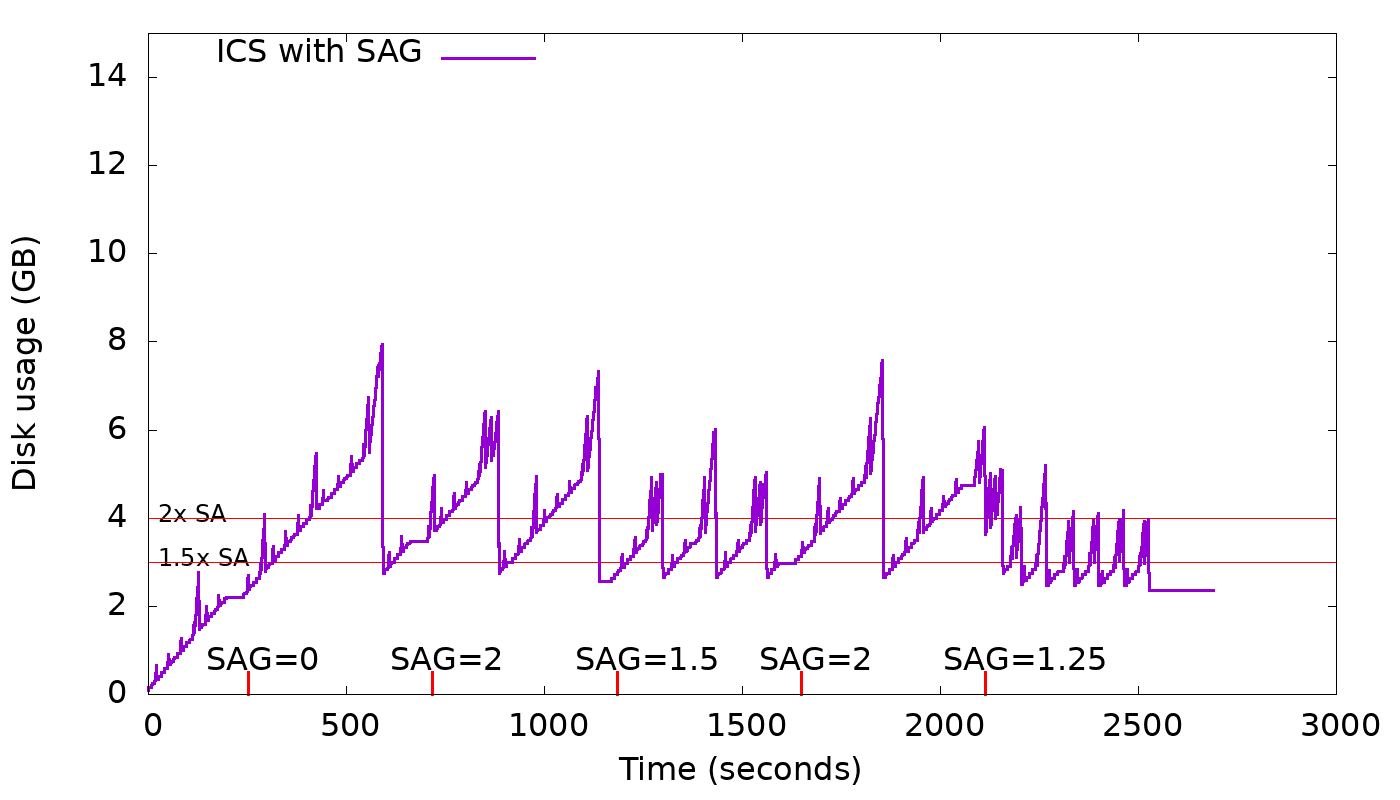
ICS is a compaction strategy that inherits size tiered properties -- therefore it's write optimized too -- but fixes its space overhead of 100% due to input files being only released on completion. That's achieved with the concept of sstable run (similar in concept to LCS levels) which breaks a large sstable into fixed-size chunks (1G by default), known as run fragments. ICS picks similar-sized runs for compaction, and fragments of those runs can be released incrementally as they're compacted, reducing the space overhead to about (number_of_input_runs * 1G). This allows user to increase storage density of nodes (from 50% to ~80%), reducing the cost of ownership. NOTE: test_system_schema_version_is_stable adjusted to account for batchlog using IncrementalCompactionStrategy contains: compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh) compaction/CMakeLists.txt: include ICS cc files configure.py: changes for ICS files, includes test db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported db/system_keyspace: pick ICS for some system tables schema/schema.hh: ICS becomes default test/boost: Add incremental_compaction_test.cc test/boost/sstable_compaction_test.cc: ICS related changes test/cqlpy/test_compaction_strategy_validation.py: ICS related changes docs/architecture/compaction/compaction-strategies.rst: changes to ICS section docs/cql/compaction.rst: changes to ICS section docs/cql/ddl.rst: adds reference to ICS options docs/getting-started/system-requirements.rst: updates sentence mentioning ICS docs/kb/compaction.rst: changes to ICS section docs/kb/garbage-collection-ics.rst: add file docs/kb/index.rst: add reference to <garbage-collection-ics> docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section some relevant commits throughout the ICS history: commit 434b97699b39c570d0d849d372bf64f418e5c692 Merge: 105586f747 30250749b8 Author: Paweł Dziepak <pdziepak@scylladb.com> Date: Tue Mar 12 12:14:23 2019 +0000 Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael " Introduce new compaction strategy which is essentially like size tiered but will work with the existing incremental compaction. Thus incremental compaction strategy. It works like size tiered, but each element composing a tier is a sstable run, meaning that the compaction strategy will look for N similar-sized sstable runs to compact, not just individual sstables. Parameters: * "sstable_size_in_mb": defines the maximum sstable (fragment) size composing a sstable run, which impacts directly the disk space requirement which is improved with incremental compaction. The lower the value the lower the space requirement for compaction because fragments involved will be released more frequently. * all others available in size tiered compaction strategy HOWTO ===== To change an existing table to use it, do: ALTER TABLE mykeyspace.mytable WITH compaction = {'class' : 'IncrementalCompactionStrategy'}; Set fragment size: ALTER TABLE mykeyspace.mytable WITH compaction = {'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 } " commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1 