If exception is caught while updating backlog tracker, the backlog
tracker will be disabled for the underlying table, potentially
causing compaction to fall behind.
That being said, let's raise the log level to error, to give it
its due importance and allow tests to detect the problem.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220330151421.49054-1-raphaelsc@scylladb.com>
"
Quoting patch 3/4:
"This continues the work in a69d98c3d0,
by implementing the cleanup method in TWCS to make it bucket aware.
Till now, the default impl was used which cleanups on file at a
time, starting from the smallest.
The cleanup strategy for TWCS is simple. It's simply calling the
size tiered cleanup method for each bucket, so there will be
one job for each tier in each window.
The next strategies to receive this improvement are LCS and ICS
(the latter one being only available in enterprise).
Refs #10097."
** Simply put, the goal is to reduce writeamp when performing cleanup
on a TWCS table, therefore reducing the operation time. **
tests: unit(dev).
"
* 'twcs_cleanup_bucket_aware/v1' of https://github.com/raphaelsc/scylla:
tests: sstable_compaction_test: Add test for TWCS' bucket-aware cleanup
compaction: TWCS: Implement cleanup method for bucket awareness
compaction: TWCS: change get_buckets() signature to work with const qualified functions
compaction_strategy: get_cleanup_compaction_jobs: accept candidates by value
Then caller can decide whether to copy or move candidate set into the
function. cleanup_sstables_compaction_task can move candidates as
it's no longer needed once it retrieves all descriptors.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
As the cleanup process can now be driven by the compaction strategy,
let's move cleanup into a new task type that uses the new
compaction_strategy::get_cleanup_compaction_jobs().
By the time being all strategies are using the default method that
returns one descriptor for each sstable that needs clean up.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
For compaction to be able to purge expired data, like tombstones, a
sstable set snapshot is set in the compaction descriptor.
That's a decision that belongs to task type. For example, all regular
compaction enable GC, whereas scrub for example doesn't for safety
reasons.
The problem is that the decision is being made by every instantiation
of compaction_descriptor in the strategies, which is both unnecessary
and also adds lots of boilerplate to the code, making it hard to
understand and work with.
As sstable set snapshot is an implementation detail, a new method
is being added to compaction_descriptor to make the intention
clearer, making the interface easier to understand.
can_purge_tombstones, used previously by rewrite task only, is being
reused for communicating GC intention into task::compact_sstables().
The boilerplate was a pain when adding a new strategy method for
the ongoing work on cleanup, described by issue #10097.
Another benefit is that we'll now only create a set snapshot when
compaction will really run. Before, it could happen that the snapshot
would be discarded if the compaction attempt had to be postponed,
which is a waste of cpu cycles.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Flushing the base table triggers view building
and corresponding compactions on the view tables.
Temporarily disable compaction on both the base
table and all its view before flush and snapshot
since those flushed sstables are about to be truncated
anyway right after the snapshot is taken.
This should make truncate go faster.
In the process, this series also embeds `database::truncate_views`
into `truncate` and coroutinizes both
Refs #6309
Test: unit(dev)
Closes#10203
* github.com:scylladb/scylla:
replica/database: truncate: fixup indentation
replica/database: truncate: temporarily disable compaction on table and views before flush
replica/database: truncate: coroutinize per-view logic
replica/database: open-code truncate_view in truncate
replica/database: truncate: coroutinize run_with_compaction_disabled lambda
replica/database: coroutinize truncate
compaction_manager: add disable_compaction method
The atomicity was lost in commit a2a5e530f0.
Registration of compacting SSTables now happens in rewrite_sstables_compaction_task
ctor, but that's risky because a regular compaction could pick those
same files if run_with_compaction_disabled() defers after the callback
passed to it returns, and before run__w__c__d() caller has a chance to
run. The deferring point is very much possible, because submit()
(submits a regular job) is called when run__w__c__d() reenables compaction
internally.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220315182857.121479-1-raphaelsc@scylladb.com>
Compaction manager is calling back the table to run off-strategy compaction,
but the logic clearly belongs to manager which should perform the
operation independently and only call table to update its state with the
result.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220315174504.107926-2-raphaelsc@scylladb.com>
Returns a RAII class compaction_reenabler
that conditionally reenables compaction
for the given table when destroyed.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
With compact_sstables() now living in compaction_manager::task,
release_exhausted no longer has to live inside compaction_descriptor,
which is a good direction because implementation detail is being
removed from the interface.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220311023410.250149-2-raphaelsc@scylladb.com>
Table submits compaction request into manager, which in turn calls
back table to run the compaction when the time has come, i.e.:
table -> compaction manager -> table -> execute compaction
But manager should not rely on table to run compaction, as compaction
execution procedure sits one layer below the manager and should be
accessed directly by it, i.e:
table -> compaction manager -> execute compaction
This makes code easier to understand and update_compaction_history()
can now be noop for unit tests using table_state.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220311023410.250149-1-raphaelsc@scylladb.com>
Saving an allocation for running the functor
as a task in the switched-to scheduling group.
