The following steps are performed in sequence as part of the
Raft-based recovery procedure:
- set `recovery_leader` to the host ID of the recovery leader in
`scylla.yaml` on all live nodes,
- send the `SIGHUP` signal to all Scylla processes to reload the config,
- perform a rolling restart (with the recovery leader being restarted
first).
These steps are not intuitive and more complicated than they could be.
In this PR, we simplify these steps. From now on, we will be able to
simply set `recovery_leader` on each node just before restarting it.
Apart from making necessary changes in the code, we also update all
tests of the Raft-based recovery procedure and the user-facing
documentation.
Fixesscylladb/scylladb#25015
The Raft-based procedure was added in 2025.2. This PR makes the
procedure simpler and less error-prone, so it should be backported
to 2025.2 and 2025.3.
Closesscylladb/scylladb#25032
* github.com:scylladb/scylladb:
docs: document the option to set recovery_leader later
test: delay setting recovery_leader in the recovery procedure tests
gossip: add recovery_leader to gossip_digest_syn
db: system_keyspace: peers_table_read_fixup: remove rows with null host_id
db/config, gms/gossiper: change recovery_leader to UUID
db/config, utils: allow using UUID as a config option
Currently, `peers_table_read_fixup` removes rows with no `host_id`, but
not with null `host_id`. Null host IDs are known to appear in system
tables, for example in `system.cluster_status` after a failed bootstrap.
We better make sure we handle them properly if they ever appear in
`system.peers`.
This commit guarantees that null UUID cannot belong to
`loaded_endpoints` in `storage_service::join_cluster`, which in
particular ensures that we throw a runtime error when a user sets
`recovery_leader` to null UUID during the recovery procedure. This is
handled by the code verifying that `recovery_leader` belongs to
`loaded_endpoints`.
Allow applying writes in the form of mutations directly to the keyspace.
Allows lower-level mutation API to build writes. Advantageous if writes
can contain large cells that would otherwise possibly cause large
allocation warnings if used via the internal CQL API.
To serve as a place to store corrupt mutation fragments. These fragments
cannot be written to sstables, as they would be spread around by
compaction and/or repair. They even might make parsing the sstable
impossible. So they are stored in this special table instead, kept
around to be inspected later and possibly restored if possible.
Requests, together with their parameters, are added to the
topology_request tables and the queue of active global requests is
kept in topology state. Thy are processed one by one by the topology
state machine.
Fixes: #16822
topology_request table has a filed to hold a request type, but
currently it can hold only per node requests. This patch makes it
possible to store global request types there as well.
Currently parameters to alter table global topology command are stored
in static column in the topology table, but this way there can be only one
outstanding alter table request. This patch moves the parameters to
the topology_request table where parameters are stored per request.
Currently, the `system.compaction_history` table miss information like the type of compaction (cleanup, major, resharding, etc), the sstable generations involved (in and out), shard's id the compaction was triggered on and statistics on purged tombstones to be collected during compaction.
The series extends the table with the following columns:
- "compaction_type" (text)
- "shard_id" (int)
- "sstables_in" (list<sstableinfo_type>)
- "sstables_out" (list<sstableinfo_type>)
- "total_tombstone_purge_attempt" (long)
- "total_tombstone_purge_failure_due_to_overlapping_with_memtable" (long)
- "total_tombstone_purge_failure_due_to_overlapping_with_uncompacting_sstable" (long)
with a user defined type `sstableinfo_type` that holds the information about sstable file
- generation (uuid)
- origin (text)
- size (long)
Additional statistics stored in the compaction_history have been incorporated in the API `/compaction_manager/compaction_history` and the `nodetool compactionhistory` command.
No backport is required. It extends the existing compaction history output.
