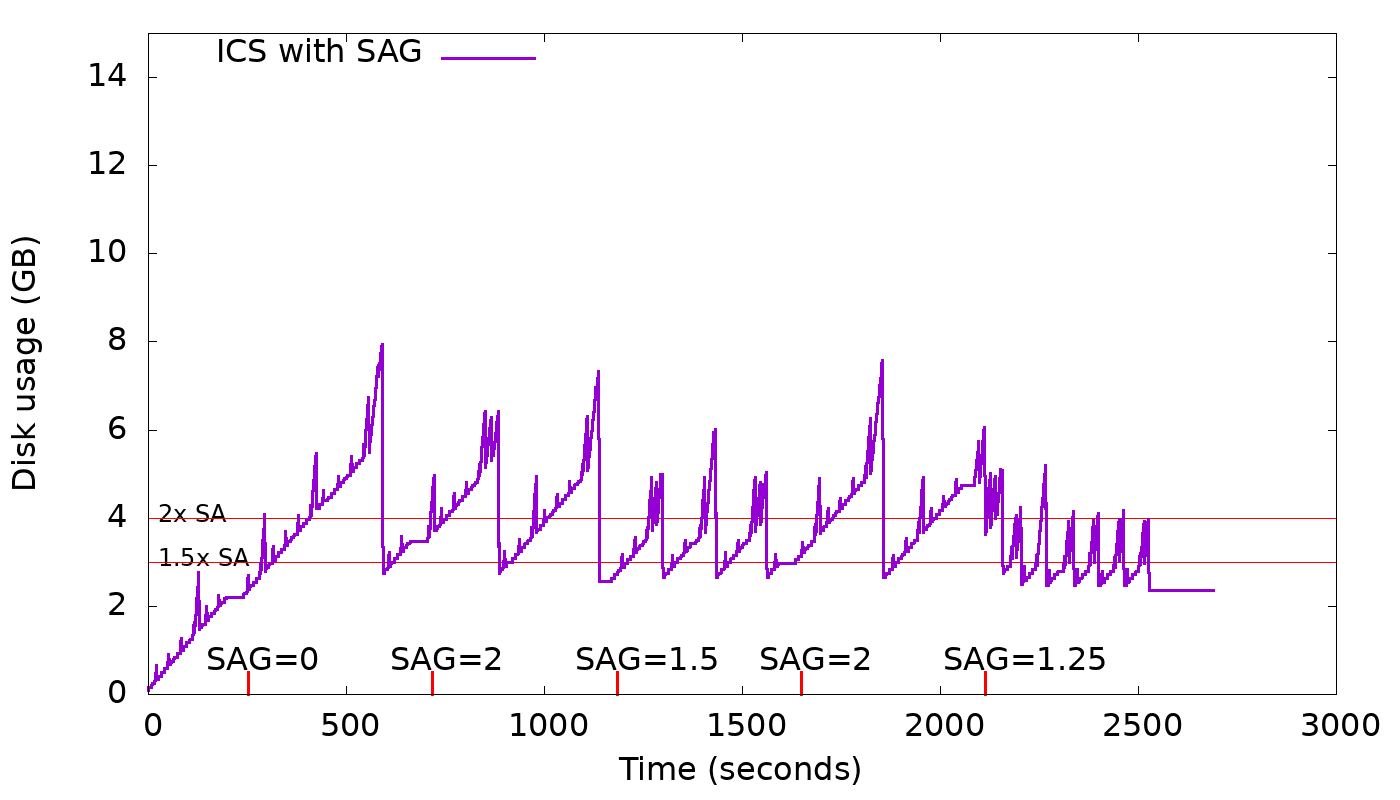
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
Adjust existing cqlpy tests and add more in order to test the workload
prioritization feature:
- The DESCRIBE test is updated to check that generated statements
contain information about shares
- Two tests for shares in the LIST EFFECTIVE SERVICE LEVEL statement
- Regression test which checks that we can create as many service levels
as promised in the documentation (currently 7), but no more
- Test which checks that NULL shares in the service levels table are
treated as the default 1000 shares
Introduces two endpoints with operations specific to service levels:
- switch_tenants: updates the scheduling group of all connections to be
aligned with the service level specific to the logged in user. This is
mostly legacy API, as with service levels on raft this is done
automatically.
- count_connections: for each user and for each scheduling group, counts
how many connections are assigned to that user and scheduling group.
This API is used in tests.
Now, the CREATE statements generated for each service level by the
DESCRIBE SCHEMA WITH INTERNALS statement will account for the service
level's shares.
This adds to the grammar the option to SELECT a specific element in a collection (map/set/list).
For example:
`SELECT map['key'] FROM table`
`SELECT map['key1']['key2'] FROM table`
This feature was implemented in Cassandra 4.0 and was requested by scylla users.
