One of its caller is in the RESTful API which gets ips from the user, so
we convert ips to ids inside the API handler using gossiper before
calling the function. We need to deprecate ip based API and move to host
id based.
these unused includes were identifier by clang-include-cleaner. after
auditing these source files, all of the reports have been confirmed.
please note, because quite a few source files relied on
`utils/to_string.hh` to pull in the specialization of
`fmt::formatter<std::optional<T>>`, after removing
`#include <fmt/std.h>` from `utils/to_string.hh`, we have to
include `fmt/std.h` directly.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Fixes https://github.com/scylladb/scylla-enterprise/issues/5016#issuecomment-2558464631
EAR - encryption at rest. Allows on-disk file encryption of sstables and commitlog data.
Introduces OpenSSL based file level encrypted storage, managed via a set of providers
ranging from local files to cloud KMS providers.
For a more comprehensive explanation, see the included docs (or if possible, original
source tree).
Manual bulk merge of EAR feature from enterprise repo to main scylla repo.
Breaks some features apart, but main EAR is still a humongous commit, because to separate this
I would have to mess with code incrementally, adding time and risk.
This PR includes the local file gen tool, tests and also p11 validation.
Note: CI will not execute the full tests unless master CI is set to provide the same environment
as the enterprise one. Not sure about the status of this ATM.
Note: Includes code to compile against cryptsoft kmipc SDK, but not the SDK. If you happen to
check out this tree in the scylla folder and configure, it will be linked against and KMIP functionality
will be enabled, otherwise not.
Closesscylladb/scylladb#22233
* github.com:scylladb/scylladb:
docs: Add EAR docs
main/build: Add p11-kit and initialize
tools: Add local-file-key-generator tool
tests: Add EAR tests
tmpdir: shorten test tempdir path
EAR: port the ear feature from enterprise
cql_test_env: Add optional query timeout
schema/migration_manager: Add schema validate
sstables: add get_shared_components accessor
config/config_file: Add exports and definitions of config_type_for<>
Instantiated only on shard 0.
Currently, only subscribe from unit test
Manual unit test using loop mount was added.
Note that the test requires sudo access
and root access to /dev/loop, so it cannot
run in rootless podman instance, and it'd
fail with Permission denied.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Closesscylladb/scylladb#21523
This PR extends authentication with 2 mechanisms:
- a new role_manager subclass, which allows managing users via
LDAP server,
- a new authenticator, which delegates plaintext authentication
to a running saslauthd daemon.
The features have been ported from the enterprise repository
with their test.py tests and the documentation as part of
changing license to source available.
Fixes: scylladb/scylla-enterprise#5000Fixes: scylladb/scylla-enterprise#5001Closesscylladb/scylladb#22030
When starting the view builder, we find all existing views in
`calculate_shard_build_step` and then register a listener for new views.
Between these steps we may yield and create a new view, then we miss
initializing the view build step for the new view, and we won't start
building it.
To fix this we first register the listener and then read existing views,
so a view can't be missed.
Fixesscylladb/scylladb#20338Closesscylladb/scylladb#22184
Usually, the smaller the messsage, the higher the CPU cost per each network byte
saved by compression, so it often makes sense to reserve heavier compression
for bigger messages (where it can make the biggest impact for a given CPU budget)
and use ligher compression for smaller messages.
There is a knob -- internode_compression_zstd_min_message_size -- which
excludes RPC messages below certain size from being compressed with zstd.
We arbitrarily set its default to 0 bytes before.
Now we want to arbitrarily set it to 1024 bytes.
This is based purely on intuition and isn't backed by any solid data.
Fixesscylladb/scylla-enterprise#4731Closesscylladb/scylla-enterprise#4990Closesscylladb/scylladb#22204
We still have a number of issues to be solved for views with tablets.
Until they are fixed, we should prevent users from creating them,
and use the vnode-based views instead.
This patch prepares the feature for enabling views with tablets. The
feature is disabled by default, but currently it has no effect.
After all tests are adjusted to use the feature, we should depend
on the feature for deciding whether we can create materialized views
in tablet-enabled keyspaces.
The unit tests are adjusted to enable this feature explicitly, and it's
also added to the scylla sstable tool config - this tool treats all
tables as if they were tablet-based (surprisingly, with SimpleStrategy),
so for it to work on views, the new feature must be enabled.
