Set enable_schema_commitlog for each group0 tables.
Assert that group0 tables use schema commitlog in ensure_group0_schema
(per each command).
Fixes: https://scylladb.atlassian.net/browse/SCYLLADB-914.
Needs backport to all live releases as all are vulnerable
Closesscylladb/scylladb#28876
* github.com:scylladb/scylladb:
test: add test_group0_tables_use_schema_commitlog
db: service: remove group0 tables from schema commitlog schema initializer
service: ensure that tables updated via group0 use schema commitlog
db: schema: remove set_is_group0_table param
(cherry picked from commit b90fe19a42)
Closesscylladb/scylladb#28916Closesscylladb/scylladb#28986
In PR 5b6570be52 we introduced the config option
`sstable_compression_user_table_options` to allow adjusting the default
compression settings for user tables. However, the new option was hooked
into the CQL layer and applied only to CQL base tables, not to the whole
spectrum of user tables: CQL auxiliary tables (materialized views,
secondary indexes, CDC log tables), Alternator base tables, Alternator
auxiliary tables (GSIs, LSIs, Streams).
Fix this by moving the logic into the `schema_builder` via a schema
initializer. This ensures that the default compression settings are
applied uniformly regardless of how the table is created, while also
keeping the logic in a central place.
Register the initializer at startup in all executables where schemas are
being used (`scylla_main()`, `scylla_sstable_main()`, `cql_test_env`).
Finally, remove the ad-hoc logic from `create_table_statement`
(redundant as of this patch), remove the xfail markers from the relevant
tests and adjust `test_describe_cdc_log_table_create_statement` to
expect LZ4WithDicts as the default compressor.
Fixes#26914.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
(cherry picked from commit 1e37781d86)
Extend the `static_configurator` mechanism to support initialization of
arbitrary schema properties, not only static ones, by passing a
`schema_builder` reference to the configurator interface.
As part of this change, rename `static_configurator` to
`schema_initializer` to better reflect its broader responsibility.
Add a checkpoint/restore mechanism to allow de-registering an
initializer (useful for testing; will be used in the next patch).
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
(cherry picked from commit d5ec66bc0c)
Schemas maintain a set of so-called "static properties". These are not
user-visible schema properties; they are internal values carried by
in-memory `schema` objects for convenience (349bc1a9b6,
https://github.com/scylladb/scylladb/pull/13170#issuecomment-1469848086).
Currently, the initialization of these properties happens when a
`schema_builder` builds a schema (`schema_builder::build()`), by
invoking all registered "static configurators".
This patch moves the initialization of static properties into the
`schema_builder` constructor. With this change, the builder initializes
the properties once, stores them in a data member, and reuses them for
all schema objects that it builds. This doesn't affect correctness as
the values produced by static configurators are "static" by
nature; they do not depend on runtime state.
In the next patch, we will replace the "static configurator" pattern
with a more general pattern that also supports initialization of regular
schema properties, not just static ones. Regular properties cannot be
initialized in `build()` because users may have already explicitly set
values via setters, and there is no way to distinguish between default
values and explicitly assigned ones.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
(cherry picked from commit 5b4aa4b6a6)
Change speculative_retry::to_sstring and speculative_retry::from_sstring
to throw exceptions::configuration_exception instead of std::invalid_argument.
These errors can be triggered by CQL, so appropriate CQL exception should be
used.
Reference: https://github.com/scylladb/scylladb/issues/24748#issuecomment-3025213304
Refs #26369
(cherry picked from commit 85f059c148)
This patch allows specifying 0 and 100 PERCENTILE values in speculative_retry.
It was possible to specify these values before #21825. #21825 prevented specifying
invalid values, like -1 and 101, but also prevented using 0 and 100.
On top of that, speculative_retry::to_sstring function did rounding when
formatting the string, which introduced inconsistency.