Merge: dca89ce7a5 e08ef3e1a3 Author: Avi Kivity <avi@scylladb.com> Date: Tue Sep 8 11:31:52 2020 +0300 Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael " A new option, space_amplification_goal (SAG), is being added to ICS. This option will allow ICS user to set a goal on the space amplification (SA). It's not supposed to be an upper bound on the space amplification, but rather, a goal. This new option will be disabled by default as it doesn't benefit write-only (no overwrites) workloads and could hurt severely the write performance. The strategy is free to delay triggering this new behavior, in order to increase overall compaction efficiency. The graph below shows how this feature works in practice for different values of space_amplification_goal: https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png When strategy finds space amplification crossed space_amplification_goal, it will work on reducing the SA by doing a cross-tier compaction on the two largest tiers. This feature works only on the two largest tiers, because taking into account others, could hurt the compaction efficiency which is based on the fact that the more similar-sized sstables are compacted together the higher the compaction efficiency will be. With SAG enabled, min_threshold only plays an important role on the smallest tiers, given that the second-largest tier could be compacted into the largest tier for a space_amplification_goal value < 2. By making the options space_amplification_goal and min_threshold independent, user will be able to tune write amplification and space amplification, based on the needs. The lower the space_amplification_goal the higher the write amplification, but by increasing the min threshold, the write amplification can be decreased to a desired amount. " commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1 Author: Raphael S. Carvalho <raphaelsc@scylladb.com> Date: Sat Oct 16 13:41:46 2021 -0300 compaction: ICS: Add garbage collection Today, ICS lacks an approach to persist expired tombstones in a timely manner, which is a problem because accumulation of tombstones are known to affecting latency considerably. For an expired tombstone to be purged, it has to reach the top of the LSM tree and hope that older overlapping data wasn't introduced at the bottom. The condition are there and must be satisfied to avoid data resurrection. STCS, today, has an inefficient garbage collection approach because it only picks a single sstable, which satisfies the tombstone density threshold and file staleness. That's a problem because overlapping data either on same tier or smaller tiers will prevent tombstones from being purged. Also, nothing is done to push the tombstones to the top of the tree, for the conditions to be eventually satisfied. Due to incremental compaction, ICS can more easily have an effecient GC by doing cross-tier compaction of relevant tiers. The trigger will be file staleness and tombstone density, which threshold values can be configured by tombstone_compaction_interval and tombstone_threshold, respectively. If ICS finds a tier which meets both