Also, switch to the desired scheduling group at
the beginning of the task so that the higher level logic,
like getting the list of sstables to compact
will be performed under the desired scheduling group,
not only the compaction code itself.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Replace the _compaction_running boolean member
by calculating _state == state::active
now that setup_new_compaction switches state to
`active`
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Move the business logic into the task specific classes.
Separating initialization during task construction,
from the compaction_done task, moved into
a do_run() method, and in some cases moving
a lambda function that was called per table (as in
rewrite_sstables) into a private method of the
derived class.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Add an enum class representing the task state machine
and a switch_state function to transition between the states
and update the corresponding compaction_manager stats counters.
Refs #9974
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Define task::describe and use it via operator<<
to print the task metadata to the log in a standard way.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Move the task-internal parts of can_proceed
to a respective compaction_manager::task method,
preparing for turning it into a class with
a proper hierarchy of access to private members.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
And use it to get the compaction state of the
table to compact.
It will be used in a later patch
to manage the task state from task
methods.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Like all other maintenance operations, acquire the _maintenance_ops_sem
once for the whole task, rather than for each sstable.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Maintenance operations like cleanup, upgrade, reshape, and reshard
are serialized serialized with major compaction using the _maintenance_ops_sem
and they need no further synchronization with regular compaction
by acquiring the per-table read lock..
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Since regular compaction may run in parallel no lock
is required per-table.
We still acquire a read lock in this patch, for backporting
purposes, in case the branch doesn't contain
6737c88045.
But it can be removed entirely in master in a follow-up patch.
This should solve some of the slowness in cleanup compaction (and
likely in upgrade sstables seen in #10060, and
possibly #10166.
Fixes#10175
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Closes#10177
Simplify the function by implementing it as a coroutine,
ensuring the input vector, holding the shared task ptrs, is
kept alive throughout the lifetime of the function
(instead of using do_with to achieve that)
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220302081547.2205813-2-bhalevy@scylladb.com>
task_stop is called exclusively from stop_tasks,
Now that stop_tasks calls task::stop() directly,
there is no need for this separation, so open-code
task_stop in stop_tasks, using coroutines.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220302081547.2205813-1-bhalevy@scylladb.com>
It was assumed that offstrategy compaction is always triggered by streaming/repair
where it would inherit the caller's scheduling group.
However, offstrategy is triggered by a timer via table::_off_strategy_trigger so I don't see
how the expiration of this timer will inherit anything from streaming/repair.
Also, since d309a86, offstrategy compaction
may be triggered by the api where it will run in the default scheduling group.
The bottom line is that the compaction manager needs to explicitly perform offstrategy compaction
in the maintenance scheduling group similar to `perform_sstable_scrub_validate_mode`.
Fixes#10151
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220302084821.2239706-1-bhalevy@scylladb.com>
Currently the output_run_identifier is assigned right
after the calling setup_new_compaction.
Move setting the uuid to setup_new_compaction to simplify
the flow.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220301083643.1845096-1-bhalevy@scylladb.com>
Instead, rely solely on compaction_data.abort source
that is task::stop now uses to stop the task.
This makes task stopping permanent, so it can't be undone
(as used to be the case where task_stop
set stopping to false after waiting for compaction_done,
to allow rerite_sstables's task to be created before
calling run_with_compaction_disabled, and start
running after it - which is no longer the case)
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220301083535.1844829-1-bhalevy@scylladb.com>
Currently, rewrite_sstables retrieved the sstables under
run_with_compaction_disabled, *after* it's created a task for itself.