The behavior is mostly compatible with Cassandra, except:
1. in SELECT, we allow list subscript in a selector, while cassandra allows only map and set.
2. in UPDATE, we allow set subscript in a column condition, while cassandra allows only map and list.
3. the slice syntax `SELECT m[a..b]` is not implemented yet
4. null subscript - `SELECT m[null]` returns null in scylla, while cassandra returns error
Fixes#7751
backport was requested for a user to be able to use it
Closesscylladb/scylladb#22051
* github.com:scylladb/scylladb:
cql3: allow SELECT of specific collection key
cql3: allow set subscript
This adds to the grammar the option to SELECT a specific key in a
collection column using subscript syntax.
For example:
SELECT map['key'] FROM table
SELECT map['key1']['key2'] FROM table
The key can also be parameterized in a prepared query. For this we need
to pass the query options to result_set_builder where we process the
selectors.
Fixesscylladb/scylladb#7751
In this patch we test the behavior of schema registry in a few
scenarios where it was identified it could misbehave.
The first one is reverse schemas for views. Previously, SELECT
queries with reverse order on views could fail because we didn't
have base info in the registry for such schemas.
The second one is schemas that temporarily died in the registry.
This can happen when, while processing a query for a given schema
version, all related schema_ptrs were destroyed, but this schema
was requested before schema_registry::grace_period() has passed.
In this scenario, the base info would not be recovered, causing
errors.
If authentication is enabled, but STARTUP isn't followed by REGISTER (which is optional, and in practice only happens on only one of a driver's connections — because there's no point listening for the same events on multiple connections), connections are wrongly displayed in the system.clients as AUTHENTICATING instead of READY, even when they are ready.
This commit fixes this problem.
Fixes: scylladb/scylladb#12640Closesscylladb/scylladb#21774
So far there's the /column_family/built_indexes one that reports the
index names similar to how system.IndexInfo does, but it's not tested.
This patch adds tests next to existing system. table ones.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Where the grammar supports IN, we add NOT IN. This includes the WHERE
clause and LWT IF clause.
Evaluation of NOT IN follows from IN.
In statement_restrictions analysis, they are different, as NOT IN
doesn't enable any clever query plan and must filter.
Some tests are added. An error message was changed ('in' changed to 'IN'),
so some tests are adjusted.
Closesscylladb/scylladb#21992
This patch adds a few more functional tests for the CQL materialized
view feature in the cqlpy. The new tests pass, but helped me catch bugs (and
understand what are *not* bugs) while refactoring some view update code.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
And split it into two -- one for materialized view, another for
secondary index. This is to fit current cqlpy layout that has different
files for views and indexes.
refs: #21552
refs: #21551 (detached this patch from there, as that PR needs fix in
the core code)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Closesscylladb/scylladb#21677
Currently, the tri-compare operator for big_decimal (operator <=>), uses
a precise but potentially very expensive algorithm for comparing the
numbers: it first brings them to the same scale, then compares the
normalized unscaled values. big_decimal has abritrary precisions,
therefore the stored numbers can be arbitrarily large.
In extreme cases, comparing two numbers can result in huge amount of
memory allocated and stalls. If this type is used int he primary key of
a table, these comparisons can make the node completely unresponsive.
This patch adds the following fast-paths to operator <=>:
* An early return for the case of equal scales.
* An early return for different signs.
* An early return for the case where one or both of the numbers are 0.
* A fast algorithm for detecting the case where the there is a big
difference between the two numbers. This algorithm works only with the
scales and is able to compare the two numbers by using only one division
and some additions and substractions. This algorithm is imprecise and
when the numbers are closer than its confidence window, it will
fall-back to the current slow but precise tri-compare.
All but the last case should have been fast before as well, but the
scale-compare algorithm makes a huge difference. Numbers, which would
previously make the node unresponsive, now compare in constant-time.
Fixes: scylladb/scylladb#21716Closesscylladb/scylladb#21715
Demote --scylla-data-dir and --scylla-yaml-file to schema source
helpers, rather than schema source in themselves. This practically means
that when these options are used, they won't define where the tool will
attempt to load the schema from, they will just be helpers to help locate
the schema, for whichever schema source the tool was instructed to use
(or left to choose).
--scylla-data-dir and --scylla-yaml-file being schema sources were
problematic with encryption at rest and for S3 support (not yet
implemented). With encryption, the tool needs access to the
configuration, so --scylla-yaml-file is often used to provide the path
to the configuration file, which contains encryption configuration,
needed for the tool to decrypt the sstable. Currently, using this option
implies forcing the tool to read the schema from the schema tables,
which is a problematic option for tests -- Scylla might be compacting a
schema sstable and this will make the tool fail to load the schema.
