In preparation of the relaxation of the grammar to return any expression,
change the whereClause production to return an expression rather than
terms. Note that the expression is still constrained to be a conjunction
of relations, and our filtering code isn't prepared for more.
Before the patch, if the WHERE clause was optional, the grammar would
pass an empty vector of expressions (which is exactly correct). After
the patch, it would pass a default-constructed expression. Now that
happens to be an empty conjunction, which is exactly what's needed, but
it is too accidental, so the patch changes optional WHERE clauses to
explicitly generate an empty conjunction if the WHERE clause wasn't
specified.
Move closer to the goal of accepting a generic expression for WHERE
clause by accepting a generic expression in statement_restrictions. The
various callers will synthesize it from a vector of terms.
std::move(_where_clause) is wrong, because _where_clause is used later
(when analyzing GROUP BY), but also harmless (because the
statement_restrictions constructor accepts it by const reference).
To avoid confusion in the next patch where we'll pass _where_clause
to a different function, remove the bad std::move() in advance here.
This PR removes all code that used classes `restriction`, `restrictions` and their children.
There were two fields in `statement_restrictions` that needed to be dealt with: `_clustering_columns_restrictions` and `_nonprimary_key_restrictions`.
Each function was reimplemented to operate on the new expression representaiion and eventually these fields weren't needed anymore.
After that the restriction classes weren't used anymore and could be deleted as well.
Now all of the code responsible for analyzing WHERE clause and planning a query works on expressions.
Closes#11069
* github.com:scylladb/scylla:
cql3: Remove all remaining restrictions code
cql3: Move a function from restrictions class to the test
cql3: Remove initial_key_restrictions
cql3: expr: Remove convert_to_restriction
cql3: Remove _new from _new_nonprimary_key_restrictions
cql3: Remove _nonprimary_key_restrictions field
cql3: Reimplement uses of _nonprimary_key_restrictions using expression
cql3: Keep a map of single column nonprimary key restrictions
cql3: Remove _new from _new_clustering_columns_restrictions
cql3: Remove _clustering_columns_restrictions from statement_restrictions
cql3: Use a variable instead of dynamic cast
cql3: Use the new map of single column clustering restrictions
cql3: Keep a map of single column clustering key restrictions
cql3: Return an expression in get_clustering_columns_restrctions()
cql3: Reimplement _clustering_columns_restrictions->has_supporting_index()
cql3: Don't create single element conjunction
cql3: Add expr::index_supports_some_column
cql3: Reimplement has_unrestricted_components()
cql3: Reimplement _clustering_columns_restrictions->need_filtering()
cql3: Reimplement num_prefix_columns_that_need_not_be_filtered
cql3: Use the new clustering restrictions field instead of ->expression
cql3: Reimplement _clustering_columns_restrictions->size() using expressions
cql3: Reimplement _clustering_columns_restrictions->get_column_defs() using expressions
cql3: Reimplement _clustering_columns_restrictions->is_all_eq() using expressions
cql3: expr: Add has_only_eq_binops function
cql3: Reimplement _clustering_columns_restrictions->empty() using expressions
query_result was the wrong place to put last position into. It is only
included in data-responses, but not on digest-responses. If we want to
support empty pages from replicas, both data and digest responses have
to include the last position. So hoist up the last position to the
parent structure: query::result. This is a breaking change inter-node
ABI wise, but it is fine: the current code wasn't released yet.
Closes#11072
The classes restriction, restrictions and its children
aren't used anywhere now and can be safely removed.
Some includes need to be modified for the code to compile.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
All parts of the code that use _nonprimary_key_restrictions
are changed to use _new_nonprimary_key_restrictions instead.
I decided not to split this into multiple commits,
as there isn't a lot of changes and they are
analogous to the ones done before for partition
and clustering columns.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
get_clustering_columns_restrctions() used to return
a shared pointer to the clustering_restrictions class.
