mirror of
https://github.com/scylladb/scylladb.git
synced 2026-06-03 21:47:10 +00:00
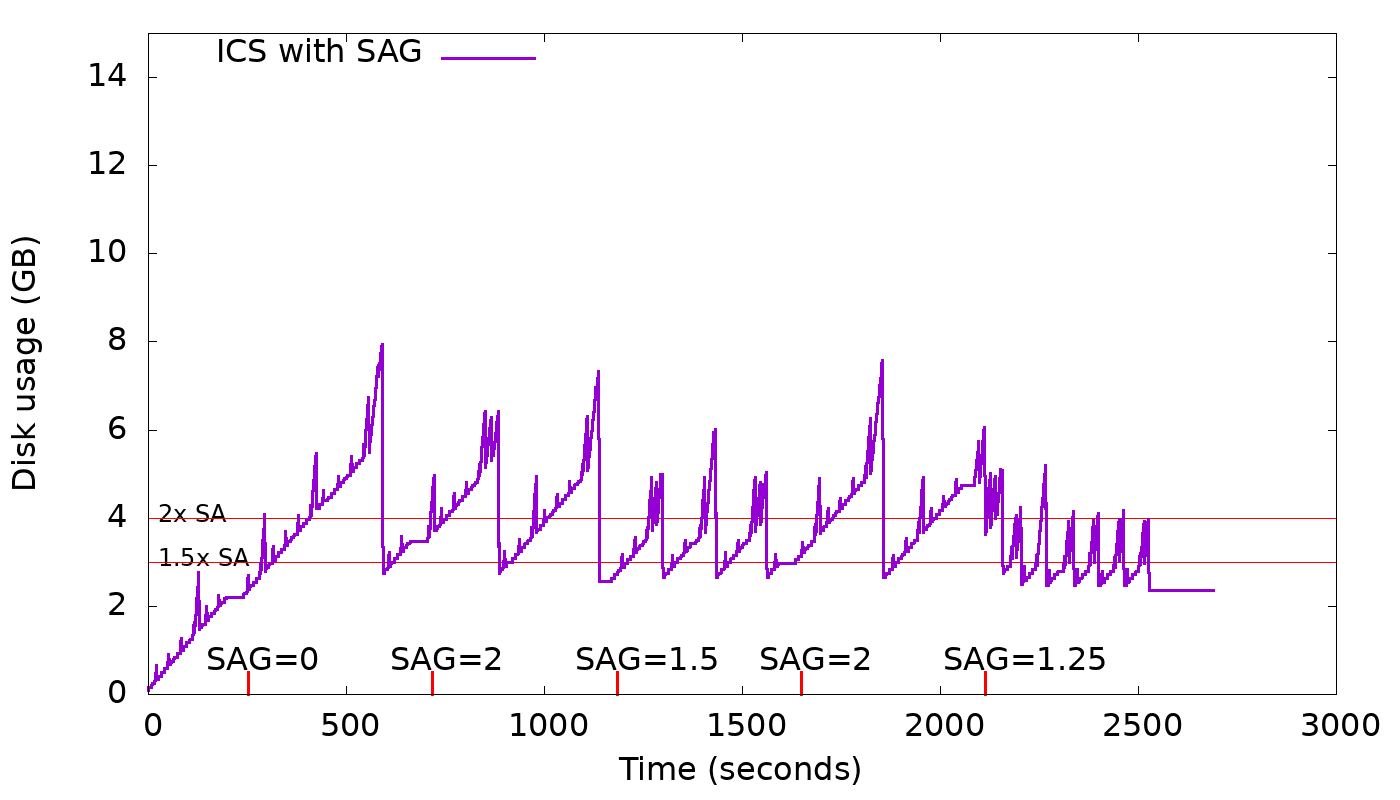
ICS is a compaction strategy that inherits size tiered properties -- therefore it's write optimized too -- but fixes its space overhead of 100% due to input files being only released on completion. That's achieved with the concept of sstable run (similar in concept to LCS levels) which breaks a large sstable into fixed-size chunks (1G by default), known as run fragments. ICS picks similar-sized runs for compaction, and fragments of those runs can be released incrementally as they're compacted, reducing the space overhead to about (number_of_input_runs * 1G). This allows user to increase storage density of nodes (from 50% to ~80%), reducing the cost of ownership. NOTE: test_system_schema_version_is_stable adjusted to account for batchlog using IncrementalCompactionStrategy contains: compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh) compaction/CMakeLists.txt: include ICS cc files configure.py: changes for ICS files, includes test db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported db/system_keyspace: pick ICS for some system tables schema/schema.hh: ICS becomes default test/boost: Add incremental_compaction_test.cc test/boost/sstable_compaction_test.cc: ICS related changes test/cqlpy/test_compaction_strategy_validation.py: ICS related changes docs/architecture/compaction/compaction-strategies.rst: changes to ICS section docs/cql/compaction.rst: changes to ICS section docs/cql/ddl.rst: adds reference to ICS options docs/getting-started/system-requirements.rst: updates sentence mentioning ICS docs/kb/compaction.rst: changes to ICS section docs/kb/garbage-collection-ics.rst: add file docs/kb/index.rst: add reference to <garbage-collection-ics> docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section some relevant commits throughout the ICS history: commit 434b97699b39c570d0d849d372bf64f418e5c692 Merge: 105586f747 30250749b8 Author: Paweł Dziepak <pdziepak@scylladb.com> Date: Tue Mar 12 12:14:23 2019 +0000 Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael " Introduce new compaction strategy which is essentially like size tiered but will work with the existing incremental compaction. Thus incremental compaction strategy. It works like size tiered, but each element composing a tier is a sstable run, meaning that the compaction strategy will look for N similar-sized sstable runs to compact, not just individual sstables. Parameters: * "sstable_size_in_mb": defines the maximum sstable (fragment) size composing a sstable run, which impacts directly the disk space requirement which is improved with incremental compaction. The lower the value the lower the space requirement for compaction because fragments involved will be released more frequently. * all others available in size tiered compaction strategy HOWTO ===== To change an existing table to use it, do: ALTER TABLE mykeyspace.mytable WITH compaction = {'class' : 'IncrementalCompactionStrategy'}; Set fragment size: ALTER TABLE mykeyspace.mytable WITH compaction = {'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 } " commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1 Merge: dca89ce7a5 e08ef3e1a3 Author: Avi Kivity <avi@scylladb.com> Date: Tue Sep 8 11:31:52 2020 +0300 Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael " A new option, space_amplification_goal (SAG), is being added to ICS. This option will allow ICS user to set a goal on the space amplification (SA). It's not supposed to be an upper bound on the space amplification, but rather, a goal. This new option will be disabled by default as it doesn't benefit write-only (no overwrites) workloads and could hurt severely the write performance. The strategy is free to delay triggering this new behavior, in order to increase overall compaction efficiency. The graph below shows how this feature works in practice for different values of space_amplification_goal: https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png When strategy finds space amplification crossed space_amplification_goal, it will work on reducing the SA by doing a cross-tier compaction on the two largest tiers. This feature works only on the two largest tiers, because taking into account others, could hurt the compaction efficiency which is based on the fact that the more similar-sized sstables are compacted together the higher the compaction efficiency will be. With SAG enabled, min_threshold only plays an important role on the smallest tiers, given that the second-largest tier could be compacted into the largest tier for a space_amplification_goal value < 2. By making the options space_amplification_goal and min_threshold independent, user will be able to tune write amplification and space amplification, based on the needs. The lower the space_amplification_goal the higher the write amplification, but by increasing the min threshold, the write amplification can be decreased to a desired amount. " commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1 Author: Raphael S. Carvalho <raphaelsc@scylladb.com> Date: Sat Oct 16 13:41:46 2021 -0300 compaction: ICS: Add garbage collection Today, ICS lacks an approach to persist expired tombstones in a timely manner, which is a problem because accumulation of tombstones are known to affecting latency considerably. For an expired tombstone to be purged, it has to reach the top of the LSM tree and hope that older overlapping data wasn't introduced at the bottom. The condition are there and must be satisfied to avoid data resurrection. STCS, today, has an inefficient garbage collection approach because it only picks a single sstable, which satisfies the tombstone density threshold and file staleness. That's a problem because overlapping data either on same tier or smaller tiers will prevent tombstones from being purged. Also, nothing is done to push the tombstones to the top of the tree, for the conditions to be eventually satisfied. Due to incremental compaction, ICS can more easily have an effecient GC by doing cross-tier compaction of relevant tiers. The trigger will be file staleness and tombstone density, which threshold values can be configured by tombstone_compaction_interval and tombstone_threshold, respectively. If ICS finds a tier which meets both conditions, then that tier and the larger[1] *and* closest-in-size[2] tier will be compacted together. [1]: A larger tier is picked because we want tombstones to eventually reach the top of the tree. [2]: It also has to be the closest-in-size tier as the smaller the size difference the higher the efficiency of the compaction. We want to minimize write amplification as much as possible. The staleness condition is there to prevent the same file from being picked over and over again in a short interval. With this approach, ICS will be continuously working to purge garbage while not hurting overall efficiency on a steady state, as same-tier compactions are prioritized. Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com> Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com> Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com> Closes scylladb/scylladb#22063
{kind=link}
2750 lines
118 KiB
C++
2750 lines
118 KiB
C++
/*
|
|
* Modified by ScyllaDB
|
|
* Copyright (C) 2015-present ScyllaDB
|
|
*/
|
|
|
|
/*
|
|
* SPDX-License-Identifier: (LicenseRef-ScyllaDB-Source-Available-1.0 and Apache-2.0)
|
|
*/
|
|
|
|
#include "db/schema_tables.hh"
|
|
|
|
#include "service/migration_manager.hh"
|
|
#include "service/storage_proxy.hh"
|
|
#include "gms/feature_service.hh"
|
|
#include "partition_slice_builder.hh"
|
|
#include "dht/i_partitioner.hh"
|
|
#include "system_keyspace.hh"
|
|
#include "query-result-set.hh"
|
|
#include "query-result-writer.hh"
|
|
#include "schema/schema_builder.hh"
|
|
#include "map_difference.hh"
|
|
#include "utils/assert.hh"
|
|
#include "utils/UUID_gen.hh"
|
|
#include "utils/to_string.hh"
|
|
#include <seastar/coroutine/all.hh>
|
|
#include "utils/log.hh"
|
|
#include "frozen_schema.hh"
|
|
#include "schema/schema_registry.hh"
|
|
#include "mutation_query.hh"
|
|
#include "system_keyspace.hh"
|
|
#include "system_distributed_keyspace.hh"
|
|
#include "cql3/query_processor.hh"
|
|
#include "cql3/cql3_type.hh"
|
|
#include "cql3/functions/functions.hh"
|
|
#include "cql3/functions/user_function.hh"
|
|
#include "cql3/functions/user_aggregate.hh"
|
|
#include "cql3/expr/evaluate.hh"
|
|
#include "cql3/expr/expr-utils.hh"
|
|
#include "cql3/util.hh"
|
|
#include "types/list.hh"
|
|
#include "types/set.hh"
|
|
#include "replica/tablets.hh"
|
|
|
|
#include "db/marshal/type_parser.hh"
|
|
#include "db/config.hh"
|
|
#include "db/extensions.hh"
|
|
#include "utils/hashers.hh"
|
|
|
|
#include <fmt/ranges.h>
|
|
|
|
#include <seastar/util/noncopyable_function.hh>
|
|
#include <seastar/rpc/rpc_types.hh>
|
|
#include <seastar/core/coroutine.hh>
|
|
#include <seastar/core/future.hh>
|
|
#include <seastar/coroutine/parallel_for_each.hh>
|
|
#include <seastar/core/loop.hh>
|
|
#include <seastar/core/on_internal_error.hh>
|
|
|
|
#include <boost/algorithm/string/predicate.hpp>
|
|
#include <boost/range/algorithm/copy.hpp>
|
|
#include <boost/range/algorithm/transform.hpp>
|
|
#include <boost/range/adaptor/indirected.hpp>
|
|
#include <boost/range/adaptor/map.hpp>
|
|
#include <boost/range/join.hpp>
|
|
|
|
#include "compaction/compaction_strategy.hh"
|
|
#include "view_info.hh"
|
|
#include "cql_type_parser.hh"
|
|
#include "db/timeout_clock.hh"
|
|
#include "replica/database.hh"
|
|
#include "data_dictionary/user_types_metadata.hh"
|
|
|
|
#include "index/target_parser.hh"
|
|
#include "lang/lua.hh"
|
|
#include "lang/manager.hh"
|
|
|
|
#include "idl/mutation.dist.hh"
|
|
#include "idl/mutation.dist.impl.hh"
|
|
#include "db/system_keyspace.hh"
|
|
#include "cql3/untyped_result_set.hh"
|
|
#include "cql3/functions/user_aggregate.hh"
|
|
|
|
#include "cql3/CqlParser.hpp"
|
|
#include "cql3/expr/expression.hh"
|
|
#include "cql3/column_identifier.hh"
|
|
#include "cql3/column_specification.hh"
|
|
#include "types/types.hh"
|
|
#include "mutation/async_utils.hh"
|
|
|
|
using namespace db;
|
|
using namespace std::chrono_literals;
|
|
|
|
|
|
static logging::logger diff_logger("schema_diff");
|
|
|
|
|
|
/** system.schema_* tables used to store keyspace/table/type attributes prior to C* 3.0 */
|
|
namespace db {
|
|
namespace {
|
|
const auto set_use_schema_commitlog = schema_builder::register_static_configurator([](const sstring& ks_name, const sstring& cf_name, schema_static_props& props) {
|
|
if (ks_name == schema_tables::NAME) {
|
|
props.enable_schema_commitlog();
|
|
}
|
|
});
|
|
const auto set_group0_table_options =
|
|
schema_builder::register_static_configurator([](const sstring& ks_name, const sstring& cf_name, schema_static_props& props) {
|
|
if (ks_name == schema_tables::NAME) {
|
|
// all schema tables are group0 tables
|
|
props.is_group0_table = true;
|
|
}
|
|
});
|
|
}
|
|
|
|
schema_ctxt::schema_ctxt(const db::config& cfg, std::shared_ptr<data_dictionary::user_types_storage> uts,
|
|
const gms::feature_service& features, replica::database* db)
|
|
: _db(db)
|
|
, _features(features)
|
|
, _extensions(cfg.extensions())
|
|
, _murmur3_partitioner_ignore_msb_bits(cfg.murmur3_partitioner_ignore_msb_bits())
|
|
, _schema_registry_grace_period(cfg.schema_registry_grace_period())
|
|
, _user_types(std::move(uts))
|
|
{}
|
|
|
|
schema_ctxt::schema_ctxt(replica::database& db)
|
|
: schema_ctxt(db.get_config(), db.as_user_types_storage(), db.features(), &db)
|
|
{}
|
|
|
|
schema_ctxt::schema_ctxt(distributed<replica::database>& db)
|
|
: schema_ctxt(db.local())
|
|
{}
|
|
|
|
schema_ctxt::schema_ctxt(distributed<service::storage_proxy>& proxy)
|
|
: schema_ctxt(proxy.local().get_db())
|
|
{}
|
|
|
|
namespace schema_tables {
|
|
|
|
logging::logger slogger("schema_tables");
|
|
|
|
const sstring version = "3";
|
|
|
|
using computed_columns_map = std::unordered_map<bytes, column_computation_ptr>;
|
|
static computed_columns_map get_computed_columns(const schema_mutations& sm);
|
|
|
|
static std::vector<column_definition> create_columns_from_column_rows(
|
|
const schema_ctxt& ctxt,
|
|
const query::result_set& rows, const sstring& keyspace,
|
|
const sstring& table, bool is_super, column_view_virtual is_view_virtual, const computed_columns_map& computed_columns);
|
|
|
|
|
|
static std::vector<index_metadata> create_indices_from_index_rows(const query::result_set& rows,
|
|
const sstring& keyspace,
|
|
const sstring& table);
|
|
|
|
static index_metadata create_index_from_index_row(const query::result_set_row& row,
|
|
sstring keyspace,
|
|
sstring table);
|
|
|
|
static void add_column_to_schema_mutation(schema_ptr, const column_definition&,
|
|
api::timestamp_type, mutation&);
|
|
|
|
static void add_computed_column_to_schema_mutation(schema_ptr, const column_definition&,
|
|
api::timestamp_type, mutation&);
|
|
|
|
static void add_index_to_schema_mutation(schema_ptr table,
|
|
const index_metadata& index, api::timestamp_type timestamp,
|
|
mutation& mutation);
|
|
|
|
static void drop_column_from_schema_mutation(schema_ptr schema_table, schema_ptr table,
|
|
const sstring& column_name, long timestamp,
|
|
std::vector<mutation>&);
|
|
|
|
static void drop_index_from_schema_mutation(schema_ptr table,
|
|
const index_metadata& column, long timestamp,
|
|
std::vector<mutation>& mutations);
|
|
|
|
static future<schema_ptr> create_table_from_table_row(
|
|
distributed<service::storage_proxy>&,
|
|
const query::result_set_row&);
|
|
|
|
static void prepare_builder_from_table_row(const schema_ctxt&, schema_builder&, const query::result_set_row&);
|
|
|
|
using namespace v3;
|
|
|
|
using days = std::chrono::duration<int, std::ratio<24 * 3600>>;
|
|
|
|
static future<> save_system_schema_to_keyspace(cql3::query_processor& qp, const sstring & ksname) {
|
|
auto ks = qp.db().find_keyspace(ksname);
|
|
auto ksm = ks.metadata();
|
|
|
|
// delete old, possibly obsolete entries in schema tables
|
|
co_await coroutine::parallel_for_each(all_table_names(schema_features::full()), [&qp, ksm] (sstring cf) -> future<> {
|
|
auto deletion_timestamp = system_keyspace::schema_creation_timestamp() - 1;
|
|
co_await qp.execute_internal(format("DELETE FROM {}.{} USING TIMESTAMP {} WHERE keyspace_name = ?", NAME, cf,
|
|
deletion_timestamp), { ksm->name() }, cql3::query_processor::cache_internal::yes).discard_result();
|
|
});
|
|
{
|
|
auto mvec = make_create_keyspace_mutations(qp.db().features().cluster_schema_features(), ksm, system_keyspace::schema_creation_timestamp(), true);
|
|
co_await qp.proxy().mutate_locally(std::move(mvec), tracing::trace_state_ptr());
|
|
}
|
|
}
|
|
|
|
future<> save_system_schema(cql3::query_processor& qp) {
|
|
co_await save_system_schema_to_keyspace(qp, schema_tables::NAME);
|
|
// #2514 - make sure "system" is written to system_schema.keyspaces.
