It was assumed that offstrategy compaction is always triggered by streaming/repair
where it would inherit the caller's scheduling group.
However, offstrategy is triggered by a timer via table::_off_strategy_trigger so I don't see
how the expiration of this timer will inherit anything from streaming/repair.
Also, since d309a86, offstrategy compaction
may be triggered by the api where it will run in the default scheduling group.
The bottom line is that the compaction manager needs to explicitly perform offstrategy compaction
in the maintenance scheduling group similar to `perform_sstable_scrub_validate_mode`.
Fixes#10151
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220302084821.2239706-1-bhalevy@scylladb.com>
"
The set puts the code in question into a helper, coroutinizes it, removes
some code duplication, improves a corner case and relaxes logging.
tests: unit(dev), dtest.simple_boot_shutdown(v1, dev)
"
* 'br-join-ring-wait-sanitize-2' of https://github.com/xemul/scylla:
storage_service: De-bloat waiting logs
storage_service: Indentation fix after previous changes
storage_service: Negate loop breaking check
storage_service: Fix off-by-one-second waiting
storage_service: Pack schema waiting loop
storage_service: Out-line schema waiting code
storage_service: Make int delay be std::chrono::milliseconds
First thing is that logging can be done with logger methods,
not with set_mode() because the mode is already set at this
place.
Second thing is that pre-update_pending_ranges logs are excessive,
as the update_pending_ranges logs its progress itself.
Third is that post-logging is also exsessive -- there are more
logs after those lines.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
In simple words turn
while {
if (continue) {
do_something
} else {
break
}
}
into
while {
if (!continue) {
break;
}
do_something
}
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The waiting loop needs to abort once a minute passes and does
it in one second steps. However, the expiration check happens
after sleep, which effectively throws this last second away.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The newly created method looks like this
wait_for_schema_agreement
update_pending_ranges
while (consistent_range_movement) {
pause
wait_for_schema_agreement
update_pending_range
}
This patch packs the wait_for_schema_agreement+update_pending_range
pairs into a single loop.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
And coroutinize while moving. No other changes.
While the code in question runs in a thread context and can enjoy
synchronous .get() calls, it's still better if it doesn't make any
assumptions about its environment. The ring joining code is changing
and new intermediate helpers should better be on the safe side from
the very beginning.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
It's milliseconds and is converted back and forth in join_token_ring().
Having a chrono type for it makes things (mostly code reading) simpler.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Recently, coordinator_result was introduced as an alternative for
exceptions. It was placed in the main "exceptions/exceptions.hh" header,
which virtually every single source file in Scylla includes.
But unfortunately, it brings in some heavy header files and templates,
leading to a lot of wasted build time - ClangBuildAnalyzer measured that
we include exceptions.hh in 323 source files, taking almost two seconds
each on average.
In this patch, we split the coordinator_result feature into a separate
header file, "exceptions/coordinator_result", and only the few places
which need it include the header file. Unfortunately, some of these
few places are themselves header, so the new header file ends up being
included in 100 source files - but 100 is still much less than 323 and
perhaps we can reduce this number 100 later.
After this patch, the total Scylla object-file size is reduced by 6.5%
(the object size is a proxy for build time, which I didn't directly
measure). ClangBuildAnalyzer reports that now each of the 323 includes
of exceptions.hh only takes 80ms, coordinator_result.hh is only included
100 times, and virtually all the cost to include it comes from Boost's
result.hh (400ms per inclusion).
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20220228204323.1427012-1-nyh@scylladb.com>
Introduced in commit: ddd693c6d7
We're not emplacing newer windows in the tracker, causing
std::out_of_range when replacing sstables for windows.
Let's fix the logic and add an unit test to cover this.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220301194944.95096-1-raphaelsc@scylladb.com>
Currently the output_run_identifier is assigned right
after the calling setup_new_compaction.
Move setting the uuid to setup_new_compaction to simplify
the flow.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220301083643.1845096-1-bhalevy@scylladb.com>
Instead, rely solely on compaction_data.abort source
that is task::stop now uses to stop the task.
This makes task stopping permanent, so it can't be undone
(as used to be the case where task_stop
set stopping to false after waiting for compaction_done,
to allow rerite_sstables's task to be created before
calling run_with_compaction_disabled, and start
running after it - which is no longer the case)
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220301083535.1844829-1-bhalevy@scylladb.com>
Currently, rewrite_sstables retrieved the sstables under
run_with_compaction_disabled, *after* it's created a task for itself.
This makes little sense as this task have not started running yet
and therefore does not need to be stopped by
run_with_compaction_disabled.
