Adds the per_partition_rate_limit_test.cc file. Currently, it only
contains a test which verifies that the feature correctly switches off
rate limiting for internal queries (!allow_limit || internal sg).
Introduces the rate_limiter, a replica-side data structure meant for
tracking the frequence with which each partition is being accessed
(separately for reads and writes) and deciding whether the request
should be accepted and processed further or rejected.
The limiter is implemented as a statically allocated hashmap which keeps
track of the frequency with which partitions are accessed. Its entries
are incremented when an operation is admitted and are decayed
exponentially over time.
If a partition is detected to be accessed more than its limit allows,
requests are rejected with a probability calculated in such a way that,
on average, the number of accepted requests is kept at the limit.
The structure currently weights a bit above 1MB and each shard is meant
to keep a separate instance. All operations are O(1), including the
periodic timer.
If the len2 argument to crc32_combine() is zero, then the crc2
argument must also be zero.
fast_crc32_combine() explicitly checks for len2==0, in which case it
ignores crc2 (which is the same as if it were zero).
zlib's crc32_combine() used to have that check prior to version
1.2.12, but then lost it, making its necessary for callers to be more
careful.
Also add the len2==0 check to the dummy fast_crc32_combine()
implementation, because it delegates to zlib's.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
Closes#10731
"
In order to wire-in the compaction_throughput_mb_per_sec the compaction
creation and stopping will need to be patched. Right now both places are
quite hairy, this set coroutinizes stop() for simpler adding of stopping
bits, unifies all the compaction manager constructors and adds the
compaction_manager::config for simpler future extending.
As a side effect the backlog_controller class gets an "abstract" sched
group it controlls which in turn will facilitate seastar sched groups
unification some day.
"
* 'br-compaction-manager-start-stop-cleanup' of https://github.com/xemul/scylla:
compaction_manager: Introduce compaction_manager::config
backlog_controller: Generalize scheduling groups
database: Keep compound flushing sched group
compaction_manager: Swap groups and controller
compaction_manager: Keep compaction_sg on board
compaction_manager: Unify scheduling_group structures
compaction_manager: Merge static/dynamic constructors
compaction_manager: Coroutinuze really_do_stop()
compaction_manager: Shuffle really_do_stop()
compaction_manager: Remove try-catch around logger
The sstable set param isn't being used anywhere, and it's also buggy
as sstable run list isn't being updated accordingly. so it could happen
that set contains sstables but run list is empty, introducing
inconsistency.
we're fortunate that the bug wasn't activated as it would've been
a hard one to catch. found this while auditting the code.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220617203438.74336-1-raphaelsc@scylladb.com>
from Nadav Har'El
This small series improves Alternator's BatchGetItem performance by
grouping requests to the same partition together (Fixes#10753) and also
improves error checking when the same item is requested more than once
(Fixes#10757).
Closes#10834
* github.com:scylladb/scylla:
alternator: make BatchGetItem group reads by partition
test/alternator: additional test for BatchGetItem
DynamoDB API's BatchGetItem invokes a number (up to 25) of read requests
in parallel, returning when all results are available. Alternator naively
implemented this by sending all read requests in parallel, no matter which
requests these were.
That implementation was inefficient when all the requests are to different
items (clustering rows) of the same partition. In a multi-node setup this
will end up sending 25 separate requests to the same remote node(s). Even
on a single-node setup, this may result in reading from disk more than
once, and even if the partition is cached - doing an O(logN) search in
each multiple times.
What we do in this patch, instead, is to group all the BatchGetItem
requests that aimed at the same partition into a single read request
asking for a (sorted) list of clustering keys. This is similar to an
"IN" request in CQL.
As an example of the performance benefit of this patch, I tried a
BatchGetItem request asking for 20 random items from a 10-million item
partition. I measured the latency of this request on a single-node
Scylla. Before this patch, I saw a latency of 17-21 ms (the lower number
is when the request is retried and the requested items are already in
the cache). After this patch, the latency is 10-14 ms. The performance
improvement on multi-node clusters are expected to be even higher.