Fixes#26369
(cherry picked from commit da2ac90bb6)
The namespace usage in this directory is very inconsistent, with files
and classes scattered in:
* global namespace
* namespace compaction
* namespace sstables
With cases, where all three used in the same file. This code used to
live in sstables/ and some of it still retains namespace sstables as a
heritage of that time. The mismatch between the dir (future module) and
the namespace used is confusing, so finish the migration and move all
code in compaction/ to namespace compaction too.
This patch, although large, is mechanic and only the following kind of
changes are made:
* replace namespace sstable {} with namespace compaction {}
* add namespace compaction {}
* drop/add sstables::
* drop/add compaction::
* move around forward-declarations so they are in the correct namespace
context
This refactoring revealed some awkward leftover coupling between
sstables and compaction, in sstables/sstable_set.cc, where the
make_sstable_set() methods of compaction strategies are implemented.
As requested in #22104, moved the files and fixed other includes and build system.
Moved files:
- combine.hh
- collection_mutation.hh
- collection_mutation.cc
- converting_mutation_partition_applier.hh
- converting_mutation_partition_applier.cc
- counters.hh
- counters.cc
- timestamp.hh
Fixes: #22104
This is a cleanup, no need to backport
Closesscylladb/scylladb#25085
Add precompiled header support to CMakeLists.txt and configure.py -
it improves compilation time by approximately 10%.
New header `stdafx.hh` is added, don't include it manually -
the compiler will include it for you. The header contains includes from
external libraries used by Scylla - seastar, standard library,
linux headers and zlib.
The feature is enabled by default, use CMake option `Scylla_USE_PRECOMPILED_HEADER`
or configure.py --disable-precompiled-header to disable.
The feature should be disabled, when trying to check headers - otherwise
you might get false negatives on missing includes from seastar / abseil and so on.
Note: following configuration needs to be added to ccache.conf:
sloppiness = pch_defines,time_macros
Closes#25182
Fixes#22106
Moves the shared compress components to sstables, and rename to
match class type.
Adjust includes, removing redundant/unneeded ones where possible.
Closesscylladb/scylladb#25103
As requested in #22102, #22103 and #22105 moved the files and fixed other includes and build system.
Moved files:
- clustering_bounds_comparator.hh
- keys.cc
- keys.hh
- clustering_interval_set.hh
- clustering_key_filter.hh
- clustering_ranges_walker.hh
- compound_compat.hh
- compound.hh
- full_position.hh
Fixes: #22102Fixes: #22103Fixes: #22105Closesscylladb/scylladb#25082
Before for views and indexes it was fetching base schema from db (and
couple other properties). This is a problem once we introduce atomic
tables and views deletion (in the following commit).
Because once we delete table it can no longer be fetched from db object,
and truncation is performed after atomically deleting all relevant
tables/views/indexes.
Now the whole relevant schema will be fetched via global_table_ptr
(table_shards) object.
When describing a table, we need to do it carefully: if some
columns were dropped, we must specify that explicitly by
```
ALTER TABLE {table} DROP {column} USING TIMESTAMP ...
```
in the result of the DESCRIBE statement. Failing to do so
could lead to data resurrection.
However, if a table has been altered many, many times,
we might end up with a huge create statement. Constructing
it could, in turn, trigger an oversized allocation.
Some tests ran into that very problem in fact.
In this commit, we want to mitigate the problem: instead of
allocating a contiguous chunk of memory for the create
statement, we use `fragmented_ostringstream` and `managed_string`
to possibly keep data scattered in memory. It makes handling
`cql3::description` less convenient in the code, but since
the struct is pretty much immediately serialized after
creating it, it's a very good trade-off.
We provide a reproducer. It consistently passes with this commit,
while having about 50% chance of failure before it (based on my
own experiments). Playing with the parameters of the test
doesn't seem to improve that chance, so let's keep it as-is.
Fixesscylladb/scylladb#24018
This commit increases the maximum length of names for keyspaces, tables, materialized views, and indexes from 48 to 192 bytes.
The previous 48-bytes limit was inherited from Cassandra 3 for compatibility. However, this validation was removed in Cassandra 4 and 5 (see CASSANDRA-20389)
and some usage scenarios (such as some feature store workflows generating long table names) now depend on this relaxed constraint.