|
|
co_await save_system_schema_to_keyspace(qp, system_keyspace::NAME);
|
|
}
|
|
|
|
namespace v3 {
|
|
|
|
schema_ptr keyspaces() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, KEYSPACES), NAME, KEYSPACES,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{},
|
|
// regular columns
|
|
{
|
|
{"durable_writes", boolean_type},
|
|
{"replication", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"keyspace definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr scylla_keyspaces() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, SCYLLA_KEYSPACES), NAME, SCYLLA_KEYSPACES,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{},
|
|
// regular columns
|
|
{
|
|
{"storage_type", utf8_type},
|
|
{"storage_options", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
{"initial_tablets", int32_type},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"scylla-specific information for keyspaces"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr tables() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, TABLES), NAME, TABLES,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"table_name", utf8_type}},
|
|
// regular columns
|
|
{
|
|
{"bloom_filter_fp_chance", double_type},
|
|
{"caching", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
{"comment", utf8_type},
|
|
{"compaction", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
{"compression", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
{"crc_check_chance", double_type},
|
|
// dclocal_read_repair_chance has been deprecated, preserved to be
|
|
// backward compatible
|
|
{"dclocal_read_repair_chance", double_type},
|
|
{"default_time_to_live", int32_type},
|
|
{"extensions", map_type_impl::get_instance(utf8_type, bytes_type, false)},
|
|
{"flags", set_type_impl::get_instance(utf8_type, false)}, // SUPER, COUNTER, DENSE, COMPOUND
|
|
{"gc_grace_seconds", int32_type},
|
|
{"id", uuid_type},
|
|
{"max_index_interval", int32_type},
|
|
{"memtable_flush_period_in_ms", int32_type},
|
|
{"min_index_interval", int32_type},
|
|
// read_repair_chance has been deprecated, preserved to be backward
|
|
// compatible
|
|
{"read_repair_chance", double_type},
|
|
{"speculative_retry", utf8_type},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"table definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
// Holds Scylla-specific table metadata.
|
|
schema_ptr scylla_tables(schema_features features) {
|
|
static thread_local schema_ptr schemas[2]{};
|
|
|
|
bool has_group0_schema_versioning = features.contains(schema_feature::GROUP0_SCHEMA_VERSIONING);
|
|
|
|
schema_ptr& s = schemas[has_group0_schema_versioning];
|
|
if (!s) {
|
|
auto id = generate_legacy_id(NAME, SCYLLA_TABLES);
|
|
auto sb = schema_builder(NAME, SCYLLA_TABLES, std::make_optional(id))
|
|
.with_column("keyspace_name", utf8_type, column_kind::partition_key)
|
|
.with_column("table_name", utf8_type, column_kind::clustering_key)
|
|
.with_column("version", uuid_type);
|
|
|
|
sb.with_column("cdc", map_type_impl::get_instance(utf8_type, utf8_type, false));
|
|
|
|
// PER_TABLE_PARTITIONERS
|
|
sb.with_column("partitioner", utf8_type);
|
|
|
|
if (has_group0_schema_versioning) {
|
|
// If true, this table's latest schema was committed by group 0.
|
|
// In this case `version` column is non-null and will be used for `schema::version()` instead of calculating a hash.
|
|
//
|
|
// If false, this table's latest schema was committed outside group 0 (e.g. during RECOVERY mode).
|
|
// In this case `version` is null and `schema::version()` will be a hash.
|
|
//
|
|
// If null, this is either a system table, or the latest schema was committed
|
|
// before the GROUP0_SCHEMA_VERSIONING feature was enabled (either inside or outside group 0).
|
|
// In this case, for non-system tables, `version` is null and `schema::version()` will be a hash.
|
|
sb.with_column("committed_by_group0", boolean_type);
|
|
}
|
|
sb.with_hash_version();
|
|
s = sb.build();
|
|
}
|
|
|
|
return s;
|
|
}
|
|
|
|
// The "columns" table lists the definitions of all columns in all tables
|
|
// and views. Its schema needs to be identical to the one in Cassandra because
|
|
// it is the API through which drivers inspect the list of columns in a table
|
|
// (e.g., cqlsh's "DESCRIBE TABLE" and "DESCRIBE MATERIALIZED VIEW" get their
|
|
// information from the columns table).
|
|
// The "view_virtual_columns" table is an additional table with exactly the
|
|
// same schema (both are created by columns_schema()), but has a separate
|
|
// list of "virtual" columns. Those are used in materialized views for keeping
|
|
// rows without data alive (see issue #3362). These virtual columns cannot be
|
|
// listed in the regular "columns" table, otherwise the "DESCRIBE MATERIALIZED
|
|
// VIEW" would list them - while it should only list real, selected, columns.
|
|
|
|
static schema_ptr columns_schema(const char* columns_table_name) {
|
|
schema_builder builder(generate_legacy_id(NAME, columns_table_name), NAME, columns_table_name,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"table_name", utf8_type},{"column_name", utf8_type}},
|
|
// regular columns
|
|
{
|
|
{"clustering_order", utf8_type},
|
|
{"column_name_bytes", bytes_type},
|
|
{"kind", utf8_type},
|
|
{"position", int32_type},
|
|
{"type", utf8_type},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"column definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}
|
|
schema_ptr columns() {
|
|
static thread_local auto schema = columns_schema(COLUMNS);
|
|
return schema;
|
|
}
|
|
schema_ptr view_virtual_columns() {
|
|
static thread_local auto schema = columns_schema(VIEW_VIRTUAL_COLUMNS);
|
|
return schema;
|
|
}
|
|
|
|
const std::unordered_set<table_id>& schema_tables_holding_schema_mutations() {
|
|
static const std::unordered_set<table_id> table_ids = [] {
|
|
std::unordered_set<table_id> ids;
|
|
for (auto&& s : {
|
|
tables(),
|
|
views(),
|
|
columns(),
|
|
view_virtual_columns(),
|
|
computed_columns(),
|
|
dropped_columns(),
|
|
indexes(),
|
|
scylla_tables(),
|
|
db::system_keyspace::legacy::column_families(),
|
|
db::system_keyspace::legacy::columns(),
|
|
db::system_keyspace::legacy::triggers()}) {
|
|
SCYLLA_ASSERT(s->clustering_key_size() > 0);
|
|
auto&& first_column_name = s->clustering_column_at(0).name_as_text();
|
|
SCYLLA_ASSERT(first_column_name == "table_name"
|
|
|| first_column_name == "view_name"
|
|
|| first_column_name == "columnfamily_name");
|
|
ids.emplace(s->id());
|
|
}
|
|
return ids;
|
|
}();
|
|
return table_ids;
|
|
};
|
|
|
|
// Computed columns are a special kind of columns. Rather than having their value provided directly
|
|
// by the user, they are computed - possibly from other column values. This table stores which columns
|
|
// for a given table are computed, and a serialized computation itself. Full column information is stored
|
|
// in the `columns` table, this one stores only entries for computed columns, so it will be empty for tables
|
|
// without any computed columns defined in the schema. `computation` is a serialized blob and its format
|
|
// is defined in column_computation.hh and system_schema docs.
|
|
//
|
|
static schema_ptr computed_columns_schema(const char* columns_table_name) {
|
|
schema_builder builder(generate_legacy_id(NAME, columns_table_name), NAME, columns_table_name,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"table_name", utf8_type}, {"column_name", utf8_type}},
|
|
// regular columns
|
|
{{"computation", bytes_type}},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"computed columns"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}
|
|
|
|
schema_ptr computed_columns() {
|
|
static thread_local auto schema = computed_columns_schema(COMPUTED_COLUMNS);
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr dropped_columns() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, DROPPED_COLUMNS), NAME, DROPPED_COLUMNS,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"table_name", utf8_type},{"column_name", utf8_type}},
|
|
// regular columns
|
|
{
|
|
{"dropped_time", timestamp_type},
|
|
{"type", utf8_type},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"dropped column registry"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr triggers() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, TRIGGERS), NAME, TRIGGERS,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"table_name", utf8_type},{"trigger_name", utf8_type}},
|
|
// regular columns
|
|
{
|
|
{"options", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"trigger definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr views() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, VIEWS), NAME, VIEWS,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"view_name", utf8_type}},
|
|
// regular columns
|
|
{
|
|
{"base_table_id", uuid_type},
|
|
{"base_table_name", utf8_type},
|
|
{"where_clause", utf8_type},
|
|
{"bloom_filter_fp_chance", double_type},
|
|
{"caching", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
{"comment", utf8_type},
|
|
{"compaction", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
{"compression", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
{"crc_check_chance", double_type},
|
|
// dclocal_read_repair_chance has been deprecated, preserved to be
|
|
// backward compatible
|
|
{"dclocal_read_repair_chance", double_type},
|
|
{"default_time_to_live", int32_type},
|
|
{"extensions", map_type_impl::get_instance(utf8_type, bytes_type, false)},
|
|
{"gc_grace_seconds", int32_type},
|
|
{"id", uuid_type},
|
|
{"include_all_columns", boolean_type},
|
|
{"max_index_interval", int32_type},
|
|
{"memtable_flush_period_in_ms", int32_type},
|
|
{"min_index_interval", int32_type},
|
|
// read_repair_chance has been deprecated, preserved to be backward
|
|
// compatible
|
|
{"read_repair_chance", double_type},
|
|
{"speculative_retry", utf8_type},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"view definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr indexes() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, INDEXES), NAME, INDEXES,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"table_name", utf8_type},{"index_name", utf8_type}},
|
|
// regular columns
|
|
{
|
|
{"kind", utf8_type},
|
|
{"options", map_type_impl::get_instance(utf8_type, utf8_type, false)},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"secondary index definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr types() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, TYPES), NAME, TYPES,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"type_name", utf8_type}},
|
|
// regular columns
|
|
{
|
|
{"field_names", list_type_impl::get_instance(utf8_type, false)},
|
|
{"field_types", list_type_impl::get_instance(utf8_type, false)},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"user defined type definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr functions() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, FUNCTIONS), NAME, FUNCTIONS,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"function_name", utf8_type}, {"argument_types", list_type_impl::get_instance(utf8_type, false)}},
|
|
// regular columns
|
|
{
|
|
{"argument_names", list_type_impl::get_instance(utf8_type, false)},
|
|
{"body", utf8_type},
|
|
{"language", utf8_type},
|
|
{"return_type", utf8_type},
|
|
{"called_on_null_input", boolean_type},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"user defined function definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr aggregates() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, AGGREGATES), NAME, AGGREGATES,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{{"aggregate_name", utf8_type}, {"argument_types", list_type_impl::get_instance(utf8_type, false)}},
|
|
// regular columns
|
|
{
|
|
{"final_func", utf8_type},
|
|
{"initcond", utf8_type},
|
|
{"return_type", utf8_type},
|
|
{"state_func", utf8_type},
|
|
{"state_type", utf8_type},
|
|
},
|
|
// static columns
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"user defined aggregate definitions"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr scylla_aggregates() {
|
|
static thread_local auto schema = [] {
|
|
schema_builder builder(generate_legacy_id(NAME, SCYLLA_AGGREGATES), NAME, SCYLLA_AGGREGATES,
|
|
// partition key
|
|
{{"keyspace_name", utf8_type}},
|
|
// clustering key
|
|
{
|
|
{"aggregate_name", utf8_type},
|
|
{"argument_types", list_type_impl::get_instance(utf8_type, false)}
|
|
},
|
|
//regular columns
|
|
{
|
|
{"reduce_func", utf8_type},
|
|
{"state_type", utf8_type},
|
|
},
|
|
//static columns,
|
|
{},
|
|
// regular column name type
|
|
utf8_type,
|
|
// comment
|
|
"scylla-specific information for user defined aggregates"
|
|
);
|
|
return builder.with_hash_version().build();
|
|
}();
|
|
return schema;
|
|
}
|
|
|
|
schema_ptr scylla_table_schema_history() {
|
|
static thread_local auto s = [] {
|
|
schema_builder builder(db::system_keyspace::NAME, SCYLLA_TABLE_SCHEMA_HISTORY, generate_legacy_id(db::system_keyspace::NAME, SCYLLA_TABLE_SCHEMA_HISTORY));
|
|
builder.with_column("cf_id", uuid_type, column_kind::partition_key);
|
|
builder.with_column("schema_version", uuid_type, column_kind::clustering_key);
|
|
builder.with_column("column_name", utf8_type, column_kind::clustering_key);
|
|
builder.with_column("clustering_order", utf8_type);
|
|
builder.with_column("column_name_bytes", bytes_type);
|
|
builder.with_column("kind", utf8_type);
|
|
builder.with_column("position", int32_type);
|
|
builder.with_column("type", utf8_type);
|
|
builder.set_comment("Scylla specific table to store a history of column mappings "
|
|
"for each table schema version upon an CREATE TABLE/ALTER TABLE operations");
|
|
return builder.with_hash_version().build(schema_builder::compact_storage::no);
|
|
}();
|
|
return s;
|
|
}
|
|
|
|
}
|
|
|
|
static
|
|
mutation
|
|
redact_columns_for_missing_features(mutation&& m, schema_features features) {
|
|
return std::move(m);
|
|
// The following code is needed if there are new schema features that require redaction.
|
|
#if 0
|
|
if (m.schema()->cf_name() != SCYLLA_TABLES) {
|
|
return std::move(m);
|
|
}
|
|
slogger.debug("adjusting schema_tables mutation due to possible in-progress cluster upgrade");
|
|
// The global schema ptr make sure it will be registered in the schema registry.
|
|
global_schema_ptr redacted_schema{scylla_tables(features)};
|
|
m.upgrade(redacted_schema);
|
|
return std::move(m);
|
|
#endif
|
|
}
|
|
|
|
/**
|
|
* Read schema from system keyspace and calculate MD5 digest of every row, resulting digest
|
|
* will be converted into UUID which would act as content-based version of the schema.
