mirror of
https://github.com/scylladb/scylladb.git
synced 2026-05-28 18:50:53 +00:00
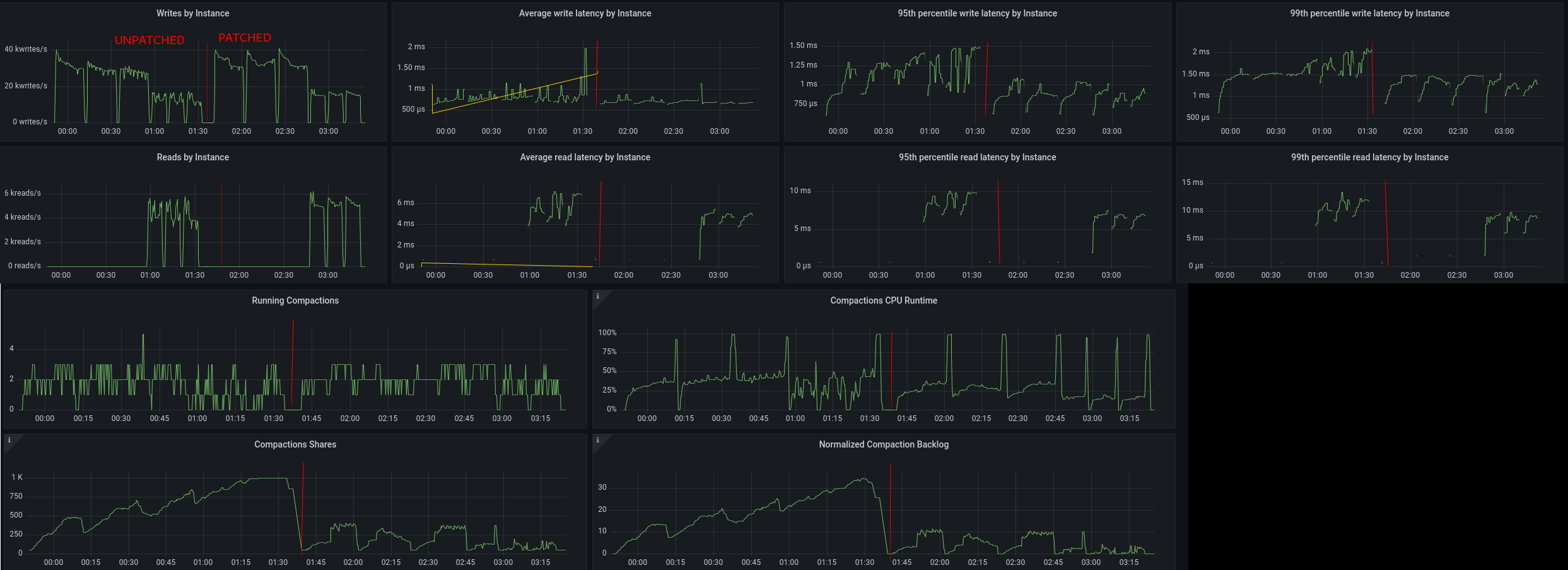
" Problem statement ================= Today, compaction can act much more aggressive than it really has to, because the strategy and its definition of backlog are completely decoupled. The backlog definition for size-tiered, which is inherited by all strategies (e.g.: LCS L0, TWCS' windows), is built on the assumption that the world must reach the state of zero amplification. But that's unrealistic and goes against the intent amplification defined by the compaction strategy. For example, size tiered is a write oriented strategy which allows for extra space amplification for compaction to keep up with the high write rate. It can be seen today, in many deployments, that compaction shares is either close to 1000, or even stuck at 1000, even though there's nothing to be done, i.e. the compaction strategy is completely satisfied. When there's a single sstable per tier, for example. This means that whenever a new compaction job kicks in, it will act much more aggressive because of the high shares, caused by false backlog of the existing tables. This translates into higher P99 latencies and reduced throughput. Solution ======== This problem can be fixed, as proposed in the document "Fixing compaction aggressiveness due to suboptimal definition of zero backlog by controller" [1], by removing backlog of tiers that don't have to be compacted now, like a tier that has a single file. That's about coupling the strategy goal with the backlog definition. So once strategy becomes satisfied, so will the controller. Low-efficiency compaction, like compacting 2 files only or cross-tier, only happens when system is under little load and can proceed at a slower pace. Once efficient jobs show up, ongoing compactions, even if inefficient, will get more shares (as efficient jobs add to the backlog) so compaction won't fall behind. With this approach, throughput and latency is improved as cpu time is no longer stolen (unnecessarily) from the foreground requests. [1]: https://docs.google.com/document/d/1EQnXXGWg6z7VAwI4u8AaUX1vFduClaf6WOMt2wem5oQ Results ======= Test sequentially populates 3 tables and then run a mixed workload on them, where disk:memory ratio (usage) reaches ~30:1 at the peak. Please find graphs here: https://user-images.githubusercontent.com/1409139/153687219-32368a35-ac63-461b-a362-64dbe8449a00.png 1) Patched version started at ~01:30 2) On population phase, throughput increase and lower P99 write latency can be clearly observed. 3) On mixed phase, throughput increase and lower P99 write and read latency can also be clearly observed. 4) Compaction CPU time sometimes reach ~100% because of the delay between each loader. 5) On unpatched version, it can be seen that backlog keeps growing even when though strategies become satisfied, so compaction is using much more CPU time in comparison. Patched version correctly clears the backlog. Can also be found at: github.com/raphaelsc/scylla.git compaction-controller-v5 tests: UNIT(dev, debug). " * 'compaction-controller-v5' of https://github.com/raphaelsc/scylla: tests: Add compaction controller test test/lib/sstable_utils: Set bytes_on_disk for fake SSTables compaction/size_tiered_backlog_tracker.hh: Use unsigned type for inflight component compaction: Redefine compaction backlog to tame compaction aggressiveness compaction_backlog_tracker: Batch changes through a new replacement interface table: Disable backlog tracker when stopping table compaction_backlog_tracker: make disable() public compaction_backlog_tracker: Clear tracker state when disabled compaction: Add normalized backlog metric compaction: make size_tiered_compaction_strategy static
{kind=link}