This change brings ScyllaDB's behavior in line with modern Cassandra versions and better supports these use cases.
The new limit of 192 bytes is derived from underlying filesystem limitations to prevent runtime errors when creating directories for table data.
When a new table is created, ScyllaDB generates a directory for its SSTables. The directory name is constructed from the table name, a dash, and a 32-character UUID.
For a CDC-enabled table, an associated log table is also created, which has the suffix `_scylla_cdc_log` appended to its name.
The directory name for this log table becomes the longest possible representation.
Additionally we reserve 15 bytes for future use, allowing for potential future extensions without breaking existing schemas.
To guarantee that directory creation never fails due to exceeding filesystem name limits, the maximum name length is calculated as follows:
255 bytes (common filesystem limit for a path component)
- 32 bytes (for the 32-character UUID string)
- 1 byte (for the '-' separator)
- 15 bytes (for the '_scylla_cdc_log' suffix)
- 15 bytes (reserved for future use)
----------
= 192 bytes (Maximum allowed name length)
This calculation is similar in principle to the one proposed for Cassandra to fix related directory creation failures (see apache/cassandra/pull/4038).
This patch also updates/adds all associated tests to validate the new 192-byte limit.
The documentation has been updated accordingly.
This reverts commit 0b516da95b, reversing
changes made to 30199552ac. It breaks
cluster.random_failures.test_random_failures.test_random_failures
in debug mode (at least).
Fixes#24513
Before for views and indexes it was fetching base schema from db (and
couple other properties). This is a problem once we introduce atomic
tables and views deletion (in the following commit).
Because once we delete table it can no longer be fetched from db object,
and truncation is performed after atomically deleting all relevant
tables/views/indexes.
Now the whole relevant schema will be fetched via global_table_ptr
(table_shards) object.
This pull request adds support for creating custom indexes (at a metadata level) as long as a supported custom class is provided (currently only vector search).
The patch contains:
- a change in CREATE INDEX statement that allows for the USING keyword to be present as long as one of the supported classes is used
- support for describing custom indexes in the DESCRIBE statement
- unit tests
Co-authored by: @Balwancia
Closesscylladb/scylladb#23720
* github.com:scylladb/scylladb:
test/cqlpy: add custom index tests
index: support storing metadata for custom indices
Added function returning custom index class name.
Added printing custom index class name when using DESCRIBE.
Changed validation to reflect current support of indices.
In the previous commits we made sure that the base info is not dependent
on the base schema version, and the info dependent on the base schema
version is calculated when it's needed. In this patch we remove the
unnecessary re-setting of the base_info.
The set_base_info method isn't removed completely, because it also has
a secondary function - zeroing the view_info fields other than base_info.
Because of this, in this patch we rename it accordingly and limit its
use to the updates caused by a base schema change.
The base info now only contains values which are not reliant on the
base schema version. We remove the the base schema from the base info
to make it immutable regardless of base schema version, at the point
of this patch it's also not needed anywhere - the new base info can
replace the base schema in most places, and in the few (view_updates)
where we need it, we pull the most recent base schema version from
the database.
After this change, the base info no longer changes in a view schema
after creation, so we'll no longer get errors when we try generating
view updates with a base_info that's incompatible with a specific
base schema version.
Fixes#9059Fixes#21292Fixes#22410
In the following patch we plan to remove the base schema from the base_info
to make the base_info immutable. To do that, we first prepare the schema
registry for the change; we need to be able to create view schemas from
frozen schemas there and frozen schemas have no information about the base
table. Unless we do this change, after base schemas are removed from the
base info, we'll no longer be able to load a view schema to the schema registry
without looking up the base schema in the database.
This change also required some updates to schema building:
* we add a method for unfreezing a view schema with base info instead of
a base schema
* we make it possible to use schema_builder with a base info instead of
a base schema
* we add a method for creating a view schema from mutations with a base info
instead of a base schema
* we add a view_info constructor withat base info instead of a base schema
* we update the naming in schema_registry to reflect the usage of base info
instead of base schema
Currently, the base_info may or may not be set in view schemas.