Now everything is being converted to expression,
so it should return an expression as well.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Enables parallelization of query like `SELECT MIN(x), MAX(x)`.
Compatibility is ensured under the same cluster feature as
UDA and native aggregates parallelization. (UDA_NATIVE_PARALLELIZED_AGGREGATION)
Enables parallelization of UDA and native aggregates. The way the
query is parallelized is the same as in #9209. Separate reduction
type for `COUNT(*)` is left for compatibility reason.
Moving `function`, `function_name` and `aggregate_function` into
db namespace to avoid including cql3 namespace into query-request.
For now, only minimal subset of cql3 function was moved to db.
Convert most use sites from `co_return coroutine::make_exception`
to `co_await coroutine::return_exception{,_ptr}` where possible.
In cases this is done in a catch clause, convert to
`co_return coroutine::exception`, generating an exception_ptr
if needed.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Closes#10972
This PR removes some restrictions classes and replaces them with expression.
* `single_column_restriction` has been removed altogether.
* `partition_key_restrictions` field inside `statement_restrictions` has been replaced with `expression`
`clustering_key_restrictions` are not replaced yet, but this PR already has 30 commits so it's probably better to merge this before adding any more changes.
Luckily most of these commits are implementations of small helper functions.
`single_column_restriction` was pretty easy to remove. This class holds the `expression` that describes the restriction and `column_definition` of the restricted column.
It inherits from `restriction` - the base class of all restrictions.
I wasn't able to replace it with plain `expression` just yet, because a lot of times a `shared_ptr<single_column_restriction>` is being cast to `shared_ptr<restriction>`.
Instead I replaced all instances of `single_column_restriction` with `restriction`.
To decide if a `restriction` is a `single_column_restriction` we can use a helper method that works on expressions.
Same with acquiring the restricted `column_definition`.
This change has two advantages:
* One less restriction class -> moving towards 0
* Preparing towards one generic `restriction/expression` type and using functions to distinguish the type of expression that we're dealing with.
`partition_key_restrictions` is a class used to keep restrictions on the partition key inside `statement_restrictions`.
Removing it required two major steps.
First I had to implement taking all the binary operators and making sure that they are valid together.
Before the change this was the `merge_to` method. It ensures that for example there are no token and regular restrictions occurring at the same time.
This has been implemented as `statement_restrictions::add_restriction`.
It detects which case it's dealing with and mimics `merge_to` from the right restrictions class.
Then I implemented all methods of `partition_key_restrictions` but operating on plain `expressions`.
While doing that I was able to gradually shift the responsibility to the brand new functions.
Finally `partition_key_restrictions` wasn't used anywhere at all and I was able to remove it.
Here's the inheritance tree of all restriction classes for context:
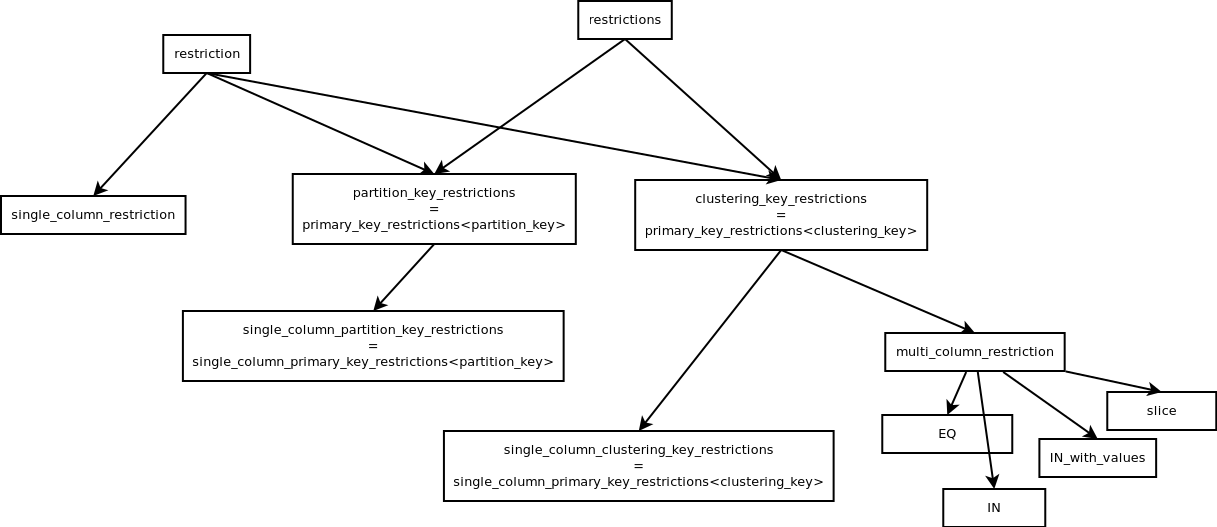
For now this is marked as a draft.