Unfortunately the patch is less trivial than I hoped it would be,
because some of the old code was organized under the assumption that
each read request only returned one item (and if it failed, it means
only one item failed), so this part of the code had to be reorganized
(and, for making the code more readable, coroutinized).
An unintended benefit of the code reorganization is that it also gave
me an opportunity to fail an attempt to ask BatchGetItem the same
item more than once (issue #10757).
The patch also adds a few more corner cases in the tests, to be even
more sure that the code reorganization doesn't introduce a regression
in BatchGetItem.
Fixes#10753Fixes#10757
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Commit e739f2b779 ("cql3: expr: make evaluate() return a
cql3::raw_value rather than an expr::constant") introduced
raw_value::view() as a synonym to raw_value::to_view() to reduce
churn. To fix this duplication, we now remove raw_value::to_view().
raw_value::to_view() was picked for removal because is has fewer
call sites, reducing churn again.
Closes#10819
A named bind-variable can be reused:
SELECT * FROM tab
WHERE a = :var AND b = :var
Currently, the grammar just ignores the possibility and creates
a new variable with the same name. The new variable cannot be
referenced by name since the first one shadows it.
Catch variable reuse by maintaining a map from bind variable names
to indexed, and check that when reusing a bind variable the types
match.
A unit test is added.
Fixes#10810Closes#10813
When evaluating an LWT condition involving both static and non-static
cells, and matching no regular row, the static row must be used UNLESS
the IF condition is IF EXISTS/IF NOT EXISTS, in which case special rules
apply.
Before this fix, Scylla used to assume a row doesn't exist if there is
no matching primary key. In Cassandra, if there is a
non-empty static row in the partition, a regular row based
on the static row' cell values is created in this case, and then this
row is used to evaluate the condition.
This problem was reported as gh-10081.
The reason for Scylla behaviour before the patch was that when
implementing LWT I tried to converge Cassandra data model (or lack of
thereof) with a relational data model, and assumed a static row is a
"shared" portion of a regular row, i.e. a storage level concept intended
to save space, and doesn't have independent existence.
This was an oversimplification.
This patch fixes gh-10081, making Scylla semantics match the one of
Cassandra.
I will now list other known examples when a static row has an own
independent existence as part of a table, for cataloguing purposes.
SELECT * from a partition which has a partition key
and a static cell set returns 1 row. If later a regular row is added
to the partition, the SELECT would still return 1 row, i.e.
the static row will disappear, and a regular row will appear instead.
Another example showing a static row has an independent existence below:
CREATE TABLE t (p int, c int, s int static, PRIMARY KEY(p, c));
INSERT INTO t (p, c) VALUES(1, 1);
INSERT INTO t (p, s) VALUES(1, 1) IF NOT EXISTS;
In Cassandra (and Scylla), IF NOT EXISTS evaluates to TRUE, even though both
the regular row and the partition exist. But the static cells are not
set, and the insert only provides a partition key, so the database assumes the
insert is operating against a static row.
It would be wrong to assume that a static row exists when the partition
key exists:
INSERT INTO t (p, c, s) VALUES(1, 1, 1) IF NOT EXISTS;
[applied] | p | c | s
-----------+---+---+------
False | 1 | 1 | null
evaluates to False, i.e. the regular row does exist when p and c exist.
Issue
CREATE TABLE t (p INT, c INT, r INT, s INT static, PRIMARY KEY(p, c))
INSERT INTO t (p, s) VALUES (1, 1);
UPDATE t SET s=2, r=1 WHERE p=1 AND c=1 IF s=1 and r=null;
- in this case, even though the regular row doesn't exist, the static
row does, and should be used for condition evaluation.
In other words, IF EXISTS/IF NOT EXISTS have contextual semantics.