Even when it's set, it may be modified. This necessitates extra
checks when handling view schemas, as well as potentially causing
errors when we forget to set it at some point.
Instead, we want to make the base info an immutable member of view
schemas (inside view_info). The first step towards that is making
sure that all newly created schemas have the base info set.
We achieve that by requiring a base schema when constructing a view
schema. Unfortunately, this adds complexity each time we're making
a view schema - we need to get the base schema as well.
In most cases, the base schema is already available. The most
problematic scenario is when we create a schema from mutations:
- when parsing system tables we can get the schema from the
database, as regular tables are parsed before views
- when loading a view schema using the schema loader tool, we need
to load the base additionally to the view schema, effectively
doubling the work
- when pulling the schema from another node - in this case we can
only get the current version of the base schema from the local
database
Additionally, we need to consider the base schema version - when
we generate view updates the version of the base schema used for
reads should match the version of the base schema in view's base
info.
This is achieved by selecting the correct (old or new) schema in
`db::schema_tables::merge_tables_and_views` and using the stored
base schema in the schema_registry.
schema_extension allows making invisible changes to system_schema
that evade upgrade rollback tests. They appear in system_schema
as an encoded blob which reduces serviceability, as they cannot
be read.
Deprecate it and point users to adding explicit columns in scylla_tables.
We could probably make use of the data structure, after we teach it
to encode its payload into proper named and typed columns instead of
using IDL.
Closesscylladb/scylladb#23151
In this series we implement the UpdateTable operation to add a GSI to an existing table, or remove a GSI from a table. As the individual commit messages will explained, this required changing how Alternator stores materialized view keys - instead of insisting that these key must be real columns (that is **not** the case when adding a GSI to an existing table), the materialized view can now take as its key any Alternator attribute serialized inside the ":attrs" map holding all non-key attributes. Fixes#11567.
We also fix the IndexStatus and Backfilling attributes returned by DescribeTable - as DynamoDB API users use this API to discover when a newly added GSI completed its "backfilling" (what we call "view building") stage. Fixes#11471.
This series should not be backported lightly - it's a new feature and required fairly large and intrusive changes that can introduce bugs to use cases that don't even use Alternator or its UpdateTable operations - every user of CQL materialized views or secondary indexes, as well as Alternator GSI or LSI, will use modified code. **It should be backported to 2025.1**, though - this version was actually branched long after this PR was sent, and it provides a feature that was promised for 2025.1.
Closesscylladb/scylladb#21989
* github.com:scylladb/scylladb:
alternator: fix view build on oversized GSI key attribute
mv: clean up do_delete_old_entry
test/alternator: unflake test for IndexStatus
test/alternator: work around unrelated bug causing test flakiness
docs/alternator: adding a GSI is no longer an unimplemented feature
test/alternator: remove xfail from all tests for issue 11567
alternator: overhaul implementation of GSIs and support UpdateTable
mv: support regular_column_transformation key columns in view
alternator: add new materialized-view computed column for item in map
build: in cmake build, schema needs alternator
build: build tests with Alternator
alternator: add function serialized_value_if_type()
mv: introduce regular_column_transformation, a new type of computed column
alternator: add IndexStatus/Backfilling in DescribeTable
alternator: add "LimitExceededException" error type
docs/alternator: document two more unimplemented Alternator features
This patch removes expansion of "SELECT *" in DESC MATERIALIZED VIEW.
Instead of explicitly printing each column, DESC command will now just
use SELECT *, if view was created with it. Also, adds a correspodning test.
Fixes#21154Closesscylladb/scylladb#21962
This patch adds a new computed column class for materialized views,
extract_from_attrs_column_computation
which is Alternator-specific and knows how to extract a value (of a
known type) from an attribute stored in Alternator's map-of-all-nonkey-
attributes ":attrs".
We'll use this new computed column in the next patch to reimplement GSI.
