mirror of
https://github.com/scylladb/scylladb.git
synced 2026-04-25 11:00:35 +00:00
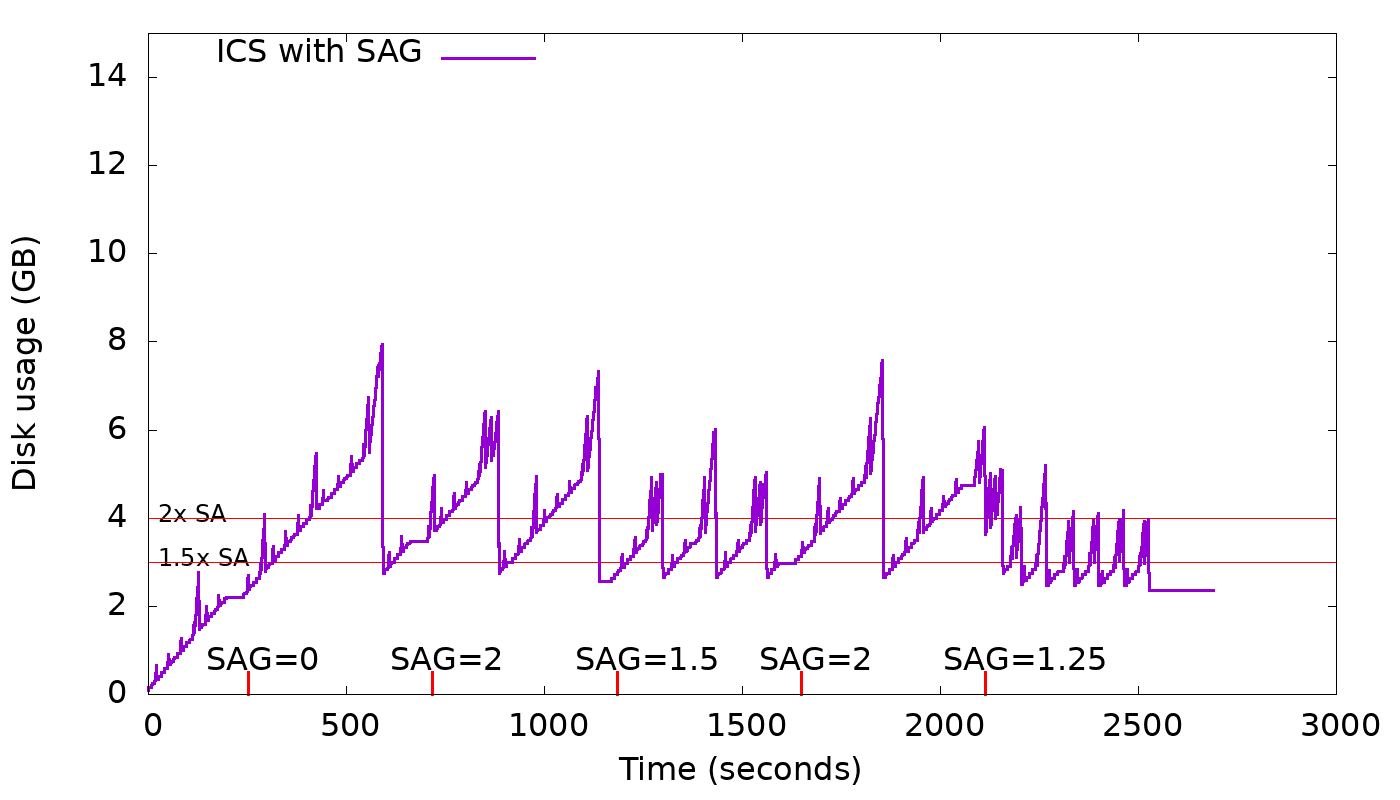
ICS is a compaction strategy that inherits size tiered properties -- therefore it's write optimized too -- but fixes its space overhead of 100% due to input files being only released on completion. That's achieved with the concept of sstable run (similar in concept to LCS levels) which breaks a large sstable into fixed-size chunks (1G by default), known as run fragments. ICS picks similar-sized runs for compaction, and fragments of those runs can be released incrementally as they're compacted, reducing the space overhead to about (number_of_input_runs * 1G). This allows user to increase storage density of nodes (from 50% to ~80%), reducing the cost of ownership. NOTE: test_system_schema_version_is_stable adjusted to account for batchlog using IncrementalCompactionStrategy contains: compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh) compaction/CMakeLists.txt: include ICS cc files configure.py: changes for ICS files, includes test db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported db/system_keyspace: pick ICS for some system tables schema/schema.hh: ICS becomes default test/boost: Add incremental_compaction_test.cc test/boost/sstable_compaction_test.cc: ICS related changes test/cqlpy/test_compaction_strategy_validation.py: ICS related changes docs/architecture/compaction/compaction-strategies.rst: changes to ICS section docs/cql/compaction.rst: changes to ICS section docs/cql/ddl.rst: adds reference to ICS options docs/getting-started/system-requirements.rst: updates sentence mentioning ICS docs/kb/compaction.rst: changes to ICS section docs/kb/garbage-collection-ics.rst: add file docs/kb/index.rst: add reference to <garbage-collection-ics> docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section some relevant commits throughout the ICS history: commit 434b97699b39c570d0d849d372bf64f418e5c692 Merge: 105586f747 30250749b8 Author: Paweł Dziepak <pdziepak@scylladb.com> Date: Tue Mar 12 12:14:23 2019 +0000 Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael " Introduce new compaction strategy which is essentially like size tiered but will work with the existing incremental compaction. Thus incremental compaction strategy. It works like size tiered, but each element composing a tier is a sstable run, meaning that the compaction strategy will look for N similar-sized sstable runs to compact, not just individual sstables. Parameters: * "sstable_size_in_mb": defines the maximum sstable (fragment) size composing a sstable run, which impacts directly the disk space requirement which is improved with incremental compaction. The lower the value the lower the space requirement for compaction because fragments involved will be released more frequently. * all others available in size tiered compaction strategy HOWTO ===== To change an existing table to use it, do: ALTER TABLE mykeyspace.mytable WITH compaction = {'class' : 'IncrementalCompactionStrategy'}; Set fragment size: ALTER TABLE mykeyspace.mytable WITH compaction = {'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 } " commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1 Merge: dca89ce7a5 e08ef3e1a3 Author: Avi Kivity <avi@scylladb.com> Date: Tue Sep 8 11:31:52 2020 +0300 Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael " A new option, space_amplification_goal (SAG), is being added to ICS. This option will allow ICS user to set a goal on the space amplification (SA). It's not supposed to be an upper bound on the space amplification, but rather, a goal. This new option will be disabled by default as it doesn't benefit write-only (no overwrites) workloads and could hurt severely the write performance. The strategy is free to delay triggering this new behavior, in order to increase overall compaction efficiency. The graph below shows how this feature works in practice for different values of space_amplification_goal: https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png When strategy finds space amplification crossed space_amplification_goal, it will work on reducing the SA by doing a cross-tier compaction on the two largest tiers. This feature works only on the two largest tiers, because taking into account others, could hurt the compaction efficiency which is based on the fact that the more similar-sized sstables are compacted together the higher the compaction efficiency will be. With SAG enabled, min_threshold only plays an important role on the smallest tiers, given that the second-largest tier could be compacted into the largest tier for a space_amplification_goal value < 2. By making the options space_amplification_goal and min_threshold independent, user will be able to tune write amplification and space amplification, based on the needs. The lower the space_amplification_goal the higher the write amplification, but by increasing the min threshold, the write amplification can be decreased to a desired