They apply to the regular row if clustering key is used in the WHERE
clause, otherwise they apply to static row.
One analogy for static rows is that it is like a static member of C++ or
Java class. It's an attribute of the class (assuming class = partition),
which is accessible through every object of the class (object = regular
row). It is also present if there are no objects of the class, but the
class itself exists: i.e. a partition could have no regular rows, but
some static cells set, in this case it has a static row.
*Unlike C++/Java static class members* a static row is an optional
attribute of the partition. A partition may exist, but the static row
may be absent (e.g. no static cell is set). If the static row does exist,
all regular rows share its contents, *even if they do not exist*.
A regular row exists when its clustering key is present
in the table. A static row exists when at least one static cell is set.
Tests are updated because now when no matching row is found
for the update we show the value of the static row as the previous
value, instead of a non-matching clustering row.
Changes in v2:
- reworded the commit message
- added select tests
Closes#10711
Our simple test for BatchGetItem on a table with sort keys still has
requests with just one sort key per partition, so if BatchGetItem has
a bug with requesting multiple sort keys from the same partition,
such bug won't be caught by the simple tests. So in this test we add a
test that does. This will be useful for the next patch, we are planning
to refactor BatchGetItem's handling of multiple sort keys in the same
partition - so it will be useful to have more regression tests.
The tests test_batch_get_item_large and test_batch_get_item_partial
would actually also catch such bugs, but they are more elaborate tests
and it's nice to have smaller tests more focused on checking specific
features.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
This is to make it constructible in a way most other services are -- all
the "scalar" parameters are passed via a config.
With this it will be much shorter to add compaction bandwidth throttling
option by just extending the config itself, not the list of constructor
arguments (and all its callers).
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The only difference between those two are in the way backlog controller
is created. It's much simpler to have the controller construction logic
in compaction manager instead. Similar "trick" is used to construct
flush controller for the database.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
A pre-scrub view snapshot cannot be attributed to user error, so no
call to bail out.
Closes#10760.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
Closes#10783
* github.com:scylladb/scylla:
api-doc: correct spelling
allow pre-scrub snapshots of materialized views and secondary indices
When memtable receives a tombstone it can happen under some workloads
that it covers data which is still in the memtable. Some workloads may
insert and delete data within a short time frame. We could reduce the
rate of memtable flushes if we eagerly drop tombstoned data.
One workload which benefits is the raft log. It stores a row for each
uncommitted raft entry. When entries are committed they are
deleted. So the live set is expected to be short under normal
conditions.
Fixes#652.
Closes#10807
* github.com:scylladb/scylla:
memtable: Add counters for tombstone compaction
memtable, cache: Eagerly compact data with tombstones
memtable: Subtract from flushed memory when cleaning
mvcc: Introduce apply_resume to hold state for partition version merging
test: mutation: Compare against compacted mutations
compacting_reader: Drop irrelevant tombstones
mutation_partition: Extract deletable_row::compact_and_expire()
mvcc: Apply mutations in memtable with preemption enabled
test: memtable: Make failed_flush_prevents_writes() immune to background merging
This patch adds an extensive array of tests for the Cassandra feature
that Scylla hasn't implemented yet (issues #2962, #8745, #10707) of
indexing the keys, values or entries of a collection column.
The goal of these tests is to explicitly exercise every corner case
I could think of by looking at the documentation of this feature and
considering its possible implementation - and as usual, making sure
that the tests actually pass on Cassandra.
These tests overlap some of the existing unit tests that we translated
from Cassandra, as well as some randomized tests that do not necessarily
cover the same edge cases as these tests cover.
All tests added in this patch pass on Cassandra, but currently fail
on Scylla due to the above issues.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10771
`sstable_directory::process_sstables_dir` may hit an exception when calling `handle_component`.
In this case we currently destroy the `sstable_dir_lister` variable without closing the `directory_lister` first -
leading to terminate in `~directory_lister` as seen in #10697.
This mini-series handles this exception and always closes the `directory_lister`.
