The central idea of incremental repair is to allow repair participants
to select and repair only a portion of the dataset to speed up the
repair process. All repair participants must utilize an identical
selection method to repair and synchronize the same selected dataset.
There are two primary selection methods: time-based and file-based. The
time-based method selects data within a specified time frame. It is
versatile but it is less efficient because it requires reading all of
the dataset and omitting data beyond the time frame. The file-based
method selects data from unrepaired SSTables and is more efficient
because it allows the entire SSTable to be omitted. This document patch
implements the file-based selection method.
Incremental repair will only be supported for tablet tables; it will not
be supported for vnode tables. On one hand, the legacy vnode is less
important to support. On the other hand, the incremental repair for
vnode is much harder to implement. With vnodes, a SSTalbe could contain
data for multiple vnode ranges. When a given vnode range is repaired,
only a portion of the SSTable is repaired. This complicates the
manipulation of SSTables significantly during both repair and
compaction. With tablets, an entire tablet is repaired so that a
sstable is either fully repaired or not repaired which is a huge
simplification.
This patch uses the repaired_at from sstables::statistics component to
mark a sstable as repaired. It uses a virtual clock as the repair
timestamp, i.e., using a monotonically increasing number for the
repaired_at field of a SSTable and sstables_repaired_at column in
system.tablets table. Notice that when a sstable is not repaired, the
repaired_at field will be set to the default value 0 by default. The
being_repaired in memory field of a SSTable is used to explicitly mark
that a SSTable is being selected. The following variables are used for
incremental repair:
The repaired_at on disk field of a SSTable is used.
- A 64-bit number increases sequentially
The sstables_repaired_at is added to the system.tablets table.
- repaired_at <= sstables_repaired_at means the sstable is repaired
The being_repaired in memory field of a SSTable is added.
- A repair UUID tells which sstable has participated in the repair
Initial test results:
1) Medium dataset results
Node amount: 3
Instance type: i4i.2xlarge
Disk usage per node: ~500GB
Cluster pre-populated with ~500GB of data before starting repairs job.
Results for Repair Timings:
The regular repair run took 210 mins.
Incremental repair 1st run took 183 mins, 2nd and 3rd runs took around 48s
The speedup is: 183 mins / 48s = 228X
2) Small dataset results
Node amount: 3
Instance type: i4i.2xlarge
Disk usage per node: ~167GB
Cluster pre-populated with ~167GB of data before starting the repairs job.
Regular repair 1st run took 110s, 2nd and 3rd runs took 110s.
Incremental repair 1st run took 110 seconds, 2nd and 3rd run took 1.5 seconds.
The speedup is: 110s / 1.5s = 73X
3) Large dataset results
Node amount: 6
Instance type: i4i.2xlarge, 3 racks
50% of base load, 50% read/write
Dataset == Sum of data on each node
Dataset Non-incremental repair (minutes)
1.3 TiB 31:07
3.5 TiB 25:10
5.0 TiB 19:03
6.3 TiB 31:42
Dataset Incremental repair (minutes)
1.3 TiB 24:32
3.0 TiB 13:06
4.0 TiB 5:23
4.8 TiB 7:14
5.6 TiB 3:58
6.3 TiB 7:33
7.0 TiB 6:55
Fixes#22472Closesscylladb/scylladb#24291
* github.com:scylladb/scylladb:
replica: Introduce get_compaction_reenablers_and_lock_holders_for_repair
compaction: Move compaction_reenabler to compaction_reenabler.hh
topology_coordinator: Make rpc::remote_verb_error to warning level
repair: Add metrics for sstable bytes read and skipped from sstables
test.py: Disable incremental for test_tombstone_gc_for_streaming_and_repair
test.py: Add tests for tablet incremental repair
repair: Add tablet incremental repair support
compaction: Add tablet incremental repair support
feature_service: Add TABLET_INCREMENTAL_REPAIR feature
tablet_allocator: Add tablet_force_tablet_count_increase and decrease
repair: Add incremental helpers
sstable: Add being_repaired to sstable
sstables: Add set_repaired_at to metadata_collector
mutation_compactor: Introduce add operator to compaction_stats
tablet: Add sstables_repaired_at to system.tablets table
test: Fix drain api in task_manager_client.py
This patch addes incremental_repair support in compaction.