I just put all this together in a readable way and wanted to put it out for you to see.
I will have another look at the code and maybe do some improvements.
Closes#10910
* github.com:scylladb/scylla:
cql3: Remove _new from _new_partition_key_restrictions
cql3: Remove _partition_key_restrictions from statement_restrictions
cql3: Use expression for index restrictions
cql3: expr: Add contains_multi_column_restriction
cql3: Add expr::value_for
cql3: Use the new restrictions map in another place
cql3: use the new map in get_single_column_partition_key_restrictions
cql3: Keep single column restrictions map inside statement restrictions
cql3: Use expression instead of _partition_key_restrictions in the remaining code
cql3: Replace partition_key_restrictions->has_supporting_index()
cql3: Replace statement_restrictions->get_column_defs()
cql3: Replace partition_key_restrictions->needs_filtering()
cql3: Replace partition_key_restrictions->size()
cql3: Replace partition_key_restrictions->is_all_eq()
cql3: Replace parition_key_restriction->has_unrestricted_components()
cql3: Replace parition_key_restrictions->empty()
cql3: Keep restrictions as expressions inside statement_restrictions
cql3: Handle single value INs inside prepare_binary_operator
cql3: Add get_columns_in_commons
cql3: expr: Add is_empty_restriction
cql3: Replicate column sorting functionality using expressions
cql3: Remove single_column_restriction class
cql3: Replace uses of single_column_restriction with restriction
cql3: expr: Add get_the_only_column
cql3: expr: Add is_single_column_restriction
cql3: expr: Add for_each_expression
cql3: Remove some unsued methods
Restrictions that might be used by an index
are currently being kept as shared_ptr<restrictions>.
This stand in the way of replacing _parition_key_restrictions
with an expression as an expression can't be cast to
shared_ptr<restriction>.
Change shared_ptr<restriction> to expression everywhere
where necessary in index operations.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
There are still some places that use partition_key_restrictions
instead of _new_partition_key_restrictions in statement_restrictions.
Change them to use the new representation
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
To remove partition_key_restrictions all of its
methods have to be implemented using the new expression
representation.
The first to go is empty() as it's easy to implement.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Now that all uses of this class have been
replaced by the generic restriction
the class is not used anywhere and can be removed.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
The commits here were extracted from PR https://github.com/scylladb/scylla/pull/10835 which implements upgrade procedure for Raft group 0.
They are mostly refactors which don't affect the behavior of the system, except one: the commit 4d439a16b3 causes all schema changes to be bounced to shard 0. Previously, they would only be bounced when the local Raft feature was enabled. I do that because:
1. eventually, we want this to be the default behavior
2. in the upgrade PR I remove the `is_raft_enabled()` function - the function was basically created with the mindset "Raft is either enabled or not" - which was right when we didn't support upgrade, but will be incorrect when we introduce intermediate states (when we upgrade from non-raft-based to raft-based operations); the upgrade PR introduces another mechanism to dispatch based on the upgrade state, but for the case of bouncing to shard 0, dispatching is simply not necessary.