The new computed-column class is based on regular_column_transformation
introduced in the previous patch. It is not yet wired to anything:
The MV code cannot handle any regular_column_transformation yet, and
Alternator will not yet use it to create a GSI. We'll do those things
in the following patches.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
This patch is to cmake what the previous patch was to configure.py.
In the next patch we want to make schema/schema.o depend on
alternator/executor.o - because when the schema has an Alternator
computed column, the schema code needs to construct the computed column
object (extract_from_attrs_column_computation) and that lives in
alternator/executor.o.
In the cmake-based build, all the schema/* objects are put into one
library "libschema.a". But code that uses this library (e.g., tests)
can't just use that library alone, because it depends on other code
not in schema/. So CMakeLists.txt lists other "libraries" that
libschema.a depends on - including for example "cql3". We now need
to add "alternator" to this dependency list. The dependency is marked
"PRIVATE" - schema needs alternator for its own internal uses, but
doesn't need to export alternator's APIs to its own users.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Unlike with vnodes, each tablet is served only by a single
shard, and it is associated with a memtable that, when
flushed, it creates sstables which token-range is confined
to the tablet owning them.
On one hand, this allows for far better agility and elasticity
since migration of tablets between nodes or shards does not
require rewriting most if not all of the sstables, as required
with vnodes (at the cleanup phase).
Having too few tablets might limit performance due not
being served by all shards or by imbalance between shards
caused by quantization. The number of tabelts per table has to be
a power of 2 with the current design, and when divided by the
number of shards, some shards will serve N tablets, while others
may serve N+1, and when N is small N+1/N may be significantly
larger than 1. For example, with N=1, some shards will serve
2 tablet replicas and some will serve only 1, causing an imbalance
of 100%.
Now, simply allocating a lot more tablets for each table may
theoretically address this problem, but practically:
a. Each tablet has memory overhead and having too many tablets
in the system with many tables and many tablets for each of them
may overwhelm the system's and cause out-of-memory errors.
b. Too-small tablets cause a proliferation of small sstables
that are less efficient to acces, have higher metadata overhead
(due to per-sstable overhead), and might exhaust the system's
open file-descriptors limitations.
The options introduced in this change can help the user tune
the system in two ways:
1. Sizing the table to prevent unnecessary tablet splits
and migrations. This can be done when the table is created,
or later on, using ALTER TABLE.
2. Controlling min_per_shard_tablet_count to improve
tablet balancing, for hot tables.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
This commit addresses issue #21825, where invalid PERCENTILE values for
the `speculative_retry` setting were not properly handled, causing potential
server crashes. The valid range for PERCENTILE is between 0 and 100, as defined
in the documentation for speculative retry options, where values above 100 or
below 0 are invalid and should be rejected.
The added validation ensures that such invalid values are rejected with a clear
error message, improving system stability and user experience.
Fixes#21825Closesscylladb/scylladb#21879
Currently, when we load a frozen schema into the registry, we lose
the base info if the schema was of a view. Because of that, in various
places we need to set the base info again, and in some codepaths we
may miss it completely, which may make us unable to process some
requests (for example, when executing reverse queries on views).
Even after setting the base info, we may still lose it if the schema
entry gets deactivated due to all `schema_ptr`s temporarily dying.
To fix this, this patch adds the base schema to the registry, alongside
the view schema. We store just the frozen base schema, so that we can
transfer it across shards. With the base schema, we can now set the base
info when returning the schema from the registry. As a result, we can now
assume that all view schemas returned by the registry have base_info set.
In this series we also make sure that the view schemas in the registry are
kept up-to-date in regards to base schema changes.