- The sstables are split into repaired and unrepaired set.
- Repaired and unrepaired set compact sperately.
- The repaired_at from sstable and sstables_repaired_at from
system.tablets table are used to decide if a sstable is repaired or
not.
- Different compactions tasks, e.g., minor, major, scrub, split, are
serialized with tablet repair.
Wired the unrepaired, repairing and repaired views into compaction_group.
Also the repaired filter was wired, so tablet_storage_group_manager
can implement the procedure to classify the sstable.
Based on this classifier, we can decide which view a sstable belongs
to, at any given point in time.
Additionally, we made changes changes to compaction_group_view
to return only sstables that belong to the underlying view.
From this point on, repaired, repairing and unrepaired sets are
connected to compaction manager through their views. And that
guarantees sstables on different groups cannot be compacted
together.
Repairing view specifically has compaction disabled on it altogether,
we can revert this later if we want, to allow repairing sstables
to be compacted with one another.
The benefit of this logical approach is having the classifier
as the single source of truth. Otherwise, we'd need to keep the
sstable location consistest with global metadata, creating
complexity
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
This will allow upcoming work to gently produce a sstable set for
each compaction group view. Example: repaired and unrepaired.
Locking strategy for compaction's sstable selection:
Since sstable retrieval path became futurized, tasks in compaction
manager will now hold the write lock (compaction_state::lock)
when retrieving the sstable list, feeding them into compaction
strategy, and finally registering selected sstables as compacting.
The last step prevents another concurrent task from picking the
same sstable. Previously, all those steps were atomic, but
we have seen stall in that area in large installations, so
futurization of that area would come sooner or later.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Since table_state is a view to a compaction group, it makes sense
to rename it as so.
With upcoming incremental repair, each replica::compaction_group
will be actually two compaction groups, so there will be two
views for each replica::compaction_group.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
to get_static_effective_replication_map, in preparation
for separating local_effective_replication_map from
vnode_effective_replication_map (both are per-keyspace).
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
As requested in #22114, moved the files and fixed other includes and build system.
Moved files:
- interval.hh
- Map_difference.hh
Fixes: #22114
This is a cleanup, no need to backport
Closesscylladb/scylladb#25095
Currently, when a max purgeable timestamp is computed, there is no
information where it comes from and how the value was obtained.
Take compaction, if there are memtables or other uncompacting sstables
possibly shadowing data, the timestamp is decreased to ensure a
tombstone is not purged but the caller does not know what that the
timestamp has its value.
In this patch, we extend the return type of max_purgeable_fn to
contain not only a timestamp but also an information on how it was
computed. This information will be required to collect statistics
on tombstone purge failures due to overlapping memtables/uncompacting
sstables that come later in the series.
Following a number of similar code cleanup PR, this one aims to be the last one, definitely dropping flat from all reader and related names.
Similarly, v2 is also dropped from reader names, although it still persists in mutation_fragment_v2, mutation_v2 and related names. This won't change in the foreseeable future, as we don't have plans to drop mutation (the v1 variant).
The changes in this PR are entirely mechanical, mostly just search-and-replace.
Code cleanup, no backport required.