Refs scylladb/scylladb#21832Closesscylladb/scylladb#21833
mark the config parameter --commitlog-use-hard-size-limit as deprecated so the
default 'true' is always used, making the hard limit mandatory.
Fixesscylladb/scylladb#16471Closesscylladb/scylladb#21804
node_ops_virtual_task does not filter the entries of system.topology_request
and so it creates statuses of operations that aren't node ops.
Filter the entries used by node_ops_virtual_task. With this change, the status
of a bootstrap of the first node will not be visible.
Fixes: https://github.com/scylladb/scylladb/issues/22008.
Needs backport to 6.2 that introduced node_ops_virtual_task
Closesscylladb/scylladb#22009
* github.com:scylladb/scylladb:
test: truncate the table before node ops task checks
node_ops: rename a method that get node ops entries
node_ops: filter topology_requests entries
now that we are allowed to use C++23. we now have the luxury of using
`std::views::reverse`.
- replace `boost::adaptors::transformed` with `std::views::transform`
- remove unused `#include <boost/range/adaptor/reversed.hpp>`
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Replace usages of `boost::algorithm::join()` with `fmt::join()` to improve
performance and reduce dependency on Boost. `fmt::join()` allows direct
formatting of ranges and tuples with custom separators without creating
intermediate strings.
When formatting comma-separated values into another string, fmt::join()
avoids the overhead of temporary string creation that
`boost::algorithm::join()` requires. This change also helps streamline
our dependencies by leveraging the existing fmt library instead of
Boost.Algorithm.
To avoid the ambiguity, some caller sites were updated to call
`seastar::format()` explicitly.
See also
- boost::algorithm::join():
https://www.boost.org/doc/libs/1_87_0/doc/html/string_algo/reference.html#doxygen.join_8hpp
- fmt::join():
https://fmt.dev/11.0/api/#ranges-api
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22082
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
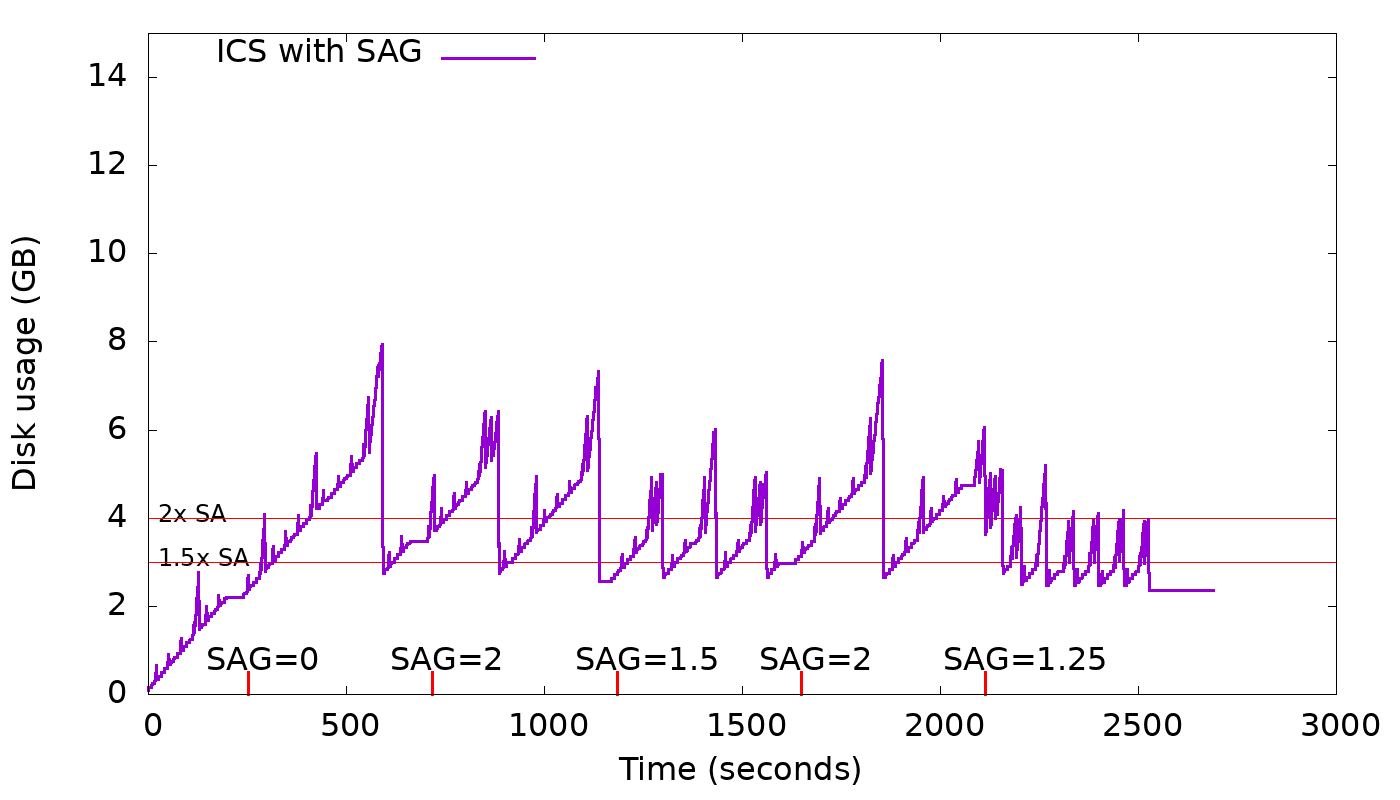
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
Add the "shares" column to the
system_distributed_keyspace.service_levels table, which is used by
legacy code.