conditions, then that tier and the larger[1] *and* closest-in-size[2] tier will be compacted together. [1]: A larger tier is picked because we want tombstones to eventually reach the top of the tree. [2]: It also has to be the closest-in-size tier as the smaller the size difference the higher the efficiency of the compaction. We want to minimize write amplification as much as possible. The staleness condition is there to prevent the same file from being picked over and over again in a short interval. With this approach, ICS will be continuously working to purge garbage while not hurting overall efficiency on a steady state, as same-tier compactions are prioritized. Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com> Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com> Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com> Closes scylladb/scylladb#22063
{kind=link}
111 lines
5.6 KiB
ReStructuredText
111 lines
5.6 KiB
ReStructuredText
===================
|
||
System Requirements
|
||
===================
|
||
|
||
.. _system-requirements-supported-platforms:
|
||
|
||
Supported Platforms
|
||
===================
|
||
ScyllaDB runs on 64-bit Linux. The x86_64 and AArch64 architectures are supported (AArch64 support includes AWS EC2 Graviton).
|
||
|
||
See :doc:`OS Support by Platform and Version </getting-started/os-support>` for information about
|
||
supported operating systems, distros, and versions.
|
||
|
||
See :doc:`Cloud Instance Recommendations for AWS, GCP, and Azure </getting-started/cloud-instance-recommendations>` for information
|
||
about instance types recommended for cloud deployments.
|
||
|
||
.. _system-requirements-hardware:
|
||
|
||
Hardware Requirements
|
||
=====================
|
||
|
||
It’s recommended to have a balanced setup. If there are only 4-8 :term:`Logical Cores <Logical Core (lcore)>`, large disks or 10Gbps networking may not be needed.
|
||
This works in the opposite direction as well.
|
||
ScyllaDB can be used in many types of installation environments.
|
||
|
||
To see which system would best suit your workload requirements, use the `ScyllaDB Sizing Calculator <https://www.scylladb.com/product/scylla-cloud/get-pricing/>`_ to customize ScyllaDB for your usage.
|
||
|
||
|
||
|
||
Core Requirements
|
||
-----------------
|
||
ScyllaDB tries to maximize the resource usage of all system components. The shard-per-core approach allows linear scale-up with the number of cores. As you have more cores, it makes sense to balance the other resources, from memory to network.
|
||
|
||
CPU
|
||
^^^
|
||
|
||
ScyllaDB requires modern Intel/AMD CPUs that support the SSE4.2 instruction set and will not boot without it.
|
||
|
||
|
||
ScyllaDB supports the following CPUs:
|
||
|
||
* Intel core: Westmere and later (2010)
|
||
* Intel atom: Goldmont and later (2016)
|
||
* AMD low power: Jaguar and later (2013)
|
||
* AMD standard: Bulldozer and later (2011)
|
||
* Apple M1 and M2
|
||
* Ampere Altra
|
||
* AWS Graviton, Graviton2, Graviton3
|
||
|
||
|
||
In terms of the number of cores, any number will work since ScyllaDB scales up with the number of cores.