Add unit test to reproduce this issue.
Fixes#10697Closes#10754
* github.com:scylladb/scylla:
sstable_directory: process_sstable_dir: fixup indentation
sstable_directory: process_sstable_dir: close directory_lister on error
Before the change, the test artificiallu set the soft pressure
condition hoping that the background flusher will flush the
memtable. It won't happen if by the time the background flusher runs
the LSA region is updated and soft pressure (which is not really
there) is lifted. Once apply() becomes preemptibe, backgroun partition
version merging can lift the soft pressure, making the memtable flush
not occur and making the test fail.
Fix by triggering soft pressure on retries.
Fixes#10801
Refs #10793
(cherry picked from commit 0e78ad50ea)
Closes#10802
If we reach a situation where flush rate exceeds compaction rate, we may
end up with arbitrarily large number of sstables on disk. If a read is
executed in such case, the amount of memory required is proportional to
the number of sstables for the given shard, which in extreme cases can
lead to OOM.
In the wild, this was observed in 2 scenarios:
- A node with >10 shards creates a keyspace with thousands of tables,
drops the keyspace and shuts down before compaction finishes. Dropping
keyspace drops tables, and each dropped table is smp::count writes to
system.local table with flush after write, which creates tens of
thousands of sstables. Bootstrap read from system.local will run OOM.
- A failure to agree on table schema (due to a code bug) between nodes
during repair resulted in excessive flushing of small sstables which
compaction couldn't keep up with.
In the unit test introduced in this patch series it can be proved that
even hard setting maximum shares for compaction and minimum shares for
flushing doesn't tilt the balance towards compaction enough to prevent
the problem. Since it's a fast producer, slow consumer problem, the
remaining solution is to block producer until the consumer catches up.
If there are too many table runs originating from memtable, we block the
current flush until the number of sstables is reduced (via ongoing
compaction or a truncate operation).
Fixes https://github.com/scylladb/scylla/issues/4116
Changelog:
v5:
- added a nicer way of timing the stalls caused by waiting for flush
- added predicate on signal when waiting for reduction of the number of sstables to correctly handle spurious wake ups
- added comment why we trigger compaction before waiting for sstable count reduction
- removed unnecessary cv.signal from table::stop
v4:
- removed conversion of table::stop to coroutines. It's an orthogonal change and doesn't need to go into this patchset
v3:
- removed unnecessary change to scheduling groups from v2
- moved sstables_changed signalling to suggested place in table::stop
- added log how long the table flush was blocked for
- changed the threshold to max(schema()->max_compaction_threshold(), 32) and comparison to <=
v2:
- Reimplemented waiting algorithm based on reviewers' feedback. It's confined to the table class and it waits in a loop until the number of sstable runs goes below threshold. It uses condition variable which is signaled on sstable set refresh. It handles node shutdown as well.
- Converted table::stop to coroutines.
- Reordered commits so that test is committed after fix, so it doesn't trip up bisection.
Closes#10717
* github.com:scylladb/scylla:
table: Add test where compaction doesn't keep up with flush rate.
random_mutation_generator: Add option to specify ks_name and cf_name
table: Prevent creating unbounded number of sstables
Otherwise, if we don't consume all lister's entries,
~directory_lister terminates since the
directory_lister is destroyed without being closed.
Add unit test to reproduce this issue.
Fixes#10697
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
When memtable receives a tombstone it can happen under some workloads
that it covers data which is still in the memtable. Some workloads may
insert and delete data within a short time frame. We could reduce the
rate of memtable flushes if we eagerly drpo tombstoned data.
One workload which benefits is the raft log. It stores a row for each
uncommitted raft entry. When entries are committed they are
deleted. So the live set is expected to be short under normal
conditions.
Fixes#652.
This patch prevents virtual dirty from going negative during memtable
flush in case partition version merging erases data previously
accounted by the flush reader. There is an assert in
~flush_memory_accounter which guards for this.