amount. " commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1 Author: Raphael S. Carvalho <raphaelsc@scylladb.com> Date: Sat Oct 16 13:41:46 2021 -0300 compaction: ICS: Add garbage collection Today, ICS lacks an approach to persist expired tombstones in a timely manner, which is a problem because accumulation of tombstones are known to affecting latency considerably. For an expired tombstone to be purged, it has to reach the top of the LSM tree and hope that older overlapping data wasn't introduced at the bottom. The condition are there and must be satisfied to avoid data resurrection. STCS, today, has an inefficient garbage collection approach because it only picks a single sstable, which satisfies the tombstone density threshold and file staleness. That's a problem because overlapping data either on same tier or smaller tiers will prevent tombstones from being purged. Also, nothing is done to push the tombstones to the top of the tree, for the conditions to be eventually satisfied. Due to incremental compaction, ICS can more easily have an effecient GC by doing cross-tier compaction of relevant tiers. The trigger will be file staleness and tombstone density, which threshold values can be configured by tombstone_compaction_interval and tombstone_threshold, respectively. If ICS finds a tier which meets both conditions, then that tier and the larger[1] *and* closest-in-size[2] tier will be compacted together. [1]: A larger tier is picked because we want tombstones to eventually reach the top of the tree. [2]: It also has to be the closest-in-size tier as the smaller the size difference the higher the efficiency of the compaction. We want to minimize write amplification as much as possible. The staleness condition is there to prevent the same file from being picked over and over again in a short interval. With this approach, ICS will be continuously working to purge garbage while not hurting overall efficiency on a steady state, as same-tier compactions are prioritized. Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com> Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com> Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com> Closes scylladb/scylladb#22063
{kind=link}
806 lines
38 KiB
C++
806 lines
38 KiB
C++
/*
|
|
* Copyright (C) 2016-present ScyllaDB
|
|
*/
|
|
|
|
/*
|
|
* SPDX-License-Identifier: (LicenseRef-ScyllaDB-Source-Available-1.0 and Apache-2.0)
|
|
*/
|
|
|
|
/*
|
|
*/
|
|
|
|
#include <vector>
|
|
#include <chrono>
|
|
#include <fmt/ranges.h>
|
|
#include <seastar/core/shared_ptr.hh>
|
|
#include <seastar/core/on_internal_error.hh>
|
|
#include "sstables/shared_sstable.hh"
|
|
#include "sstables/sstables.hh"
|
|
#include "compaction_strategy.hh"
|
|
#include "compaction_strategy_impl.hh"
|
|
#include "compaction_strategy_state.hh"
|
|
#include "cql3/statements/property_definitions.hh"
|
|
#include "schema/schema.hh"
|
|
#include "size_tiered_compaction_strategy.hh"
|
|
#include "leveled_compaction_strategy.hh"
|
|
#include "time_window_compaction_strategy.hh"
|
|
#include "backlog_controller.hh"
|
|
#include "compaction_backlog_manager.hh"
|
|
#include "size_tiered_backlog_tracker.hh"
|
|
#include "leveled_manifest.hh"
|
|
#include "utils/to_string.hh"
|
|
#include "incremental_compaction_strategy.hh"
|
|
#include "sstables/sstable_set_impl.hh"
|
|
|
|
logging::logger leveled_manifest::logger("LeveledManifest");
|
|
logging::logger compaction_strategy_logger("CompactionStrategy");
|
|
|
|
using namespace sstables;
|
|
|
|
namespace sstables {
|
|
|
|
using timestamp_type = api::timestamp_type;
|
|
|
|
compaction_descriptor compaction_strategy_impl::make_major_compaction_job(std::vector<sstables::shared_sstable> candidates, int level, uint64_t max_sstable_bytes) {
|
|
// run major compaction in maintenance priority
|
|
return compaction_descriptor(std::move(candidates), level, max_sstable_bytes);
|
|
}
|
|
|
|
std::vector<compaction_descriptor> compaction_strategy_impl::get_cleanup_compaction_jobs(table_state& table_s, std::vector<shared_sstable> candidates) const {
|
|
// The default implementation is suboptimal and causes the writeamp problem described issue in #10097.
|
|
// The compaction strategy relying on it should strive to implement its own method, to make cleanup bucket aware.
|
|
return candidates | std::views::transform([] (const shared_sstable& sst) {
|
|
return compaction_descriptor({ sst },
|
|
sst->get_sstable_level(), sstables::compaction_descriptor::default_max_sstable_bytes, sst->run_identifier());
|
|
}) | std::ranges::to<std::vector>();
|
|
}
|
|
|
|
bool compaction_strategy_impl::worth_dropping_tombstones(const shared_sstable& sst, gc_clock::time_point compaction_time, const table_state& t) {
|
|
if (_disable_tombstone_compaction) {
|
|
return false;
|
|
}
|
|
// ignore sstables that were created just recently because there's a chance
|
|
// that expired tombstones still cover old data and thus cannot be removed.
|
|
// We want to avoid a compaction loop here on the same data by considering
|
|
// only old enough sstables.