|
|
*/
|
|
future<table_schema_version> calculate_schema_digest(distributed<service::storage_proxy>& proxy, schema_features features, noncopyable_function<bool(std::string_view)> accept_keyspace)
|
|
{
|
|
using mutations_generator = coroutine::experimental::generator<mutation>;
|
|
|
|
auto map = [&proxy, features, accept_keyspace = std::move(accept_keyspace)] (sstring table) mutable -> mutations_generator {
|
|
auto& db = proxy.local().get_db();
|
|
auto rs = co_await db::system_keyspace::query_mutations(db, NAME, table);
|
|
auto s = db.local().find_schema(NAME, table);
|
|
for (auto&& p : rs->partitions()) {
|
|
auto partition_key = value_cast<sstring>(utf8_type->deserialize(::partition_key(p.mut().key()).get_component(*s, 0)));
|
|
if (!accept_keyspace(partition_key)) {
|
|
continue;
|
|
}
|
|
auto mut = co_await unfreeze_gently(p.mut(), s);
|
|
co_yield redact_columns_for_missing_features(std::move(mut), features);
|
|
}
|
|
};
|
|
auto hash = md5_hasher();
|
|
auto tables = all_table_names(features);
|
|
{
|
|
for (auto& table: tables) {
|
|
auto gen_mutations = map(table);
|
|
while (auto mut_opt = co_await gen_mutations()) {
|
|
auto& m = *mut_opt;
|
|
feed_hash_for_schema_digest(hash, m, features);
|
|
if (diff_logger.is_enabled(logging::log_level::trace)) {
|
|
md5_hasher h;
|
|
feed_hash_for_schema_digest(h, m, features);
|
|
diff_logger.trace("Digest {} for {}, compacted={}", h.finalize(), m, compact_for_schema_digest(m));
|
|
}
|
|
}
|
|
}
|
|
co_return utils::UUID_gen::get_name_UUID(hash.finalize());
|
|
}
|
|
}
|
|
|
|
future<table_schema_version> calculate_schema_digest(distributed<service::storage_proxy>& proxy, schema_features features)
|
|
{
|
|
return calculate_schema_digest(proxy, features, std::not_fn(&is_system_keyspace));
|
|
}
|
|
|
|
static thread_local semaphore the_merge_lock {1};
|
|
|
|
future<> merge_lock() {
|
|
if (slogger.is_enabled(log_level::trace)) {
|
|
slogger.trace("merge_lock at {}", current_backtrace());
|
|
}
|
|
return smp::submit_to(0, [] { return the_merge_lock.wait(); });
|
|
}
|
|
|
|
future<> merge_unlock() {
|
|
if (slogger.is_enabled(log_level::trace)) {
|
|
slogger.trace("merge_unlock at {}", current_backtrace());
|
|
}
|
|
return smp::submit_to(0, [] { the_merge_lock.signal(); });
|
|
}
|
|
|
|
future<semaphore_units<>> hold_merge_lock() noexcept {
|
|
SCYLLA_ASSERT(this_shard_id() == 0);
|
|
|
|
if (slogger.is_enabled(log_level::trace)) {
|
|
slogger.trace("hold_merge_lock at {}", current_backtrace());
|
|
}
|
|
return get_units(the_merge_lock, 1);
|
|
}
|
|
|
|
future<> with_merge_lock(noncopyable_function<future<> ()> func) {
|
|
co_await merge_lock();
|
|
std::exception_ptr ep;
|
|
try {
|
|
co_await func();
|
|
} catch (...) {
|
|
ep = std::current_exception();
|
|
}
|
|
co_await merge_unlock();
|
|
if (ep) {
|
|
std::rethrow_exception(std::move(ep));
|
|
}
|
|
}
|
|
|
|
future<> update_schema_version_and_announce(sharded<db::system_keyspace>& sys_ks, distributed<service::storage_proxy>& proxy, schema_features features, std::optional<table_schema_version> version_from_group0) {
|
|
auto uuid = version_from_group0 ? *version_from_group0 : co_await calculate_schema_digest(proxy, features);
|
|
co_await sys_ks.local().update_schema_version(uuid);
|
|
co_await proxy.local().get_db().invoke_on_all([uuid] (replica::database& db) {
|
|
db.update_version(uuid);
|
|
});
|
|
slogger.info("Schema version changed to {}", uuid);
|
|
}
|
|
|
|
future<std::optional<table_schema_version>> get_group0_schema_version(db::system_keyspace& sys_ks) {
|
|
auto version = co_await sys_ks.get_scylla_local_param_as<utils::UUID>("group0_schema_version");
|
|
if (!version) {
|
|
co_return std::nullopt;
|
|
}
|
|
co_return table_schema_version{*version};
|
|
}
|
|
|
|
future<> recalculate_schema_version(sharded<db::system_keyspace>& sys_ks, distributed<service::storage_proxy>& proxy, gms::feature_service& feat) {
|
|
co_await with_merge_lock([&] () -> future<> {
|
|
auto version_from_group0 = co_await get_group0_schema_version(sys_ks.local());
|
|
co_await update_schema_version_and_announce(sys_ks, proxy, feat.cluster_schema_features(), version_from_group0);
|
|
});
|
|
}
|
|
|
|
future<std::vector<canonical_mutation>> convert_schema_to_mutations(distributed<service::storage_proxy>& proxy, schema_features features)
|
|
{
|
|
auto map = [&proxy, features] (sstring table) -> future<std::vector<canonical_mutation>> {
|
|
auto& db = proxy.local().get_db();
|
|
auto rs = co_await db::system_keyspace::query_mutations(db, NAME, table);
|
|
auto s = db.local().find_schema(NAME, table);
|
|
std::vector<canonical_mutation> results;
|
|
results.reserve(rs->partitions().size());
|
|
for (auto&& p : rs->partitions()) {
|
|
auto mut = co_await unfreeze_gently(p.mut(), s);
|
|
auto partition_key = value_cast<sstring>(utf8_type->deserialize(mut.key().get_component(*s, 0)));
|
|
if (is_system_keyspace(partition_key)) {
|
|
continue;
|
|
}
|
|
mut = redact_columns_for_missing_features(std::move(mut), features);
|
|
results.emplace_back(co_await make_canonical_mutation_gently(mut));
|
|
}
|
|
co_return results;
|
|
};
|
|
auto reduce = [] (auto&& result, auto&& mutations) {
|
|
std::move(mutations.begin(), mutations.end(), std::back_inserter(result));
|
|
return std::move(result);
|
|
};
|
|
co_return co_await map_reduce(all_table_names(features), map, std::vector<canonical_mutation>{}, reduce);
|
|
}
|
|
|
|
std::vector<mutation>
|
|
adjust_schema_for_schema_features(std::vector<mutation> schema, schema_features features) {
|
|
for (auto& m : schema) {
|
|
m = redact_columns_for_missing_features(std::move(m), features);
|
|
}
|
|
return schema;
|
|
}
|
|
|
|
static
|
|
future<mutation> query_partition_mutation(service::storage_proxy& proxy,
|
|
schema_ptr s,
|
|
lw_shared_ptr<query::read_command> cmd,
|
|
partition_key pkey)
|
|
{
|
|
auto dk = dht::decorate_key(*s, pkey);
|
|
auto range = dht::partition_range::make_singular(dk);
|
|
auto res_hit_rate = co_await proxy.query_mutations_locally(s, std::move(cmd), range, db::no_timeout, tracing::trace_state_ptr{});
|
|
auto&& [res, hit_rate] = res_hit_rate;
|
|
auto&& partitions = res->partitions();
|
|
if (partitions.size() == 0) {
|
|
co_return mutation(s, std::move(dk));
|
|
} else if (partitions.size() == 1) {
|
|
co_return co_await unfreeze_gently(partitions[0].mut(), s);
|
|
} else {
|
|
auto&& ex = std::make_exception_ptr(std::invalid_argument("Results must have at most one partition"));
|
|
co_return coroutine::exception(std::move(ex));
|
|
}
|
|
}
|
|
|
|
future<schema_result_value_type>
|
|
read_schema_partition_for_keyspace(distributed<service::storage_proxy>& proxy, sstring schema_table_name, sstring keyspace_name)
|
|
{
|
|
auto schema = proxy.local().get_db().local().find_schema(NAME, schema_table_name);
|
|
auto keyspace_key = dht::decorate_key(*schema,
|
|
partition_key::from_singular(*schema, keyspace_name));
|
|
auto rs = co_await db::system_keyspace::query(proxy.local().get_db(), NAME, schema_table_name, keyspace_key);
|
|
co_return schema_result_value_type{keyspace_name, std::move(rs)};
|
|
}
|
|
|
|
future<mutation>
|
|
read_schema_partition_for_table(distributed<service::storage_proxy>& proxy, schema_ptr schema, const sstring& keyspace_name, const sstring& table_name)
|
|
{
|
|
SCYLLA_ASSERT(schema_tables_holding_schema_mutations().contains(schema->id()));
|
|
auto keyspace_key = partition_key::from_singular(*schema, keyspace_name);
|
|
auto clustering_range = query::clustering_range(clustering_key_prefix::from_clustering_prefix(
|
|
*schema, exploded_clustering_prefix({utf8_type->decompose(table_name)})));
|
|
auto slice = partition_slice_builder(*schema)
|
|
.with_range(std::move(clustering_range))
|
|
.build();
|
|
auto cmd = make_lw_shared<query::read_command>(schema->id(), schema->version(), std::move(slice), proxy.local().get_max_result_size(slice),
|
|
query::tombstone_limit::max, query::row_limit(query::max_rows));
|
|
co_return co_await query_partition_mutation(proxy.local(), std::move(schema), std::move(cmd), std::move(keyspace_key));
|
|
}
|
|
|
|
future<mutation>
|
|
read_keyspace_mutation(distributed<service::storage_proxy>& proxy, const sstring& keyspace_name) {
|
|
schema_ptr s = keyspaces();
|
|
auto key = partition_key::from_singular(*s, keyspace_name);
|
|
auto slice = s->full_slice();
|
|
auto cmd = make_lw_shared<query::read_command>(s->id(), s->version(), std::move(slice), proxy.local().get_max_result_size(slice), query::tombstone_limit::max);
|
|
co_return co_await query_partition_mutation(proxy.local(), std::move(s), std::move(cmd), std::move(key));
|
|
}
|
|
|
|
mutation compact_for_schema_digest(const mutation& m) {
|
|
// Cassandra is skipping tombstones from digest calculation
|
|
// to avoid disagreements due to tombstone GC.
|
|
// See https://issues.apache.org/jira/browse/CASSANDRA-6862.
|
|
// We achieve similar effect with compact_for_compaction().
|
|
mutation m_compacted(m);
|
|
m_compacted.partition().compact_for_compaction_drop_tombstones_unconditionally(*m.schema(), m.decorated_key());
|
|
return m_compacted;
|
|
}
|
|
|
|
void feed_hash_for_schema_digest(hasher& h, const mutation& m, schema_features features) {
|
|
auto compacted = compact_for_schema_digest(m);
|
|
if (!features.contains<schema_feature::DIGEST_INSENSITIVE_TO_EXPIRY>() || !compacted.partition().empty()) {
|
|
feed_hash(h, compacted);
|
|
}
|
|
}
|
|
|
|
/// Helper function which fills a given mutation with column information
|
|
/// provided the corresponding column_definition object.
|
|
static void fill_column_info(const schema& table,
|
|
const clustering_key& ckey,
|
|
const column_definition& column,
|
|
api::timestamp_type timestamp,
|
|
ttl_opt ttl,
|
|
mutation& m) {
|
|
auto order = "NONE";
|
|
if (column.is_clustering_key()) {
|
|
order = "ASC";
|
|
}
|
|
auto type = column.type;
|
|
if (type->is_reversed()) {
|
|
type = type->underlying_type();
|
|
if (column.is_clustering_key()) {
|
|
order = "DESC";
|
|
}
|
|
}
|
|
int32_t pos = -1;
|
|
if (column.is_primary_key()) {
|
|
pos = table.position(column);
|
|
}
|
|
|
|
m.set_clustered_cell(ckey, "column_name_bytes", data_value(column.name()), timestamp, ttl);
|
|
m.set_clustered_cell(ckey, "kind", serialize_kind(column.kind), timestamp, ttl);
|
|
m.set_clustered_cell(ckey, "position", pos, timestamp, ttl);
|
|
m.set_clustered_cell(ckey, "clustering_order", sstring(order), timestamp, ttl);
|
|
m.set_clustered_cell(ckey, "type", type->as_cql3_type().to_string(), timestamp, ttl);
|
|
}
|
|
|
|
future<> store_column_mapping(distributed<service::storage_proxy>& proxy, schema_ptr s, bool with_ttl) {
|
|
// Skip "system*" tables -- only user-related tables are relevant
|
|
if (static_cast<std::string_view>(s->ks_name()).starts_with(db::system_keyspace::NAME)) {
|
|
co_return;
|
|
}
|
|
schema_ptr history_tbl = scylla_table_schema_history();
|
|
|
|
// Insert the new column mapping for a given schema version (without TTL)
|
|
std::vector<mutation> muts;
|
|
partition_key pk = partition_key::from_exploded(*history_tbl, {uuid_type->decompose(s->id().uuid())});
|
|
|
|
ttl_opt ttl;
|
|
if (with_ttl) {
|
|
ttl = gc_clock::duration(DEFAULT_GC_GRACE_SECONDS);
|
|
}
|
|
// Use one timestamp for all mutations for the ease of debugging
|
|
const auto ts = api::new_timestamp();
|
|
for (const auto& cdef : s->static_and_regular_columns()) {
|
|
mutation m(history_tbl, pk);
|
|
auto ckey = clustering_key::from_exploded(*history_tbl, {uuid_type->decompose(s->version().uuid()),
|
|
utf8_type->decompose(cdef.name_as_text())});
|
|
fill_column_info(*s, ckey, cdef, ts, ttl, m);
|
|
muts.emplace_back(std::move(m));
|
|
}
|
|
co_await proxy.local().mutate_locally(std::move(muts), tracing::trace_state_ptr());
|
|
}
|
|
|
|
future<lw_shared_ptr<query::result_set>> extract_scylla_specific_keyspace_info(distributed<service::storage_proxy>& proxy, const schema_result_value_type& partition) {
|
|
lw_shared_ptr<query::result_set> scylla_specific_rs;
|
|
if (proxy.local().local_db().has_schema(NAME, SCYLLA_KEYSPACES)) {
|
|
auto&& rs = partition.second;
|
|
if (rs->empty()) {
|
|
co_await coroutine::return_exception(std::runtime_error("query result has no rows"));
|
|
}
|
|
auto&& row = rs->row(0);
|
|
auto keyspace_name = row.get_nonnull<sstring>("keyspace_name");
|
|
auto keyspace_key = dht::decorate_key(*scylla_keyspaces(), partition_key::from_singular(*scylla_keyspaces(), keyspace_name));
|
|
scylla_specific_rs = co_await db::system_keyspace::query(proxy.local().get_db(), NAME, SCYLLA_KEYSPACES, keyspace_key);
|
|
}
|
|
co_return scylla_specific_rs;
|
|
}
|
|
|
|
template<typename V>
|
|
static std::vector<V> get_list(const query::result_set_row& row, const sstring& name);
|
|
|
|
// Create types for a given keyspace. This takes care of topologically sorting user defined types.
|
|
template <typename T> static future<std::vector<user_type>> create_types(keyspace_metadata& ks, T&& range) {
|
|
cql_type_parser::raw_builder builder(ks);
|
|
std::unordered_set<bytes> names;
|
|
for (const query::result_set_row& row : range) {
|
|
auto name = row.get_nonnull<sstring>("type_name");
|
|
names.insert(to_bytes(name));
|
|
builder.add(std::move(name), get_list<sstring>(row, "field_names"), get_list<sstring>(row, "field_types"));
|
|
}
|
|
// Add user types that use any of the above types. From the
|
|
// database point of view they haven't changed since the content
|
|
// of system.types is the same for them. The runtime objects in
|
|
// the other hand now point to out of date types, so we need to
|
|
// recreate them.
|
|
for (const auto& p : ks.user_types().get_all_types()) {
|
|
const user_type& t = p.second;
|
|
if (names.contains(t->_name)) {
|
|
continue;
|
|
}
|
|
for (const auto& name : names) {
|
|
if (t->references_user_type(t->_keyspace, name)) {
|
|
std::vector<sstring> field_types;
|
|
for (const data_type& f : t->field_types()) {
|
|
field_types.push_back(f->as_cql3_type().to_string());
|
|
}
|
|
builder.add(t->get_name_as_string(), t->string_field_names(), std::move(field_types));
|
|
}
|
|
}
|
|
}
|
|
co_return co_await builder.build();
|
|
}
|
|
|
|
future<std::vector<user_type>> create_types(replica::database& db, const std::vector<const query::result_set_row*>& rows) {
|
|
std::vector<user_type> ret;
|
|
for (auto i = rows.begin(), e = rows.end(); i != e;) {
|
|
const auto &row = *i;
|
|
auto keyspace = row->get_nonnull<sstring>("keyspace_name");
|
|
auto next = std::find_if(i, e, [&keyspace](const query::result_set_row* r) {
|
|
return r->get_nonnull<sstring>("keyspace_name") != keyspace;
|
|
});
|
|
auto ks = db.find_keyspace(keyspace).metadata();
|
|
auto v = co_await create_types(*ks, boost::make_iterator_range(i, next) | boost::adaptors::indirected);
|
|
ret.insert(ret.end(), std::make_move_iterator(v.begin()), std::make_move_iterator(v.end()));
|
|
i = next;
|
|
}
|
|
co_return ret;
|
|
}
|
|
|
|
std::vector<data_type> read_arg_types(replica::database& db, const query::result_set_row& row, const sstring& keyspace) {
|
|
std::vector<data_type> arg_types;
|
|
for (const auto& arg : get_list<sstring>(row, "argument_types")) {
|
|
arg_types.push_back(db::cql_type_parser::parse(keyspace, arg, db.user_types()));
|
|
}
|
|
return arg_types;
|
|
}
|
|
|
|
future<shared_ptr<cql3::functions::user_function>> create_func(replica::database& db, const query::result_set_row& row) {
|
|
cql3::functions::function_name name{
|
|
row.get_nonnull<sstring>("keyspace_name"), row.get_nonnull<sstring>("function_name")};
|
|
auto arg_types = read_arg_types(db, row, name.keyspace);
|
|
data_type return_type = db::cql_type_parser::parse(name.keyspace, row.get_nonnull<sstring>("return_type"), db.user_types());
|
|
|
|
// FIXME: We already computed the bitcode in
|
|
// create_function_statement, but it is not clear how to get it
|
|
// here. In this point in the code we only get what was saved in
|
|
// system_schema.functions, and we don't want to store the bitcode
|
|
// If this was not the replica that the client connected to we do
|
|
// have to produce bitcode in at least one shard. Right now this
|
|
// gets run in each shard.