Because this table is in a distributed and not local keyspace, adding
the column to an existing cluster during rolling upgrade requires a bit
of care. A callback is added to the workload prioritization cluster
feature which runs when the feature becomes enabled and adds the column
for all nodes in the cluster.
Add a "shares" column which hold the number of shares allocated to
given service level.
It is not used by the code at all right now, subsequent commits will
make good use of it.
This is a forward port (from scylla-enterprise) of additional compression options (zstd, dictionaries shared across messages) for inter-node network traffic. It works as follows:
After the patch, messaging_service (Scylla's interface for all inter-node communication)
compresses its network traffic with compressors managed by
the new advanced_rpc_compression::tracker. Those compressors compress with lz4,
but can also be configured to use zstd as long as a CPU usage limit isn't crossed.
A precomputed compression dictionary can be fed to the tracker. Each connection
handled by the tracker will then start a negotiation with the other end to switch
to this dictionary, and when it succeeds, the connection will start being compressed using that dictionary.
All traffic going through the tracker is passed as a single merged "stream" through dict_sampler.
dictionary_service has access to the dict_sampler.
On chosen nodes (in the "usual" configuration: the Raft leader), it uses the sampler to maintain
a random multi-megabyte sample of the sampler's stream. Every several minutes,
it copies the sample, trains a compression dictionary on it (by calling zstd's
training library via the alien_worker thread) and publishes the new dictionary
to system.dicts via Raft's write_mutation command.
This update triggers (eventually) a callback on all nodes, which feeds the new dictionary
to advanced_rpc_compression::tracker, and this switches (eventually) all inter-node connections
to this dictionary.
Closesscylladb/scylladb#22032
* github.com:scylladb/scylladb:
messaging_service: use advanced_rpc_compression::tracker for compression
message/dictionary_service: introduce dictionary_service
service: make Raft group 0 aware of system.dicts
db/system_keyspace: add system.dicts
utils: add advanced_rpc_compressor
utils: add dict_trainer
utils: introduce reservoir_sampling
utils: introduce alien_worker
utils: add stream_compressor
This patch sets up an `alien_worker`, `advanced_rpc_compression::tracker`,
`dict_sampler` and `dictionary_service` in `main()`, and wires them to each other
and to `messaging_service`.
`messaging_service` compresses its network traffic with compressors managed by
the `advanced_rpc_compression::tracker`. All this traffic is passed as a single
merged "stream" through `dict_sampler`.
`dictionary_service` has access to `dict_sampler`.
On chosen nodes (by default: the Raft leader), it uses the sampler to maintain
a random multi-megabyte sample of the sampler's stream. Every several minutes,
it copies the sample, trains a compression dictionary on it (by calling zstd's
training library via the `alien_worker` thread) and publishes the new dictionary
to `system.dicts` via Raft.
This update triggers a callback into `advanced_rpc_compression::tracker` on all nodes,
which updates the dictionary used by the compressors it manages.
now that we are allowed to use C++23. we now have the luxury of using
`std::ranges::to`.
in this change, we:
- replace `boost::copy_range` to `std::ranges::to`
- remove unused `#include` of boost headers
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21880
Adds a new system table which will act as the medium for distributing
compression dictionaries over the cluster.