Closes#10864
* github.com:scylladb/scylla:
service/raft: raft_group_registry: add assertions when fetching servers for groups
service/raft: raft_group_registry: remove `_raft_support_listener`
service/raft: raft_group0: log adding/removing servers to/from group 0 RPC map
service/raft: raft_group0: move group 0 RPC handlers from `storage_service`
service/raft: messaging: extract raft_addr/inet_addr conversion functions
service: storage_service: initialize `raft_group0` in `main` and pass a reference to `join_cluster`
treewide: remove unnecessary `migration_manager::is_raft_enabled()` calls
test/boost: memtable_test: perform schema operations on shard 0
test/boost: cdc_test: remove test_cdc_across_shards
message: rename `send_message_abortable` to `send_message_cancellable`
message: change parameter order in `send_message_oneway_timeout`
Currently, we use the last row in the query result set as the position where the query is continued from on the next page. Since only live rows make it into query result set, this mandates the query to be stopped on a live row on the replica, lest any dead rows or tombstones processed after the live rows, would have to be re-processed on the next page (and the saved reader would have to be thrown away due to position mismatch). This requirement of having to stop on a live row is problematic with datasets which have lots of dead rows or tombstones, especially if these form a prefix. In the extreme case, a query can time out before it can process a single live row and the data-set becomes effectively unreadable until compaction gets rid of the tombstones.
This series prepares the way for the solution: it allows the replica to determine what position the query should continue from on the next page. This position can be that of a dead row, if the query stopped on a dead row. For now, the replica supplies the same position that would have been obtained with looking at the last row in the result set, this series merely introduces the infrastructure for transferring a position together with the query result, and it prepares the paging logic to make use of this position. If the coordinator is not prepared for the new field, it will simply fall-back to the old way of looking at the last row in the result set. As I said for now this is still the same as the content of the new field so there is no problem in mixed clusters.
Refs: https://github.com/scylladb/scylla/issues/3672
Refs: https://github.com/scylladb/scylla/issues/7689
Refs: https://github.com/scylladb/scylla/issues/7933
Tests: manual upgrade test.
I wrote a data set with:
```
./scylla-bench -mode=write -workload=sequential -replication-factor=3 -nodes 127.0.0.1,127.0.0.2,127.0.0.3 -clustering-row-count=10000 -clustering-row-size=8096 -partition-count=1000
```
This creates large, 80MB partitions, which should fill many pages if read in full. Then I started a read workload:
```
./scylla-bench -mode=read -workload=uniform -replication-factor=3 -nodes 127.0.0.1,127.0.0.2,127.0.0.3 -clustering-row-count=10000 -duration=10m -rows-per-request=9000 -page-size=100
```
I confirmed that paging is happening as expected, then upgraded the nodes one-by-one to this PR (while the read-load was ongoing). I observed no read errors or any other errors in the logs.
Closes#10829
* github.com:scylladb/scylla:
query: have replica provide the last position
idl/query: add last_position to query_result
mutlishard_mutation_query: propagate compaction state to result builder
multishard_mutation_query: defer creating result builder until needed
querier: use full_position instead of ad-hoc struct
querier: rely on compactor for position tracking
mutation_compactor: add current_full_position() convenience accessor
mutation_compactor: s/_last_clustering_pos/_last_pos/
mutation_compactor: add state accessor to compact_mutation
introduce full_position
idl: move position_in_partition into own header
service/paging: use position_in_partition instead of clustering_key for last row
alternator/serialization: extract value object parsing logic
service/pagers/query_pagers.cc: fix indentation
position_in_partition: add to_string(partition_region) and parse_partition_region()
mutation_fragment.hh: move operator<<(partition_region) to position_in_partition.hh
Static columns are not currently allowed in a materialized view. If the
base table has a static column and one tries to create a view with a
"SELECT *", the following error message is printed today:
Unable to include static column 'ColumnDefinition{name=s,
type=org.apache.cassandra.db.marshal.Int32Type, kind=STATIC,
componentIndex=null, droppedAt=-9223372036854775808}' which would
be included by Materialized View SELECT * statement
It is completely unnecessary to include all these details about the
column definition - just its name would have sufficed. In other words,
we should print def.name_as_text(), not the entire def. This is what
other error messages in the same file do as well.