|
||
A practical approach is to use a large number of cores as long as the hardware price remains reasonable.
|
||
Between 20-60 logical cores (including hyperthreading) is a recommended number. However, any number will fit.
|
||
When using virtual machines, containers, or the public cloud, remember that each virtual CPU is mapped to a single logical core, or thread.
|
||
Allow ScyllaDB to run independently without any additional CPU intensive tasks on the same server/cores as ScyllaDB.
|
||
|
||
.. _system-requirements-memory:
|
||
|
||
Memory Requirements
|
||
-------------------
|
||
The more memory available, the better ScyllaDB performs, as ScyllaDB uses all of the available memory for caching. The wider the rows are in the schema, the more memory will be required. 64 GB-256 GB is the recommended range for a medium to high workload. Memory requirements are calculated based on the number of :abbr:`lcores (logical cores)` you are using in your system.
|
||
|
||
* Recommended size: 16 GB or 2GB per lcore (whichever is higher)
|
||
* Maximum: 1 TiB per lcore, up to 256 lcores
|
||
* Minimum:
|
||
|
||
- For test environments: 1 GB or 256 MiB per lcore (whichever is higher)
|
||
- For production environments: 4 GB or 0.5 GB per lcore (whichever is higher)
|
||
|
||
.. _system-requirements-disk:
|
||
|
||
Disk Requirements
|
||
-----------------
|
||
|
||
SSD
|
||
^^^
|
||
We highly recommend SSD and local disks. ScyllaDB is built for a large volume of data and large storage per node.
|
||
You can use up to 100:1 Disk/RAM ratio, with 30:1 Disk/RAM ratio as a good rule of thumb; for example, 30 TB of storage requires 1 TB of RAM.
|
||
We recommend a RAID-0 setup and a replication factor of 3 within the local datacenter (RF=3) when there are multiple drives.
|
||
|
||
HDD
|
||
^^^
|
||
HDDs are supported but may become a bottleneck. Some workloads may work with HDDs, especially if they play nice and minimize random seeks. An example of an HDD-friendly workload is a write-mostly (98% writes) workload, with minimal random reads. If you use HDDs, try to allocate a separate disk for the commit log (not needed with SSDs).
|
||
|
||
Disk Space
|
||
^^^^^^^^^^
|
||
ScyllaDB is flushing memtables to SSTable data files for persistent storage. SSTables are periodically compacted to improve performance by merging and rewriting data and discarding the old one. Depending on compaction strategy, disk space utilization temporarily increases during compaction. For this reason, you should leave an adequate amount of free disk space available on a node.
|
||
Use the following table as a guidelines for the minimum disk space requirements based on the compaction strategy:
|
||
|
||
====================================== =========== ============
|
||
Compaction Strategy Recommended Minimum
|
||
====================================== =========== ============
|
||
Size Tiered Compaction Strategy (STCS) 50% 70%
|
||
-------------------------------------- ----------- ------------
|
||
Leveled Compaction Strategy (LCS) 50% 80%
|
||
-------------------------------------- ----------- ------------
|
||
Time-window Compaction Strategy (TWCS) 50% 70%
|
||
-------------------------------------- ----------- ------------
|
||
Incremental Compaction Strategy (ICS) 70% 80%
|
||
====================================== =========== ============
|
||
|
||
Use the default ICS unless you'll have a clear understanding that another strategy is better for your use case. More on :doc:`choosing a Compaction Strategy </architecture/compaction/compaction-strategies>`.
|
||
In order to maintain a high level of service availability, keep 50% to 20% free disk space at all times!
|
||
|
||
.. _system-requirements-network:
|
||
|
||
Network Requirements
|
||
====================
|
||
|
||
A network speed of 10 Gbps or more is recommended, especially for large nodes. To tune the interrupts and their queues, run the ScyllaDB setup scripts.
|