|
|
|
|
auto arg_names = get_list<sstring>(row, "argument_names");
|
|
auto body = row.get_nonnull<sstring>("body");
|
|
auto language = row.get_nonnull<sstring>("language");
|
|
auto ctx = co_await db.lang().create(language, name.name, arg_names, body);
|
|
if (!ctx) {
|
|
throw std::runtime_error(format("Unsupported language for UDF: {}", language));
|
|
}
|
|
co_return ::make_shared<cql3::functions::user_function>(std::move(name), std::move(arg_types), std::move(arg_names),
|
|
std::move(body), language, std::move(return_type),
|
|
row.get_nonnull<bool>("called_on_null_input"), std::move(*ctx));
|
|
}
|
|
|
|
shared_ptr<cql3::functions::user_aggregate> create_aggregate(replica::database& db, const query::result_set_row& row, const query::result_set_row* scylla_row, cql3::functions::change_batch& batch) {
|
|
cql3::functions::function_name name{
|
|
row.get_nonnull<sstring>("keyspace_name"), row.get_nonnull<sstring>("aggregate_name")};
|
|
auto arg_types = read_arg_types(db, row, name.keyspace);
|
|
data_type state_type = db::cql_type_parser::parse(name.keyspace, row.get_nonnull<sstring>("state_type"), db.user_types());
|
|
sstring sfunc = row.get_nonnull<sstring>("state_func");
|
|
auto ffunc = row.get<sstring>("final_func");
|
|
auto initcond_str = row.get<sstring>("initcond");
|
|
|
|
auto find_func = [&batch] (sstring ks, sstring name, const std::vector<data_type>& arg_types) {
|
|
// first search current batch because aggregate may depend on functions
|
|
// we're currently adding
|
|
auto fname = cql3::functions::function_name{std::move(ks), std::move(name)};
|
|
auto func = batch.find(fname, arg_types);
|
|
if (!func) {
|
|
func = cql3::functions::instance().find(fname, arg_types);
|
|
}
|
|
return func;
|
|
};
|
|
|
|
std::vector<data_type> acc_types{state_type};
|
|
acc_types.insert(acc_types.end(), arg_types.begin(), arg_types.end());
|
|
auto state_func = dynamic_pointer_cast<cql3::functions::scalar_function>(find_func(name.keyspace, sfunc, acc_types));
|
|
if (!state_func) {
|
|
throw std::runtime_error(format("State function {} needed by aggregate {} not found", sfunc, name.name));
|
|
}
|
|
if (state_func->return_type() != state_type) {
|
|
throw std::runtime_error(format("State function {} needed by aggregate {} doesn't return state", sfunc, name.name));
|
|
}
|
|
|
|
::shared_ptr<cql3::functions::scalar_function> reduce_func = nullptr;
|
|
if (scylla_row) {
|
|
auto rfunc_name = scylla_row->get<sstring>("reduce_func");
|
|
auto rfunc = find_func(name.keyspace, rfunc_name.value(), {state_type, state_type});
|
|
if (!rfunc) {
|
|
throw std::runtime_error(format("Reduce function {} needed by aggregate {} not found", rfunc_name.value(), name.name));
|
|
}
|
|
reduce_func = dynamic_pointer_cast<cql3::functions::scalar_function>(rfunc);
|
|
if (!reduce_func) {
|
|
throw std::runtime_error(format("Reduce function {} needed by aggregate {} is not a scalar function", rfunc_name.value(), name.name));
|
|
}
|
|
}
|
|
|
|
::shared_ptr<cql3::functions::scalar_function> final_func = nullptr;
|
|
if (ffunc) {
|
|
final_func = dynamic_pointer_cast<cql3::functions::scalar_function>(
|
|
find_func(name.keyspace, ffunc.value(), {state_type}));
|
|
if (!final_func) {
|
|
throw std::runtime_error(format("Final function {} needed by aggregate {} not found", ffunc.value(), name.name));
|
|
}
|
|
}
|
|
|
|
bytes_opt initcond = std::nullopt;
|
|
if (initcond_str) {
|
|
// In general using the default dialect is wrong, but here the database is communicating with itself,
|
|
// not the user, so any dialect should work.
|
|
auto expr = cql3::util::do_with_parser(*initcond_str, cql3::dialect{}, std::mem_fn(&cql3_parser::CqlParser::term));
|
|
auto dummy_ident = ::make_shared<cql3::column_identifier>("", true);
|
|
auto column_spec = make_lw_shared<cql3::column_specification>("", "", dummy_ident, state_type);
|
|
auto raw = cql3::expr::evaluate(prepare_expression(expr, db.as_data_dictionary(), "", nullptr, {column_spec}), cql3::query_options::DEFAULT);
|
|
initcond = std::move(raw).to_bytes_opt();
|
|
}
|
|
return ::make_shared<cql3::functions::user_aggregate>(name, initcond, std::move(state_func), std::move(reduce_func), std::move(final_func));
|
|
}
|
|
|
|
template<typename... Args>
|
|
void set_cell_or_clustered(mutation& m, const clustering_key & ckey, Args && ...args) {
|
|
m.set_clustered_cell(ckey, std::forward<Args>(args)...);
|
|
}
|
|
|
|
template<typename... Args>
|
|
void set_cell_or_clustered(mutation& m, const exploded_clustering_prefix & ckey, Args && ...args) {
|
|
m.set_cell(ckey, std::forward<Args>(args)...);
|
|
}
|
|
|
|
template<typename Map>
|
|
static atomic_cell_or_collection
|
|
make_map_mutation(const Map& map,
|
|
const column_definition& column,
|
|
api::timestamp_type timestamp,
|
|
noncopyable_function<map_type_impl::native_type::value_type (const typename Map::value_type&)> f)
|
|
{
|
|
auto column_type = static_pointer_cast<const map_type_impl>(column.type);
|
|
auto ktyp = column_type->get_keys_type();
|
|
auto vtyp = column_type->get_values_type();
|
|
|
|
if (column_type->is_multi_cell()) {
|
|
collection_mutation_description mut;
|
|
|
|
for (auto&& entry : map) {
|
|
auto te = f(entry);
|
|
mut.cells.emplace_back(ktyp->decompose(data_value(te.first)), atomic_cell::make_live(*vtyp, timestamp, vtyp->decompose(data_value(te.second)), atomic_cell::collection_member::yes));
|
|
}
|
|
|
|
return mut.serialize(*column_type);
|
|
} else {
|
|
map_type_impl::native_type tmp;
|
|
tmp.reserve(map.size());
|
|
std::transform(map.begin(), map.end(), std::inserter(tmp, tmp.end()), std::move(f));
|
|
return atomic_cell::make_live(*column.type, timestamp, column_type->decompose(make_map_value(column_type, std::move(tmp))));
|
|
}
|
|
}
|
|
|
|
template<typename Map>
|
|
static atomic_cell_or_collection
|
|
make_map_mutation(const Map& map,
|
|
const column_definition& column,
|
|
api::timestamp_type timestamp)
|
|
{
|
|
return make_map_mutation(map, column, timestamp, [](auto&& p) {
|
|
return std::make_pair(data_value(p.first), data_value(p.second));
|
|
});
|
|
}
|
|
|
|
template<typename K, typename Map>
|
|
static void store_map(mutation& m, const K& ckey, const bytes& name, api::timestamp_type timestamp, const Map& map) {
|
|
auto s = m.schema();
|
|
auto column = s->get_column_definition(name);
|
|
SCYLLA_ASSERT(column);
|
|
set_cell_or_clustered(m, ckey, *column, make_map_mutation(map, *column, timestamp));
|
|
}
|
|
|
|
/*
|
|
* Keyspace metadata serialization/deserialization.
|
|
*/
|
|
|
|
std::vector<mutation> make_create_keyspace_mutations(schema_features features, lw_shared_ptr<keyspace_metadata> keyspace, api::timestamp_type timestamp, bool with_tables_and_types_and_functions)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
schema_ptr s = keyspaces();
|
|
auto pkey = partition_key::from_singular(*s, keyspace->name());
|
|
mutation m(s, pkey);
|
|
auto ckey = clustering_key_prefix::make_empty();
|
|
m.set_cell(ckey, "durable_writes", keyspace->durable_writes(), timestamp);
|
|
|
|
auto map = keyspace->strategy_options();
|
|
map["class"] = keyspace->strategy_name();
|
|
store_map(m, ckey, "replication", timestamp, map);
|
|
|
|
if (features.contains<schema_feature::SCYLLA_KEYSPACES>()) {
|
|
schema_ptr scylla_keyspaces_s = scylla_keyspaces();
|
|
mutation scylla_m(scylla_keyspaces_s, pkey); // pkey can be reused, it's identical in both tables
|
|
auto& storage_options = keyspace->get_storage_options();
|
|
sstring storage_type(storage_options.type_string());
|
|
auto storage_map = storage_options.to_map();
|
|
if (!storage_map.empty()) {
|
|
scylla_m.set_cell(ckey, "storage_type", storage_type, timestamp);
|
|
store_map(scylla_m, ckey, "storage_options", timestamp, storage_map);
|
|
}
|
|
auto initial_tablets = keyspace->initial_tablets();
|
|
if (initial_tablets.has_value()) {
|
|
scylla_m.set_cell(ckey, "initial_tablets", int32_t(*initial_tablets), timestamp);
|
|
}
|
|
mutations.emplace_back(std::move(scylla_m));
|
|
}
|
|
|
|
mutations.emplace_back(std::move(m));
|
|
|
|
if (with_tables_and_types_and_functions) {
|
|
for (const auto& kv : keyspace->user_types().get_all_types()) {
|
|
add_type_to_schema_mutation(kv.second, timestamp, mutations);
|
|
}
|
|
for (auto&& s : keyspace->cf_meta_data() | std::views::values) {
|
|
add_table_or_view_to_schema_mutation(s, timestamp, true, mutations);
|
|
}
|
|
}
|
|
return mutations;
|
|
}
|
|
|
|
std::vector<mutation> make_drop_keyspace_mutations(schema_features features, lw_shared_ptr<keyspace_metadata> keyspace, api::timestamp_type timestamp)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
for (auto&& schema_table : all_tables(schema_features::full())) {
|
|
auto pkey = partition_key::from_exploded(*schema_table, {utf8_type->decompose(keyspace->name())});
|
|
mutation m{schema_table, pkey};
|
|
m.partition().apply(tombstone{timestamp, gc_clock::now()});
|
|
mutations.emplace_back(std::move(m));
|
|
}
|
|
if (features.contains<schema_feature::SCYLLA_KEYSPACES>()) {
|
|
auto pkey = partition_key::from_exploded(*scylla_keyspaces(), {utf8_type->decompose(keyspace->name())});
|
|
mutation km{scylla_keyspaces(), pkey};
|
|
km.partition().apply(tombstone{timestamp, gc_clock::now()});
|
|
mutations.emplace_back(std::move(km));
|
|
}
|
|
return mutations;
|
|
}
|
|
|
|
/**
|
|
* Deserialize only Keyspace attributes without nested tables or types
|
|
*
|
|
* @param partition Keyspace attributes in serialized form
|
|
*/
|
|
future<lw_shared_ptr<keyspace_metadata>> create_keyspace_from_schema_partition(distributed<service::storage_proxy>& proxy,
|
|
const schema_result_value_type& result,
|
|
lw_shared_ptr<query::result_set> scylla_specific_rs)
|
|
{
|
|
auto&& rs = result.second;
|
|
if (rs->empty()) {
|
|
throw std::runtime_error("query result has no rows");
|
|
}
|
|
auto&& row = rs->row(0);
|
|
auto keyspace_name = row.get_nonnull<sstring>("keyspace_name");
|
|
// We get called from multiple shards with result set originating on only one of them.
|
|
// Cannot use copying accessors for "deep" types like map, because we will hit shared_ptr asserts
|
|
// (or screw up shared pointers)
|
|
const auto& replication = row.get_nonnull<map_type_impl::native_type>("replication");
|
|
|
|
std::map<sstring, sstring> strategy_options;
|
|
for (auto& p : replication) {
|
|
strategy_options.emplace(value_cast<sstring>(p.first), value_cast<sstring>(p.second));
|
|
}
|
|
auto strategy_name = strategy_options["class"];
|
|
strategy_options.erase("class");
|
|
bool durable_writes = row.get_nonnull<bool>("durable_writes");
|
|
|
|
data_dictionary::storage_options storage_opts;
|
|
std::optional<unsigned> initial_tablets;
|
|
// Scylla-specific row will only be present if SCYLLA_KEYSPACES schema feature is available in the cluster
|
|
if (scylla_specific_rs) {
|
|
if (!scylla_specific_rs->empty()) {
|
|
auto row = scylla_specific_rs->row(0);
|
|
auto storage_type = row.get<sstring>("storage_type");
|
|
auto options = row.get<map_type_impl::native_type>("storage_options");
|
|
if (storage_type && options) {
|
|
std::map<sstring, sstring> values;
|
|
for (const auto& entry : *options) {
|
|
values.emplace(value_cast<sstring>(entry.first), value_cast<sstring>(entry.second));
|
|
}
|
|
storage_opts.value = data_dictionary::storage_options::from_map(std::string_view(*storage_type), values);
|
|
}
|
|
initial_tablets = row.get<int>("initial_tablets");
|
|
}
|
|
}
|
|
co_return keyspace_metadata::new_keyspace(keyspace_name, strategy_name, strategy_options, initial_tablets, durable_writes, storage_opts);
|
|
}
|
|
|
|
template<typename V>
|
|
static std::vector<V> get_list(const query::result_set_row& row, const sstring& name) {
|
|
std::vector<V> list;
|
|
|
|
const auto& values = row.get_nonnull<const list_type_impl::native_type&>(name);
|
|
for (auto&& v : values) {
|
|
list.emplace_back(value_cast<V>(v));
|
|
};
|
|
|
|
return list;
|
|
}
|
|
|
|
future<std::vector<user_type>> create_types_from_schema_partition(
|
|
keyspace_metadata& ks, lw_shared_ptr<query::result_set> result) {
|
|
co_return co_await create_types(ks, result->rows());
|
|
}
|
|
|
|
seastar::future<std::vector<shared_ptr<cql3::functions::user_function>>> create_functions_from_schema_partition(
|
|
replica::database& db, lw_shared_ptr<query::result_set> result) {
|
|
std::vector<shared_ptr<cql3::functions::user_function>> ret;
|
|
for (const auto& row : result->rows()) {
|
|
ret.emplace_back(co_await create_func(db, row));
|
|
}
|
|
co_return ret;
|
|
}
|
|
|
|
std::vector<shared_ptr<cql3::functions::user_aggregate>> create_aggregates_from_schema_partition(
|
|
replica::database& db, lw_shared_ptr<query::result_set> result, lw_shared_ptr<query::result_set> scylla_result, cql3::functions::change_batch& batch) {
|
|
std::unordered_multimap<sstring, const query::result_set_row*> scylla_aggs;
|
|
if (scylla_result) {
|
|
for (const auto& scylla_row : scylla_result->rows()) {
|
|
auto scylla_agg_name = scylla_row.get_nonnull<sstring>("aggregate_name");
|
|
scylla_aggs.emplace(scylla_agg_name, &scylla_row);
|
|
}
|
|
}
|
|
|
|
std::vector<shared_ptr<cql3::functions::user_aggregate>> ret;
|
|
for (const auto& row : result->rows()) {
|
|
auto agg_name = row.get_nonnull<sstring>("aggregate_name");
|
|
auto agg_args = read_arg_types(db, row, row.get_nonnull<sstring>("keyspace_name"));
|
|
const query::result_set_row *scylla_row_ptr = nullptr;
|
|
for (auto [it, end] = scylla_aggs.equal_range(agg_name); it != end; ++it) {
|
|
auto scylla_agg_args = read_arg_types(db, *it->second, it->second->get_nonnull<sstring>("keyspace_name"));
|
|
if (agg_args == scylla_agg_args) {
|
|
scylla_row_ptr = it->second;
|
|
break;
|
|
}
|
|
}
|
|
ret.emplace_back(create_aggregate(db, row, scylla_row_ptr, batch));
|
|
}
|
|
return ret;
|
|
}
|
|
|
|
/*
|
|
* User type metadata serialization/deserialization
|
|
*/
|
|
|
|
template<typename Func, typename T, typename... Args>
|
|
static atomic_cell_or_collection
|
|
make_list_mutation(const std::vector<T, Args...>& values,
|
|
const column_definition& column,
|
|
api::timestamp_type timestamp,
|
|
Func&& f)
|
|
{
|
|
auto column_type = static_pointer_cast<const list_type_impl>(column.type);
|
|
auto vtyp = column_type->get_elements_type();
|
|
|
|
if (column_type->is_multi_cell()) {
|
|
collection_mutation_description m;
|
|
m.cells.reserve(values.size());
|
|
m.tomb.timestamp = timestamp - 1;
|
|
m.tomb.deletion_time = gc_clock::now();
|
|
|
|
for (auto&& value : values) {
|
|
auto dv = f(value);
|
|
auto uuid = utils::UUID_gen::get_time_UUID_bytes();
|
|
m.cells.emplace_back(
|
|
bytes(reinterpret_cast<const int8_t*>(uuid.data()), uuid.size()),
|
|
atomic_cell::make_live(*vtyp, timestamp, vtyp->decompose(std::move(dv)), atomic_cell::collection_member::yes));
|
|
}
|
|
|
|
return m.serialize(*column_type);
|
|
} else {
|
|
list_type_impl::native_type tmp;
|
|
tmp.reserve(values.size());
|
|
std::transform(values.begin(), values.end(), std::back_inserter(tmp), f);
|
|
return atomic_cell::make_live(*column.type, timestamp, column_type->decompose(make_list_value(column_type, std::move(tmp))));
|
|
}
|
|
}
|
|
|
|
void add_type_to_schema_mutation(user_type type, api::timestamp_type timestamp, std::vector<mutation>& mutations)
|
|
{
|
|
schema_ptr s = types();
|
|
auto pkey = partition_key::from_singular(*s, type->_keyspace);
|
|
auto ckey = clustering_key::from_singular(*s, type->get_name_as_string());
|
|
mutation m{s, pkey};
|
|
|
|
auto field_names_column = s->get_column_definition("field_names");
|
|
auto field_names = make_list_mutation(type->field_names(), *field_names_column, timestamp, [](auto&& name) {
|
|
return utf8_type->deserialize(name);
|
|
});
|
|
m.set_clustered_cell(ckey, *field_names_column, std::move(field_names));
|
|
|
|
auto field_types_column = s->get_column_definition("field_types");
|
|
auto field_types = make_list_mutation(type->field_types(), *field_types_column, timestamp, [](auto&& type) {
|
|
return data_value(type->as_cql3_type().to_string());
|
|
});
|
|
m.set_clustered_cell(ckey, *field_types_column, std::move(field_types));
|
|
|
|
mutations.emplace_back(std::move(m));
|
|
}
|
|
|
|
std::vector<mutation> make_create_type_mutations(lw_shared_ptr<keyspace_metadata> keyspace, user_type type, api::timestamp_type timestamp)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
add_type_to_schema_mutation(type, timestamp, mutations);
|
|
return mutations;
|
|
}
|
|
|
|
std::vector<mutation> make_drop_type_mutations(lw_shared_ptr<keyspace_metadata> keyspace, user_type type, api::timestamp_type timestamp)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
schema_ptr s = types();
|
|
auto pkey = partition_key::from_singular(*s, type->_keyspace);
|
|
auto ckey = clustering_key::from_singular(*s, type->get_name_as_string());
|
|
mutation m{s, pkey};
|
|
m.partition().apply_delete(*s, ckey, tombstone(timestamp, gc_clock::now()));
|
|
mutations.emplace_back(std::move(m));
|
|
|
|
return mutations;
|
|
}
|
|
|
|
/*
|
|
* UDF metadata serialization/deserialization.