After this patch the error message becomes nicer and clearer:
Unable to include static column 's' which would be included by
Materialized View SELECT * statement
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10854
In schema_altering_statement: we will bounce statements to shard 0
whether Raft is enabled or not.
In migration_manager, when we're sending a group 0 snapshot: well, if
we're sending a group 0 snapshot, Raft must be enabled; the check is
redundant.
Use the recently introduced query-result facility to have the replica
set the position where the query should continue from. For now this is
the same as what the implicit position would have been previously (last
row in result), but it opens up the possibility to stop the query at a
dead row.
The per-partition rate limit feature requires all nodes in the cluster
to support it in order to work well. This commit adds a check which
disallows creating/altering tables with per-partition rate limit until
the node is sure that all nodes in the cluster support it.
Now, mutate/mutate_result accept a flag which decides whether the write
should be rate limited or not.
The new parameter is mandatory and all call sites were updated.
The grammar now checks that UPDATEs don't clash (for example,
updates to the same column). The checks are good, but the grammar
isn't the right place for them - better to concentrate all the checks
in the prepare() code so it's easy to see all the checks.
Move the checks to raw::update_statement::prepare_internal(). This
exposes that the checks are quadratic, so add a comment. It could be
fixed with a stable_sort() first, but that is left to later.
Closes#10820
When evaluating an LWT condition involving both static and non-static
cells, and matching no regular row, the static row must be used UNLESS
the IF condition is IF EXISTS/IF NOT EXISTS, in which case special rules
apply.
Before this fix, Scylla used to assume a row doesn't exist if there is
no matching primary key. In Cassandra, if there is a
non-empty static row in the partition, a regular row based
on the static row' cell values is created in this case, and then this
row is used to evaluate the condition.
This problem was reported as gh-10081.
The reason for Scylla behaviour before the patch was that when
implementing LWT I tried to converge Cassandra data model (or lack of
thereof) with a relational data model, and assumed a static row is a
"shared" portion of a regular row, i.e. a storage level concept intended
to save space, and doesn't have independent existence.
This was an oversimplification.
This patch fixes gh-10081, making Scylla semantics match the one of
Cassandra.
I will now list other known examples when a static row has an own
independent existence as part of a table, for cataloguing purposes.
SELECT * from a partition which has a partition key
and a static cell set returns 1 row. If later a regular row is added
to the partition, the SELECT would still return 1 row, i.e.
the static row will disappear, and a regular row will appear instead.
Another example showing a static row has an independent existence below:
CREATE TABLE t (p int, c int, s int static, PRIMARY KEY(p, c));
INSERT INTO t (p, c) VALUES(1, 1);
INSERT INTO t (p, s) VALUES(1, 1) IF NOT EXISTS;
In Cassandra (and Scylla), IF NOT EXISTS evaluates to TRUE, even though both
the regular row and the partition exist. But the static cells are not
set, and the insert only provides a partition key, so the database assumes the
insert is operating against a static row.
It would be wrong to assume that a static row exists when the partition
key exists:
INSERT INTO t (p, c, s) VALUES(1, 1, 1) IF NOT EXISTS;
[applied] | p | c | s
-----------+---+---+------
False | 1 | 1 | null
evaluates to False, i.e. the regular row does exist when p and c exist.
Issue
CREATE TABLE t (p INT, c INT, r INT, s INT static, PRIMARY KEY(p, c))
INSERT INTO t (p, s) VALUES (1, 1);
UPDATE t SET s=2, r=1 WHERE p=1 AND c=1 IF s=1 and r=null;
- in this case, even though the regular row doesn't exist, the static
row does, and should be used for condition evaluation.