This makes little sense as this task have not started running yet
and therefore does not need to be stopped by
run_with_compaction_disabled.
This is currently worked around by setting task->stopping = false
in task_stop().
This change just moves task create in rewrite_sstables till
after the sstables are retrieved and the deferred cleanup
of _stats.pending_tasks till after it's first adjusted.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220301083409.1844500-1-bhalevy@scylladb.com>
Rather than using a std::optional<compacting_sstable_registration>
for lazy construction, construct the object early
and call register_compacting when the sstables to register
are available.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Rather than a compaction_manager* so that in the next
patch it could be constructed with just that and
the caller can call register_compacting when
it has the sstables to register ready.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
"
Problem statement
=================
Today, compaction can act much more aggressive than it really has to, because
the strategy and its definition of backlog are completely decoupled.
The backlog definition for size-tiered, which is inherited by all
strategies (e.g.: LCS L0, TWCS' windows), is built on the assumption that the
world must reach the state of zero amplification. But that's unrealistic and
goes against the intent amplification defined by the compaction strategy.
For example, size tiered is a write oriented strategy which allows for extra
space amplification for compaction to keep up with the high write rate.
It can be seen today, in many deployments, that compaction shares is either
close to 1000, or even stuck at 1000, even though there's nothing to be done,
i.e. the compaction strategy is completely satisfied.
When there's a single sstable per tier, for example.
This means that whenever a new compaction job kicks in, it will act much more
aggressive because of the high shares, caused by false backlog of the existing
tables. This translates into higher P99 latencies and reduced throughput.
Solution
========
This problem can be fixed, as proposed in the document "Fixing compaction
aggressiveness due to suboptimal definition of zero backlog by controller" [1],
by removing backlog of tiers that don't have to be compacted now, like a tier
that has a single file. That's about coupling the strategy goal with the
backlog definition. So once strategy becomes satisfied, so will the controller.
Low-efficiency compaction, like compacting 2 files only or cross-tier, only
happens when system is under little load and can proceed at a slower pace.
Once efficient jobs show up, ongoing compactions, even if inefficient, will get
more shares (as efficient jobs add to the backlog) so compaction won't fall
behind.
With this approach, throughput and latency is improved as cpu time is no longer
stolen (unnecessarily) from the foreground requests.
[1]: https://docs.google.com/document/d/1EQnXXGWg6z7VAwI4u8AaUX1vFduClaf6WOMt2wem5oQ
Results
=======
Test sequentially populates 3 tables and then run a mixed workload on them,
where disk:memory ratio (usage) reaches ~30:1 at the peak.
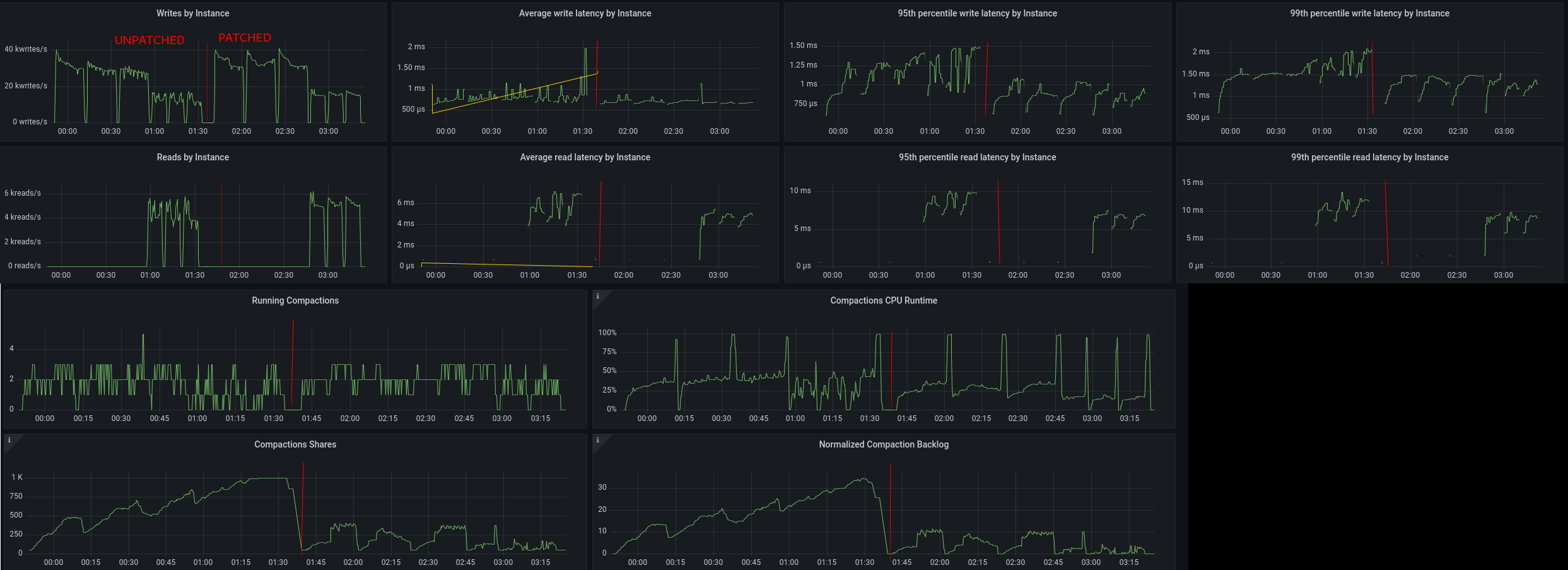
Please find graphs here:
https://user-images.githubusercontent.com/1409139/153687219-32368a35-ac63-461b-a362-64dbe8449a00.png
1) Patched version started at ~01:30
2) On population phase, throughput increase and lower P99 write latency can be