This is currently worked around by setting task->stopping = false
in task_stop().
This change just moves task create in rewrite_sstables till
after the sstables are retrieved and the deferred cleanup
of _stats.pending_tasks till after it's first adjusted.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220301083409.1844500-1-bhalevy@scylladb.com>
This series contains:
- lister: move to utils
- tidy up the clutter in the root dir
Based on Avi's feedback to `[PATCH 1/1] utils: directory_lister: close: always abort queue` that was sent to the mailing list:
- directory_lister: drop abort method
- lister: do not require get after close to fail
- test: lister_test: test_directory_lister_close simplify indentation
- cosmetic cleanup
Closes#10142
* github.com:scylladb/scylla:
test: lister_test: test_directory_lister_close simplify indentation
lister: do not require get after close to fail
directory_lister: drop abort method
lister: move to utils
This PR consists of two changes.
The first fixes the flat_mutation_reader and flat_mutation_reader_v2, so that they can be destructed without being closed (if no action has been initiated). This has been discussed in the referenced issue.
The second one changes scanning and flush readers so that they implement the second version of the API.
It also contains unit test fixes, dealing with flat mutation reader assertions (where the v1 asserter failed to consume range tombstones intelligently enough in some flows) and several sstable_3_x tests (where sstables that contain range tombstones were expected to be byte-by-byte equivalent to a reference, aside from semantic validation).
Fixes#9065.
Closes#9669
* github.com:scylladb/scylla:
flat_reader_assertions: do not accumulate out-of-range tombstones
flat_reader_assertions: refactor resetting accumulated tombstone lists
flat_mutation_reader_test: fix "test_flat_mutation_reader_consume_single_partition"
memtable::make_flush_reader(): return flat_mutation_reader_v2
memtable::make_flat_reader(): return flat_mutation_reader_v2
flat_mutation_reader_v2: add consume_partitions()
introduce the MutationConsumer concept
mutation_source: clone shortcut constructors for flat_mutation_reader_v2
flat_mutation_reader_v2: add delegating_reader_v2
memtable: upgrade scanning_reader and flush_reader to v2
flat_mutation_reader: allow destructing readers which are not closed and didn't initiate any IO.
tests: stop comparing sstables with range tombstones to C* reference
tests: flat_reader_assertions: improve range tombstone checking
Also remove the incorrect difference in range tombstone checking
behavior between `produces_range_tombstone()` and `produces(const
range_tombstone&)` by having both turn on checking.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
Since `flat_reader_assertions::produces(const range_tombstone&,...)`
records the range tombstone for checking, be sure to explicitly pass
in a clustering range that does not extend beyond the mock-read part
of the mutation.
Also (provisionally) change the assertion method to accept clustering
ranges.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
This change is a part of effort to migrate existing readers from old API
to the new one. The corresponding make_flush_reader and
make_flat_reader functions still return flat_mutation_reader.
In functions such as upgrade_to_v2 (excerpt below), if the constructor
of transforming_reader throws, r needs to be destroyed, however it
hasn't been closed. However, if a reader didn't start any operations, it
is safe to destruct such a reader. This issue can potentially manifest
itself in many more readers and might be hard to track down. This commit
adds a bool indicating whether a close is anticipated, thus avoiding
errors in the destructor.
Code excerpt:
flat_mutation_reader_v2 upgrade_to_v2(flat_mutation_reader r) {
class transforming_reader : public flat_mutation_reader_v2::impl {
// ...
};
return make_flat_mutation_reader_v2<transforming_reader>(std::move(r));
}
Fixes#9065.
As flat mutation reader {up,down}grades get added to the write path,
comparing range-tombstone-containing (at least) sstables byte-by-byte
to a reference is starting to seem like a fool's errand.
* When a flat mutation reader is {up,down}graded, information may get
lost while splitting range tombstones. Making those splits revertable
should in theory be possible but would surely make {up,down}graders
slower and more complex, and may also possibly entail adding
information to in-memory representation of range tombstones and
range rombstone changes. Such investment for the sake of 7 unit tests
does not seem wise, given that the plan is to get rid of reader
{up,down}grade logic once the move to flat mutation reader v2 is
completed.
* All affected tests also validate their written sstables
semantically.
* At least some of the offending reference sstables are not
"canonical" wrt range tombstones to begin with -- they contain range
tombstones that overlap with clustering rows. The fact that Scylla
does not "canonicalize" those in some way seems purely incidental.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
`produces_range_tombstone()` is smart enough to not just try to read
one range tombstone from the input and compare it to the passed
reference, but to read as many range tombstones as the reader is
looking at (including none) using `may_produce_tombstones()` and
record those appropriately.