In other words, IF EXISTS/IF NOT EXISTS have contextual semantics.
They apply to the regular row if clustering key is used in the WHERE
clause, otherwise they apply to static row.
One analogy for static rows is that it is like a static member of C++ or
Java class. It's an attribute of the class (assuming class = partition),
which is accessible through every object of the class (object = regular
row). It is also present if there are no objects of the class, but the
class itself exists: i.e. a partition could have no regular rows, but
some static cells set, in this case it has a static row.
*Unlike C++/Java static class members* a static row is an optional
attribute of the partition. A partition may exist, but the static row
may be absent (e.g. no static cell is set). If the static row does exist,
all regular rows share its contents, *even if they do not exist*.
A regular row exists when its clustering key is present
in the table. A static row exists when at least one static cell is set.
Tests are updated because now when no matching row is found
for the update we show the value of the static row as the previous
value, instead of a non-matching clustering row.
Changes in v2:
- reworded the commit message
- added select tests
Closes#10711
An expr::constant is an expression that happens to represent a constant,
so it's too heavyweight to be used for evaluation. Right now the extra
weight is just a type (which causes extra work by having to maintain
the shared_ptr reference count), but it will grow in the future to include
source location (for error reporting) and maybe other things.
Prior to e9b6171b5 ("Merge 'cql3: expr: unify left-hand-side and
right-hand-side of binary_operator prepares' from Avi Kivity"), we had
to use expr::constant since there was not enough type infomation in
expressions. But now every expression carries its type (in programming
language terms, expressions are now statically typed), so carrying types
in values is not needed.
So change evaluate() to return cql3::raw_value. The majority of the
patch just changes that. The rest deals with some fallout:
- cql3::raw_value gains a view() helper to convert to a raw_value_view,
and is_null_or_unset() to match with expr::constant and reduce further
churn.
- some helpers that worked on expr::constant and now receive a
raw_value now need the type passed via an additional argument. The
type is computed from the expression by the caller.
- many type checks during expression evaluation were dropped. This is
a consequence of static typing - we must trust the expression prepare
phase to perform full type checking since values no longer carry type
information.
Closes#10797
Currently, preparing the left-hand-side of a binary operator and the
right-hand-side use different code paths. The left-hand-side derives
the type of the expression from the expression itself, while the
right-hand-side imposes the type on the expression (allowing the types
of bind variables to be inferred).
This series unifies the two, by making the imposed type (the "receiver")
optional, and by allowing prepare to fail gracefully if we were not able
to infer the type. The old prepare_binop_lhs() is removed and replaced
with prepare_expression, already used for the right hand side.
There is one step remaining, and that is to replace prepare_binary_operator
with prepare_expression, but that is more involved and is left for a follow-up.
Closes#10709
* github.com:scylladb/scylla:
cql3: expr: drop prepare_binop_lhs()
cql3: expr: move implementation of prepare_binop_lhs() to try_prepare_expression()
cql3: expr: use recursive descent when preparing subscripts
cql3: expr: allow prepare of tuple_constructor with no receiver
cql3: expr: drop no longer used printable_relation parameter from prepare_binop_lhs()
cql3: expr: print only column name when failing to resolve column
cql3: expr: pass schema to prepare_expression
cql3: expr: prepare_binary_operator: drop unused argument ctx
cql3: expr: stub type inference for prepare_expression
cql3: expr: introduce type_of() to fetch the type of an expression
cql3: expr: keep type information in casts
cql3: expr: add type field to subscript, field_selection, and null expressions
cql3: expr: cast: use data_type instead of cql3_type for the prepared form
Currently prepare_expression is never used where a schema is needed -
it is called for the right-hand-side of binary operators (where we
don't accept columns) or for attributes like WRITETIME or TTL. But
when we unify expression preparation it will need to handle columns
too, and these need the schema to look up the column.
So pass the schema as a parameter. It is optional (a pointer) since
not all contexts will have a schema (for example CREATE AGGREGATE).