clearly observed.
3) On mixed phase, throughput increase and lower P99 write and read latency can
also be clearly observed.
4) Compaction CPU time sometimes reach ~100% because of the delay between each
loader.
5) On unpatched version, it can be seen that backlog keeps growing even when
though strategies become satisfied, so compaction is using much more CPU time
in comparison. Patched version correctly clears the backlog.
Can also be found at:
github.com/raphaelsc/scylla.git compaction-controller-v5
tests: UNIT(dev, debug).
"
* 'compaction-controller-v5' of https://github.com/raphaelsc/scylla:
tests: Add compaction controller test
test/lib/sstable_utils: Set bytes_on_disk for fake SSTables
compaction/size_tiered_backlog_tracker.hh: Use unsigned type for inflight component
compaction: Redefine compaction backlog to tame compaction aggressiveness
compaction_backlog_tracker: Batch changes through a new replacement interface
table: Disable backlog tracker when stopping table
compaction_backlog_tracker: make disable() public
compaction_backlog_tracker: Clear tracker state when disabled
compaction: Add normalized backlog metric
compaction: make size_tiered_compaction_strategy static
This new interface allows table to communicate multiple changes in the
SSTable set with a single call, which is useful on compaction completion
for example.
With this new interface, the size tiered backlog tracker will be able to
know when compaction completed, which will allow it to recompute tiers
and their backlog contribution, if any. Without it, tiered tracker
would have to recompute tiers for every change, which would be terribly
expensive.
The old remove/add interface are being removed in favor of the new one.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
If the tracker is disabled, we never get to access the underlying
implementation anymore. It makes sense to clear _impl on
disable(). So table::stop() can call its backlog tracker's disable
method, clearing all its state. This is important for clean
shutdown, as any sstable in tracker state may cause sstable
manager to hang when being stopped.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Normalized backlog metric is important for understanding the controller
behavior as the controller acts on normalized backlog for yielding an
output, not the raw backlog value in bytes.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Use exponential_backoff_retry::retry(abort_source&)
when sleeping between retries and request abort
when the task is stopped.
Fixes#10112
Test: unit(dev)
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Provide a function to make a sstables::compaction_stopped_exception
based on the information in the stopped task.
To be reused by the next patch that will
also throw this exception from the retry sleep path,
when the task is stopped.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
This reverts commit 4c05e5f966.
Moving cleanup to maintenance group made its operation time up to
10x slower than previous release. It's a blocker to 4.6 release,
so let's revert it until we figure this all out.
Probably this happens because maintenance group is fixed at a
relatively small constant, and cleanup may be incrementally
generating backlog for regular compaction, where the former is
fighting for resources against the latter.
Fixes#10060.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220213184306.91585-1-raphaelsc@scylladb.com>
{kind=link}