Fixes https://github.com/scylladb/scylladb/issues/21354
This issue is a bug, so adding backport labels 6.1 and 6.2
Closesscylladb/scylladb#21862
* github.com:scylladb/scylladb:
test: add test for schema registry maintaining base info for views
schema_registry: avoid setting base info when getting the schema from registry
schema_registry: update cached base schemas when updating a view
schema_registry: cache base schemas for views
db: set base info before adding schema to registry
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
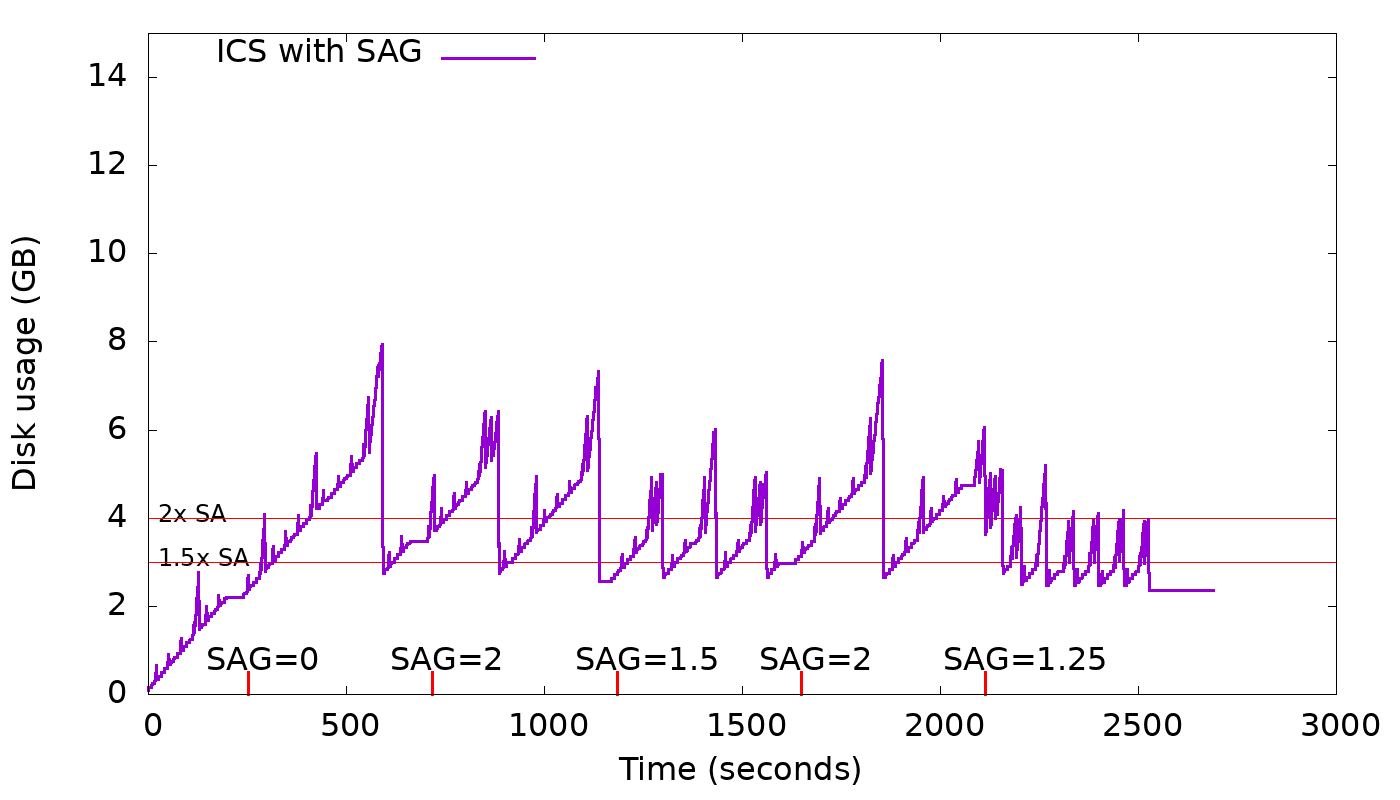
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
This string conversion functions are not in any fast path. Deinlining
them moves a <boost/lexical_cast.hpp> include out of a common header file.
Some files accessed on boost::iterator_range via lexical_cast.hpp,
so they gain a new dependency.
Closesscylladb/scylladb#21950
After the previous patches, the view schemas returned by schema registry
always have their base info set. As such, we no longer need to set it after
getting the view schema from the registry. This patch removes these
unnecessary updates.