This table will be managed by Raft (group 0). It will be hooked up to it in
follow-up commits.
Currently node_ops_virtual_task shows stats of all system.topology_request
entries. However, the table also contains info about non-node_ops requests,
e.g. truncate.
Filter the entries used by node_ops_virtual_task by their type.
With this change bootstrap of the first node will not be visible.
Update the test accordingly.
now that we are allowed to use C++23. we now have the luxury of using
`std::ranges::stable_partition`.
in this change, we:
- replace `boost::range::stable_parition()` to
`std::ranges::stable_parition()`
- since `std::ranges::stable_parition()` returns a subrange instead of
an iterator, change the names of variables which were previously used
for holding the return value of `boost::range::stable_partition()`
accordingly for better readability.
- remove unused `#include` of boost headers
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21911
Currently, when finishing db::view::calculate_affected_clustering_ranges
we deoverlap, transform and copy all ranges prepared before. This
is all done within a single continuation and can cause stalls.
We fix this by adding yields after each transform and moving elements
to the final vector one by one instead of copying them all at the end.
After this change, the longest continuation in this code will be
deoverlapping the initial ranges (and one transform). While it has
a relatively high computational complexity (we sort all ranges), it
should execute quickly because we're operating on views there and
we don't need to copy the actual bytes. If we encounter a stall there,
we'll need to implement an asynchronous `deoverlap` method.
Fixesscylladb/scylladb#21843Closesscylladb/scylladb#21846
this issue was identified by clang-20.
---
it's a cleanup, hence no need to backport.
Closesscylladb/scylladb#21835
* github.com:scylladb/scylladb:
locator: remove unused member variable
auth: remove unused member variable
db: remove unused member variable
This pull request is continuation of scylladb/scylladb#20688 - contents of the main commit are the same, the only change is the additional commit with a test.
Until this patch, the materialized view flow-control algorithm (https://www.scylladb.com/2018/12/04/worry-free-ingestion-flow-control/) used a constant delay_limit_us hard-coded to one second, which means that when the size of view-update backlog reached the maximum (10% of memory), we delay every request by an additional second - while smaller amounts of backlog will result in smaller delays.
This hard-coded one maximum second delay was considered *huge* - it will slow down a client with concurrency 1000 to just 1000 requests per second - but we already saw some workloads where it was not enough - such as a test workload running very slow reads at high concurrency on a slow machine, where a latency of over one second was expected for each read, so adding a one second latecy for writes wasn't having any noticable affect on slowing down the client.
So this patch replaces the hard-coded default with a live-updateable configuration parameter, `view_flow_control_delay_limit_in_ms`, which defaults to 1000ms as before.
Another useful way in which the new `view_flow_control_delay_limit_in_ms` can be used is to set it to 0. In that case, the view-update flow control always adds zero delay, and in effect - does absolutely nothing. This setting can be used in emergency situations where it is suspected that the MV flow control is not behaving properly, and the user wants to disable it.
The new parameter's help string mentions both these use cases of the parameter.
Fixes#18187
This is new functionality, no need to backport to any open source release.
Closesscylladb/scylladb#21647
* github.com:scylladb/scylladb:
materialized views: test for the MV delay configuration parameter
service: add injection for skipping view update backlog
materialized view: make flow-control maximum delay configurable
This change goes thru locator:topology to use node&
instead of node* where nullptr is not possible. There are
places where the node object is used in unordered_set, in
those cases the node is wrapped in std::reference_wrapper.
Fixesscylladb/scylladb#20357Closesscylladb/scylladb#21863
Currently truncating a table works by issuing an RPC to all the nodes which call `database::truncate_table_on_all_shards()`, which makes sure that older writes are dropped.
It works with tablets, but is not safe. A concurrent replication process may bring back old data.
This change makes makes TRUNCATE TABLE a topology operation, so that it excludes with other processes in the system which could interfere with it. More specifically, it makes TRUNCATE a global topology request.
Backporting is not needed.
Fixes#16411Closesscylladb/scylladb#19789
* github.com:scylladb/scylladb:
docs: docs: topology-over-raft: Document truncate_table request
storage_proxy: fix indentation and remove empty catch/rethrow
test: add tests for truncate with tablets
storage_proxy: use new TRUNCATE for tablets
truncate: make TRUNCATE a global topology operation
storage_service: move logic of wait_for_topology_request_completion()
RPC: add truncate_with_tablets RPC with frozen_topology_guard
feature_service: added cluster feature for system.topology schema change
system.topology_requests: change schema
storage_proxy: propagate group0 client and TSM dependency
Replace boost::make_iterator_range() with std::ranges::subrange.