Fixes https://github.com/scylladb/scylladb/issues/3791Closesscylladb/scylladb#21288
* github.com:scylladb/scylladb:
nodetool: Refactor of compactionhistory_operation
nodetool: Add more stats into compactionhistory output
api/compaction_manager: Extend compaction_history api
compaction: Collect tombstone purge stats during compaction
compacting_reader: Extend to accept tombstone purge statistics
mutation_compactor: Collect tombstone purge attempts
compaction_garbage_collector: Extend return type of max_purgeable_fn
compaction: Extend compaction_result to collect more information
system_keyspace: Upgrade compaction_history table
system_keyspace: Create UDT: sstableinfo_type
system_keyspace: Extract compaction_history struct
system_keyspace: Squeeze update_compaction_history parameters
compaction/compaction_manager: update_history accepts compaction_result as rvalue
Blobs can be large, and unfragmented blobs can easily exceed 128k
(as seen in #23903). Rename get_blob() to get_blob_unfragmented()
to warn users.
Note that most uses are fine as the blobs are really short strings.
Closesscylladb/scylladb#24102
Currently, the system.compaction_history table miss precious
information like the type of compaction (cleanup, major, resharding,
etc) or the sstable generations involved (in and out) used countless
times to diagnose issues.
Thus, the commit extend the current definition of the table by adding
the following columns:
+ "compaction_type" (text)
+ "started_at" (int)
+ "shard_id" (int)
+ "sstables_in" (list<sstableinfo_type>)
+ "sstables_out" (list<sstableinfo_type>)
+ "total_tombstone_purge_attempt" (long)
+ "total_tombstone_purge_failure_due_to_overlapping_with_memtable" (long)
+ "total_tombstone_purge_failure_due_to_overlapping_with_uncompacting_sstable" (long)
Furthermore, the commit introduces a new feature flag in order to
prevent nodes from writing data to new columns when a cluster is
not fully upgraded.
The new user defined type holds the following information on sstable:
+ generation uuid;
+ origin text;
+ size long;
and will be used by the system.compaction_history table to keep
track of compacted files and the files being the result of this
compaction.
Move the compaction_history_entry struct to a seperate file. The intent
of this change is to later re-use it in scylla-nodetool as it currently
defines its own structure that is very similar.
Since the number of statistics inserted into compaction_history
table grows in time, the number of parameters in the method
update_compaction_history grows as well.
So instead, let's re-use the already existing compaction_history_entry
structure to populate data from the compaction_manager to the
system table.
Changing DC or rack on a node which was already bootstrapped is, in
case of vnodes, very unsafe (almost guaranteed to cause data loss or
unavailability), and is outright not supported if the cluster has
a tablet-backed keyspaces. Moreover, the possibility of doing that
makes it impossible to uphold some of the invariants promised by
the RF-rack-valid flag, which is eventually going to become
unconditionally enabled.
Get rid of the above problems by removing the possibility of changing
the DC / rack of a node. A node will now fail to start if its snitch
reports a different DC or rack than the one that was reported during the
first boot.
Fixes: scylladb/scylladb#23278
"
The series makes endpoint state map in the gossiper addressable by host
id instead of ips. The transition has implication outside of the
gossiper as well. Gossiper based topology operations are affected by
this change since they assume that the mapping is ip based.
On wire protocol is not affected by the change as maps that are sent by
the gossiper protocol remain ip based. If old node sends two different
entries for the same host id the one with newer generation is applied.
If new node has two ids that are mapped to the same ip the newer one is
added to the outgoing map.
Interoperability was verified manually by running mixed cluster.
The series concludes the conversion of the system to be host id based.
"
* 'gleb/gossipper-endpoint-map-to-host-id-v2' of github.com:scylladb/scylla-dev:
gossiper: make examine_gossiper private
gossiper: rename get_nodes_with_host_id to get_node_ip
treewide: drop id parameter from gossiper::for_each_endpoint_state
treewide: move gossiper to index nodes by host id
gossiper: drop ip from replicate function parameters
gossiper: drop ip from apply_new_states parameters
gossiper: drop address from handle_major_state_change parameter list
gossiper: pass rpc::client_info to gossiper_shutdown verb handler
gossiper: add try_get_host_id function
gossiper: add ip to endpoint_state
serialization: fix std::map de-serializer to not invoke value's default constructor
gossiper: drop template from wait_alive_helper function
gossiper: move get_supported_features and its users to host id
storage_service: make candidates_for_removal host id based
gossiper: use peers table to detect address change
storage_service: use std::views::keys instead of std::views::transform that returns a key
gossiper: move _pending_mark_alive_endpoints to host id
gossiper: do not allow to assassinate endpoint in raft topology mode
gossiper: fix indentation after previous patch
gossiper: do not allow to assassinate non existing endpoint
Adds a helper method which queries the creation timestamp
of a given dict in `system.dicts`.