Closesscylladb/scylladb#24087
* github.com:scylladb/scylladb:
test/boost/mutation_reader_another_test: drop v2 from reader and related names
test/boost/mutation_reader: s/puppet_reader_v2/puppet_reader/
test/boost/sstable_datafile_test: s/sstable_reader_v2/sstable_mutation_reader/
test/boost/mutation_test: s/consumer_v2/consumer/
test/lib/mutation_reader_assertions: s/flat_reader_assertions_v2/mutation_reader_assertions/
readers/mutation_readers: s/generating_reader_v2/generating_reader/
readers/mutation_readers: s/delegating_reader_v2/delegating_reader/
readers/mutation_readers: s/empty_flat_reader_v2/empty_mutation_reader/
readers/mutation_source: s/make_reader_v2/make_mutation_reader/
readers/mutation_source: s/flat_reader_v2_factory_type/mutation_reader_factory/
readers/mutation_reader: s/reader_consumer_v2/mutation_reader_consumer/
mutation/mutation_compactor: drop v2 from compactor and related names
replica/table: s/make_reader_v2/make_mutation_reader/
mutation_writer: s/bucket_writer_v2/bucket_writer/
readers/queue: drop v2 from reader and related names
readers/multishard: drop v2 from reader and related names
readers/evictable: drop v2 from reader and related names
readers/multi_range: remove flat from name
In next patches, make_sstable_compressor_factory() will have to
disappear.
In preparation for that, we switch to a seastar::thread-dependent
replacement.
`sstable_manager` depends on `sstable_compressor_factory&`.
Currently, `test_env` obtains an implementation of this
interface with the synchronous `make_sstable_compressor_factory()`.
But after this patch, the only implementation of that interface
`sstable_compressor_factory&` will use `sharded<...>`,
so its construction will become asynchronous,
and the synchronous `make_sstable_compressor_factory()` must disappear.
There are several possible ways to deal with this, but I think the
easiest one is to write an asynchronous replacement for
`make_sstable_compressor_factory()`
that will keep the same signature but will be only usable
in a `seastar::thread`.
All other uses of `make_sstable_compressor_factory()` outside of
`test_env::do_with()` already are in seastar threads,
so if we just get rid of `test_env::do_with()`, then we will
be able to use that thread-dependent replacement. This is the
purpose of this commit.
We shouldn't be losing much.
Interval map is very susceptible to quadratic space behavior when
it's flooded with many entries overlapping all (or most of)
intervals, since each such entry will have presence on all
intervals it overlaps with.
A trigger we observed was memtable flush storm, which creates many
small "L0" sstables that spans roughly the entire token range.
Since we cannot rely on insertion order, solution will be about
storing sstables with such wide ranges in a vector (unleveled).
There should be no consequence for single-key reads, since upper
layer applies an additional filtering based on token of key being
queried.
And for range scans, there can be an increase in memory usage,
but not significant because the sstables span an wide range and
would have been selected in the combined reader if the range of
scan overlaps with them.
Anyway, this is a protection against storm of memtable flushes
and shouldn't be the common scenario.
It works both with tablets and vnodes, by adjusting the token
range spanned by compaction group accordingly.
Fixes#23634.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Following up on the previous commits, we avoid constructing
compressors where not necessary,
by checking things directly on `compression_parameters` instead.
Note: this commit is meant to be a code refactoring only and is not intended
to change the observable behaviour.
Today `schema` contains a `compression_parameters`.
`compression_parameters` contains an instance of
`compressor`, and SSTable writers just share that instance.
This is fine because `compressor` is a stateless object,
functionally dependent on the schema.
But in later parts of the series, we will break this functional
dependency by adding dictionaries to compressors. Two writers
for the same schema might have different dictionaries, so they won't
be able to just share a single instance contained in the schema.
And when that happens, having a `compressor` instance
in the `schema`/`compression_parameters` will become awkward,
since it won't be actually used. It will be only a container for options.
In addition, for performance reasons, we will want to share some pieces
of compressors across shards, which will require -- in the general case --
a construction of a compressor to be asynchronous, and therefore not
possible inside the constructor of `compression_parameters`.
This commit modifies `compression_parameters` so that it doesn't hold or
construct instances of `compressor`.
Before this patch, the `compressor` instance constructed in
`compression_parameters` has an additional role of validating and
holding compressor-specific options.
(Today the only such option is the zstd compression level).