This will start happening after tombstones are compacted with rows on
partition version merging.
This problem is prevented by the patch by having the cleaner notify
the memtable layer via callback about the amount of dirty memory released
during merging, so that the memtable layer can adjust its accounting.
Memtables and cache will compact eagerly, so tests should not expect
readers to produce exact mutations written, only those which are
equivalant after applying copmaction.
The compacting reader created using make_compacting_reader() was not
dropping range_tombstone_change fragments which were shadowed by the
partition tombstones. As a result the output fragment stream was not
minimal.
Lack of this change would cause problems in unit tests later in the
series after the change which makes memtables lazily compact partition
versions. In test_reverse_reader_reads_in_native_reverse_order we
compare output of two readers, and assume that compacted streams are
the same. If compacting reader doesn't produce minimal output, then
the streams could differ if one of them went through the compaction in
the memtable (which is minimal).
Preerequisite for eagerly applying tombstones, which we want to be
preemptible. Before the patch, apply path to the memtable was not
preemptible.
Because merging can now be defered, we need to involve snapshots to
kick-off background merging in case of preemption. This requires us to
propagate region and cleaner objects, in order to create a snapshot.
Before the change, the test artificiallu set the soft pressure
condition hoping that the background flusher will flush the
memtable. It won't happen if by the time the background flusher runs
the LSA region is updated and soft pressure (which is not really
there) is lifted. Once apply() becomes preemptibe, backgroun partition
version merging can lift the soft pressure, making the memtable flush
not occur and making the test fail.
Fix by triggering soft pressure on retries.
The test simulates a situation where 2 threads issue flushes to 2
tables. Both issue small flushes, but one has injected reactor stalls.
This can lead to a situation where lots of small sstables accumulate on
disk, and, if compaction never has a chance to keep up, resources can be
exhausted.
The series fixes a couple of crashes that were found during starting and
stopping Scylla with raft while doing ddl operations. Most of them
related to shutdown order between different components.
Also in scylla-dev gleb/group0-fixes-v1
CI https://jenkins.scylladb.com/job/releng/job/Scylla-CI/749/
* origin-dev/gleb/group0-fixes-v1:
migration manager: remove unused code
db/system_distributed_keyspace: do not announce empty schema
main: stop raft before the migration manager
storage_service: do not pass the raft group manager to storage_service constructor
main: destroy the group0_client after stopping the group0
Previously, any attempt to take a materialized view or secondary index
snapshot was considered a mistake and caused the snapshot operation to
abort, with a suggestion to snapshot the base table instead.
But an automatic pre-scrub snapshot of a view cannot be attributed to
user error, so the operation should not be aborted in that case.
(It is an open question whether the more correct thing to do during
pre-scrub snapshot would be to silently ignore views. Or perhaps they
should be ignored in all cases except when the user explicitly asks to
snapshot them, by name)
Closes#10760.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
An expr::constant is an expression that happens to represent a constant,
so it's too heavyweight to be used for evaluation. Right now the extra
weight is just a type (which causes extra work by having to maintain
the shared_ptr reference count), but it will grow in the future to include
source location (for error reporting) and maybe other things.
Prior to e9b6171b5 ("Merge 'cql3: expr: unify left-hand-side and
right-hand-side of binary_operator prepares' from Avi Kivity"), we had
to use expr::constant since there was not enough type infomation in
expressions. But now every expression carries its type (in programming
language terms, expressions are now statically typed), so carrying types
in values is not needed.
So change evaluate() to return cql3::raw_value. The majority of the
patch just changes that. The rest deals with some fallout:
- cql3::raw_value gains a view() helper to convert to a raw_value_view,
and is_null_or_unset() to match with expr::constant and reduce further
churn.
- some helpers that worked on expr::constant and now receive a
raw_value now need the type passed via an additional argument. The
type is computed from the expression by the caller.