|
|
*/
|
|
|
|
static std::pair<mutation, clustering_key> get_mutation(schema_ptr s, const cql3::functions::function& func) {
|
|
auto name = func.name();
|
|
auto pkey = partition_key::from_singular(*s, name.keyspace);
|
|
|
|
list_type_impl::native_type arg_types;
|
|
for (const auto& arg_type : func.arg_types()) {
|
|
arg_types.emplace_back(arg_type->as_cql3_type().to_string());
|
|
}
|
|
auto arg_list_type = list_type_impl::get_instance(utf8_type, false);
|
|
data_value arg_types_val = make_list_value(arg_list_type, std::move(arg_types));
|
|
auto ckey = clustering_key::from_exploded(
|
|
*s, {utf8_type->decompose(name.name), arg_list_type->decompose(arg_types_val)});
|
|
mutation m{s, pkey};
|
|
return {std::move(m), std::move(ckey)};
|
|
}
|
|
|
|
std::vector<mutation> make_create_function_mutations(shared_ptr<cql3::functions::user_function> func,
|
|
api::timestamp_type timestamp) {
|
|
schema_ptr s = functions();
|
|
auto p = get_mutation(s, *func);
|
|
mutation& m = p.first;
|
|
clustering_key& ckey = p.second;
|
|
auto argument_names_column = s->get_column_definition("argument_names");
|
|
auto argument_names = make_list_mutation(func->arg_names(), *argument_names_column, timestamp, [] (auto&& name) {
|
|
return name;
|
|
});
|
|
m.set_clustered_cell(ckey, *argument_names_column, std::move(argument_names));
|
|
m.set_clustered_cell(ckey, "body", func->body(), timestamp);
|
|
m.set_clustered_cell(ckey, "language", func->language(), timestamp);
|
|
m.set_clustered_cell(ckey, "return_type", func->return_type()->as_cql3_type().to_string(), timestamp);
|
|
m.set_clustered_cell(ckey, "called_on_null_input", func->called_on_null_input(), timestamp);
|
|
return make_mutation_vector(std::move(m));
|
|
}
|
|
|
|
std::vector<mutation> make_drop_function_mutations(schema_ptr s, const cql3::functions::function& func, api::timestamp_type timestamp) {
|
|
auto p = get_mutation(s, func);
|
|
mutation& m = p.first;
|
|
clustering_key& ckey = p.second;
|
|
m.partition().apply_delete(*s, ckey, tombstone(timestamp, gc_clock::now()));
|
|
return make_mutation_vector(std::move(m));
|
|
}
|
|
|
|
std::vector<mutation> make_drop_function_mutations(shared_ptr<cql3::functions::user_function> func, api::timestamp_type timestamp) {
|
|
return make_drop_function_mutations(functions(), *func, timestamp);
|
|
}
|
|
|
|
/*
|
|
* UDA metadata serialization/deserialization
|
|
*/
|
|
|
|
static std::pair<mutation, clustering_key> get_mutation(schema_ptr s, const cql3::functions::user_aggregate& aggregate) {
|
|
auto name = aggregate.name();
|
|
auto pkey = partition_key::from_singular(*s, name.keyspace);
|
|
|
|
list_type_impl::native_type arg_types;
|
|
for (const auto& arg_type : aggregate.arg_types()) {
|
|
arg_types.emplace_back(arg_type->as_cql3_type().to_string());
|
|
}
|
|
auto arg_list_type = list_type_impl::get_instance(utf8_type, false);
|
|
data_value arg_types_val = make_list_value(arg_list_type, std::move(arg_types));
|
|
auto ckey = clustering_key::from_exploded(
|
|
*s, {utf8_type->decompose(name.name), arg_list_type->decompose(arg_types_val)});
|
|
mutation m{s, pkey};
|
|
return {std::move(m), std::move(ckey)};
|
|
}
|
|
|
|
std::vector<mutation> make_create_aggregate_mutations(schema_features features, shared_ptr<cql3::functions::user_aggregate> aggregate, api::timestamp_type timestamp) {
|
|
schema_ptr s = aggregates();
|
|
auto p = get_mutation(s, *aggregate);
|
|
mutation& m = p.first;
|
|
clustering_key& ckey = p.second;
|
|
std::vector<mutation> muts;
|
|
|
|
data_type state_type = aggregate->sfunc()->arg_types()[0];
|
|
if (aggregate->has_finalfunc()) {
|
|
m.set_clustered_cell(ckey, "final_func", aggregate->finalfunc()->name().name, timestamp);
|
|
}
|
|
if (aggregate->initcond()) {
|
|
m.set_clustered_cell(ckey, "initcond", state_type->deserialize(*aggregate->initcond()).to_parsable_string(), timestamp);
|
|
}
|
|
m.set_clustered_cell(ckey, "return_type", aggregate->return_type()->as_cql3_type().to_string(), timestamp);
|
|
m.set_clustered_cell(ckey, "state_func", aggregate->sfunc()->name().name, timestamp);
|
|
m.set_clustered_cell(ckey, "state_type", state_type->as_cql3_type().to_string(), timestamp);
|
|
muts.emplace_back(std::move(m));
|
|
|
|
if (features.contains<schema_feature::SCYLLA_AGGREGATES>() && aggregate->is_reducible()) {
|
|
schema_ptr sa_schema = scylla_aggregates();
|
|
auto sa_p = get_mutation(sa_schema, *aggregate);
|
|
mutation& sa_mut = sa_p.first;
|
|
clustering_key& sa_ckey = sa_p.second;
|
|
sa_mut.set_clustered_cell(sa_ckey, "reduce_func", aggregate->reducefunc()->name().name, timestamp);
|
|
sa_mut.set_clustered_cell(sa_ckey, "state_type", state_type->as_cql3_type().to_string(), timestamp);
|
|
|
|
muts.emplace_back(std::move(sa_mut));
|
|
}
|
|
|
|
return muts;
|
|
}
|
|
|
|
std::vector<mutation> make_drop_aggregate_mutations(schema_features features, shared_ptr<cql3::functions::user_aggregate> aggregate, api::timestamp_type timestamp) {
|
|
auto muts = make_drop_function_mutations(aggregates(), *aggregate, timestamp);
|
|
if (features.contains<schema_feature::SCYLLA_AGGREGATES>() && aggregate->is_reducible()) {
|
|
auto scylla_muts = make_drop_function_mutations(scylla_aggregates(), *aggregate, timestamp);
|
|
std::move(scylla_muts.begin(), scylla_muts.end(), std::back_inserter(muts));
|
|
}
|
|
|
|
return muts;
|
|
}
|
|
|
|
/*
|
|
* Table metadata serialization/deserialization.
|
|
*/
|
|
|
|
/// Returns mutations which when applied to the database will cause all schema changes
|
|
/// which create or alter the table with a given name, made with timestamps smaller than t,
|
|
/// have no effect. Used when overriding schema to shadow concurrent conflicting schema changes.
|
|
/// Shouldn't be needed if schema changes are serialized with RAFT.
|
|
static schema_mutations make_table_deleting_mutations(const sstring& ks, const sstring& table, bool is_view, api::timestamp_type t) {
|
|
tombstone tomb;
|
|
|
|
// Generate neutral mutations if t == api::min_timestamp
|
|
if (t > api::min_timestamp) {
|
|
tomb = tombstone(t - 1, gc_clock::now());
|
|
}
|
|
|
|
auto tables_m_s = is_view ? views() : tables();
|
|
mutation tables_m{tables_m_s, partition_key::from_singular(*tables_m_s, ks)};
|
|
{
|
|
auto ckey = clustering_key::from_singular(*tables_m_s, table);
|
|
tables_m.partition().apply_delete(*tables_m_s, ckey, tomb);
|
|
}
|
|
|
|
mutation scylla_tables_m{scylla_tables(), partition_key::from_singular(*scylla_tables(), ks)};
|
|
{
|
|
auto ckey = clustering_key::from_singular(*scylla_tables(), table);
|
|
scylla_tables_m.partition().apply_delete(*scylla_tables(), ckey, tomb);
|
|
}
|
|
|
|
auto make_drop_columns = [&] (const schema_ptr& s) {
|
|
mutation m{s, partition_key::from_singular(*s, ks)};
|
|
auto ckey = clustering_key::from_exploded(*s, {utf8_type->decompose(table)});
|
|
m.partition().apply_delete(*s, ckey, tomb);
|
|
return m;
|
|
};
|
|
|
|
return schema_mutations(std::move(tables_m),
|
|
make_drop_columns(columns()),
|
|
make_drop_columns(view_virtual_columns()),
|
|
make_drop_columns(computed_columns()),
|
|
mutation(indexes(), partition_key::from_singular(*indexes(), ks)),
|
|
make_drop_columns(dropped_columns()),
|
|
std::move(scylla_tables_m)
|
|
);
|
|
}
|
|
|
|
std::vector<mutation> make_create_table_mutations(schema_ptr table, api::timestamp_type timestamp)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
add_table_or_view_to_schema_mutation(table, timestamp, true, mutations);
|
|
make_table_deleting_mutations(table->ks_name(), table->cf_name(), table->is_view(), timestamp)
|
|
.copy_to(mutations);
|
|
return mutations;
|
|
}
|
|
|
|
static void add_table_params_to_mutations(mutation& m, const clustering_key& ckey, schema_ptr table, api::timestamp_type timestamp) {
|
|
m.set_clustered_cell(ckey, "bloom_filter_fp_chance", table->bloom_filter_fp_chance(), timestamp);
|
|
m.set_clustered_cell(ckey, "comment", table->comment(), timestamp);
|
|
m.set_clustered_cell(ckey, "default_time_to_live", gc_clock::as_int32(table->default_time_to_live()), timestamp);
|
|
m.set_clustered_cell(ckey, "gc_grace_seconds", gc_clock::as_int32(table->gc_grace_seconds()), timestamp);
|
|
m.set_clustered_cell(ckey, "max_index_interval", table->max_index_interval(), timestamp);
|
|
m.set_clustered_cell(ckey, "memtable_flush_period_in_ms", table->memtable_flush_period(), timestamp);
|
|
m.set_clustered_cell(ckey, "min_index_interval", table->min_index_interval(), timestamp);
|
|
m.set_clustered_cell(ckey, "speculative_retry", table->speculative_retry().to_sstring(), timestamp);
|
|
m.set_clustered_cell(ckey, "crc_check_chance", table->crc_check_chance(), timestamp);
|
|
|
|
store_map(m, ckey, "caching", timestamp, table->caching_options().to_map());
|
|
|
|
{
|
|
auto map = table->compaction_strategy_options();
|
|
map["class"] = sstables::compaction_strategy::name(table->configured_compaction_strategy());
|
|
store_map(m, ckey, "compaction", timestamp, map);
|
|
}
|
|
|
|
store_map(m, ckey, "compression", timestamp, table->get_compressor_params().get_options());
|
|
|
|
std::map<sstring, bytes> map;
|
|
|
|
if (!table->extensions().empty()) {
|
|
for (auto& p : table->extensions()) {
|
|
map.emplace(p.first, p.second->serialize());
|
|
}
|
|
}
|
|
|
|
store_map(m, ckey, "extensions", timestamp, map);
|
|
}
|
|
|
|
static data_type expand_user_type(data_type);
|
|
|
|
static std::vector<data_type> expand_user_types(const std::vector<data_type>& types) {
|
|
std::vector<data_type> result;
|
|
result.reserve(types.size());
|
|
std::transform(types.begin(), types.end(), std::back_inserter(result), &expand_user_type);
|
|
return result;
|
|
}
|
|
|
|
static data_type expand_user_type(data_type original) {
|
|
if (original->is_user_type()) {
|
|
return tuple_type_impl::get_instance(
|
|
expand_user_types(
|
|
static_pointer_cast<const user_type_impl>(
|
|
original)->field_types()));
|
|
}
|
|
if (original->is_tuple()) {
|
|
return tuple_type_impl::get_instance(
|
|
expand_user_types(
|
|
static_pointer_cast<
|
|
const tuple_type_impl>(
|
|
original)->all_types()));
|
|
}
|
|
if (original->is_reversed()) {
|
|
return reversed_type_impl::get_instance(
|
|
expand_user_type(original->underlying_type()));
|
|
}
|
|
|
|
if (original->is_collection()) {
|
|
|
|
auto ct = static_pointer_cast<const collection_type_impl>(original);
|
|
|
|
if (ct->is_list()) {
|
|
return list_type_impl::get_instance(
|
|
expand_user_type(ct->value_comparator()),
|
|
ct->is_multi_cell());
|
|
}
|
|
if (ct->is_map()) {
|
|
return map_type_impl::get_instance(
|
|
expand_user_type(ct->name_comparator()),
|
|
expand_user_type(ct->value_comparator()),
|
|
ct->is_multi_cell());
|
|
}
|
|
if (ct->is_set()) {
|
|
return set_type_impl::get_instance(
|
|
expand_user_type(ct->name_comparator()),
|
|
ct->is_multi_cell());
|
|
}
|
|
}
|
|
|
|
return original;
|
|
}
|
|
|
|
static void add_dropped_column_to_schema_mutation(schema_ptr table, const sstring& name, const schema::dropped_column& column, api::timestamp_type timestamp, mutation& m) {
|
|
auto ckey = clustering_key::from_exploded(*dropped_columns(), {utf8_type->decompose(table->cf_name()), utf8_type->decompose(name)});
|
|
db_clock::time_point tp(db_clock::duration(column.timestamp));
|
|
m.set_clustered_cell(ckey, "dropped_time", tp, timestamp);
|
|
|
|
/*
|
|
* From origin:
|
|
* we never store actual UDT names in dropped column types (so that we can safely drop types if nothing refers to
|
|
* them anymore), so before storing dropped columns in schema we expand UDTs to tuples. See expandUserTypes method.
|
|
* Because of that, we can safely pass Types.none() to parse()
|
|
*/
|
|
m.set_clustered_cell(ckey, "type", expand_user_type(column.type)->as_cql3_type().to_string(), timestamp);
|
|
}
|
|
|
|
mutation make_scylla_tables_mutation(schema_ptr table, api::timestamp_type timestamp) {
|
|
schema_ptr s = tables();
|
|
auto pkey = partition_key::from_singular(*s, table->ks_name());
|
|
auto ckey = clustering_key::from_singular(*s, table->cf_name());
|
|
mutation m(scylla_tables(), pkey);
|
|
m.set_clustered_cell(ckey, "version", table->version().uuid(), timestamp);
|
|
// Since 4.0, we stopped using cdc column in scylla tables. Extensions are
|
|
// used instead. Since we stopped reading this column in commit 861c7b5, we
|
|
// can now keep it always empty.