This means that the pieces of logic responsible for compressor-specific
options have to be rewritten. That ends up being the bulk of this commit.
Similarly to previous patches -- mostly the result is used as log
argument. The remaining users include
- scylla sstable tool that dumps component names to json output
- API endpoint that returns component names to user
- tests
these are all good to explicitly convert component_names to strings.
There are few more places that expect strings instead of component name
objects. For now they also use fmt::to_string() explicitly, partially it
will be fixed later, mostly -- as future follow-ups.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
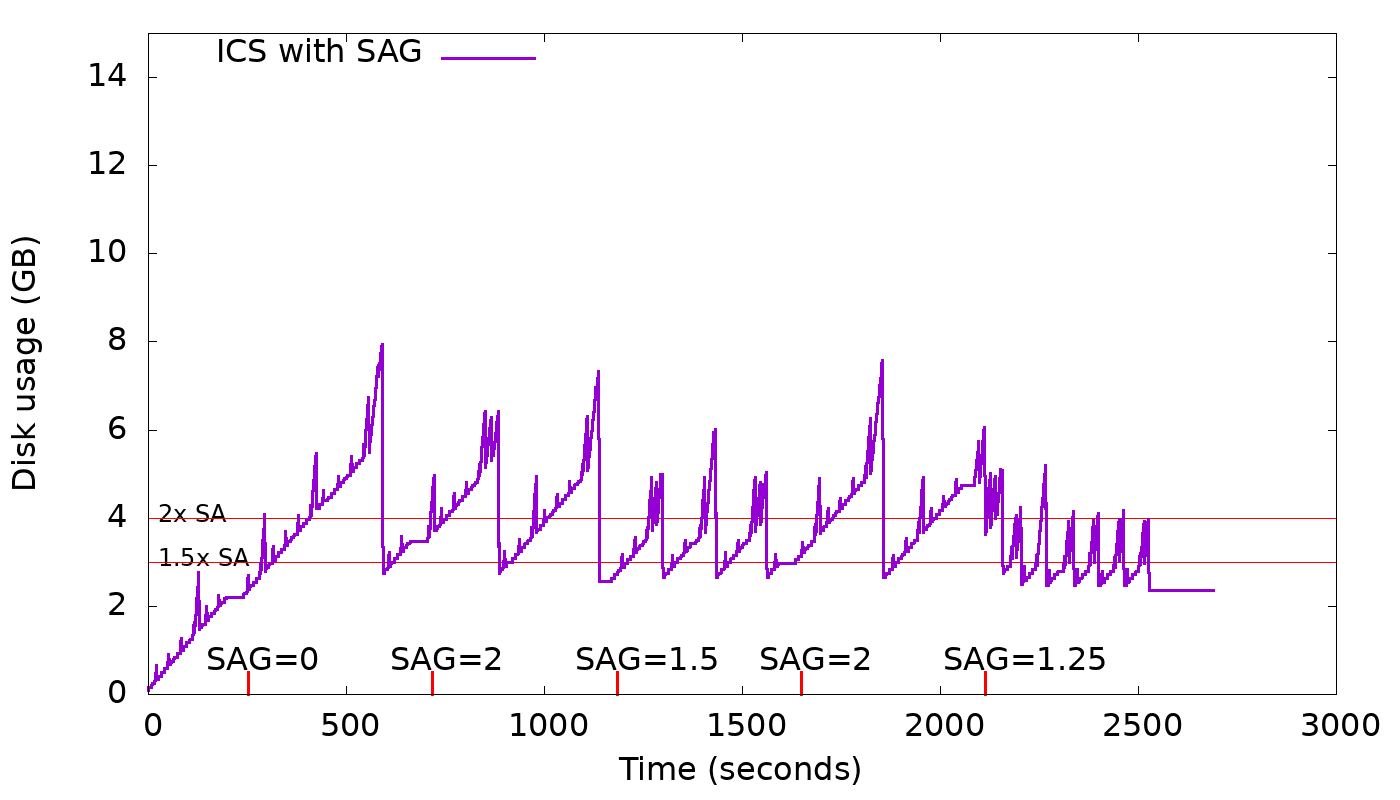
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
now that we are allowed to use C++23. we now have the luxury of using
`std::ranges::to`.
in this change, we:
- replace `boost::copy_range` to `std::ranges::to`
- remove unused `#include` of boost headers
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21880
To reduce test executable size and speed up compilation time, compile unit
tests into a single executable.