The schema registry now holds base schemas for view schemas.
The base schema may change without changing the view schema, so to
preserve the change in the schema registry, we also update the
base schema in the registry when updating the base info in the
view schema.
Currently, when we load a frozen schema into the registry, we lose
the base info if the schema was of a view. Because of that, in various
places we need to set the base info again, and in some codepaths we
may miss it completely, which may make us unable to process some
requests (for example, when executing reverse queries on views).
Even after setting the base info, we may still lose it if the schema
entry gets deactivated.
To fix this, this patch adds the base schema to the registry, alongside
the view schema. With the base schema, we can now set the base
info when returning the schema from the registry. As a result, we can now
assume that all view schemas returned by the registry have base_info set.
To store the base schema, the loader methods now have to return the base
schema alongside the view schema. At the same time, when loading into
the registry, we need to check whether we're loading a view schema, and if
so, we need to also provide the base schema. When inserting a regular table
schema, the base schema should be a disengaged optional.
Schema of system tables is defined statically and table_schema_version needs to be explicitly set in code like this:
```
builder.with_version(system_keyspace::generate_schema_version(table_id, version_offset));
```
Whenever schema is changed, the schema version needs to change, otherwise we hit undefined behavior when trying to interpret mutation data created with the old schema using the new schema.
It's not obvious that one needs to do that and developers often forget to do that. There were several instances of mistakes of omission, some caught during review, some not, e.g.: 31ea74b96e.
This patch changes definitions to call the new `schema_builder::with_hash_version()`, which will make the schema builder compute version from schema definition so that changes of the schema will automatically change the version. This way we no longer rely on the developer to remember to bump the version offset.
All nodes should arrive at the same version, which is verified by existing `test_group0_schema_versioning` and a new unit test: `test_system_schema_version_is_stable`.
Closesscylladb/scylladb#21602
* github.com:scylladb/scylladb:
system_tables: Compute schema version automatically
schema_builder: Introduce with_hash_version()
schema: Store raw_view_info in schema::raw_schema
schema: Remove dead comment
hashing: Add hasher for unordered_map
hashing: Add hasher for unique_ptr
hashing: Add hasher for double
[avi: add missing include <memory> to hashing.hh]
Our "sstring_view" is an historic alias for the standard std::string_view.
The patch changes the last remaining random uses of this old alias across
our source directory to the standard type name.
After this patch, there are no more uses of the "sstring_view" alias.
It will be removed in the following patch.
Refs #4062.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
For historic reasons, we have (in bytes.hh) a type sstring_view which
is an alias for std::string_view - since the same standard type can hold
a pointer into both a seastar::sstring and std::string.
This alias in unnecessary and misleading to new developers (who might
assume it is somehow different from std::string_view). This patch doesn't
yet remove all occurances of sstring_view (the request in #4062), but
begins to do it by renaming one commonly-used function, to_sstring_view(bytes)
to to_string_view() and of course changes all its uses to the new name.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Currently, if version is missing, we use a unique timeuuid as the
version. It's not useful for creating static schema of system tables
because to achieve the same version on all the nodes, version needs to
be provided externally.
This patch introduces a way to build the schema with version computed
from schema definition, so we can have a stable version which is the
same on all machines.
Will be used for reliable computation of schema version for system
tables. System tables currently set the version statically and we rely
on the developer to bump up the version manually when the definition
changes. We cannot use mutation hash, since system tables are
initialized too rearly (mutation hash needs system schema to be
already there). This is a very error prone process, as it is easy to
forget to do so, and the issue comes up only when testing mixed
clusters.
It will be used for hashing, which will work with raw_schema.
Also, it's more in-line with the current design, where basic information
is kept in raw_schema and other fields are derived from it.
Recently, seastar rpc started accepting std::type_identity in addition
to boost::type as a type marker (while labeling the latter with an
ominous deprecation warning). Reduce our depedendency on boost
by switching to std::type_identity.
{kind=link}