Demoting these options the schema helpers, allows providing them, while
at the same time having the option to use a different schema-source.
To allow the user to force the tool to load the schema from the schema
tables, a new --schema-tables option is added. Similarly, a
--sstable-schema option is introduced to force the tool to load the
schema from the sstable itself.
With this, each 4 schema source now has an option to force the use of
said schema source. There are various helper options to be used along
with these.
The documentation as well as the tests are updated with the changes.
The schema related documentation gets an rather extensive facelift
because it was a bit out-of-date and incomplete.
Fixes: scylladb/scylladb#20534Closesscylladb/scylladb#21678
ScyllaDB doesn't support counters with tablets yet. So scylla-sstable
tests which use counter schema are marked with xfail, but this is done
too aggressively, disabling too many tests that are otherwise fine.
There are two tests affected:
* test_scylla_sstable_script - this test uses early return when the
schema parameter is the one with counters and tablets are enabled.
This is still too eager because tablets are now always enabled. Also,
the early return make the fact that this test is disabled hidden.
So change the check to check whether tablets are used on the test
keyspace and use xfail instead of sneaky early return.
* test_scylla_sstable_dump_data - this test is blanket-disabled when run
with the tablets parameter. Even though only 1 out of 5 schemas tested
use counters. Remove the blanket xfail and only add it when test
keyspace uses tablets and the schema parameter is the one with
counters.
This makes dozens of test run again, restoring the test coverage lost
with the too eager use of xfail (and sneaky return).
Refs: #18180Closesscylladb/scylladb#21685
This patch moves (after straightforward translation) the test
"test_views_with_future_tombstone", a regression test for #5793,
from the C++ boost framework to the Python cqlpy framework.
The main motivation this move is the ease of debugging failures:
During the work on a patch for #20679 (eliminating read-before-write)
this test began to fail, and understanding where the C++ failed was
near impossible: the Boost test framework reports that the test failed,
but not in which line or why, and adding printouts to this huge source
file require a ridiculous amount of time for recompilation every time.
In contrast, the new pytest-based version shows exactly where the
error is, beautifully:
```
> assert [] == list(cql.execute(f'select * from {mv}'))
E assert [] == [Row(b=2, a=1, c=3, d=4, e=5)]
test_materialized_view.py:1614: AssertionError
```
It shows exactly which assertion failed, and exactly what were the
values that were compared. Beautiful and super helpful for debugging.
Beyond the ease of debugging, moving this (and later, other) test to
the cql-pytest framework has additional advantages:
1. The test was misplaced, in the cql_test source file, and it belongs
with materialized views tests so let's use this opportunity to move
it to the right place.
2. Can easily run the same test on multiple versions of Scylla, and
also on Cassandra. It's a good way to confirm the test is correct.
3. No need to recompile the test after every attempt to fix the bug.
The cql_query_test.cc is huge - over 6,000 lines - and takes over
a minute to compile after every attempt to fix a bug.
Refs #16134 (the issue asks to move all MV tests to cql-pytest)
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closesscylladb/scylladb#21552
We recently added a "--release <version>" option to test/cql-pytest/run
to run a cql-pytest test against a released version of Scylla, downloaded
automatically from ScyllaDB's precompiled binary repository. This patch
adds the same capability also to test/alternator/run - allowing to run
a current test/alternator test on older releases of Scylla. The
implementation in this patch reuses the same implementation from the
cql-pytest patch.
Here is an example use case: the pull request #19941 claimed that
a certain bug fix was backported to release 6.0. Was it? Let's run
the test reproducing that bug on two releases:
test/alternator/run --release 6.0 test_streams.py::test_stream_list_tables
test/alternator/run --release 6.1 test_streams.py::test_stream_list_tables
It shows that the test passes on 6.1 (so the bug is fixed there) but the
test fails 6.0. It turns out that although the fix was backported to
branch-6.0, this happened shortly after 6.0.4 was released and no later
6.0 minor release came afterwards! So the bug wasn't actually fixed
on any official release of 6.0.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closesscylladb/scylladb#21343
A recent improvement to test/cqlpy/run to add the "--release" option
broke the ability to run this script it without *any* options (no test
name, etc.). This patch fixes this case.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Python and Python developers don't like directory names to include a
minus sign, like "cql-pytest". In this patch we rename test/cql-pytest
to test/cqlpy, and also change a few references in other code (e.g., code
that used test/cql-pytest/run.py) and also references to this test suite
in documentation and comments.
Arguably, the word "test" was always redundant in test/cql-pytest, and
I want to leave the "py" in test/cqlpy to emphasize that it's Python-based
tests, contrasting with test/cql which are CQL-request-only approval
tests.
Fixes#20846
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
{kind=link}