- many type checks during expression evaluation were dropped. This is
a consequence of static typing - we must trust the expression prepare
phase to perform full type checking since values no longer carry type
information.
Closes#10797
This reverts commit e0670f0bb5, reversing
changes made to 605ee74c39. It causes failures
in debug mode in
database_test.test_database_with_data_in_sstables_is_a_mutation_source_plain,
though with low probability.
Fixes#10780Reopens#652.
active_memtable().empty() becomes true once seal_active_memtable
succeeds with _memtables->add_memtable(), not when it is able
to flush the (once active) memtable.
In contrast, min_memtable_timestamp() returns api::max_timestamp
only if there is no data in any memtable.
Fixes#10793
Backport notes:
- Introduced in f6d9d6175f (currently in
branch-5.0)
- backport requires also 0e78ad50ea
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Closes#10798
and LSIs' from Nadav Har'El
This series includes three small fixes (and of course, tests) for
various edge cases of GSI and LSI handling in Alternator:
1. We add the IndexArn that were missing in DescribeTable for indexes
(GSI and LSI)
2. We forbid the same name to be used for both GSI and LSI (allowing it
was a bug, not a feature)
3. We improve the error handling when trying to tag a GSI or LSI, which
is not currently allowed (it's also not allowed in DynamoDB).
Closes#10791
* github.com:scylladb/scylla:
alternator: improve error handling when trying to tag a GSI or LSI
alternator: forbid duplicate index (LSI and GSI) names
alternator: add ARN for indexes (LSI and GSI)
In issue #10786, we raised the idea of maybe allowing to tag (with
TagResource) GSIs and LSIs, not just base tables. However, currently,
neither DynamoDB nor Syclla allows it. So in this patch we add a
test that confirms this. And while at it, we fix Alternator to
return the same error message as DynamoDB in this case.
Refs #10786.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Adding an LSI and GSI with the same name to the same Alternator table
should be forbidden - because if both exists only one of them (the GSI)
would actually be usable. DynamoDB also forbids such duplicate name.
So in this patch we add a test for this issue, and fix it.
Since the patch involves a few more uses of the IndexName string,
we also clean up its handling a bit, to use std::string_view instead
of the old-style std::string&.
Fixes#10789
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
DynamoDB gives an ARN ("Amazon Resource Name") to LSIs and GSIs. These
look like BASEARN/index/INDEXNAME, where BASEARN is the ARN of the base
table, and INDEXNAME is the name of the LSI or the GSI.
These ARNs should be returned by DescribeTable as part of its
description of each index, and this patch adds that missing IndexArn
field.
The ARN we're adding here is hardly useful (e.g., as explained in
issue #10786, it can't be used to add tags to the index table),
but nevertheless should exist for compatibility with DynamoDB.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Older versions of the Python Cassandra driver had a bug where a single empty
page aborts a scan.
The test test_secondary_index.py::test_filter_and_limit uses filtering and deliberately
tiny pages, so it turns out that some of them are empty, so the test breaks on buggy
versions of the driver, which cause the test to fail when run by developers who happen
to have old versions of the driver.
So in this small series we skip this test when running on a buggy version of the driver.
Fixes#10763Closes#10766
* github.com:scylladb/scylla:
test/cql-pytest: skip another test on older, buggy, drivers
test/cql-pytest: de-duplicate code checking for an old buggy driver
Marking a test as flaky allows to keep running it in CI rather than disable it when it's discovered that a test is flaky.
Flaky tests, if they fail, show up as flaky in the output, but don't fail the CI.
```
kostja@hulk:~/work/scylla/scylla$ ./test.py cdc_with --repeat=30 --verbose
Found 30 tests.