When `produces(const schema&, const mutation_fragment&)` is passed a
range tombstone as the second argument, it does not do anything
special -- it just reads one fragment, disregards it (!), and applies
its second argument to both "expected" and "encountered" range
tombstone lists. The right thing here is to use the same logic as
`produces_range_tombstone()`; upcoming memtable-related reader
changes (which result in more split range tombstones) cause some unit
tests to fail without fixing this.
Refactor the relevant logic into a private method (`apply_rt()`) and
use that in both places.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
The header file "exceptions/exceptions.hh" and the exception types in it
is used by virtually every source file in Scylla, so excessive includes
and templated code generation in this header could slow down the build
considerably.
Before this patch, all of the exceptions' constructors were inline in
exceptions.hh, so source file using one of these exceptions will need
to recompile the code, which is fairly heavy, using the fmt templates
for various types. According to ClangBuildAnalyzer, 323 source files
needed to materialize prepare_message<db::consistency_level,int&,int&>,
taking 0.3 seconds each.
So this patch moves the exception constructors from the header file
exceptions.hh to the source file exceptions.cc. The header file no longer
uses fmt.
Unfortunately, the actual build-time savings from this patch is tiny -
around 0.1%... It turns out that most of the prepare_message<>
compilation time comes from fmt compilation time, and since virtually
all source files use fmt for other header reasons (intentionally or
through other headers), no compilation time can be saved. Nevertheless,
I hope that as we proceed with more cleanups like this and eliminate
more unnecessary code-generation-in-headers, we'll start seeing build
time drop.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
"
Some templates put constraints onto the involved types with the help of
static assertions. Having them in form of concepts is much better.
tests: unit(dev)
"
* 'br-static-assert-to-concept' of https://github.com/xemul/scylla:
sstables: Remove excessive type-match assertions
mutation_reader: Sanitize invocable asserion and concept
code: Convert is_future result_of assertions into invoke_result concept
code: Convert is_same+result_of assertions into invocable concepts
code: Convert nothrow construction assertions into concepts
code: Convert is_integral assertions to concepts
In a previous patch, we added a test for the case of Scylla trying to
assign the JSON value 1e6 into an integer - which should be allowed
because 1e6 is indeed a whole number, in the range of int.
We already fixed that in commit efe7456f0a,
but this patch adds another test which demonstrates that an even more
esoteric problem remains:
If we are reading a JSON value into a bigint (CQL's 64-bit integer),
*and* if the number is between 2^53 and 2^63-1 *and* if the number
is written using scientific notation, e.g., 922337203685477580.7e1
(which is 2^63-1), then the bigint is set incorrectly, with some
digits being lost. The problem is that RapidJSON reads this integer
into the "double" type, which only keeps 53 significant bits.
Because this is an open issue (#10137), the test included here is
marked as expected failure (xfail). The test is also known to
fail in Cassandra - which doesn't allow scientific notation for
JSON integers at all despite the JSON standard - so the test is
also marked "cassandra_bug".
Refs #10137
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Rather than using a std::optional<compacting_sstable_registration>
for lazy construction, construct the object early
and call register_compacting when the sstables to register
are available.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Rather than a compaction_manager* so that in the next
patch it could be constructed with just that and
the caller can call register_compacting when
it has the sstables to register ready.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
There's no need anymore for an indented block
to destroy tnhe directory_lister since the other
sub-case was deleted.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Currently, the lister test expected get() to
always fail after close(), but it unexpectedly
succeeded if get() was never called before close,
as seen in https://jenkins.scylladb.com/view/master/job/scylla-master/job/next/4587/artifact/testlog/x86_64_debug/lister_test.test_directory_lister_close.4001.log
```
random-seed=1475104835
Generated 719 dir entries
Getting 565 dir entries
Closing directory_lister
Getting 0 dir entries
Closing directory_lister
test/boost/lister_test.cc(190): fatal error: in "test_directory_lister_close": exception std::exception expected but not raised
```
This change relaxes this requirement to keep
close() simple, based on Avi's feedback:
> The user should call close(), and not do it while get() is running, and
> that's it.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Based on Avi's feedback:
> We generally have a public abort() only if we depend on an external
> event (like data from a tcp socket) that we don't control. But here
> there are no such external events. So why have a public abort() at all?