We will later use the age of the current SSTable compression dict
to decide if another training should be done already.
When a table is dropped, its corresponding dictionary in `system.dicts`
-- if any -- should be deleted, otherwise it will remain forever as
garbage.
This commit implements such cleanup.
Extend the `system.dicts` helper for querying and modifying
`system.dicts` with an ability to use names other than "general".
We will use that in later commits to publish dictionaries for SSTable compression.
Before this patch, `system.dicts` contains only one dictionary, for RPC
compression, with the fixed name "general".
In later parts of this series, we will add more dictionaries to
system.dicts, one per table, for SSTable compression.
To enable that, this patch adjusts the callback mechanism for group0's `write_mutations`
command, so that the mutation callbacks for group0-managed tables can see which
partition keys were affected. This way, the callbacks can query only the
modified partitions instead of doing a full scan. (This is necessary to
prevent quadratic behaviours.)
For now, only the `system.dicts` callback uses the partition keys.
To allow safe plug and unplug of the system_keyspace.
This patch follows-up on 917fdb9e53
(more specifically - f9b57df471)
Since just keeping a shared_ptr<system_keyspace> doesn't prevent
stopping the system_keyspace shards, while using the `pluggable`
interface allows safe draining of outstanding async calls
on shutdown, before stopping the system_keyspace.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
In the current scenario, topology_change_kind variable, was been handled using
_manage_topology_change_kind_from_group0 variable. This method was brittle
and had some bugs(e.g. for restart case, it led to a time gap between group0
server start and topology_change_kind being managed via group0)
Post _manage_topology_change_kind_from_group0 removal, careful management of
topology_change_kind variable was needed for maintaining correct
topology_change_kind in all scenarios. So this PR also performs a refactoring
to populate all init data to system tables even before group0 creation(via
raft_initialize_discovery_leader function). Now because raft_initialize_discovery_leader
happens before the group 0 creation, we write mutations directly to system
tables instead of a group 0 command. Hence, post group0 creation, the node
can read the correct values from system tables and correct values are
maintained throughout.
Added a new function initialize_done_topology_upgrade_state which takes
care of updating the correct upgrade state to system tables before starting
group0 server. This ensures that the node can read the correct values from
system tables and correct values are maintained throughout.
By moving raft_initialize_discovery_leader logic to happen before starting
group0 server, and not as group0 command post server start, we also get rid
of the potential problem of init group0 command not being the 1st command on
the server. Hence ensuring full integrity as expected by programmer.
Fixes: scylladb/scylladb#21114
node_ops_virtual_task does not filter the entries of system.topology_request
and so it creates statuses of operations that aren't node ops.
Filter the entries used by node_ops_virtual_task. With this change, the status
of a bootstrap of the first node will not be visible.
Fixes: https://github.com/scylladb/scylladb/issues/22008.