================================================================================
[N/TOTAL] SUITE MODE RESULT TEST
------------------------------------------------------------------------------
[1/30] cql debug [ FLKY ] cdc_with_lwt_test.2 9.36s
[2/30] cql debug [ FLKY ] cdc_with_lwt_test.1 9.53s
[3/30] cql debug [ PASS ] cdc_with_lwt_test.7 9.37s
[4/30] cql debug [ PASS ] cdc_with_lwt_test.8 9.41s
[5/30] cql debug [ PASS ] cdc_with_lwt_test.10 9.76s
[6/30] cql debug [ FLKY ] cdc_with_lwt_test.9 9.71s
```
Closes#10721
* github.com:scylladb/scylla:
test.py: add support for flaky tests
test.py: make Test hierarchy resettable
test.py: proper suite name in the log
test.py: shutdown cassandra-python connection before exit
Use a nice suite name rather than an internal Python
object key in the log. Fixes a regression introduced
when addressing a style-related review remark.
Shutdown cassandra-python connections before exit, to avoid
warnings/exceptions at shutdown.
Cassandra-python runs a thread pool and if
connections are not shut down before exit, there could
be a warning that the thread pool is not destroyed
before exiting main.
Change port type passed to Cassandra Python driver to int to avoid format errors in exceptions.
Manually shutdown connections to avoid reconnects after tests are done (required by upcoming async pytests).
Tests: (dev)
Closes#10722
* github.com:scylladb/scylla:
test.py: shutdown connection manually
test.py: fix port type passed to Cassandra driver
"
This series is a consequence of the work started by:
"compaction: LCS: Fix inefficiency when pushing SSTables to higher levels"
9de7abdc80
"Redefine Compaction Backlog to tame compaction aggressiveness" d8833de3bb
The backlog definition for leveled is incorrectly built on the assumption that
the world must reach the state of zero amplification, i.e. everything in the
last level. The actual goal is space amplification of 1.1.
In reality, LCS just wants that for every level L, level L is fan_out=10 times
larger than L-1. See more in commit 9de7abdc80 which adjusts LCS to conform
to this goal.
If level 3 = 1000G, level 2 = 100G, level 1 = 10G, level 0 = 1G, that should
return zero backlog as space amplification is (1000+100+10+1)/1000 = ~1.1
But today, LCS calculates high backlog for the layout above, as it will only be
satisfied once everything is promoted to the maximum level. That's completely
disconnected from what the strategy actually wants. Therefore, a mismatch.
With today's definition, the backlog for any SSTable is:
sizeof(sstable) * (Lmax - levelof(sstable)) * fan_out
where Lmax = maximum level,
and fan_out = LCS' fan out which is 10 by default
That's essentially calculating the total cost for data in the SSTable to climb
up to the maximum level. Of course, if a SSTable is at the maximum level,
(Lmax - levelof(sstable)) returns zero, therefore backlog for it is zero.
Take a look at this example:
If L0 sstable is 0.16G, then its backlog = 0.16G * (3 - 0) * 10 = 4.8G
0.16G = LCS' default fragment size
Maximum level (Lmax in formula) can be easily 3 as:
log10 of (30G/0.16G=~187 sstables)) = ~2.27
~2.27 means that data has exceeded level 2 capacity and so needs 3 levels.
So 3 L0 sstables could add ~15G of backlog. With 1G memory per shard (30:1 disk
memory ratio), that's normalized backlog of ~15, which translates into
additional ~500 shares. That's halfway to full compaction speed.
With more files in higher levels, we can easily get to a normalized backlog
above 30, resulting in 1k shares.
The suboptimal backlog definition causes either table using LCS or coexisting
tables to run with more shares than needed, causing compaction to steal
resources, resulting in higher latency and reduced throughput.
To solve this problem, a new formula is used which will basically calculate
the amount of work needed to achieve the layout goal. We no longer want to
promote everything to the last level, but instead we'll incrementally calculate
the backlog in each level L, which is the amount of work needed such that the
next level L + 1 is at least fan_out times bigger.