Here is a file size comparison of the unit test executable:
- Before applying the patch
$ du -h --exclude='*.o' --exclude='*.o.d' build/release/test/boost/ build/debug/test/boost/
11G build/release/test/boost/
29G build/debug/test/boost/
- After applying the patch
du -h --exclude='*.o' --exclude='*.o.d' build/release/test/boost/ build/debug/test/boost/
5.5G build/release/test/boost/
19G build/debug/test/boost/
It reduces executable sizes 5.5GB on release, and 10GB on debug.
Closes#9155Closesscylladb/scylladb#21443
Replace boost::make_iterator_range() with std::ranges::subrange.
This change improves code modernization and reduces external dependencies:
- Replace boost::make_iterator_range() with std::ranges::subrange
- Remove boost/range/iterator_range.hpp include
- Improve iterator type detection in interval.hh using std::ranges::const_iterator_t<Range>
This is part of ongoing efforts to modernize our codebase and minimize
external dependencies.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21787
With commits ed7d352e7d and bb1867c7c7, we now have input streams for both compressed and uncompressed SSTables that provide seamless checksum and digest checking. The code for these was based on `validate_checksums()`, which implements its own validation logic over raw streams. This has led to some duplicate code.
This PR deduplicates the uncompressed case by modifying `validate_checksums()` to use a checksummed input stream instead of a raw stream. The same cannot be done for compressed SSTables though. The reason is that `validate_checksums()` needs to examine the whole data file, even if an invalid chunk is encountered. In the checksummed case we support that by offloading the error handling logic from the data source via a function parameter. In the compressed data source we cannot do that because it needs to return decompressed data and decompression may fail if the data are invalid.
This PR also enables `validate_checksums()` to partially verify SSTables with just the per-chunk checksums if the digest is missing.
In more detail, this PR consists of:
* Port of some integrity checks from `do_validate_uncompressed()` to the checksummed data source. It should now be able to detect corruption due to truncated or appended chunks (expected number of chunks is retrieved from the CRC component).
* Introduction of `error_handler` parameter in checksummed data source and `data_stream()`.
* Refactoring of `validate_checksums()`. The JSON response of `sstable validate-checksums` was also modified to report a missing digest.
* Tests for `validate_checksums()` against SSTables with truncated data, appended data, invalid digests, or no digest.
Refs #19058.
This PR is a hybrid of cleanup and feature. No backport is needed.
Closesscylladb/scylladb#20933
* github.com:scylladb/scylladb:
tools/scylla-sstable: Rename valid_checksums -> valid
test: Check validate_checksums() with missing digest
sstables: Allow validate_checksums() to report missing digests
sstables: Refactor validate_checksums() to use checksummed data stream
sstables: Add error_handler parameter to data_stream()
sstables: Add error handler in checksummed data source
sstables: Check for excessive chunks in checksummed data source
sstables: Check for premature EOF in checksummed data source
test: test_validate_checksums: Check SSTable with invalid digest
test: test_validate_checksums: Check SSTable with appended data
test: test_validate_checksums: Complement test for truncated SSTable
now that we are allowed to use C++23. we now have the luxury of using
`std::views::transform`.
in this change, we:
- replace `boost::adaptors::transformed` with `std::views::transform`
- use `fmt::join()` when appropriate where `boost::algorithm::join()`
is not applicable to a range view returned by `std::view::transform`.