|
|
auto& cdc_cdef = *scylla_tables()->get_column_definition("cdc");
|
|
m.set_clustered_cell(ckey, cdc_cdef, atomic_cell::make_dead(timestamp, gc_clock::now()));
|
|
if (table->has_custom_partitioner()) {
|
|
m.set_clustered_cell(ckey, "partitioner", table->get_partitioner().name(), timestamp);
|
|
} else {
|
|
// Avoid storing anything for default partitioner, so we don't end up with
|
|
// different digests on different nodes due to the other node redacting
|
|
// the partitioner column when the per_table_partitioners cluster feature is disabled.
|
|
//
|
|
// Tombstones are not considered for schema digest, so this is okay (and
|
|
// needed in order for disabling of per_table_partitioners to have effect).
|
|
auto& cdef = *scylla_tables()->get_column_definition("partitioner");
|
|
m.set_clustered_cell(ckey, cdef, atomic_cell::make_dead(timestamp, gc_clock::now()));
|
|
}
|
|
return m;
|
|
}
|
|
|
|
static schema_mutations make_table_mutations(schema_ptr table, api::timestamp_type timestamp, bool with_columns_and_triggers)
|
|
{
|
|
// When adding new schema properties, don't set cells for default values so that
|
|
// both old and new nodes will see the same version during rolling upgrades.
|
|
|
|
// For property that can be null (and can be changed), we insert tombstones, to make sure
|
|
// we don't keep a property the user has removed
|
|
schema_ptr s = tables();
|
|
auto pkey = partition_key::from_singular(*s, table->ks_name());
|
|
mutation m{s, pkey};
|
|
auto ckey = clustering_key::from_singular(*s, table->cf_name());
|
|
m.set_clustered_cell(ckey, "id", table->id().uuid(), timestamp);
|
|
|
|
auto scylla_tables_mutation = make_scylla_tables_mutation(table, timestamp);
|
|
|
|
list_type_impl::native_type flags;
|
|
if (table->is_super()) {
|
|
flags.emplace_back("super");
|
|
}
|
|
if (table->is_dense()) {
|
|
flags.emplace_back("dense");
|
|
}
|
|
if (table->is_compound()) {
|
|
flags.emplace_back("compound");
|
|
}
|
|
if (table->is_counter()) {
|
|
flags.emplace_back("counter");
|
|
}
|
|
|
|
m.set_clustered_cell(ckey, "flags", make_list_value(s->get_column_definition("flags")->type, flags), timestamp);
|
|
|
|
add_table_params_to_mutations(m, ckey, table, timestamp);
|
|
|
|
mutation columns_mutation(columns(), pkey);
|
|
mutation computed_columns_mutation(computed_columns(), pkey);
|
|
mutation dropped_columns_mutation(dropped_columns(), pkey);
|
|
mutation indices_mutation(indexes(), pkey);
|
|
|
|
if (with_columns_and_triggers) {
|
|
for (auto&& column : table->v3().all_columns()) {
|
|
if (column.is_view_virtual()) {
|
|
throw std::logic_error("view_virtual column found in non-view table");
|
|
}
|
|
add_column_to_schema_mutation(table, column, timestamp, columns_mutation);
|
|
if (column.is_computed()) {
|
|
add_computed_column_to_schema_mutation(table, column, timestamp, computed_columns_mutation);
|
|
}
|
|
}
|
|
for (auto&& index : table->indices()) {
|
|
add_index_to_schema_mutation(table, index, timestamp, indices_mutation);
|
|
}
|
|
// TODO: triggers
|
|
|
|
for (auto&& e : table->dropped_columns()) {
|
|
add_dropped_column_to_schema_mutation(table, e.first, e.second, timestamp, dropped_columns_mutation);
|
|
}
|
|
}
|
|
|
|
return schema_mutations{std::move(m),
|
|
std::move(columns_mutation),
|
|
std::nullopt,
|
|
std::move(computed_columns_mutation),
|
|
std::move(indices_mutation),
|
|
std::move(dropped_columns_mutation),
|
|
std::move(scylla_tables_mutation)};
|
|
}
|
|
|
|
void add_table_or_view_to_schema_mutation(schema_ptr s, api::timestamp_type timestamp, bool with_columns, std::vector<mutation>& mutations)
|
|
{
|
|
make_schema_mutations(s, timestamp, with_columns).copy_to(mutations);
|
|
}
|
|
|
|
static schema_mutations make_view_mutations(view_ptr view, api::timestamp_type timestamp, bool with_columns);
|
|
static void make_drop_table_or_view_mutations(schema_ptr schema_table, schema_ptr table_or_view, api::timestamp_type timestamp, std::vector<mutation>& mutations);
|
|
|
|
static void make_update_indices_mutations(
|
|
replica::database& db,
|
|
schema_ptr old_table,
|
|
schema_ptr new_table,
|
|
api::timestamp_type timestamp,
|
|
std::vector<mutation>& mutations)
|
|
{
|
|
mutation indices_mutation(indexes(), partition_key::from_singular(*indexes(), old_table->ks_name()));
|
|
|
|
auto diff = difference(old_table->all_indices(), new_table->all_indices());
|
|
|
|
// indices that are no longer needed
|
|
for (auto&& name : diff.entries_only_on_left) {
|
|
const index_metadata& index = old_table->all_indices().at(name);
|
|
drop_index_from_schema_mutation(old_table, index, timestamp, mutations);
|
|
schema_ptr view;
|
|
try {
|
|
view = db.find_schema(old_table->ks_name(), secondary_index::index_table_name(name));
|
|
db.get_notifier().before_drop_column_family(*view, mutations, timestamp);
|
|
} catch (const replica::no_such_column_family&) {
|
|
on_internal_error(slogger, format("Could not find schema for dropped index {}.{}",
|
|
old_table->ks_name(), secondary_index::index_table_name(name)));
|
|
}
|
|
make_drop_table_or_view_mutations(views(), view, timestamp, mutations);
|
|
}
|
|
|
|
auto add_index = [&](const sstring& name) -> view_ptr {
|
|
const index_metadata& index = new_table->all_indices().at(name);
|
|
add_index_to_schema_mutation(new_table, index, timestamp, indices_mutation);
|
|
auto& cf = db.find_column_family(new_table);
|
|
auto view = cf.get_index_manager().create_view_for_index(index);
|
|
auto view_mutations = make_view_mutations(view, timestamp, true);
|
|
view_mutations.copy_to(mutations);
|
|
return view;
|
|
};
|
|
|
|
// old indices with updated attributes
|
|
for (auto&& name : diff.entries_differing) {
|
|
add_index(name);
|
|
}
|
|
// Newly added indices. Because these are newly created tables (views),
|
|
// we need to call the before_create_column_family callback for them.
|
|
// If we don't, among other things *tablets* will not be created for
|
|
// these new views.
|
|
// The callbacks must be called in a Seastar thread, which means that
|
|
// *this* function must be called in a Seastar thread when creating an
|
|
// index.
|
|
for (auto&& name : diff.entries_only_on_right) {
|
|
auto view = add_index(name);
|
|
auto ksm = db.find_keyspace(new_table->ks_name()).metadata();
|
|
db.get_notifier().before_create_column_family(*ksm, *view, mutations, timestamp);
|
|
}
|
|
|
|
mutations.emplace_back(std::move(indices_mutation));
|
|
}
|
|
|
|
static void add_drop_column_to_mutations(schema_ptr table, const sstring& name, const schema::dropped_column& dc, api::timestamp_type timestamp, std::vector<mutation>& mutations) {
|
|
schema_ptr s = dropped_columns();
|
|
auto pkey = partition_key::from_singular(*s, table->ks_name());
|
|
auto ckey = clustering_key::from_exploded(*s, {utf8_type->decompose(table->cf_name()), utf8_type->decompose(name)});
|
|
mutation m(s, pkey);
|
|
add_dropped_column_to_schema_mutation(table, name, dc, timestamp, m);
|
|
mutations.emplace_back(std::move(m));
|
|
}
|
|
|
|
static void make_update_columns_mutations(schema_ptr old_table,
|
|
schema_ptr new_table,
|
|
api::timestamp_type timestamp,
|
|
std::vector<mutation>& mutations) {
|
|
mutation columns_mutation(columns(), partition_key::from_singular(*columns(), old_table->ks_name()));
|
|
mutation view_virtual_columns_mutation(view_virtual_columns(), partition_key::from_singular(*columns(), old_table->ks_name()));
|
|
mutation computed_columns_mutation(computed_columns(), partition_key::from_singular(*columns(), old_table->ks_name()));
|
|
|
|
auto diff = difference(old_table->v3().columns_by_name(), new_table->v3().columns_by_name());
|
|
|
|
// columns that are no longer needed
|
|
for (auto&& name : diff.entries_only_on_left) {
|
|
// Thrift only knows about the REGULAR ColumnDefinition type, so don't consider other type
|
|
// are being deleted just because they are not here.
|
|
const column_definition& column = *old_table->v3().columns_by_name().at(name);
|
|
if (column.is_view_virtual()) {
|
|
drop_column_from_schema_mutation(view_virtual_columns(), old_table, column.name_as_text(), timestamp, mutations);
|
|
} else {
|
|
drop_column_from_schema_mutation(columns(), old_table, column.name_as_text(), timestamp, mutations);
|
|
}
|
|
if (column.is_computed()) {
|
|
drop_column_from_schema_mutation(computed_columns(), old_table, column.name_as_text(), timestamp, mutations);
|
|
}
|
|
}
|
|
|
|
// newly added columns and old columns with updated attributes
|
|
for (auto&& name : boost::range::join(diff.entries_differing, diff.entries_only_on_right)) {
|
|
const column_definition& column = *new_table->v3().columns_by_name().at(name);
|
|
if (column.is_view_virtual()) {
|
|
add_column_to_schema_mutation(new_table, column, timestamp, view_virtual_columns_mutation);
|
|
} else {
|
|
add_column_to_schema_mutation(new_table, column, timestamp, columns_mutation);
|
|
}
|
|
if (column.is_computed()) {
|
|
add_computed_column_to_schema_mutation(new_table, column, timestamp, computed_columns_mutation);
|
|
}
|
|
}
|
|
|
|
mutations.emplace_back(std::move(columns_mutation));
|
|
mutations.emplace_back(std::move(view_virtual_columns_mutation));
|
|
mutations.emplace_back(std::move(computed_columns_mutation));
|
|
|
|
// dropped columns
|
|
auto dc_diff = difference(old_table->dropped_columns(), new_table->dropped_columns());
|
|
|
|
// newly dropped columns
|
|
// columns added then dropped again
|
|
for (auto& name : boost::range::join(dc_diff.entries_differing, dc_diff.entries_only_on_right)) {
|
|
add_drop_column_to_mutations(new_table, name, new_table->dropped_columns().at(name), timestamp, mutations);
|
|
}
|
|
}
|
|
|
|
std::vector<mutation> make_update_table_mutations(replica::database& db,
|
|
lw_shared_ptr<keyspace_metadata> keyspace,
|
|
schema_ptr old_table,
|
|
schema_ptr new_table,
|
|
api::timestamp_type timestamp)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
add_table_or_view_to_schema_mutation(new_table, timestamp, false, mutations);
|
|
make_update_indices_mutations(db, old_table, new_table, timestamp, mutations);
|
|
make_update_columns_mutations(std::move(old_table), std::move(new_table), timestamp, mutations);
|
|
|
|
warn(unimplemented::cause::TRIGGERS);
|
|
return mutations;
|
|
}
|
|
|
|
static void make_drop_table_or_view_mutations(schema_ptr schema_table,
|
|
schema_ptr table_or_view,
|
|
api::timestamp_type timestamp,
|
|
std::vector<mutation>& mutations) {
|
|
auto pkey = partition_key::from_singular(*schema_table, table_or_view->ks_name());
|
|
mutation m{schema_table, pkey};
|
|
auto ckey = clustering_key::from_singular(*schema_table, table_or_view->cf_name());
|
|
m.partition().apply_delete(*schema_table, ckey, tombstone(timestamp, gc_clock::now()));
|
|
mutations.emplace_back(m);
|
|
for (auto& column : table_or_view->v3().all_columns()) {
|
|
if (column.is_view_virtual()) {
|
|
drop_column_from_schema_mutation(view_virtual_columns(), table_or_view, column.name_as_text(), timestamp, mutations);
|
|
} else {
|
|
drop_column_from_schema_mutation(columns(), table_or_view, column.name_as_text(), timestamp, mutations);
|
|
}
|
|
if (column.is_computed()) {
|
|
drop_column_from_schema_mutation(computed_columns(), table_or_view, column.name_as_text(), timestamp, mutations);
|
|
}
|
|
}
|
|
for (auto& column : table_or_view->dropped_columns() | std::views::keys) {
|
|
drop_column_from_schema_mutation(dropped_columns(), table_or_view, column, timestamp, mutations);
|
|
}
|
|
mutation m1{scylla_tables(), pkey};
|
|
m1.partition().apply_delete(*scylla_tables(), ckey, tombstone(timestamp, gc_clock::now()));
|
|
mutations.emplace_back(m1);
|
|
}
|
|
|
|
std::vector<mutation> make_drop_table_mutations(lw_shared_ptr<keyspace_metadata> keyspace, schema_ptr table, api::timestamp_type timestamp)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
make_drop_table_or_view_mutations(tables(), std::move(table), timestamp, mutations);
|
|
|
|
return mutations;
|
|
}
|
|
|
|
future<schema_mutations> read_table_mutations(distributed<service::storage_proxy>& proxy, const qualified_name& table, schema_ptr s)
|
|
{
|
|
auto&& [cf_m, col_m, vv_col_m, c_col_m, dropped_m, idx_m, st_m] = co_await coroutine::all(
|
|
[&] { return read_schema_partition_for_table(proxy, s, table.keyspace_name, table.table_name); },
|
|
[&] { return read_schema_partition_for_table(proxy, columns(), table.keyspace_name, table.table_name); },
|
|
[&] { return read_schema_partition_for_table(proxy, view_virtual_columns(), table.keyspace_name, table.table_name); },
|
|
[&] { return read_schema_partition_for_table(proxy, computed_columns(), table.keyspace_name, table.table_name); },
|
|
[&] { return read_schema_partition_for_table(proxy, dropped_columns(), table.keyspace_name, table.table_name); },
|
|
[&] { return read_schema_partition_for_table(proxy, indexes(), table.keyspace_name, table.table_name); },
|
|
[&] { return read_schema_partition_for_table(proxy, scylla_tables(), table.keyspace_name, table.table_name); }
|
|
);
|
|
co_return schema_mutations{std::move(cf_m), std::move(col_m), std::move(vv_col_m), std::move(c_col_m), std::move(idx_m), std::move(dropped_m), std::move(st_m)};
|
|
}
|
|
|
|
future<schema_ptr> create_table_from_name(distributed<service::storage_proxy>& proxy, const sstring& keyspace, const sstring& table)
|
|
{
|
|
auto qn = qualified_name(keyspace, table);
|
|
auto sm = co_await read_table_mutations(proxy, qn, tables());
|
|
if (!sm.live()) {
|
|
co_await coroutine::return_exception(std::runtime_error(format("{}:{} not found in the schema definitions keyspace.", qn.keyspace_name, qn.table_name)));
|
|
}
|
|
co_return create_table_from_mutations(proxy, std::move(sm));
|
|
}
|
|
|
|
// Limit concurrency of user tables to prevent stalls.
|
|
// See https://github.com/scylladb/scylladb/issues/11574
|
|
// Note: we aim at providing enough concurrency to utilize
|
|
// the cpu while operations are blocked on disk I/O
|
|
// and or filesystem calls, e.g. fsync.
|
|
constexpr size_t max_concurrent = 8;
|
|
|
|
/**
|
|
* Deserialize tables from low-level schema representation, all of them belong to the same keyspace
|
|
*
|
|
* @return map containing name of the table and its metadata for faster lookup
|
|
*/
|
|
future<std::map<sstring, schema_ptr>> create_tables_from_tables_partition(distributed<service::storage_proxy>& proxy, const schema_result::mapped_type& result)
|
|
{
|
|
auto tables = std::map<sstring, schema_ptr>();
|
|
co_await max_concurrent_for_each(result->rows().begin(), result->rows().end(), max_concurrent, [&] (const query::result_set_row& row) -> future<> {
|
|
schema_ptr cfm = co_await create_table_from_table_row(proxy, row);
|
|
tables.emplace(cfm->cf_name(), std::move(cfm));
|
|
});
|
|
co_return std::move(tables);
|
|
}
|
|
|
|
/**
|
|
* Deserialize table metadata from low-level representation
|
|
*
|
|
* @return Metadata deserialized from schema
|
|
*/
|
|
static future<schema_ptr> create_table_from_table_row(distributed<service::storage_proxy>& proxy, const query::result_set_row& row)
|
|
{
|
|
auto ks_name = row.get_nonnull<sstring>("keyspace_name");
|
|
auto cf_name = row.get_nonnull<sstring>("table_name");
|
|
return create_table_from_name(proxy, ks_name, cf_name);
|
|
}
|
|
|
|
static void prepare_builder_from_table_row(const schema_ctxt& ctxt, schema_builder& builder, const query::result_set_row& table_row)
|
|
{
|
|
// These row reads have been purposefully reordered to match the origin counterpart. For easier matching.