|
|
if (db_clock::now()-_tombstone_compaction_interval < sst->data_file_write_time()) {
|
|
return false;
|
|
}
|
|
if (_unchecked_tombstone_compaction) {
|
|
return true;
|
|
}
|
|
auto droppable_ratio = sst->estimate_droppable_tombstone_ratio(compaction_time, t.get_tombstone_gc_state(), t.schema());
|
|
return droppable_ratio >= _tombstone_threshold;
|
|
}
|
|
|
|
uint64_t compaction_strategy_impl::adjust_partition_estimate(const mutation_source_metadata& ms_meta, uint64_t partition_estimate, schema_ptr schema) const {
|
|
return partition_estimate;
|
|
}
|
|
|
|
reader_consumer_v2 compaction_strategy_impl::make_interposer_consumer(const mutation_source_metadata& ms_meta, reader_consumer_v2 end_consumer) const {
|
|
return end_consumer;
|
|
}
|
|
|
|
compaction_descriptor
|
|
compaction_strategy_impl::get_reshaping_job(std::vector<shared_sstable> input, schema_ptr schema, reshape_config cfg) const {
|
|
return compaction_descriptor();
|
|
}
|
|
|
|
std::optional<sstring> compaction_strategy_impl::get_value(const std::map<sstring, sstring>& options, const sstring& name) {
|
|
auto it = options.find(name);
|
|
if (it == options.end()) {
|
|
return std::nullopt;
|
|
}
|
|
return it->second;
|
|
}
|
|
|
|
void compaction_strategy_impl::validate_min_max_threshold(const std::map<sstring, sstring>& options, std::map<sstring, sstring>& unchecked_options) {
|
|
auto min_threshold_key = "min_threshold", max_threshold_key = "max_threshold";
|
|
|
|
auto tmp_value = compaction_strategy_impl::get_value(options, min_threshold_key);
|
|
auto min_threshold = cql3::statements::property_definitions::to_long(min_threshold_key, tmp_value, DEFAULT_MIN_COMPACTION_THRESHOLD);
|
|
if (min_threshold < 2) {
|
|
throw exceptions::configuration_exception(fmt::format("{} value ({}) must be bigger or equal to 2", min_threshold_key, min_threshold));
|
|
}
|
|
|
|
tmp_value = compaction_strategy_impl::get_value(options, max_threshold_key);
|
|
auto max_threshold = cql3::statements::property_definitions::to_long(max_threshold_key, tmp_value, DEFAULT_MAX_COMPACTION_THRESHOLD);
|
|
if (max_threshold < 2) {
|
|
throw exceptions::configuration_exception(fmt::format("{} value ({}) must be bigger or equal to 2", max_threshold_key, max_threshold));
|
|
}
|
|
|
|
unchecked_options.erase(min_threshold_key);
|
|
unchecked_options.erase(max_threshold_key);
|
|
}
|
|
|
|
static double validate_tombstone_threshold(const std::map<sstring, sstring>& options) {
|
|
auto tmp_value = compaction_strategy_impl::get_value(options, compaction_strategy_impl::TOMBSTONE_THRESHOLD_OPTION);
|
|
auto tombstone_threshold = cql3::statements::property_definitions::to_double(compaction_strategy_impl::TOMBSTONE_THRESHOLD_OPTION, tmp_value, compaction_strategy_impl::DEFAULT_TOMBSTONE_THRESHOLD);
|
|
if (tombstone_threshold < 0.0 || tombstone_threshold > 1.0) {
|
|
throw exceptions::configuration_exception(fmt::format("{} value ({}) must be between 0.0 and 1.0", compaction_strategy_impl::TOMBSTONE_THRESHOLD_OPTION, tombstone_threshold));
|
|
}
|
|
return tombstone_threshold;
|
|
}
|
|
|
|
static double validate_tombstone_threshold(const std::map<sstring, sstring>& options, std::map<sstring, sstring>& unchecked_options) {
|
|
auto tombstone_threshold = validate_tombstone_threshold(options);
|
|
unchecked_options.erase(compaction_strategy_impl::TOMBSTONE_THRESHOLD_OPTION);
|
|
return tombstone_threshold;
|
|
}
|
|
|
|
static db_clock::duration validate_tombstone_compaction_interval(const std::map<sstring, sstring>& options) {
|
|
auto tmp_value = compaction_strategy_impl::get_value(options, compaction_strategy_impl::TOMBSTONE_COMPACTION_INTERVAL_OPTION);
|
|
auto interval = cql3::statements::property_definitions::to_long(compaction_strategy_impl::TOMBSTONE_COMPACTION_INTERVAL_OPTION, tmp_value, compaction_strategy_impl::DEFAULT_TOMBSTONE_COMPACTION_INTERVAL().count());
|
|
auto tombstone_compaction_interval = db_clock::duration(std::chrono::seconds(interval));
|
|
if (interval <= 0) {
|
|
throw exceptions::configuration_exception(fmt::format("{} value ({}) must be positive", compaction_strategy_impl::TOMBSTONE_COMPACTION_INTERVAL_OPTION, tombstone_compaction_interval));
|
|
}
|
|
return tombstone_compaction_interval;
|
|
}
|
|
|
|
static db_clock::duration validate_tombstone_compaction_interval(const std::map<sstring, sstring>& options, std::map<sstring, sstring>& unchecked_options) {
|
|
auto tombstone_compaction_interval = validate_tombstone_compaction_interval(options);
|
|
unchecked_options.erase(compaction_strategy_impl::TOMBSTONE_COMPACTION_INTERVAL_OPTION);
|
|
return tombstone_compaction_interval;
|
|
}
|
|
|
|
static bool validate_unchecked_tombstone_compaction(const std::map<sstring, sstring>& options) {
|
|
auto unchecked_tombstone_compaction = compaction_strategy_impl::DEFAULT_UNCHECKED_TOMBSTONE_COMPACTION;
|
|
auto tmp_value = compaction_strategy_impl::get_value(options, compaction_strategy_impl::UNCHECKED_TOMBSTONE_COMPACTION_OPTION);
|
|
if (tmp_value.has_value()) {
|
|
if (tmp_value != "true" && tmp_value != "false") {
|
|
throw exceptions::configuration_exception(fmt::format("{} value ({}) must be \"true\" or \"false\"", compaction_strategy_impl::UNCHECKED_TOMBSTONE_COMPACTION_OPTION, *tmp_value));
|
|
}
|
|
unchecked_tombstone_compaction = tmp_value == "true";
|
|
}
|
|
return unchecked_tombstone_compaction;
|
|
}
|
|
|
|
static bool validate_unchecked_tombstone_compaction(const std::map<sstring, sstring>& options, std::map<sstring, sstring>& unchecked_options) {
|
|
auto unchecked_tombstone_compaction = validate_unchecked_tombstone_compaction(options);
|
|
unchecked_options.erase(compaction_strategy_impl::UNCHECKED_TOMBSTONE_COMPACTION_OPTION);
|
|
return unchecked_tombstone_compaction;
|
|
}
|
|
|
|
void compaction_strategy_impl::validate_options_for_strategy_type(const std::map<sstring, sstring>& options, sstables::compaction_strategy_type type) {
|
|
auto unchecked_options = options;
|
|
compaction_strategy_impl::validate_options(options, unchecked_options);
|
|
switch (type) {
|
|
case compaction_strategy_type::size_tiered:
|
|
size_tiered_compaction_strategy::validate_options(options, unchecked_options);
|
|
break;
|
|
case compaction_strategy_type::leveled:
|
|
leveled_compaction_strategy::validate_options(options, unchecked_options);
|
|
break;
|
|
case compaction_strategy_type::time_window:
|
|
time_window_compaction_strategy::validate_options(options, unchecked_options);
|
|
break;
|
|
case compaction_strategy_type::incremental:
|
|
incremental_compaction_strategy::validate_options(options, unchecked_options);
|
|
break;
|
|
default:
|
|
break;
|
|
}
|
|
|
|
unchecked_options.erase("class");
|
|
if (!unchecked_options.empty()) {
|
|
throw exceptions::configuration_exception(fmt::format("Invalid compaction strategy options {} for chosen strategy type", unchecked_options));
|
|
}
|
|
}
|
|
|
|
// options is a map of compaction strategy options and their values.