- use `std::ranges::fold_left()` to accumulate the range returned by
`std::view::transform`
- use `std::ranges::fold_left()` to get the maximum element in the
range returned by `std::view::transform`
- use `std::ranges::min()` to get the minimal element in the range
returned by `std::view::transform`
- use `std::ranges::equal()` to compare the range views returned
by `std::view::transform`
- remove unused `#include <boost/range/adaptor/transformed.hpp>`
- use `std::ranges::subrange()` instead of `boost::make_iterator_range()`,
to feed `std::views::transform()` a view range.
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
limitations:
there are still a couple places where we are still using
`boost::adaptors::transformed` due to the lack of a C++23 alternative
for `boost::join()` and `boost::adaptors::uniqued`.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21700
Scrub compaction can pick up input sstables from maintenance sstable set
but on compaction completion, it doesn't update the maintenance set
leaving the original sstable in set after it has been scrubbed. To fix
this, on compaction completion has to update the maintenance sstable if
the input originated from there.
This patch modifies the `update_sstable_sets_on_compaction_completion`
to remove the input sstable from the maintenance sstable set if it
exists in that set.
Also added a testcase to verify the fix.
Fixes#20030
Signed-off-by: Lakshmi Narayanan Sreethar <lakshmi.sreethar@scylladb.com>
Currently, `validate_checksums()` expects the SSTable to have a digest
component and fails immediately otherwise. This is suboptimal since data
integrity verification could still be carried out partially via checksum
checking.
Lift this restriction by allowing the function to perform checksum
checking in any case, and treat digest checking as best effort. Add a
separate boolean flag in the response to indicate the presence or
absence of the digest component, so that the user can deduce if a valid
result involved digest checking or not.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
now that we are allowed to use C++23. we now have the luxury of using
`std::ranges::find_if`.
in this change, we:
- replace `boost::find_if` with `std::ranges::find_if`
- remove all `#include <boost/range/algorithm/find_if.hpp>`
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
In the previous patch we enabled integrity checking on all compaction
types. This means that compaction jobs should now fail if they encounter
an SSTable with an invalid checksum or digest.
Add a test to verify this behavior. Test every compaction type with:
* compressed/uncompressed SSTables with invalid checksums
* compressed/uncompressed SSTables with invalid digests
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
now that we are allowed to use C++23. we now have the luxury of using
`std::ranges::any_of`.
in this change, we replace `boost::algorithm::any_of` with
`std::ranges::any_of`
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
now that we are allowed to use C++23. we now have the luxury of using
`std::ranges::all_of`.
in this change, we replace `boost::algorithm::all_of` with
`std::ranges::all_of`
to reduce the dependency to boost for better maintainability, and
leverage standard library features for better long-term support.
this change is part of our ongoing effort to modernize our codebase
and reduce external dependencies where possible.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
This PR builds upon the PR for checksum validation (#20207) to further enhance scrub's corruption detection capabilities by validating digests as well. The digest (full checksum) is the checksum over the entire data, as opposed to per-chunk checksums which apply to individual chunks. Until now, digests were not examined on any code paths. This PR integrates digest checking into the compressed/checksummed data sources as an optional feature and enables it only through the validation path of the sstable layer (`sstable::validate()`). The validation path is used by the following tools:
* scrub in validate mode
* `sstable validate`
All other reads, including normal user reads, are unaffected by this change.
The PR consists of:
* Extensions to the compressed and checksummed data sources to support digest checking. The data sources receive the expected digest as a parameter and calculate the actual digest incrementally across multiple get() calls. The check happens on the get() call that reaches EOF and results to an exception if the digest is invalid. A digest check requires reading the whole file range. Therefore, a partial read or skip() is treated as an internal error.
* A new shareable digest component loaded on demand by the validation code. No lifecycle management.
* Grouping of old scrub/validate tests for compressed and uncompressed SSTables to reduce code duplication.
* scrub/validate tests for SSTables with valid checksums but invalid digests, and SSTables with no digests at all.
* scrub/validate tests with 3.x Cassandra SSTables to ensure compatibility.
Refs #19058.