|
|
if (auto val = table_row.get<double>("bloom_filter_fp_chance")) {
|
|
builder.set_bloom_filter_fp_chance(*val);
|
|
} else {
|
|
builder.set_bloom_filter_fp_chance(builder.get_bloom_filter_fp_chance());
|
|
}
|
|
|
|
if (auto map = get_map<sstring, sstring>(table_row, "caching")) {
|
|
builder.set_caching_options(caching_options::from_map(*map));
|
|
}
|
|
|
|
if (auto val = table_row.get<sstring>("comment")) {
|
|
builder.set_comment(*val);
|
|
}
|
|
|
|
if (auto opt_map = get_map<sstring, sstring>(table_row, "compaction")) {
|
|
auto &map = *opt_map;
|
|
auto i = map.find("class");
|
|
if (i != map.end()) {
|
|
try {
|
|
builder.set_compaction_strategy(sstables::compaction_strategy::type(i->second));
|
|
map.erase(i);
|
|
} catch (const exceptions::configuration_exception& e) {
|
|
// If compaction strategy class isn't supported, fallback to incremental.
|
|
slogger.warn("Falling back to incremental compaction strategy after the problem: {}", e.what());
|
|
builder.set_compaction_strategy(sstables::compaction_strategy_type::incremental);
|
|
}
|
|
}
|
|
if (map.contains("max_threshold")) {
|
|
builder.set_max_compaction_threshold(std::stoi(map["max_threshold"]));
|
|
}
|
|
if (map.contains("min_threshold")) {
|
|
builder.set_min_compaction_threshold(std::stoi(map["min_threshold"]));
|
|
}
|
|
if (map.contains("enabled")) {
|
|
builder.set_compaction_enabled(boost::algorithm::iequals(map["enabled"], "true"));
|
|
}
|
|
|
|
builder.set_compaction_strategy_options(std::move(map));
|
|
}
|
|
|
|
if (auto map = get_map<sstring, sstring>(table_row, "compression")) {
|
|
compression_parameters cp(*map);
|
|
builder.set_compressor_params(cp);
|
|
}
|
|
|
|
if (auto val = table_row.get<int32_t>("default_time_to_live")) {
|
|
builder.set_default_time_to_live(gc_clock::duration(*val));
|
|
}
|
|
|
|
if (auto val = get_map<sstring, bytes>(table_row, "extensions")) {
|
|
auto &map = *val;
|
|
schema::extensions_map result;
|
|
auto& exts = ctxt.extensions().schema_extensions();
|
|
for (auto&p : map) {
|
|
auto i = exts.find(p.first);
|
|
if (i != exts.end()) {
|
|
try {
|
|
auto ep = i->second(p.second);
|
|
if (ep) {
|
|
result.emplace(p.first, std::move(ep));
|
|
}
|
|
continue;
|
|
} catch (...) {
|
|
slogger.warn("Error parsing extension {}: {}", p.first, std::current_exception());
|
|
}
|
|
}
|
|
|
|
// unknown. we should still preserve it.
|
|
class placeholder : public schema_extension {
|
|
bytes _bytes;
|
|
public:
|
|
placeholder(bytes bytes)
|
|
: _bytes(std::move(bytes)) {
|
|
}
|
|
bytes serialize() const override {
|
|
return _bytes;
|
|
}
|
|
virtual bool is_placeholder() const override {
|
|
return true;
|
|
}
|
|
};
|
|
|
|
result.emplace(p.first, ::make_shared<placeholder>(p.second));
|
|
}
|
|
builder.set_extensions(std::move(result));
|
|
}
|
|
|
|
if (auto val = table_row.get<int32_t>("gc_grace_seconds")) {
|
|
builder.set_gc_grace_seconds(*val);
|
|
}
|
|
|
|
if (auto val = table_row.get<int>("min_index_interval")) {
|
|
builder.set_min_index_interval(*val);
|
|
}
|
|
|
|
if (auto val = table_row.get<int32_t>("memtable_flush_period_in_ms")) {
|
|
builder.set_memtable_flush_period(*val);
|
|
}
|
|
|
|
if (auto val = table_row.get<int>("max_index_interval")) {
|
|
builder.set_max_index_interval(*val);
|
|
}
|
|
|
|
if (auto val = table_row.get<double>("crc_check_chance")) {
|
|
builder.set_crc_check_chance(*val);
|
|
}
|
|
|
|
if (auto val = table_row.get<sstring>("speculative_retry")) {
|
|
builder.set_speculative_retry(*val);
|
|
}
|
|
}
|
|
|
|
schema_ptr create_table_from_mutations(const schema_ctxt& ctxt, schema_mutations sm, std::optional<table_schema_version> version)
|
|
{
|
|
slogger.trace("create_table_from_mutations: version={}, {}", version, sm);
|
|
|
|
auto table_rs = query::result_set(sm.columnfamilies_mutation());
|
|
query::result_set_row table_row = table_rs.row(0);
|
|
|
|
auto ks_name = table_row.get_nonnull<sstring>("keyspace_name");
|
|
auto cf_name = table_row.get_nonnull<sstring>("table_name");
|
|
auto id = table_id(table_row.get_nonnull<utils::UUID>("id"));
|
|
schema_builder builder{ks_name, cf_name, id};
|
|
|
|
auto cf = cf_type::standard;
|
|
auto is_dense = false;
|
|
auto is_counter = false;
|
|
auto is_compound = false;
|
|
auto flags = table_row.get<set_type_impl::native_type>("flags");
|
|
|
|
if (flags) {
|
|
for (auto& s : *flags) {
|
|
if (s == "super") {
|
|
// cf = cf_type::super;
|
|
fail(unimplemented::cause::SUPER);
|
|
} else if (s == "dense") {
|
|
is_dense = true;
|
|
} else if (s == "compound") {
|
|
is_compound = true;
|
|
} else if (s == "counter") {
|
|
is_counter = true;
|
|
}
|
|
}
|
|
}
|
|
|
|
auto computed_columns = get_computed_columns(sm);
|
|
std::vector<column_definition> column_defs = create_columns_from_column_rows(
|
|
ctxt,
|
|
query::result_set(sm.columns_mutation()),
|
|
ks_name,
|
|
cf_name,/*,
|
|
fullRawComparator, */
|
|
cf == cf_type::super,
|
|
column_view_virtual::no,
|
|
computed_columns);
|
|
|
|
|
|
builder.set_is_dense(is_dense);
|
|
builder.set_is_compound(is_compound);
|
|
builder.set_is_counter(is_counter);
|
|
|
|
prepare_builder_from_table_row(ctxt, builder, table_row);
|
|
|
|
v3_columns columns(std::move(column_defs), is_dense, is_compound);
|
|
columns.apply_to(builder);
|
|
|
|
std::vector<index_metadata> index_defs;
|
|
if (sm.indices_mutation()) {
|
|
index_defs = create_indices_from_index_rows(query::result_set(*sm.indices_mutation()), ks_name, cf_name);
|
|
}
|
|
for (auto&& index : index_defs) {
|
|
builder.with_index(index);
|
|
}
|
|
|
|
if (sm.dropped_columns_mutation()) {
|
|
query::result_set dcr(*sm.dropped_columns_mutation());
|
|
for (auto& row : dcr.rows()) {
|
|
auto name = row.get_nonnull<sstring>("column_name");
|
|
auto type = cql_type_parser::parse(ks_name, row.get_nonnull<sstring>("type"), ctxt.user_types());
|
|
auto time = row.get_nonnull<db_clock::time_point>("dropped_time");
|
|
builder.without_column(name, type, time.time_since_epoch().count());
|
|
}
|
|
}
|
|
|
|
if (version) {
|
|
builder.with_version(*version);
|
|
} else {
|
|
builder.with_version(sm.digest(ctxt.features().cluster_schema_features()));
|
|
}
|
|
|
|
if (auto partitioner = sm.partitioner()) {
|
|
builder.with_partitioner(*partitioner);
|
|
builder.with_sharder(smp::count, ctxt.murmur3_partitioner_ignore_msb_bits());
|
|
}
|
|
|
|
return builder.build();
|
|
}
|
|
|
|
/*
|
|
* Column metadata serialization/deserialization.
|
|
*/
|
|
|
|
static void add_column_to_schema_mutation(schema_ptr table,
|
|
const column_definition& column,
|
|
api::timestamp_type timestamp,
|
|
mutation& m)
|
|
{
|
|
auto ckey = clustering_key::from_exploded(*m.schema(), {utf8_type->decompose(table->cf_name()),
|
|
utf8_type->decompose(column.name_as_text())});
|
|
fill_column_info(*table, ckey, column, timestamp, std::nullopt, m);
|
|
}
|
|
|
|
static void add_computed_column_to_schema_mutation(schema_ptr table,
|
|
const column_definition& column,
|
|
api::timestamp_type timestamp,
|
|
mutation& m) {
|
|
auto ckey = clustering_key::from_exploded(*m.schema(),
|
|
{utf8_type->decompose(table->cf_name()), utf8_type->decompose(column.name_as_text())});
|
|
|
|
m.set_clustered_cell(ckey, "computation", data_value(column.get_computation().serialize()), timestamp);
|
|
}
|
|
|
|
sstring serialize_kind(column_kind kind)
|
|
{
|
|
switch (kind) {
|
|
case column_kind::partition_key: return "partition_key";
|
|
case column_kind::clustering_key: return "clustering";
|
|
case column_kind::static_column: return "static";
|
|
case column_kind::regular_column: return "regular";
|
|
default: throw std::invalid_argument("unknown column kind");
|
|
}
|
|
}
|
|
|
|
column_kind deserialize_kind(sstring kind) {
|
|
if (kind == "partition_key") {
|
|
return column_kind::partition_key;
|
|
} else if (kind == "clustering_key" || kind == "clustering") {
|
|
return column_kind::clustering_key;
|
|
} else if (kind == "static") {
|
|
return column_kind::static_column;
|
|
} else if (kind == "regular") {
|
|
return column_kind::regular_column;
|
|
} else if (kind == "compact_value") { // backward compatibility
|
|
return column_kind::regular_column;
|
|
} else {
|
|
throw std::invalid_argument("unknown column kind: " + kind);
|
|
}
|
|
}
|
|
|
|
sstring serialize_index_kind(index_metadata_kind kind)
|
|
{
|
|
switch (kind) {
|
|
case index_metadata_kind::keys: return "KEYS";
|
|
case index_metadata_kind::composites: return "COMPOSITES";
|
|
case index_metadata_kind::custom: return "CUSTOM";
|
|
}
|
|
throw std::invalid_argument("unknown index kind");
|
|
}
|
|
|
|
index_metadata_kind deserialize_index_kind(sstring kind) {
|
|
if (kind == "KEYS") {
|
|
return index_metadata_kind::keys;
|
|
} else if (kind == "COMPOSITES") {
|
|
return index_metadata_kind::composites;
|
|
} else if (kind == "CUSTOM") {
|
|
return index_metadata_kind::custom;
|
|
} else {
|
|
throw std::invalid_argument("unknown column kind: " + kind);
|
|
}
|
|
}
|
|
|
|
static void add_index_to_schema_mutation(schema_ptr table,
|
|
const index_metadata& index,
|
|
api::timestamp_type timestamp,
|
|
mutation& m)
|
|
{
|
|
auto ckey = clustering_key::from_exploded(*m.schema(), {utf8_type->decompose(table->cf_name()), utf8_type->decompose(index.name())});
|
|
m.set_clustered_cell(ckey, "kind", serialize_index_kind(index.kind()), timestamp);
|
|
store_map(m, ckey, "options", timestamp, index.options());
|
|
}
|
|
|
|
static void drop_index_from_schema_mutation(schema_ptr table, const index_metadata& index, long timestamp, std::vector<mutation>& mutations)
|
|
{
|
|
schema_ptr s = indexes();
|
|
auto pkey = partition_key::from_singular(*s, table->ks_name());
|
|
auto ckey = clustering_key::from_exploded(*s, {utf8_type->decompose(table->cf_name()), utf8_type->decompose(index.name())});
|
|
mutation m{s, pkey};
|
|
m.partition().apply_delete(*s, ckey, tombstone(timestamp, gc_clock::now()));
|
|
mutations.push_back(std::move(m));
|
|
}
|
|
|
|
static void drop_column_from_schema_mutation(
|
|
schema_ptr schema_table,
|
|
schema_ptr table,
|
|
const sstring& column_name,
|
|
long timestamp,
|
|
std::vector<mutation>& mutations)
|
|
{
|
|
auto pkey = partition_key::from_singular(*schema_table, table->ks_name());
|
|
auto ckey = clustering_key::from_exploded(*schema_table, {utf8_type->decompose(table->cf_name()),
|
|
utf8_type->decompose(column_name)});
|
|
|
|
mutation m{schema_table, pkey};
|
|
m.partition().apply_delete(*schema_table, ckey, tombstone(timestamp, gc_clock::now()));
|
|
mutations.emplace_back(m);
|
|
}
|
|
|
|
static computed_columns_map get_computed_columns(const schema_mutations& sm) {
|
|
if (!sm.computed_columns_mutation()) {
|
|
return {};
|
|
}
|
|
query::result_set computed_result(*sm.computed_columns_mutation());
|
|
return computed_result.rows() | std::views::transform([] (const query::result_set_row& row) {
|
|
return computed_columns_map::value_type{to_bytes(row.get_nonnull<sstring>("column_name")), column_computation::deserialize(row.get_nonnull<bytes>("computation"))};
|
|
}) | std::ranges::to<computed_columns_map>();
|
|
}
|
|
|
|
static std::vector<column_definition> create_columns_from_column_rows(const schema_ctxt& ctxt,
|
|
const query::result_set& rows,
|
|
const sstring& keyspace,
|
|
const sstring& table, /*,
|
|
AbstractType<?> rawComparator, */
|
|
bool is_super,
|
|
column_view_virtual is_view_virtual,
|
|
const computed_columns_map& computed_columns)
|
|
{
|
|
std::vector<column_definition> columns;
|
|
for (auto&& row : rows.rows()) {
|
|
auto kind = deserialize_kind(row.get_nonnull<sstring>("kind"));
|
|
auto type = cql_type_parser::parse(keyspace, row.get_nonnull<sstring>("type"), ctxt.user_types());
|
|
auto name_bytes = row.get_nonnull<bytes>("column_name_bytes");
|
|
column_id position = row.get_nonnull<int32_t>("position");
|
|
|
|
if (auto val = row.get<sstring>("clustering_order")) {
|
|
auto order = *val;
|
|
std::transform(order.begin(), order.end(), order.begin(), ::toupper);
|
|
if (order == "DESC") {
|
|
type = reversed_type_impl::get_instance(type);
|
|
}
|
|
}
|
|
column_computation_ptr computation;
|
|
auto computed_it = computed_columns.find(name_bytes);
|
|
if (computed_it != computed_columns.end()) {
|
|
computation = computed_it->second->clone();
|
|
}
|
|
|
|
columns.emplace_back(name_bytes, type, kind, position, is_view_virtual, std::move(computation));
|
|
}
|
|
return columns;
|
|
}
|
|
|
|
static std::vector<index_metadata> create_indices_from_index_rows(const query::result_set& rows,
|
|
const sstring& keyspace,
|
|
const sstring& table)
|
|
{
|
|
return rows.rows() | std::views::transform([&keyspace, &table] (auto&& row) {
|
|
return create_index_from_index_row(row, keyspace, table);
|
|
}) | std::ranges::to<std::vector<index_metadata>>();
|
|
}
|
|
|
|
static index_metadata create_index_from_index_row(const query::result_set_row& row,
|
|
sstring keyspace,
|
|
sstring table)
|
|
{
|
|
auto index_name = row.get_nonnull<sstring>("index_name");
|
|
index_options_map options;
|
|
auto map = row.get_nonnull<map_type_impl::native_type>("options");
|
|
for (auto&& entry : map) {
|
|
options.emplace(value_cast<sstring>(entry.first), value_cast<sstring>(entry.second));
|
|
}
|
|
index_metadata_kind kind = deserialize_index_kind(row.get_nonnull<sstring>("kind"));
|
|
sstring target_string = options.at(cql3::statements::index_target::target_option_name);
|
|
const index_metadata::is_local_index is_local(secondary_index::target_parser::is_local(target_string));
|
|
return index_metadata{index_name, options, kind, is_local};
|
|
}
|
|
|
|
/*
|
|
* View metadata serialization/deserialization.