Needs backport to 6.2 that introduced node_ops_virtual_task
Closesscylladb/scylladb#22009
* github.com:scylladb/scylladb:
test: truncate the table before node ops task checks
node_ops: rename a method that get node ops entries
node_ops: filter topology_requests entries
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
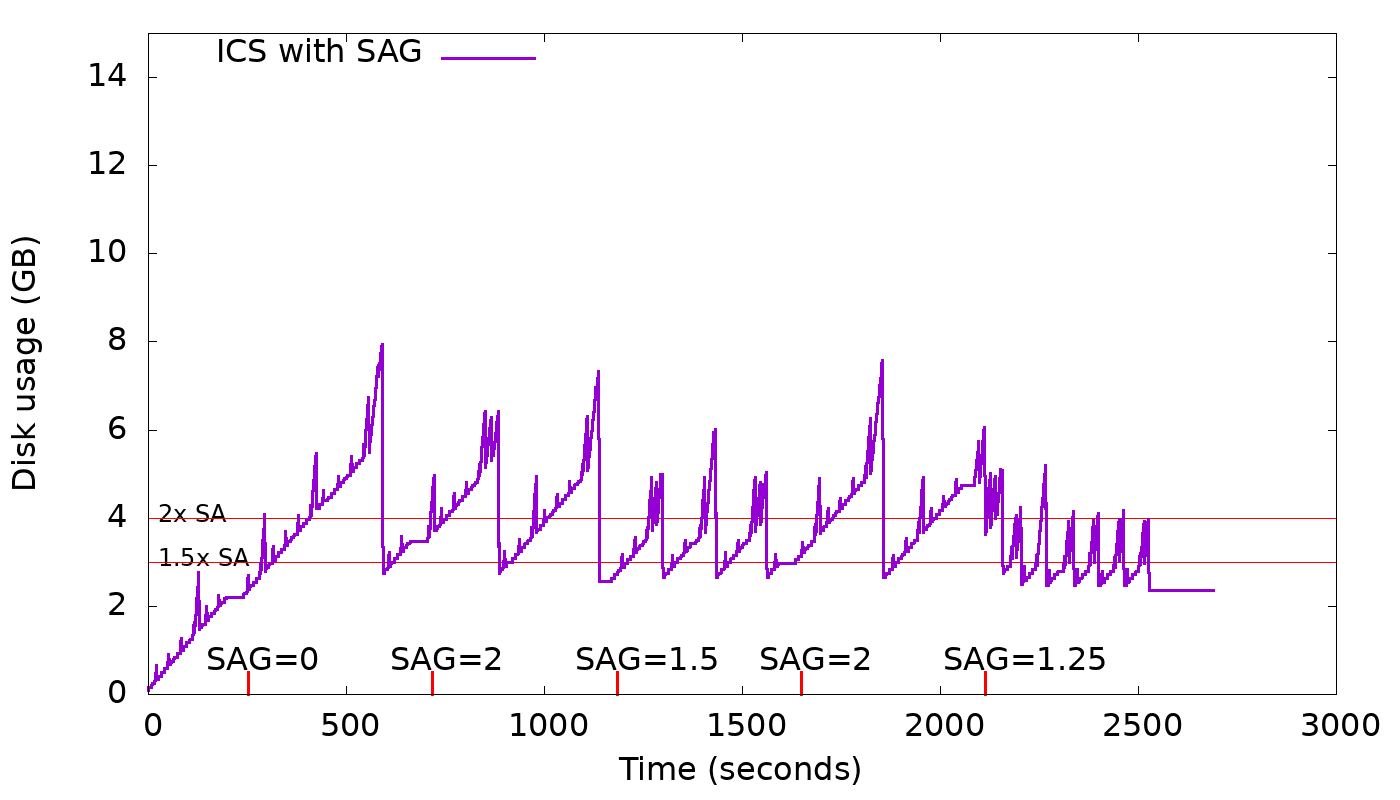
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
Add a "shares" column which hold the number of shares allocated to
given service level.
It is not used by the code at all right now, subsequent commits will
make good use of it.
Adds a new system table which will act as the medium for distributing
compression dictionaries over the cluster.
This table will be managed by Raft (group 0). It will be hooked up to it in
follow-up commits.
Currently node_ops_virtual_task shows stats of all system.topology_request
entries. However, the table also contains info about non-node_ops requests,
e.g. truncate.
Filter the entries used by node_ops_virtual_task by their type.
With this change bootstrap of the first node will not be visible.
Update the test accordingly.
"
This rather large patch series moves storage proxy and some adjacent
services (like migration manager) to use host ids to identify nodes rather
than ips. Messaging service gains a capability to address nodes by host
ids (which allows dropping translations from topology coordinator code
that worked on host ids already) and also makes sure that a node with
incorrect host id will reject a message (can happen during address
changes).
The series gets rid of the raft address map completely and replaces it with
the gossiper address map which is managed by the gossiper since translation
is now done in the layer below raft.