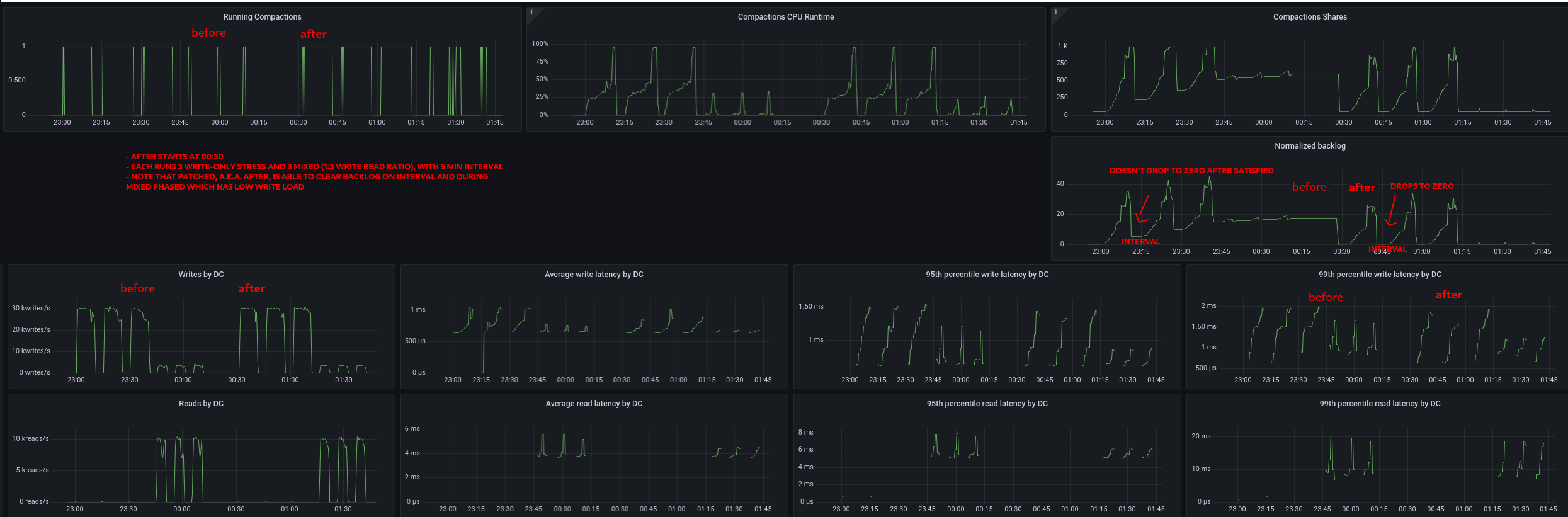
Fixes#10583.
Results
=====
image:
https://user-images.githubusercontent.com/1409139/168713675-d5987d09-7011-417c-9f91-70831c069382.png
The patched version correctly clears the backlog, meaning that once LCS is
satisfied, backlog is 0. Therefore, next compaction either from this table or
another won't run unnecessarily aggressive.
p99 read and write latency have clearly improved. throughput is also more
stable.
"
* 'LCS_backlog_revamp' of https://github.com/raphaelsc/scylla:
tests: sstable_compaction_test: Adjust controller unit test for LCS
compaction: Redefine Leveled compaction backlog
The controller unit test for LCS was only creating level 0 SSTables.
As level 0 falls back to STCS controller, it means that we weren't actually
testing LCS controller.
So let's adjust the unit test to account for LCS fan_out, which is 10
instead of 4, and also allow creation of SSTables on higher levels.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Older versions of the Python Cassandra driver had a bug, detected by
the driver_bug_1 fixture, where a single empty page aborts a scan.
The test test_secondary_index.py::test_filter_and_limit uses filtering
and deliberately tiny pages, so it turns out that some of them are
empty, so the test breaks on buggy versions of the driver, which causes
the test to fail when run by developers who happen to have old versions
of the driver.
So in this patch we use the driver_bug_1 fixture, to skip this test
when running on a buggy version of the driver.
Fixes#10763
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
{kind=link}