|
|
*/
|
|
|
|
view_ptr create_view_from_mutations(const schema_ctxt& ctxt, schema_mutations sm, std::optional<table_schema_version> version) {
|
|
auto table_rs = query::result_set(sm.columnfamilies_mutation());
|
|
query::result_set_row row = table_rs.row(0);
|
|
|
|
auto ks_name = row.get_nonnull<sstring>("keyspace_name");
|
|
auto cf_name = row.get_nonnull<sstring>("view_name");
|
|
auto id = table_id(row.get_nonnull<utils::UUID>("id"));
|
|
|
|
schema_builder builder{ks_name, cf_name, id};
|
|
prepare_builder_from_table_row(ctxt, builder, row);
|
|
|
|
auto computed_columns = get_computed_columns(sm);
|
|
auto column_defs = create_columns_from_column_rows(ctxt, query::result_set(sm.columns_mutation()), ks_name, cf_name, false, column_view_virtual::no, computed_columns);
|
|
for (auto&& cdef : column_defs) {
|
|
builder.with_column_ordered(cdef);
|
|
}
|
|
if (sm.view_virtual_columns_mutation()) {
|
|
column_defs = create_columns_from_column_rows(ctxt, query::result_set(*sm.view_virtual_columns_mutation()), ks_name, cf_name, false, column_view_virtual::yes, computed_columns);
|
|
for (auto&& cdef : column_defs) {
|
|
builder.with_column_ordered(cdef);
|
|
}
|
|
}
|
|
|
|
if (version) {
|
|
builder.with_version(*version);
|
|
} else {
|
|
builder.with_version(sm.digest(ctxt.features().cluster_schema_features()));
|
|
}
|
|
|
|
auto base_id = table_id(row.get_nonnull<utils::UUID>("base_table_id"));
|
|
auto base_name = row.get_nonnull<sstring>("base_table_name");
|
|
auto include_all_columns = row.get_nonnull<bool>("include_all_columns");
|
|
auto where_clause = row.get_nonnull<sstring>("where_clause");
|
|
|
|
builder.with_view_info(std::move(base_id), std::move(base_name), include_all_columns, std::move(where_clause));
|
|
return view_ptr(builder.build());
|
|
}
|
|
|
|
static future<view_ptr> create_view_from_table_row(distributed<service::storage_proxy>& proxy, const query::result_set_row& row) {
|
|
qualified_name qn(row.get_nonnull<sstring>("keyspace_name"), row.get_nonnull<sstring>("view_name"));
|
|
schema_mutations sm = co_await read_table_mutations(proxy, qn, views());
|
|
if (!sm.live()) {
|
|
co_await coroutine::return_exception(std::runtime_error(format("{}:{} not found in the view definitions keyspace.", qn.keyspace_name, qn.table_name)));
|
|
}
|
|
co_return create_view_from_mutations(proxy, std::move(sm));
|
|
}
|
|
|
|
/**
|
|
* Deserialize views from low-level schema representation, all of them belong to the same keyspace
|
|
*
|
|
* @return vector containing the view definitions
|
|
*/
|
|
future<std::vector<view_ptr>> create_views_from_schema_partition(distributed<service::storage_proxy>& proxy, const schema_result::mapped_type& result)
|
|
{
|
|
std::vector<view_ptr> views;
|
|
co_await max_concurrent_for_each(result->rows().begin(), result->rows().end(), max_concurrent, [&] (auto&& row) -> future<> {
|
|
auto v = co_await create_view_from_table_row(proxy, row);
|
|
views.push_back(std::move(v));
|
|
});
|
|
co_return std::move(views);
|
|
}
|
|
|
|
static schema_mutations make_view_mutations(view_ptr view, api::timestamp_type timestamp, bool with_columns)
|
|
{
|
|
// When adding new schema properties, don't set cells for default values so that
|
|
// both old and new nodes will see the same version during rolling upgrades.
|
|
|
|
// For properties that can be null (and can be changed), we insert tombstones, to make sure
|
|
// we don't keep a property the user has removed
|
|
schema_ptr s = views();
|
|
auto pkey = partition_key::from_singular(*s, view->ks_name());
|
|
mutation m{s, pkey};
|
|
auto ckey = clustering_key::from_singular(*s, view->cf_name());
|
|
|
|
m.set_clustered_cell(ckey, "base_table_id", view->view_info()->base_id().uuid(), timestamp);
|
|
m.set_clustered_cell(ckey, "base_table_name", view->view_info()->base_name(), timestamp);
|
|
m.set_clustered_cell(ckey, "where_clause", view->view_info()->where_clause(), timestamp);
|
|
m.set_clustered_cell(ckey, "bloom_filter_fp_chance", view->bloom_filter_fp_chance(), timestamp);
|
|
m.set_clustered_cell(ckey, "include_all_columns", view->view_info()->include_all_columns(), timestamp);
|
|
m.set_clustered_cell(ckey, "id", view->id().uuid(), timestamp);
|
|
|
|
add_table_params_to_mutations(m, ckey, view, timestamp);
|
|
|
|
mutation columns_mutation(columns(), pkey);
|
|
mutation view_virtual_columns_mutation(view_virtual_columns(), pkey);
|
|
mutation computed_columns_mutation(computed_columns(), pkey);
|
|
mutation dropped_columns_mutation(dropped_columns(), pkey);
|
|
mutation indices_mutation(indexes(), pkey);
|
|
|
|
if (with_columns) {
|
|
for (auto&& column : view->v3().all_columns()) {
|
|
if (column.is_view_virtual()) {
|
|
add_column_to_schema_mutation(view, column, timestamp, view_virtual_columns_mutation);
|
|
} else {
|
|
add_column_to_schema_mutation(view, column, timestamp, columns_mutation);
|
|
}
|
|
if (column.is_computed()) {
|
|
add_computed_column_to_schema_mutation(view, column, timestamp, computed_columns_mutation);
|
|
}
|
|
}
|
|
|
|
for (auto&& e : view->dropped_columns()) {
|
|
add_dropped_column_to_schema_mutation(view, e.first, e.second, timestamp, dropped_columns_mutation);
|
|
}
|
|
for (auto&& index : view->indices()) {
|
|
add_index_to_schema_mutation(view, index, timestamp, indices_mutation);
|
|
}
|
|
}
|
|
|
|
auto scylla_tables_mutation = make_scylla_tables_mutation(view, timestamp);
|
|
|
|
return schema_mutations{std::move(m),
|
|
std::move(columns_mutation),
|
|
std::move(view_virtual_columns_mutation),
|
|
std::move(computed_columns_mutation),
|
|
std::move(indices_mutation),
|
|
std::move(dropped_columns_mutation),
|
|
std::move(scylla_tables_mutation)};
|
|
}
|
|
|
|
schema_mutations make_schema_mutations(schema_ptr s, api::timestamp_type timestamp, bool with_columns)
|
|
{
|
|
return s->is_view() ? make_view_mutations(view_ptr(s), timestamp, with_columns) : make_table_mutations(s, timestamp, with_columns);
|
|
}
|
|
|
|
std::vector<mutation> make_create_view_mutations(lw_shared_ptr<keyspace_metadata> keyspace, view_ptr view, api::timestamp_type timestamp)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
// Include the serialized base table mutations in case the target node is missing them.
|
|
auto base = keyspace->cf_meta_data().at(view->view_info()->base_name());
|
|
// Use a smaller timestamp for the included base mutations.
|
|
// If the constructed schema change command also contains an update for the base table,
|
|
// these mutations would conflict with the base mutations we're returning here; using a smaller
|
|
// timestamp makes sure that the update mutations take precedence. Although there is no known
|
|
// scenario involving creation of new view where this might happen, there is one with updating
|
|
// a view (see `make_update_view_mutations`); we use similarly modified timestamp here for consistency.
|
|
add_table_or_view_to_schema_mutation(base, timestamp - 1, true, mutations);
|
|
add_table_or_view_to_schema_mutation(view, timestamp, true, mutations);
|
|
make_table_deleting_mutations(view->ks_name(), view->cf_name(), view->is_view(), timestamp)
|
|
.copy_to(mutations);
|
|
return mutations;
|
|
}
|
|
|
|
/**
|
|
* Note: new_view can be generated due to an ALTER on its base table; in that
|
|
* case, the new base schema isn't yet loaded, thus can't be accessed from this
|
|
* function.
|
|
*/
|
|
std::vector<mutation> make_update_view_mutations(lw_shared_ptr<keyspace_metadata> keyspace,
|
|
view_ptr old_view,
|
|
view_ptr new_view,
|
|
api::timestamp_type timestamp,
|
|
bool include_base)
|
|
{
|
|
std::vector<mutation> mutations;
|
|
if (include_base) {
|
|
// Include the serialized base table mutations in case the target node is missing them.
|
|
auto base = keyspace->cf_meta_data().at(new_view->view_info()->base_name());
|
|
// Use a smaller timestamp for the included base mutations.
|
|
// If the constructed schema change command also contains an update for the base table,
|
|
// these mutations would conflict with the base mutations we're returning here; using a smaller
|
|
// timestamp makes sure that the update mutations take precedence. Such conflicting mutations
|
|
// may appear, for example, when we modify a user defined type that is referenced by both base table
|
|
// and its attached view. See #15530.
|
|
add_table_or_view_to_schema_mutation(base, timestamp - 1, true, mutations);
|
|
}
|
|
add_table_or_view_to_schema_mutation(new_view, timestamp, false, mutations);
|
|
make_update_columns_mutations(old_view, new_view, timestamp, mutations);
|
|
return mutations;
|
|
}
|
|
|
|
std::vector<mutation> make_drop_view_mutations(lw_shared_ptr<keyspace_metadata> keyspace, view_ptr view, api::timestamp_type timestamp) {
|
|
std::vector<mutation> mutations;
|
|
make_drop_table_or_view_mutations(views(), view, timestamp, mutations);
|
|
return mutations;
|
|
}
|
|
|
|
data_type parse_type(sstring str)
|
|
{
|
|
return db::marshal::type_parser::parse(str);
|
|
}
|
|
|
|
std::vector<schema_ptr> all_tables(schema_features features) {
|
|
// Don't forget to update this list when new schema tables are added.
|
|
// The listed schema tables are the ones synchronized between nodes,
|
|
// and forgetting one of them in this list can cause bugs like #4339.
|
|
//
|
|
// This list must be kept backwards-compatible because it's used
|
|
// for schema digest calculation. Refs #4457.
|
|
std::vector<schema_ptr> result = {
|
|
keyspaces(), tables(), scylla_tables(), columns(), dropped_columns(), triggers(),
|
|
views(), types(), functions(), aggregates(), indexes()
|
|
};
|
|
result.emplace_back(view_virtual_columns());
|
|
if (features.contains<schema_feature::COMPUTED_COLUMNS>()) {
|
|
result.emplace_back(computed_columns());
|
|
}
|
|
if (features.contains<schema_feature::SCYLLA_KEYSPACES>()) {
|
|
result.emplace_back(scylla_keyspaces());
|
|
}
|
|
if (features.contains<schema_feature::SCYLLA_AGGREGATES>()) {
|
|
result.emplace_back(scylla_aggregates());
|
|
}
|
|
return result;
|
|
}
|
|
|
|
std::vector<sstring> all_table_names(schema_features features) {
|
|
return all_tables(features)
|
|
| std::views::transform([] (auto schema) { return schema->cf_name(); })
|
|
| std::ranges::to<std::vector>();
|
|
}
|
|
|
|
void check_no_legacy_secondary_index_mv_schema(replica::database& db, const view_ptr& v, schema_ptr base_schema) {
|
|
// Legacy format for a secondary index used a hardcoded "token" column, which ensured a proper
|
|
// order for indexed queries. This "token" column is has been implemented as a computed column
|
|
// for a long time now, and migration code has been / will be executed on all reasonable Scylla
|
|
// deployments (which don't do unsupported upgrades).
|
|
//
|
|
// This function is now used as a sanity check that we're not dealing with the legacy format anymore.
|
|
if (v->clustering_key_size() == 0) {
|
|
return;
|
|
}
|
|
const auto ck_cols = v->clustering_key_columns();
|
|
const column_definition& first_view_ck = ck_cols.front();
|
|
if (first_view_ck.is_computed()) {
|
|
return;
|
|
}
|
|
|
|
if (!base_schema) {
|
|
base_schema = db.find_schema(v->view_info()->base_id());
|
|
}
|
|
|
|
// If the first clustering key part of a view is a column with name not found in base schema,
|
|
// and the column is not computed (which we checked above), then it must be backing an index
|
|
// created before computed columns were introduced.
|
|
if (!base_schema->columns_by_name().contains(first_view_ck.name())) {
|
|
on_fatal_internal_error(slogger, format(
|
|
"Materialized view {}.{}: first clustering key column ({}) is not computed and does not have a corresponding"
|
|
" column in the base table. This materialized view must therefore be a secondary index created"
|
|
" using legacy method (without computed columns) that wasn't migrated properly to new method."
|
|
" Make sure that you perform rolling upgrade according to documented procedure without skipping"
|
|
" major Scylla versions.", v->ks_name(), v->cf_name(), first_view_ck.name_as_text()));
|
|
}
|
|
}
|
|
|
|
|
|
namespace legacy {
|
|
|
|
table_schema_version schema_mutations::digest() const {
|
|
md5_hasher h;
|
|
const db::schema_features no_features;
|
|
db::schema_tables::feed_hash_for_schema_digest(h, _columnfamilies, no_features);
|
|
db::schema_tables::feed_hash_for_schema_digest(h, _columns, no_features);
|
|
return table_schema_version(utils::UUID_gen::get_name_UUID(h.finalize()));
|
|
}
|
|
|
|
future<schema_mutations> read_table_mutations(distributed<service::storage_proxy>& proxy,
|
|
sstring keyspace_name, sstring table_name, schema_ptr s)
|
|
{
|
|
mutation cf_m = co_await read_schema_partition_for_table(proxy, s, keyspace_name, table_name);
|
|
mutation col_m = co_await read_schema_partition_for_table(proxy, db::system_keyspace::legacy::columns(), keyspace_name, table_name);
|
|
co_return schema_mutations{std::move(cf_m), std::move(col_m)};
|
|
}
|
|
|
|
} // namespace legacy
|
|
|
|
static auto GET_COLUMN_MAPPING_QUERY = format("SELECT column_name, clustering_order, column_name_bytes, kind, position, type FROM system.{} WHERE cf_id = ? AND schema_version = ?",
|
|
db::schema_tables::SCYLLA_TABLE_SCHEMA_HISTORY);
|
|
|
|
future<column_mapping> get_column_mapping(db::system_keyspace& sys_ks, ::table_id table_id, table_schema_version version) {
|
|
shared_ptr<cql3::untyped_result_set> results = co_await sys_ks._qp.execute_internal(
|
|
GET_COLUMN_MAPPING_QUERY,
|
|
db::consistency_level::LOCAL_ONE,
|
|
{table_id.uuid(), version.uuid()},
|
|
cql3::query_processor::cache_internal::no
|
|
);
|
|
if (results->empty()) {
|
|
// If we don't have a stored column_mapping for an obsolete schema version
|
|
// then it means it's way too old and been cleaned up already.
|
|
// Fail the whole learn stage in this case.
|
|
co_await coroutine::return_exception(std::runtime_error(
|
|
format("Failed to look up column mapping for schema version {}",
|
|
version)));
|
|
}
|
|
std::vector<column_definition> static_columns, regular_columns;
|
|
for (const auto& row : *results) {
|
|
auto kind = deserialize_kind(row.get_as<sstring>("kind"));
|
|
auto type = cql_type_parser::parse("" /*unused*/, row.get_as<sstring>("type"), data_dictionary::dummy_user_types_storage());
|
|
auto name_bytes = row.get_blob("column_name_bytes");
|
|
column_id position = row.get_as<int32_t>("position");
|
|
|
|
auto order = row.get_as<sstring>("clustering_order");
|
|
std::transform(order.begin(), order.end(), order.begin(), ::toupper);
|
|
if (order == "DESC") {
|
|
type = reversed_type_impl::get_instance(type);
|
|
}
|
|
if (kind == column_kind::static_column) {
|
|
static_columns.emplace_back(name_bytes, type, kind, position);
|
|
} else if (kind == column_kind::regular_column) {
|
|
regular_columns.emplace_back(name_bytes, type, kind, position);
|
|
}
|
|
}
|
|
std::vector<column_mapping_entry> cm_columns;
|
|
for (const column_definition& def : boost::range::join(static_columns, regular_columns)) {
|
|
cm_columns.emplace_back(column_mapping_entry{def.name(), def.type});
|
|
}
|
|
column_mapping cm(std::move(cm_columns), static_columns.size());
|
|
co_return std::move(cm);
|
|
}
|
|
|
|
future<bool> column_mapping_exists(db::system_keyspace& sys_ks, table_id table_id, table_schema_version version) {
|
|
shared_ptr<cql3::untyped_result_set> results = co_await sys_ks._qp.execute_internal(
|
|
GET_COLUMN_MAPPING_QUERY,
|
|
db::consistency_level::LOCAL_ONE,
|
|
{table_id.uuid(), version.uuid()},
|
|
cql3::query_processor::cache_internal::yes
|
|
);
|
|
co_return !results->empty();
|
|
}
|
|
|
|
future<> drop_column_mapping(db::system_keyspace& sys_ks, table_id table_id, table_schema_version version) {
|
|
const static sstring DEL_COLUMN_MAPPING_QUERY =
|
|
format("DELETE FROM system.{} WHERE cf_id = ? and schema_version = ?",
|
|
db::schema_tables::SCYLLA_TABLE_SCHEMA_HISTORY);
|
|
co_await sys_ks._qp.execute_internal(
|
|
DEL_COLUMN_MAPPING_QUERY,
|
|
db::consistency_level::LOCAL_ONE,
|
|
{table_id.uuid(), version.uuid()},
|
|
cql3::query_processor::cache_internal::no);
|
|
}
|
|
|
|
} // namespace schema_tables
|
|
} // namespace schema
|