New feature, no backport is needed.
Closesscylladb/scylladb#20720
* github.com:scylladb/scylladb:
test: Test scrub/validate with SSTables from Cassandra
compaction: Make quarantine optional for perform_sstable_scrub()
test: Make random schema optional in scrub_test_framework
test: Add tests for invalid digests
test: Merge scrub/validate tests for compressed and uncompressed cases
sstables: Verify digests on validation path
sstables: Check if digest component exists
sstables: Add digest in the SSTable components
sstables: Add digest check in compressed data source
sstables: Add digest check in checksummed data source
All current unit tests for scrub in validate mode generate random
SSTables on the fly.
Add some more tests with frozen Cassandra SSTables from the source tree
to verify compatibility with Cassandra. Use some of the existing 3.x
Cassandra SSTables to test the valid case, and use the same schema to
generate some corrupted SSTables for the invalid case. Overall, the new
tests cover the following scenarios:
* valid compressed/uncompressed
* compressed/uncompressed with invalid checksums
* compressed/uncompressed with invalid digest
For the compressed SSTable with invalid checksums, a small chunk length
was used (4KiB) to have more chunks with less disk space. For
uncompressed SSTables the chunk length is not configurable.
Finally, since the SSTables live in the source tree, the quarantine
mechanism was disabled.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
The scrub_test_framework, which is the foundation for all scrub-related
tests, always generates a random schema upon initialization and makes it
available to the user. This is useful for running tests with ephemeral
SSTables, but is redundant when the creation of the SSTable predates the
test (e.g., it lives in the source tree).
Turn scrub_test_framework into a template with a boolean parameter to
optionally switch off the random schema generation. Also, add an
overload for run() to support passing a ready-to-use SSTable instead of
mutation fragments.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
In a previous patch we extended the validation path of the SSTable layer
to validate the digests along with the checksums.
Add two tests for compressed and uncompressed SSTables to test the
validation API against SSTables with valid checksums but corrupted
digests.
Add two more tests to ensure that the absence of digest does not affect
checksum validation.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
Currently, every scrub/validate test is duplicated to cover both
compressed and uncompressed SSTables. However, except for the
compression type, the tests are identical. This leads to some code
bloat.
Introduce common functions parameterized by the compression type to
reduce code duplication. Also, group together the compressed and
uncompressed variants into one compression-agnostic test.
Signed-off-by: Nikos Dragazis <nikolaos.dragazis@scylladb.com>
Using the standard library is preffered over boost.
In cql3/expr/expression.cc to_sorted_vector got more of a
face-list and was modernized to use also std::unique
and while at it, to move its input range in the uniquely sorted
result vector.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
The `consume*()` variants just forward the call to the `_impl` method with the same name. The latter, being a member of `::impl`, will bypass the top level `fill_buffer()`, etc. methods and thus will never call `set_close_required()`. Do this in the top-level `consume*()` methods instead, to ensure a reader, on which only `consume*()` is called, and then is destroyed, will complain as it should (and abort).
Only one place was found in core code, which didn't close the reader: `split_mutation() in `mutation/mutation.cc` and this reader is the "from-mutation" one which has no real close routine. All other places were in tests. All this is to say, there were no real bugs uncovered by this PR.
Fixes#16520
Improvement, no backport required.
Closesscylladb/scylladb#16522
* github.com:scylladb/scylladb:
readers/flat_mutation_reader_v2: call set_close_required() from consume*()
test/boost/sstable_compaction_test: close reader after use
test/boost/repair_test: close reader after use
mutation/mutation: split_mutation(): close reader after use
This function was obsoleted by schema_builder some time ago. Not to patch all its callers, that helper became wrapper around it. Remained users are all in tests, and patching the to use builder directory makes the code shorter in many cases.
Closesscylladb/scylladb#20466
* github.com:scylladb/scylladb:
schema: Ditch make_shared_schema() helper
test: Tune up indentation in uncompressed_schema()
test: Make tests use schema_builder instead of make_shared_schema
When purging regular tombstone consult the min_live_timestamp, if available.