Fixes: scylladb/scylladb#6403
perf-simple-query -- smp 1 -m 1G output
Before:
enable-cache=1
Running test with config: {partitions=10000, concurrency=100, mode=read, frontend=cql, query_single_key=no, counters=no}
Disabling auto compaction
Creating 10000 partitions...
64336.82 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41291 insns/op, 24485 cycles/op, 0 errors)
62669.58 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41277 insns/op, 24695 cycles/op, 0 errors)
69172.12 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.2 tasks/op, 41326 insns/op, 24463 cycles/op, 0 errors)
56706.60 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41143 insns/op, 24513 cycles/op, 0 errors)
56416.65 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 41186 insns/op, 24851 cycles/op, 0 errors)
throughput: mean=61860.35 standard-deviation=5395.48 median=62669.58 median-absolute-deviation=5153.75 maximum=69172.12 minimum=56416.65
instructions_per_op: mean=41244.62 standard-deviation=76.90 median=41276.94 median-absolute-deviation=58.55 maximum=41326.19 minimum=41142.80
cpu_cycles_per_op: mean=24601.35 standard-deviation=167.39 median=24512.64 median-absolute-deviation=116.65 maximum=24851.45 minimum=24462.70
After:
enable-cache=1
Running test with config: {partitions=10000, concurrency=100, mode=read, frontend=cql, query_single_key=no, counters=no}
Disabling auto compaction
Creating 10000 partitions...
65237.35 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.2 tasks/op, 40733 insns/op, 23145 cycles/op, 0 errors)
59283.09 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40624 insns/op, 23948 cycles/op, 0 errors)
70851.03 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40625 insns/op, 23027 cycles/op, 0 errors)
70549.61 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40650 insns/op, 23266 cycles/op, 0 errors)
68634.96 tps ( 63.1 allocs/op, 0.0 logallocs/op, 14.1 tasks/op, 40622 insns/op, 22935 cycles/op, 0 errors)
throughput: mean=66911.21 standard-deviation=4814.60 median=68634.96 median-absolute-deviation=3638.40 maximum=70851.03 minimum=59283.09
instructions_per_op: mean=40650.89 standard-deviation=47.55 median=40624.60 median-absolute-deviation=27.11 maximum=40733.37 minimum=40622.33
cpu_cycles_per_op: mean=23264.16 standard-deviation=402.12 median=23145.29 median-absolute-deviation=237.63 maximum=23947.96 minimum=22934.59
CI: https://jenkins.scylladb.com/job/scylla-master/job/scylla-ci/13531/
SCT (longevity-100gb-4h with nemesis_selector: ['topology_changes']): https://jenkins.scylladb.com/view/staging/job/scylla-staging/job/gleb/job/move-to-host-id/3/
Tested mixed cluster manually.
"
* 'gleb/move-to-host-id-v2' of github.com:scylladb/scylla-dev: (55 commits)
group0: drop unused field from replace_info struct
test: rename raft_address_map_test to address_map_test and move if from raft tests
raft_address_map: remove raft address map
topology coordinator: do not modify expire state for left/new nodes any more in raft address map
topology coordinator: drop expiring entries in gossiper address map on error injections since raft one is no longer used
group0: drop raft address map dependency from raft_rpc
group0: move raft_ticker_type definition from raft_address_map.hh
storage_service: do not update raft address map on gossiper events
group0: drop raft address map dependency from raft_server_with_timeouts
group0: move group0 upgrade code to host ids
repair: drop raft address map dependency
group0: remove unused raft address map getter from raft_group0
group0: drop raft address map from group0_state_machine dependency since it is not used there any more
group0: remove dependency on raft address map from group0_state_id_handler
gossiper: add get_application_state_ptr that searches by host_id
gossiper: change get_live_token_owners to return host ids
view: move view building to host id
hints: use host id to send hints
storage_proxy: remove id_vector_to_addr since it is no longer used
db: consistency_level: change is_sufficient_live_nodes to work on host ids
...
now that we are allowed to use C++23. we now have the luxury of using
`std::views::transform`.
in this change, we:
- replace `boost::adaptors::transformed` with `std::views::transform`
- use `fmt::join()` when appropriate where `boost::algorithm::join()`
is not applicable to a range view returned by `std::view::transform`.