|
|
// unchecked_options is an analogical map from which already checked options are deleted.
|
|
// This helps making sure that only allowed options are being set.
|
|
void compaction_strategy_impl::validate_options(const std::map<sstring, sstring>& options, std::map<sstring, sstring>& unchecked_options) {
|
|
validate_tombstone_threshold(options, unchecked_options);
|
|
validate_tombstone_compaction_interval(options, unchecked_options);
|
|
validate_unchecked_tombstone_compaction(options, unchecked_options);
|
|
|
|
auto it = options.find("enabled");
|
|
if (it != options.end() && it->second != "true" && it->second != "false") {
|
|
throw exceptions::configuration_exception(fmt::format("enabled value ({}) must be \"true\" or \"false\"", it->second));
|
|
}
|
|
unchecked_options.erase("enabled");
|
|
}
|
|
|
|
compaction_strategy_impl::compaction_strategy_impl(const std::map<sstring, sstring>& options) {
|
|
_tombstone_threshold = validate_tombstone_threshold(options);
|
|
_tombstone_compaction_interval = validate_tombstone_compaction_interval(options);
|
|
_unchecked_tombstone_compaction = validate_unchecked_tombstone_compaction(options);
|
|
}
|
|
|
|
} // namespace sstables
|
|
|
|
size_tiered_backlog_tracker::inflight_component
|
|
size_tiered_backlog_tracker::compacted_backlog(const compaction_backlog_tracker::ongoing_compactions& ongoing_compactions) const {
|
|
inflight_component in;
|
|
for (auto const& crp : ongoing_compactions) {
|
|
// A SSTable being compacted may not contribute to backlog if compaction strategy decided
|
|
// to perform a low-efficiency compaction when system is under little load, or when user
|
|
// performs major even though strategy is completely satisfied
|
|
if (!_contrib.sstables.contains(crp.first)) {
|
|
continue;
|
|
}
|
|
auto compacted = crp.second->compacted();
|
|
in.total_bytes += compacted;
|
|
in.contribution += compacted * log4(crp.first->data_size());
|
|
}
|
|
return in;
|
|
}
|
|
|
|
// Provides strong exception safety guarantees.
|
|
size_tiered_backlog_tracker::sstables_backlog_contribution size_tiered_backlog_tracker::calculate_sstables_backlog_contribution(const std::vector<sstables::shared_sstable>& all, const sstables::size_tiered_compaction_strategy_options& stcs_options) {
|
|
sstables_backlog_contribution contrib;
|
|
if (all.empty()) {
|
|
return contrib;
|
|
}
|
|
using namespace sstables;
|
|
|
|
// Deduce threshold from the last SSTable added to the set
|
|
// Low-efficiency jobs, which fan-in is smaller than min-threshold, will not have backlog accounted.
|
|
// That's because they can only run when system is under little load, and accounting them would result
|
|
// in efficient jobs acting more aggressive than they really have to.
|
|
// TODO: potentially switch to compaction manager's fan-in threshold, so to account for the dynamic
|
|
// fan-in threshold behavior.
|
|
const auto& newest_sst = std::ranges::max(all, std::less<generation_type>(), std::mem_fn(&sstable::generation));
|
|
auto threshold = newest_sst->get_schema()->min_compaction_threshold();
|
|
|
|
for (auto& bucket : size_tiered_compaction_strategy::get_buckets(all, stcs_options)) {
|
|
if (!size_tiered_compaction_strategy::is_bucket_interesting(bucket, threshold)) {
|
|
continue;
|
|
}
|
|
contrib.value += std::ranges::fold_left(bucket | std::views::transform([] (const shared_sstable& sst) -> double {
|
|
return sst->data_size() * log4(sst->data_size());
|
|
}), double(0.0f), std::plus{});
|
|
// Controller is disabled if exception is caught during add / remove calls, so not making any effort to make this exception safe
|
|
contrib.sstables.insert(bucket.begin(), bucket.end());
|
|
}
|
|
|
|
return contrib;
|
|
}
|
|
|
|
double size_tiered_backlog_tracker::backlog(const compaction_backlog_tracker::ongoing_writes& ow, const compaction_backlog_tracker::ongoing_compactions& oc) const {
|
|
inflight_component compacted = compacted_backlog(oc);
|
|
|
|
auto total_backlog_bytes = std::ranges::fold_left(_contrib.sstables | std::views::transform(std::mem_fn(&sstables::sstable::data_size)), uint64_t(0), std::plus{});
|
|
|
|
// Bail out if effective backlog is zero, which happens in a small window where ongoing compaction exhausted
|
|
// input files but is still sealing output files or doing managerial stuff like updating history table
|
|
if (total_backlog_bytes <= compacted.total_bytes) {
|
|
return 0;
|
|
}
|
|
|
|
// Formula for each SSTable is (Si - Ci) * log(T / Si)
|
|
// Which can be rewritten as: ((Si - Ci) * log(T)) - ((Si - Ci) * log(Si))
|
|
//
|
|
// For the meaning of each variable, please refer to the doc in size_tiered_backlog_tracker.hh
|
|
|
|
// Sum of (Si - Ci) for all SSTables contributing backlog
|
|
auto effective_backlog_bytes = total_backlog_bytes - compacted.total_bytes;
|
|
|
|
// Sum of (Si - Ci) * log (Si) for all SSTables contributing backlog
|
|
auto sstables_contribution = _contrib.value - compacted.contribution;
|
|
// This is subtracting ((Si - Ci) * log (Si)) from ((Si - Ci) * log(T)), yielding the final backlog
|
|
auto b = (effective_backlog_bytes * log4(_total_bytes)) - sstables_contribution;
|
|
return b > 0 ? b : 0;
|
|
}
|
|
|
|
// Provides strong exception safety guarantees.