In order to expose the API for deleting ghost rows from a view,
a CQL statement is created. It is loosely based on select_statement,
as its first step is to select view table rows.
Right now is_json is used to decide if the statement needs to be treated
in a special way. For two types (regular statement and JSON statement),
a boolean is enough, but this series extends it for two more types,
so the flag is converted to an enum.
Functionality of the relation class has been replaced by
expr::to_restriction.
Relation and all classes deriving from it can now be removed.
Signed-off-by: cvybhu <jan.ciolek@scylladb.com>
Parser used to output the where clause as a vector of relations,
but now we can change it to a vector of expressions.
Cql.g needs to be modified to output expressions instead
of relations.
The WHERE clause is kept in a few places in the code that
need to be changed to vector<expression>.
Finally relation->to_restriction is replaced by expr::to_restriction
and the expressions are converted to restrictions where required.
The relation class isn't used anywhere now and can be removed.
Signed-off-by: cvybhu <jan.ciolek@scylladb.com>
After fcb8d040 ("treewide: use Software Package Data Exchange
(SPDX) license identifiers"), many dual-licensed files were
left with empty comments on top. Remove them to avoid visual
noise.
Closes#10562
Each feature has a private variable and a public accessor. Since the
accessor effectively makes the variable public, avoid the intermediary
and make the variable public directly.
To ease mechanical translation, the variable name is chosen as
the function name (without the cluster_supports_ prefix).
References throughout the codebase are adjusted.
The STORAGE option is designed to hold a map of options
used for customizing storage for given keyspace.
The option is kept in a system_schema.scylla_keyspaces table.
The option is only available if the whole cluster is aware
of it - guarded by a cluster feature.
Example of the table contents:
```
cassandra@cqlsh> select * from system_schema.scylla_keyspaces;
keyspace_name | storage_options | storage_type
---------------+------------------------------------------------+--------------
ksx | {'bucket': '/tmp/xx', 'endpoint': 'localhost'} | S3
```
Makes final function and initial condition to be optional while
creating UDA. No final function means UDA returns final state
and defeult initial condition is `null`.
Fixes: #10324
The error message incorrectly stated that the timeout value cannot
be longer than 24h, but it can - the actual restriction is that the
value cannot be expressed in units like days or months, which was done
in order to significantly simplify the parsing routines (and the fact
that timeouts counted in days are not expected to be common).
Fixes#10286Closes#10294
"
By way of having an implementation of `data_dictionary` and using that.
The schema loader only needs a database to parse cql3 statements, which
are all coordinator-side objects and hence been largely migrated to use
data dictionary instead.
A few hard-dependencies on replica:: objects were found and resolved:
* index::secondary_index_manager
* tombstone_gc
The former was migrated to use `data_dictionary::table` instead of
`replica::table`. This in turn requires disentangling
`replica::data_dictionary_impl` from `replica::database`, as currently
the former can only really be used by the latter.
What all of this achieves us is that we no longer have to instantiate a
`replica::database` object in `tools::load_schema()`. We want to use the
standard allocator in tools, which means they cannot use LSA memory at
all. Database on the other hand creates memtable and row-cache instances
so it had to go.
Refs: #9882
Tests: unit(dev, schema_loader_test:debug,
cql-pytest/test_tools.py:debug)
"
* 'tools-schema-loader-database-impl/v2' of https://github.com/denesb/scylla:
tools/schema_loader: use own data dictionary impl
tombstone_gc: switch to using data dictionary
index/secondary_index_manager: switch to using data dictionary
replica/table: add as_data_dictionary()
replica: disentangle data_dictionary_impl from database
replica: move data_dictionary_impl into own header
But only on the surface, the only internal function needing the database
(`needs_repair_before_gc()`) still gets a real database because the
replication factor cannot be obtained from the data dictionary
currently. Although this might not look like an improvement, it is
enough to avoid a `real_database()` call for tables that don't have
tombstone gc mode set to repair.
{kind=link}