This is safe since we don't need to protect dead data from resurrection, as it is already dead.
For shadowable_tombstones, consult the min_memtable_live_row_marker_timestamp,
if available, otherwise fallback to the min_live_timestamp.
If we see in a view table a shadowable tombstone with time T, then in any row where the row marker's timestamp is higher than T the shadowable tombstone is completely ignored and it doesn't hide any data in any column, so the shadowable tombstone can be safely purged without any effect or risk resurrecting any deleted data.
In other words, rows which might cause problems for purging a shadowable tombstone with time T are rows with row markers older or equal T. So to know if a whole sstable can cause problems for shadowable tombstone of time T, we need to check if the sstable's oldest row marker (and not oldest column) is older or equal T. And the same check applies similarly to the memtable.
If both extended timestamp statistics are missing, fallback to the legacy (and inaccurate) min_timestamp.
Fixesscylladb/scylladb#20423Fixesscylladb/scylladb#20424
> [!NOTE]
> no backport needed at this time
> We may consider backport later on after given some soak time in master/enterprise
> since we do see tombstone accumulation in the field under some materialized views workloads
Closesscylladb/scylladb#20446
* github.com:scylladb/scylladb:
cql-pytest: add test_compaction_tombstone_gc
sstable_compaction_test: add mv_tombstone_purge_test
sstable_compaction_test: tombstone_purge_test: test that old deleted data do not inhibit tombstone garbage collection
sstable_compaction_test: tombstone_purge_test: add testlog debugging
sstable_compaction_test: tombstone_purge_test: make_expiring: use next_timestamp
sstable, compaction: add debug logging for extended min timestamp stats
compaction: get_max_purgeable_timestamp: use memtable and sstable extended timestamp stats
compaction: define max_purgeable_fn
tombstone: can_gc_fn: move declaration to compaction_garbage_collector.hh
sstables: scylla_metadata: add ext_timestamp_stats
compaction_group, storage_group, table_state: add extended timestamp stats getters
sstables, memtable: track live timestamps
memtable_encoding_stats_collector: update row_marker: do nothing if missing
This PR introduces a new file data source implementation for uncompressed SSTables that will be validating the checksum of each chunk that is being read. Unlike for compressed SSTables, checksum validation for uncompressed SSTables will be active for scrub/validate reads but not for normal user reads to ensure we will not have any performance regression.
It consists of:
* A new file data source for uncompressed SSTables.
* Integration of checksums into SSTable's shareable components. The validation code loads the component on demand and manages its lifecycle with shared pointers.
* A new `integrity_check` flag to enable the new file data source for uncompressed SSTables. The flag is currently enabled only through the validation path, i.e., it does not affect normal user reads.
* New scrub tests for both compressed and uncompressed SSTables, as well as improvements in the existing ones.
* A change in JSON response of `scylla validate-checksums` to report if an uncompressed SSTable cannot be validated due to lack of checksums (no `CRC.db` in `TOC.txt`).
Refs #19058.
New feature, no backport is needed.
Closesscylladb/scylladb#20207
* github.com:scylladb/scylladb:
test: Add test to validate SSTables with no checksums
tools: Fix typo in help message of scylla validate-checksums
sstables: Allow validate_checksums() to report missing checksums
test: Add test for concurrent scrub/validate operations
test: Add scrub/validate tests for uncompressed SSTables
test/lib: Add option to create uncompressed random schemas
test: Add test for scrub/validate with file-level corruption
test: Check validation errors in scrub tests
sstables: Enable checksum validation for uncompressed SSTables
sstables: Expose integrity option via crawling mutation readers
sstables: Expose integrity option via data_consume_rows()
sstables: Add option for integrity check in data streams
sstables: Remove unused variable
sstables: Add checksum in the SSTable components
sstables: Introduce checksummed file data source implementation
sstables: Replace assert with on_internal_error
{kind=link}