This change improves code modernization and reduces external dependencies:
- Replace boost::make_iterator_range() with std::ranges::subrange
- Remove boost/range/iterator_range.hpp include
- Improve iterator type detection in interval.hh using std::ranges::const_iterator_t<Range>
This is part of ongoing efforts to modernize our codebase and minimize
external dependencies.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21787
since fedora 38 is EOL. and fedora 39 comes with fmt v10.0.0, also,
we've switched to the build image based on fedora 40, which ships
fmt-devel v10.2.1, there is no need to support fmt < 10.
in this change, we drop the support fmt < 10.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21847
The function get_service_levels is used to retrieve all service levels
and it is called from multiple different contexts.
Importantly, it is called internally from the context of group0 state reload,
where it should be executed with a long timeout, similarly to other
internal queries, because a failure of this function affects the entire
group0 client, and a longer timeout can be tolerated.
The function is also called in the context of the user command LIST
SERVICE LEVELS, and perhaps other contexts, where a shorter timeout is
preferred.
The commit introduces a function parameter to indicate whether the
context is internal or not. For internal context, a long timeout is
chosen for the query. Otherwise, the timeout is shorter, the same as
before. When the distinction is not important, a default value is
chosen which maintains the same behavior.
The main purpose is to fix the case where the timeout is too short and causes
a failure that propagates and fails the group0 client.
Fixesscylladb/scylladb#20483Closesscylladb/scylladb#21748
Until this patch, the materialized view flow-control algorithm
(https://www.scylladb.com/2018/12/04/worry-free-ingestion-flow-control/)
used a constant delay_limit_us hard-coded to one second, which means
that when the size of view-update backlog reached the maximum (10%
of memory), we delay every request by an additional second - while
smaller amounts of backlog will result in smaller delays.
This hard-coded one maximum second delay was considered *huge* - it will
slow down a client with concurrency 1000 to just 1000 requests per
second - but we already saw some workloads where it was not enough -
such as a test workload running very slow reads at high concurrency
on a slow machine, where a latency of over one second was expected
for each read, so adding a one second latecy for writes wasn't having
any noticable affect on slowing down the client.
So this patch replaces the hard-coded default with a live-updateable
configuration parameter, `view_flow_control_delay_limit_in_ms`, which
defaults to 1000ms as before.
Another useful way in which the new `view_flow_control_delay_limit_in_ms`
can be used is to set it to 0. In that case, the view-update flow
control always adds zero delay, and in effect - does absolutely
nothing. This setting can be used in emergency situations where it
is suspected that the MV flow control is not behaving properly, and
the user wants to disable it.
The new parameter's help string mentions both these use cases of
the parameter.
Fixes#18187
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
"
This rather large patch series moves storage proxy and some adjacent
services (like migration manager) to use host ids to identify nodes rather
than ips. Messaging service gains a capability to address nodes by host
ids (which allows dropping translations from topology coordinator code
that worked on host ids already) and also makes sure that a node with
incorrect host id will reject a message (can happen during address
changes).
The series gets rid of the raft address map completely and replaces it with
the gossiper address map which is managed by the gossiper since translation
is now done in the layer below raft.
Fixes: scylladb/scylladb#6403
perf-simple-query -- smp 1 -m 1G output
Before:
enable-cache=1
Running test with config: {partitions=10000, concurrency=100, mode=read, frontend=cql, query_single_key=no, counters=no}
Disabling auto compaction
Creating 10000 partitions...
64336.82 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41291 insns/op, 24485 cycles/op, 0 errors)
62669.58 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41277 insns/op, 24695 cycles/op, 0 errors)
69172.12 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.2 tasks/op, 41326 insns/op, 24463 cycles/op, 0 errors)
56706.60 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41143 insns/op, 24513 cycles/op, 0 errors)
56416.65 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41186 insns/op, 24851 cycles/op, 0 errors)
throughput: mean=61860.35 standard-deviation=5395.48 median=62669.58 median-absolute-deviation=5153.75 maximum=69172.12 minimum=56416.65
instructions_per_op: mean=41244.62 standard-deviation=76.90 median=41276.94 median-absolute-deviation=58.55 maximum=41326.19 minimum=41142.80
cpu_cycles_per_op: mean=24601.35 standard-deviation=167.39 median=24512.64 median-absolute-deviation=116.65 maximum=24851.45 minimum=24462.70
After:
enable-cache=1
Running test with config: {partitions=10000, concurrency=100, mode=read, frontend=cql, query_single_key=no, counters=no}
Disabling auto compaction
Creating 10000 partitions...