|
|
void size_tiered_backlog_tracker::replace_sstables(const std::vector<sstables::shared_sstable>& old_ssts, const std::vector<sstables::shared_sstable>& new_ssts) {
|
|
auto tmp_all = _all;
|
|
auto tmp_total_bytes = _total_bytes;
|
|
tmp_all.reserve(_all.size() + new_ssts.size());
|
|
|
|
for (auto& sst : old_ssts) {
|
|
if (sst->data_size() > 0) {
|
|
auto erased = tmp_all.erase(sst);
|
|
if (erased) {
|
|
tmp_total_bytes -= sst->data_size();
|
|
}
|
|
}
|
|
}
|
|
for (auto& sst : new_ssts) {
|
|
if (sst->data_size() > 0) {
|
|
auto [_, inserted] = tmp_all.insert(sst);
|
|
if (inserted) {
|
|
tmp_total_bytes += sst->data_size();
|
|
}
|
|
}
|
|
}
|
|
auto tmp_contrib = calculate_sstables_backlog_contribution(tmp_all | std::ranges::to<std::vector>(), _stcs_options);
|
|
|
|
std::invoke([&] () noexcept {
|
|
_all = std::move(tmp_all);
|
|
_total_bytes = tmp_total_bytes;
|
|
_contrib = std::move(tmp_contrib);
|
|
});
|
|
}
|
|
|
|
namespace sstables {
|
|
|
|
extern logging::logger clogger;
|
|
|
|
// The backlog for TWCS is just the sum of the individual backlogs in each time window.
|
|
// We'll keep various SizeTiered backlog tracker objects-- one per window for the static SSTables.
|
|
// We then scan the current compacting and in-progress writes and matching them to existing time
|
|
// windows.
|
|
//
|
|
// With the above we have everything we need to just calculate the backlogs individually and sum
|
|
// them. Just need to be careful that for the current in progress backlog we may have to create
|
|
// a new object for the partial write at this time.
|
|
class time_window_backlog_tracker final : public compaction_backlog_tracker::impl {
|
|
time_window_compaction_strategy_options _twcs_options;
|
|
size_tiered_compaction_strategy_options _stcs_options;
|
|
std::unordered_map<api::timestamp_type, size_tiered_backlog_tracker> _windows;
|
|
|
|
api::timestamp_type lower_bound_of(api::timestamp_type timestamp) const {
|
|
timestamp_type ts = time_window_compaction_strategy::to_timestamp_type(_twcs_options.timestamp_resolution, timestamp);
|
|
return time_window_compaction_strategy::get_window_lower_bound(_twcs_options.sstable_window_size, ts);
|
|
}
|
|
public:
|
|
time_window_backlog_tracker(time_window_compaction_strategy_options twcs_options, size_tiered_compaction_strategy_options stcs_options)
|
|
: _twcs_options(twcs_options)
|
|
, _stcs_options(stcs_options)
|
|
{}
|
|
|
|
virtual double backlog(const compaction_backlog_tracker::ongoing_writes& ow, const compaction_backlog_tracker::ongoing_compactions& oc) const override {
|
|
std::unordered_map<api::timestamp_type, compaction_backlog_tracker::ongoing_writes> writes_per_window;
|
|
std::unordered_map<api::timestamp_type, compaction_backlog_tracker::ongoing_compactions> compactions_per_window;
|
|
double b = 0;
|
|
|
|
for (auto& wp : ow) {
|
|
auto bound = lower_bound_of(wp.second->maximum_timestamp());
|
|
writes_per_window[bound].insert(wp);
|
|
}
|
|
|
|
for (auto& cp : oc) {
|
|
auto bound = lower_bound_of(cp.first->get_stats_metadata().max_timestamp);
|
|
compactions_per_window[bound].insert(cp);
|
|
}
|
|
|
|
auto no_ow = compaction_backlog_tracker::ongoing_writes();
|
|
auto no_oc = compaction_backlog_tracker::ongoing_compactions();
|
|
// Match the in-progress backlogs to existing windows. Compactions should always match an
|
|
// existing windows. Writes in progress can fall into an non-existent window.
|
|
for (auto& windows : _windows) {
|
|
auto bound = windows.first;
|
|
auto* ow_this_window = &no_ow;
|
|
auto itw = writes_per_window.find(bound);
|
|
if (itw != writes_per_window.end()) {
|
|
ow_this_window = &itw->second;
|
|
}
|
|
auto* oc_this_window = &no_oc;
|
|
auto itc = compactions_per_window.find(bound);
|
|
if (itc != compactions_per_window.end()) {
|
|
oc_this_window = &itc->second;
|
|
}
|
|
b += windows.second.backlog(*ow_this_window, *oc_this_window);
|
|
if (itw != writes_per_window.end()) {
|
|
// We will erase here so we can keep track of which
|
|
// writes belong to existing windows. Writes that don't belong to any window
|
|
// are writes in progress to new windows and will be accounted in the final
|
|
// loop before we return
|
|
writes_per_window.erase(itw);
|
|
}
|
|
}
|
|
|
|
// Partial writes that don't belong to any window are accounted here.
|
|
for (auto& current : writes_per_window) {
|
|
b += size_tiered_backlog_tracker(_stcs_options).backlog(current.second, no_oc);
|
|
}
|
|
return b;
|
|
}
|
|
|
|
// Provides strong exception safety guarantees
|
|
virtual void replace_sstables(const std::vector<sstables::shared_sstable>& old_ssts, const std::vector<sstables::shared_sstable>& new_ssts) override {
|
|
struct replacement {
|
|
std::vector<sstables::shared_sstable> old_ssts;
|
|
std::vector<sstables::shared_sstable> new_ssts;
|
|
};
|
|
std::unordered_map<api::timestamp_type, replacement> per_window_replacement;
|
|
auto tmp_windows = _windows;
|
|
|
|
for (auto& sst : new_ssts) {
|
|
auto bound = lower_bound_of(sst->get_stats_metadata().max_timestamp);
|
|
if (!tmp_windows.contains(bound)) {
|
|
tmp_windows.emplace(bound, size_tiered_backlog_tracker(_stcs_options));
|
|
}
|
|
per_window_replacement[bound].new_ssts.push_back(std::move(sst));
|
|
}
|
|
for (auto& sst : old_ssts) {
|
|
auto bound = lower_bound_of(sst->get_stats_metadata().max_timestamp);
|
|
if (tmp_windows.contains(bound)) {
|
|
per_window_replacement[bound].old_ssts.push_back(std::move(sst));
|
|
}
|
|
}
|
|
|
|
for (auto& [bound, r] : per_window_replacement) {
|
|
// All windows must exist here, as windows are created for new files and will
|
|
// remain alive as long as there's a single file in them
|
|
auto it = tmp_windows.find(bound);
|
|
if (it == tmp_windows.end()) {
|
|
on_internal_error(clogger, fmt::format("window for bound {} not found", bound));
|
|
}
|
|
auto& w = it->second;
|
|
w.replace_sstables(r.old_ssts, r.new_ssts);
|
|
if (w.total_bytes() <= 0) {
|
|
tmp_windows.erase(bound);
|
|
}
|
|
}
|
|
|
|
std::invoke([&] () noexcept {
|
|
_windows = std::move(tmp_windows);
|
|
});
|
|
}
|
|
};
|
|
|
|
class leveled_compaction_backlog_tracker final : public compaction_backlog_tracker::impl {
|
|
// Because we can do SCTS in L0, we will account for that in the backlog.