- use `std::ranges::fold_left()` to accumulate the range returned by
`std::view::transform`
- use `std::ranges::fold_left()` to get the maximum element in the
range returned by `std::view::transform`
- use `std::ranges::min()` to get the minimal element in the range
returned by `std::view::transform`
- use `std::ranges::equal()` to compare the range views returned
by `std::view::transform`
- remove unused `#include <boost/range/adaptor/transformed.hpp>`
- use `std::ranges::subrange()` instead of `boost::make_iterator_range()`,
to feed `std::views::transform()` a view range.
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
limitations:
there are still a couple places where we are still using
`boost::adaptors::transformed` due to the lack of a C++23 alternative
for `boost::join()` and `boost::adaptors::uniqued`.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21700
`coroutine::parallel_for_each` accepts both a range and a pair of
iterators. let's use the former when appropriate. it is simpler this way.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21684
Schema of system tables is defined statically and table_schema_version needs to be explicitly set in code like this:
```
builder.with_version(system_keyspace::generate_schema_version(table_id, version_offset));
```
Whenever schema is changed, the schema version needs to change, otherwise we hit undefined behavior when trying to interpret mutation data created with the old schema using the new schema.
It's not obvious that one needs to do that and developers often forget to do that. There were several instances of mistakes of omission, some caught during review, some not, e.g.: 31ea74b96e.
This patch changes definitions to call the new `schema_builder::with_hash_version()`, which will make the schema builder compute version from schema definition so that changes of the schema will automatically change the version. This way we no longer rely on the developer to remember to bump the version offset.
All nodes should arrive at the same version, which is verified by existing `test_group0_schema_versioning` and a new unit test: `test_system_schema_version_is_stable`.
Closesscylladb/scylladb#21602
* github.com:scylladb/scylladb:
system_tables: Compute schema version automatically
schema_builder: Introduce with_hash_version()
schema: Store raw_view_info in schema::raw_schema
schema: Remove dead comment
hashing: Add hasher for unordered_map
hashing: Add hasher for unique_ptr
hashing: Add hasher for double
[avi: add missing include <memory> to hashing.hh]
This adds a new tablet migration kind: repair. It allows tablet repair
scheduler to use this migration kind to schedule repair jobs.
The current repair scheduler implementation does the following:
- A tablet is picked to be repaired when the time since last repair is
bigger than a threshold (auto repair mode) or it is requested by user
(manual repair mode)
- The tablet repair can be scheduled along with tablet migration and
rebuild. It runs in the tablet_migration track.
- Repair jobs are scheduled in a smart way so that at any point in time,
there are no more than configured jobs per shard, which is similar to
scylla manager's control.
In this patch, both the manual repair and the auto repair are not
enabled yet.
This depends on the previous change to the schema_builder
which makes version computation depend on definition only
instead of being new time uuid.
This way we avoid the possibility for a common mistake
when schema of a system table is extended but we forget
to bump up its version passed to .with_version().
Separate the configuration for enabling the tablets feature from the enablement of tablets when creating new keyspaces.
This change always enables the TABLETS cluster feature and the tablets logic respectively.
The `enable_tablets` config option just controls whether tablets are enabled or disabled by default for new keyspaces.
If `enable_tablets` is set to `true`, tablets can be disabled using `CREATE KEYSPACE WITH tablets = { 'enabled': false }` as it is today.
If `enable_tablets` is set to `false`, tablets can be enabled using `CREATE KEYSPACE WITH tablets = { 'enabled': true }`.
The motivation for this change is to simplify the user experience of using tablets by setting the default for new keyspaces to false amd allowing the user to simply opt-in by using tablets = {enabled: true }.
This is not pissible today.
The user has to enable tablets by default for all new keyspaces (that use the NetworkTopologyStrategy) and then actively opt-out to use vnodes.