65237.35 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.2 tasks/op, 40733 insns/op, 23145 cycles/op, 0 errors)
59283.09 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40624 insns/op, 23948 cycles/op, 0 errors)
70851.03 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40625 insns/op, 23027 cycles/op, 0 errors)
70549.61 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40650 insns/op, 23266 cycles/op, 0 errors)
68634.96 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40622 insns/op, 22935 cycles/op, 0 errors)
throughput: mean=66911.21 standard-deviation=4814.60 median=68634.96 median-absolute-deviation=3638.40 maximum=70851.03 minimum=59283.09
instructions_per_op: mean=40650.89 standard-deviation=47.55 median=40624.60 median-absolute-deviation=27.11 maximum=40733.37 minimum=40622.33
cpu_cycles_per_op: mean=23264.16 standard-deviation=402.12 median=23145.29 median-absolute-deviation=237.63 maximum=23947.96 minimum=22934.59
CI: https://jenkins.scylladb.com/job/scylla-master/job/scylla-ci/13531/
SCT (longevity-100gb-4h with nemesis_selector: ['topology_changes']): https://jenkins.scylladb.com/view/staging/job/scylla-staging/job/gleb/job/move-to-host-id/3/
Tested mixed cluster manually.
"
* 'gleb/move-to-host-id-v2' of github.com:scylladb/scylla-dev: (55 commits)
group0: drop unused field from replace_info struct
test: rename raft_address_map_test to address_map_test and move if from raft tests
raft_address_map: remove raft address map
topology coordinator: do not modify expire state for left/new nodes any more in raft address map
topology coordinator: drop expiring entries in gossiper address map on error injections since raft one is no longer used
group0: drop raft address map dependency from raft_rpc
group0: move raft_ticker_type definition from raft_address_map.hh
storage_service: do not update raft address map on gossiper events
group0: drop raft address map dependency from raft_server_with_timeouts
group0: move group0 upgrade code to host ids
repair: drop raft address map dependency
group0: remove unused raft address map getter from raft_group0
group0: drop raft address map from group0_state_machine dependency since it is not used there any more
group0: remove dependency on raft address map from group0_state_id_handler
gossiper: add get_application_state_ptr that searches by host_id
gossiper: change get_live_token_owners to return host ids
view: move view building to host id
hints: use host id to send hints
storage_proxy: remove id_vector_to_addr since it is no longer used
db: consistency_level: change is_sufficient_live_nodes to work on host ids
...
now that we are allowed to use C++23. we now have the luxury of using
`std::views::transform`.
in this change, we:
- replace `boost::adaptors::transformed` with `std::views::transform`
- use `fmt::join()` when appropriate where `boost::algorithm::join()`
is not applicable to a range view returned by `std::view::transform`.
- use `std::ranges::fold_left()` to accumulate the range returned by
`std::view::transform`
- use `std::ranges::fold_left()` to get the maximum element in the
range returned by `std::view::transform`
- use `std::ranges::min()` to get the minimal element in the range
returned by `std::view::transform`
- use `std::ranges::equal()` to compare the range views returned
by `std::view::transform`
- remove unused `#include <boost/range/adaptor/transformed.hpp>`
- use `std::ranges::subrange()` instead of `boost::make_iterator_range()`,
to feed `std::views::transform()` a view range.
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
limitations:
there are still a couple places where we are still using
`boost::adaptors::transformed` due to the lack of a C++23 alternative
for `boost::join()` and `boost::adaptors::uniqued`.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21700
This commit addresses inconsistent spelling annotations that triggered
codespell warnings in our codebase.
Problem:
- Previous annotations like "CREATEing" and "DROPing" were flagged as
misspellings by the codespell workflow
- These annotations were used to describe CQL statement execution contexts
Solution:
- Updated annotations to "CREAT'ing" and "DROP'ing"
- Preserves the intent of the original annotations
- Silences codespell warnings without changing the underlying meaning
- Ensures consistent and spell-checker-friendly code documentation
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21741
{kind=link}