|
|
// Whatever backlog we accumulate here will be added to the main backlog.
|
|
size_tiered_backlog_tracker _l0_scts;
|
|
std::vector<uint64_t> _size_per_level;
|
|
uint64_t _max_sstable_size;
|
|
public:
|
|
leveled_compaction_backlog_tracker(int32_t max_sstable_size_in_mb, size_tiered_compaction_strategy_options stcs_options)
|
|
: _l0_scts(stcs_options)
|
|
, _size_per_level(leveled_manifest::MAX_LEVELS, uint64_t(0))
|
|
, _max_sstable_size(max_sstable_size_in_mb * 1024 * 1024)
|
|
{}
|
|
|
|
virtual double backlog(const compaction_backlog_tracker::ongoing_writes& ow, const compaction_backlog_tracker::ongoing_compactions& oc) const override {
|
|
std::vector<uint64_t> effective_size_per_level = _size_per_level;
|
|
compaction_backlog_tracker::ongoing_writes l0_partial_writes;
|
|
compaction_backlog_tracker::ongoing_compactions l0_compacted;
|
|
|
|
for (auto& op : ow) {
|
|
auto level = op.second->level();
|
|
if (level == 0) {
|
|
l0_partial_writes.insert(op);
|
|
}
|
|
effective_size_per_level[level] += op.second->written();
|
|
}
|
|
|
|
for (auto& cp : oc) {
|
|
auto level = cp.first->get_sstable_level();
|
|
if (level == 0) {
|
|
l0_compacted.insert(cp);
|
|
}
|
|
effective_size_per_level[level] -= cp.second->compacted();
|
|
}
|
|
|
|
double b = _l0_scts.backlog(l0_partial_writes, l0_compacted);
|
|
|
|
size_t max_populated_level = [&effective_size_per_level] () -> size_t {
|
|
auto it = std::find_if(effective_size_per_level.rbegin(), effective_size_per_level.rend(), [] (uint64_t s) {
|
|
return s != 0;
|
|
});
|
|
if (it == effective_size_per_level.rend()) {
|
|
return 0;
|
|
}
|
|
return std::distance(it, effective_size_per_level.rend()) - 1;
|
|
}();
|
|
|
|
// The LCS goal is to achieve a layout where for every level L, sizeof(L+1) >= (sizeof(L) * fan_out)
|
|
// If table size is S, which is the sum of size of all levels, the target size of the highest level
|
|
// is S % 1.111, where 1.111 refers to strategy's space amplification goal.
|
|
// As level L is fan_out times smaller than L+1, level L-1 is fan_out^2 times smaller than L+1,
|
|
// and so on, the target size of any level can be easily calculated.
|
|
|
|
static constexpr auto fan_out = leveled_manifest::leveled_fan_out;
|
|
static constexpr double space_amplification_goal = 1.111;
|
|
uint64_t total_size = std::accumulate(effective_size_per_level.begin(), effective_size_per_level.end(), uint64_t(0));
|
|
uint64_t target_max_level_size = std::ceil(total_size / space_amplification_goal);
|
|
|
|
auto target_level_size = [&] (size_t level) {
|
|
auto r = std::ceil(target_max_level_size / std::pow(fan_out, max_populated_level - level));
|
|
return std::max(uint64_t(r), _max_sstable_size);
|
|
};
|
|
|
|
// The backlog for a level L is the amount of bytes to be compacted, such that:
|
|
// sizeof(L) <= sizeof(L+1) * fan_out
|
|
// If we start from L0, then L0 backlog is (sizeof(L0) - target_sizeof(L0)) * fan_out, where
|
|
// (sizeof(L0) - target_sizeof(L0)) is the amount of data to be promoted into next level
|
|
// By summing the backlog for each level, we get the total amount of work for all levels to
|
|
// reach their target size.
|
|
for (size_t level = 0; level < max_populated_level; ++level) {
|
|
auto lsize = effective_size_per_level[level];
|
|
auto target_lsize = target_level_size(level);
|
|
|
|
// Current level satisfies the goal, skip to the next one.
|
|
if (lsize <= target_lsize) {
|
|
continue;
|
|
}
|
|
auto next_level = level + 1;
|
|
auto bytes_for_next_level = lsize - target_lsize;
|
|
|
|
// The fan_out is usually 10. But if the level above us is not fully populated -- which
|
|
// can happen when a level is still being born, we don't want that to jump abruptly.
|
|
// So what we will do instead is to define the fan out as the minimum between 10
|
|
// and the number of sstables that are estimated to be there.
|
|
unsigned estimated_next_level_ssts = (effective_size_per_level[next_level] + _max_sstable_size - 1) / _max_sstable_size;
|
|
auto estimated_fan_out = std::min(fan_out, estimated_next_level_ssts);
|
|
|
|
b += bytes_for_next_level * estimated_fan_out;
|
|
|
|
// Update size of next level, as data from current level can be promoted as many times
|
|
// as needed, and therefore needs to be included in backlog calculation for the next
|
|
// level, if needed.