* Not required to be backported to OSS versions. May be backported to specific enterprise versions
* This PR resubmits https://github.com/scylladb/scylladb/pull/20729 that was reverted in 73b1f66b70 due to https://github.com/scylladb/scylladb/issues/21159 which is now fixed
Closesscylladb/scylladb#21451
* github.com:scylladb/scylladb:
data_dictionary: keyspace_metadata::describe: print tablets enabled also when defaulted
tablets_test: test enable/disable tablets when creating a new keyspace
treewide: always allow tablets keyspaces
feature_service: prevent enabling both tablets and gossip topology changes
alternator: create_keyspace_metadata: enable tablets using feature_service
With the tablets feature always enabled (Unless gossip toopology
changes are forced), the enable_tablets option now controls only
the default for newly created keyspaces.
Even when set to `false`, tablets are still enabled as a
feature and the user may explicitly enable tablets
using `CREATE KEYSPACE <name> WITH tablets = {'enabled': true}`
Note: best viewed with `git show -w`
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Recently, seastar rpc started accepting std::type_identity in addition
to boost::type as a type marker (while labeling the latter with an
ominous deprecation warning). Reduce our depedendency on boost
by switching to std::type_identity.
This reverts commit c286434e4c, reversing
changes made to 6712fcc316.
The commit causes memtable_test to be very flaky in debug mode.
Specifically, subtests test_exceptions_in_flush_on_sstable_open
and test_exceptions_in_flush_on_sstable_write).
With the tablets feature always enabled (Unless gossip toopology
changes are forced), the enable_tablets option now controls only
the default for newly created keyspaces.
Even when set to `false`, tablets are still enabled as a
feature and the user may explicitly enable tablets
using `CREATE KEYSPACE <name> WITH tablets = {'enabled': true}`
Note: best viewed with `git show -w`
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
the log.hh under the root of the tree was created keep the backward
compatibility when seastar was extracted into a separate library.
so log.hh should belong to `utils` directory, as it is based solely
on seastar, and can be used all subsystems.
in this change, we move log.hh into utils/log.hh to that it is more
modularized. and this also improves the readability, when one see
`#include "utils/log.hh"`, it is obvious that this source file
needs the logging system, instead of its own log facility -- please
note, we do have two other `log.hh` in the tree.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
The system.sstables (a.k.a. sstables registry) primary key is "string location" as partition key and "uuid generation" as clustering one. The "location" part was taken from table.config.datadir value which, in turn, a string containing path to on-disk files if the table was located locally, e.g. /var/lib/scylla/data/ks/cf-abc123 one. Recently [1] the datadir was moved from table config onto storage options, but this string is still used as registry key.
Other than being owned by a table with ID, sstables are accessed by restore-from-object-storage code [2]. To make it work, both storage driver and sstable_directory helper class maintain two formats of object prefixes for sstables components. For S3-backed sstables having a record in registry, the path used is s3://bucket/generation/component. For restore code there are user-provided prefixes that do not match the aforementioned pattern. The selection between those two is now made by checking sstable state, which is not obvious and may cause troubles for tiered storage driver.
This patch changes the registry schema so that partition key becomes "uuid owner" and is set to be table.id() value. This is to stop using the local path by S3 backed sstables. Also this change makes it possible for storage driver and sstable directory to rely on the storage options only to tell different bucket prefixes formats from each other.
As a side effect, the make_s3_object_name() helper, that generates the proper object name, becomes explicit for restore-from-S3 usage. Now it relies on the sstable::filename() calling this->prefix() behind the scenes and the latter to return the user-provided prefix, which is pretty fragile construction.
No need to backport (and it's not going to be easy to do it), storage options feature is still experimental
Refs #20675 [1]
Refs #20305 [2]
Closesscylladb/scylladb#20998
* github.com:scylladb/scylladb:
sstables: Flatten S3 object name making
sstable_directory: Flatten directory lister creation
treewide: Rename sstable registry location field to be owner
system_keyspace: Change sstables registry partition key type
sstables: Keep location variant on s3 backend too
storage_options: Use variant on S3 options
sstables: Split sstable::filename() helper
sstables: Add s3_storage::owner() helper
This is sort of continuation of the previous patch. The partition key in
the registry is now table_id, not string, and is better called "owner",
not "location". This patch is s/location/owner/ over specific places
that include field name in the schema, argument names in registry
maintenance classes and tests accessing the selected row fields by name.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
{kind=link}