|
|
effective_size_per_level[next_level] += bytes_for_next_level;
|
|
}
|
|
return b;
|
|
}
|
|
|
|
// Provides strong exception safety guarantees
|
|
virtual void replace_sstables(const std::vector<sstables::shared_sstable>& old_ssts, const std::vector<sstables::shared_sstable>& new_ssts) override {
|
|
auto tmp_size_per_level = _size_per_level;
|
|
std::vector<sstables::shared_sstable> l0_old_ssts, l0_new_ssts;
|
|
for (auto& sst : new_ssts) {
|
|
auto level = sst->get_sstable_level();
|
|
tmp_size_per_level[level] += sst->data_size();
|
|
if (level == 0) {
|
|
l0_new_ssts.push_back(std::move(sst));
|
|
}
|
|
}
|
|
for (auto& sst : old_ssts) {
|
|
auto level = sst->get_sstable_level();
|
|
tmp_size_per_level[level] -= sst->data_size();
|
|
if (level == 0) {
|
|
l0_old_ssts.push_back(std::move(sst));
|
|
}
|
|
}
|
|
if (l0_old_ssts.size() || l0_new_ssts.size()) {
|
|
// stcs replace_sstables guarantees strong exception safety
|
|
_l0_scts.replace_sstables(std::move(l0_old_ssts), std::move(l0_new_ssts));
|
|
}
|
|
std::invoke([&] () noexcept {
|
|
_size_per_level = std::move(tmp_size_per_level);
|
|
});
|
|
}
|
|
};
|
|
|
|
struct unimplemented_backlog_tracker final : public compaction_backlog_tracker::impl {
|
|
virtual double backlog(const compaction_backlog_tracker::ongoing_writes& ow, const compaction_backlog_tracker::ongoing_compactions& oc) const override {
|
|
return compaction_controller::disable_backlog;
|
|
}
|
|
virtual void replace_sstables(const std::vector<sstables::shared_sstable>& old_ssts, const std::vector<sstables::shared_sstable>& new_ssts) override {}
|
|
};
|
|
|
|
struct null_backlog_tracker final : public compaction_backlog_tracker::impl {
|
|
virtual double backlog(const compaction_backlog_tracker::ongoing_writes& ow, const compaction_backlog_tracker::ongoing_compactions& oc) const override {
|
|
return 0;
|
|
}
|
|
virtual void replace_sstables(const std::vector<sstables::shared_sstable>& old_ssts, const std::vector<sstables::shared_sstable>& new_ssts) override {}
|
|
};
|
|
|
|
//
|
|
// Null compaction strategy is the default compaction strategy.
|
|
// As the name implies, it does nothing.
|
|
//
|
|
class null_compaction_strategy : public compaction_strategy_impl {
|
|
public:
|
|
virtual compaction_descriptor get_sstables_for_compaction(table_state& table_s, strategy_control& control) override {
|
|
return sstables::compaction_descriptor();
|
|
}
|
|
|
|
virtual int64_t estimated_pending_compactions(table_state& table_s) const override {
|
|
return 0;
|
|
}
|
|
|
|
virtual compaction_strategy_type type() const override {
|
|
return compaction_strategy_type::null;
|
|
}
|
|
|
|
virtual std::unique_ptr<compaction_backlog_tracker::impl> make_backlog_tracker() const override {
|
|
return std::make_unique<null_backlog_tracker>();
|
|
}
|
|
};
|
|
|
|
leveled_compaction_strategy::leveled_compaction_strategy(const std::map<sstring, sstring>& options)
|
|
: compaction_strategy_impl(options)
|
|
, _max_sstable_size_in_mb(calculate_max_sstable_size_in_mb(compaction_strategy_impl::get_value(options, SSTABLE_SIZE_OPTION)))
|
|
, _stcs_options(options)
|
|
{
|
|
}
|
|
|
|
// options is a map of compaction strategy options and their values.
|
|
// unchecked_options is an analogical map from which already checked options are deleted.
|
|
// This helps making sure that only allowed options are being set.
|
|
void leveled_compaction_strategy::validate_options(const std::map<sstring, sstring>& options, std::map<sstring, sstring>& unchecked_options) {
|
|
size_tiered_compaction_strategy_options::validate(options, unchecked_options);
|
|
|
|
auto tmp_value = compaction_strategy_impl::get_value(options, SSTABLE_SIZE_OPTION);
|
|
auto min_sstables_size = cql3::statements::property_definitions::to_long(SSTABLE_SIZE_OPTION, tmp_value, DEFAULT_MAX_SSTABLE_SIZE_IN_MB);
|
|
if (min_sstables_size <= 0) {
|
|
throw exceptions::configuration_exception(fmt::format("{} value ({}) must be positive", SSTABLE_SIZE_OPTION, min_sstables_size));
|
|
}
|
|
unchecked_options.erase(SSTABLE_SIZE_OPTION);
|
|
}
|
|
|
|
std::unique_ptr<compaction_backlog_tracker::impl> leveled_compaction_strategy::make_backlog_tracker() const {
|
|
return std::make_unique<leveled_compaction_backlog_tracker>(_max_sstable_size_in_mb, _stcs_options);
|
|
}
|
|
|
|
int32_t
|
|
leveled_compaction_strategy::calculate_max_sstable_size_in_mb(std::optional<sstring> option_value) const {
|
|
using namespace cql3::statements;
|
|
auto max_size = property_definitions::to_int(SSTABLE_SIZE_OPTION, option_value, DEFAULT_MAX_SSTABLE_SIZE_IN_MB);
|
|
|
|
if (max_size >= 1000) {
|
|
leveled_manifest::logger.warn("Max sstable size of {}MB is configured; having a unit of compaction this large is probably a bad idea",
|
|
max_size);
|
|
} else if (max_size < 50) {
|
|
leveled_manifest::logger.warn("Max sstable size of {}MB is configured. Testing done for CASSANDRA-5727 indicates that performance" \
|
|
" improves up to 160MB", max_size);
|
|
}
|
|
return max_size;
|
|
}
|
|
|
|
time_window_compaction_strategy::time_window_compaction_strategy(const std::map<sstring, sstring>& options)
|
|
: compaction_strategy_impl(options)
|
|
, _options(options)
|
|
, _stcs_options(options)
|
|
{
|
|
if (!options.contains(TOMBSTONE_COMPACTION_INTERVAL_OPTION) && !options.contains(TOMBSTONE_THRESHOLD_OPTION)) {
|
|
_disable_tombstone_compaction = true;
|
|
clogger.debug("Disabling tombstone compactions for TWCS");
|
|
} else {
|
|
clogger.debug("Enabling tombstone compactions for TWCS");
|
|
}
|
|
_use_clustering_key_filter = true;
|
|
}
|
|
|
|
// options is a map of compaction strategy options and their values.
|
|
// unchecked_options is an analogical map from which already checked options are deleted.
|
|
// This helps making sure that only allowed options are being set.
|
|
void time_window_compaction_strategy::validate_options(const std::map<sstring, sstring>& options, std::map<sstring, sstring>& unchecked_options) {
|
|
time_window_compaction_strategy_options::validate(options, unchecked_options);
|
|
size_tiered_compaction_strategy_options::validate(options, unchecked_options);
|
|
}
|
|
|
|
std::unique_ptr<compaction_backlog_tracker::impl> time_window_compaction_strategy::make_backlog_tracker() const {
|
|
return std::make_unique<time_window_backlog_tracker>(_options, _stcs_options);
|
|
}
|
|
|
|
} // namespace sstables
|
|
|
|
namespace sstables {
|
|
|
|
size_tiered_compaction_strategy::size_tiered_compaction_strategy(const std::map<sstring, sstring>& options)
|
|
: compaction_strategy_impl(options)
|
|
, _options(options)
|
|
{}
|
|
|
|
size_tiered_compaction_strategy::size_tiered_compaction_strategy(const size_tiered_compaction_strategy_options& options)
|
|
: _options(options)
|
|
{}
|
|
|
|
// options is a map of compaction strategy options and their values.
|
|
// unchecked_options is an analogical map from which already checked options are deleted.
|
|
// This helps making sure that only allowed options are being set.
|
|
void size_tiered_compaction_strategy::validate_options(const std::map<sstring, sstring>& options, std::map<sstring, sstring>& unchecked_options) {
|
|
size_tiered_compaction_strategy_options::validate(options, unchecked_options);
|
|
}
|
|
|
|
std::unique_ptr<compaction_backlog_tracker::impl> size_tiered_compaction_strategy::make_backlog_tracker() const {
|
|
return std::make_unique<size_tiered_backlog_tracker>(_options);
|
|
}
|
|
|
|
compaction_strategy::compaction_strategy(::shared_ptr<compaction_strategy_impl> impl)
|
|
: _compaction_strategy_impl(std::move(impl)) {}
|
|
compaction_strategy::compaction_strategy() = default;
|
|
compaction_strategy::~compaction_strategy() = default;
|
|
compaction_strategy::compaction_strategy(const compaction_strategy&) = default;
|
|
compaction_strategy::compaction_strategy(compaction_strategy&&) = default;
|
|
compaction_strategy& compaction_strategy::operator=(compaction_strategy&&) = default;
|
|
|
|
compaction_strategy_type compaction_strategy::type() const {
|
|
return _compaction_strategy_impl->type();
|
|
}
|
|
|
|
compaction_descriptor compaction_strategy::get_sstables_for_compaction(table_state& table_s, strategy_control& control) {
|
|
return _compaction_strategy_impl->get_sstables_for_compaction(table_s, control);
|
|
}
|
|
|
|
compaction_descriptor compaction_strategy::get_major_compaction_job(table_state& table_s, std::vector<sstables::shared_sstable> candidates) {
|
|
return _compaction_strategy_impl->get_major_compaction_job(table_s, std::move(candidates));
|
|
}
|
|
|
|
std::vector<compaction_descriptor> compaction_strategy::get_cleanup_compaction_jobs(table_state& table_s, std::vector<shared_sstable> candidates) const {
|
|
return _compaction_strategy_impl->get_cleanup_compaction_jobs(table_s, std::move(candidates));
|
|
}
|
|
|
|
void compaction_strategy::notify_completion(table_state& table_s, const std::vector<shared_sstable>& removed, const std::vector<shared_sstable>& added) {
|
|
_compaction_strategy_impl->notify_completion(table_s, removed, added);
|
|
}
|
|
|
|
bool compaction_strategy::parallel_compaction() const {
|
|
return _compaction_strategy_impl->parallel_compaction();
|
|
}
|
|
|
|
int64_t compaction_strategy::estimated_pending_compactions(table_state& table_s) const {
|
|
return _compaction_strategy_impl->estimated_pending_compactions(table_s);
|
|
}
|
|
|
|
bool compaction_strategy::use_clustering_key_filter() const {
|
|
return _compaction_strategy_impl->use_clustering_key_filter();
|
|
}
|
|
|
|
compaction_backlog_tracker compaction_strategy::make_backlog_tracker() const {
|
|
return compaction_backlog_tracker(_compaction_strategy_impl->make_backlog_tracker());
|
|
}
|
|
|
|
sstables::compaction_descriptor
|
|
compaction_strategy::get_reshaping_job(std::vector<shared_sstable> input, schema_ptr schema, reshape_config cfg) const {
|
|
return _compaction_strategy_impl->get_reshaping_job(std::move(input), schema, cfg);
|
|
}
|
|
|
|
uint64_t compaction_strategy::adjust_partition_estimate(const mutation_source_metadata& ms_meta, uint64_t partition_estimate, schema_ptr schema) const {
|
|
return _compaction_strategy_impl->adjust_partition_estimate(ms_meta, partition_estimate, std::move(schema));
|
|
}
|
|
|
|
reader_consumer_v2 compaction_strategy::make_interposer_consumer(const mutation_source_metadata& ms_meta, reader_consumer_v2 end_consumer) const {
|
|
return _compaction_strategy_impl->make_interposer_consumer(ms_meta, std::move(end_consumer));
|
|
}
|
|
|
|
bool compaction_strategy::use_interposer_consumer() const {
|
|
return _compaction_strategy_impl->use_interposer_consumer();
|
|
}
|
|
|
|
compaction_strategy make_compaction_strategy(compaction_strategy_type strategy, const std::map<sstring, sstring>& options) {
|
|
::shared_ptr<compaction_strategy_impl> impl;
|
|
|
|
switch (strategy) {
|
|
case compaction_strategy_type::null:
|
|
impl = ::make_shared<null_compaction_strategy>();
|
|
break;
|
|
case compaction_strategy_type::size_tiered:
|
|
impl = ::make_shared<size_tiered_compaction_strategy>(options);
|
|
break;
|
|
case compaction_strategy_type::leveled:
|
|
impl = ::make_shared<leveled_compaction_strategy>(options);
|
|
break;
|
|
case compaction_strategy_type::time_window:
|
|
impl = ::make_shared<time_window_compaction_strategy>(options);
|
|
break;
|
|
case compaction_strategy_type::incremental:
|
|
impl = make_shared<incremental_compaction_strategy>(incremental_compaction_strategy(options));
|
|
break;
|
|
default:
|
|
throw std::runtime_error("strategy not supported");
|
|
}
|
|
|
|
return compaction_strategy(std::move(impl));
|
|
}
|
|
|
|
future<reshape_config> make_reshape_config(const sstables::storage& storage, reshape_mode mode) {
|
|
co_return sstables::reshape_config{
|
|
.mode = mode,
|
|
.free_storage_space = co_await storage.free_space() / smp::count,
|
|
};
|
|
}
|
|
|
|
std::unique_ptr<sstable_set_impl> incremental_compaction_strategy::make_sstable_set(schema_ptr schema) const {
|
|
return std::make_unique<partitioned_sstable_set>(std::move(schema), false);
|
|
}
|
|
|
|
}
|
|
|
|
namespace compaction {
|
|
|
|
compaction_strategy_state compaction_strategy_state::make(const compaction_strategy& cs) {
|
|
switch (cs.type()) {
|
|
case compaction_strategy_type::null:
|
|
case compaction_strategy_type::size_tiered:
|
|
case compaction_strategy_type::incremental:
|
|
return compaction_strategy_state(default_empty_state{});
|
|
case compaction_strategy_type::leveled:
|
|
return compaction_strategy_state(leveled_compaction_strategy_state{});
|
|
case compaction_strategy_type::time_window:
|
|
return compaction_strategy_state(time_window_compaction_strategy_state{});
|
|
default:
|
|
throw std::runtime_error("strategy not supported");
|
|
}
|
|
}
|
|
|
|
}
|