If needed in the future, we can consider adding
get(abort_source&) to allow aborting get() via
an external event.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
There's nothing specific to scylla in the lister
classes, they could (and maybe should) be part of
the seastar library.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Currently any unhandled error during deferred shutdown
is rethrown in a noexcept context (in ~deferred_action),
generating a core dump.
The core dump is not helpful if the cause of the
error is "environmental", i.e. in the system, rather
than in scylla itself.
This change detects several such errors and calls
_Exit(255) to exit the process early, without leaving
a coredump behind. Otherwise, call abort() explicitly,
rather than letting terminate() be called implicitly
by the destructor exception handling code.
Fixes#9573
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20220227101054.1294368-1-bhalevy@scylladb.com>
We add a `peers()` method to `discovery` which returns the peers
discovered until now (including seeds). The caller of functions which
return an output -- `tick` or `request` -- is responsible for persisting
`peers()` before returning the output of `tick`/`request` (e.g. before
sending the response produced by `request` back). The user of
`discovery` is also responsible for restoring previously persisted peers
when constructing `discovery` again after a restart (e.g. if we
previously crashed in the middle of the algorithm).
The `persistent_discovery` class is a wrapper around `discovery` which
does exactly that.
For storage we use a simple local table.
A simple bugfix is also included in the first patch.
* kbr/discovery-persist-v3:
service: raft: raft_group0: persist discovered peers and restore on restart
db: system_keyspace: introduce discovery table
service: raft: discovery: rename `get_output` to `tick`
service: raft: discovery: stop returning peer_list from `request` after becoming leader
cached_page::on_evicted() is invoked in the LSA allocator context, set in the
reclaimer callback installed by the cache_tracker. However,
cached_pages are allocated in the standard allocator context (note:
page content is allocated inside LSA via lsa_buffer). The LSA region
will happily deallocate these, thinking that they these are large
objects which were delegated to the standard allocator. But the
_non_lsa_memory_in_use metric will underflow. When it underflows
enough, shard_segment_pool.total_memory() will become 0 and memory
reclamation will stop doing anything, leading to apparent OOM.
The fix is to switch to the standard allocator context inside
cached_page::on_evicted(). evict_range() was also given the same
treatment as a precaution, it currently is only invoked in the
standard allocator context.
The series also adds two safety checks to LSA to catch such problems earlier.
Fixes#10056
\cc @slivne @bhalevy
Closes#10130
* github.com:scylladb/scylla:
lsa: Abort when trying to free a standard allocator object not allocated through the region
lsa: Abort when _non_lsa_memory_in_use goes negative
tests: utils: cached_file: Validate occupancy after eviction
test: sstable_partition_index_cache_test: Fix alloc-dealloc mismatch
utils: cached_file: Fix alloc-dealloc mismatch during eviction
"
Problem statement
=================
Today, compaction can act much more aggressive than it really has to, because
the strategy and its definition of backlog are completely decoupled.
The backlog definition for size-tiered, which is inherited by all
strategies (e.g.: LCS L0, TWCS' windows), is built on the assumption that the
world must reach the state of zero amplification. But that's unrealistic and
goes against the intent amplification defined by the compaction strategy.
For example, size tiered is a write oriented strategy which allows for extra
space amplification for compaction to keep up with the high write rate.
It can be seen today, in many deployments, that compaction shares is either
close to 1000, or even stuck at 1000, even though there's nothing to be done,
i.e. the compaction strategy is completely satisfied.
When there's a single sstable per tier, for example.
This means that whenever a new compaction job kicks in, it will act much more
aggressive because of the high shares, caused by false backlog of the existing
tables. This translates into higher P99 latencies and reduced throughput.
Solution
========
This problem can be fixed, as proposed in the document "Fixing compaction
aggressiveness due to suboptimal definition of zero backlog by controller" [1],
by removing backlog of tiers that don't have to be compacted now, like a tier
that has a single file. That's about coupling the strategy goal with the
backlog definition. So once strategy becomes satisfied, so will the controller.
Low-efficiency compaction, like compacting 2 files only or cross-tier, only
happens when system is under little load and can proceed at a slower pace.
Once efficient jobs show up, ongoing compactions, even if inefficient, will get
more shares (as efficient jobs add to the backlog) so compaction won't fall
behind.
With this approach, throughput and latency is improved as cpu time is no longer
stolen (unnecessarily) from the foreground requests.
[1]: https://docs.google.com/document/d/1EQnXXGWg6z7VAwI4u8AaUX1vFduClaf6WOMt2wem5oQ
Results
=======
Test sequentially populates 3 tables and then run a mixed workload on them,
where disk:memory ratio (usage) reaches ~30:1 at the peak.
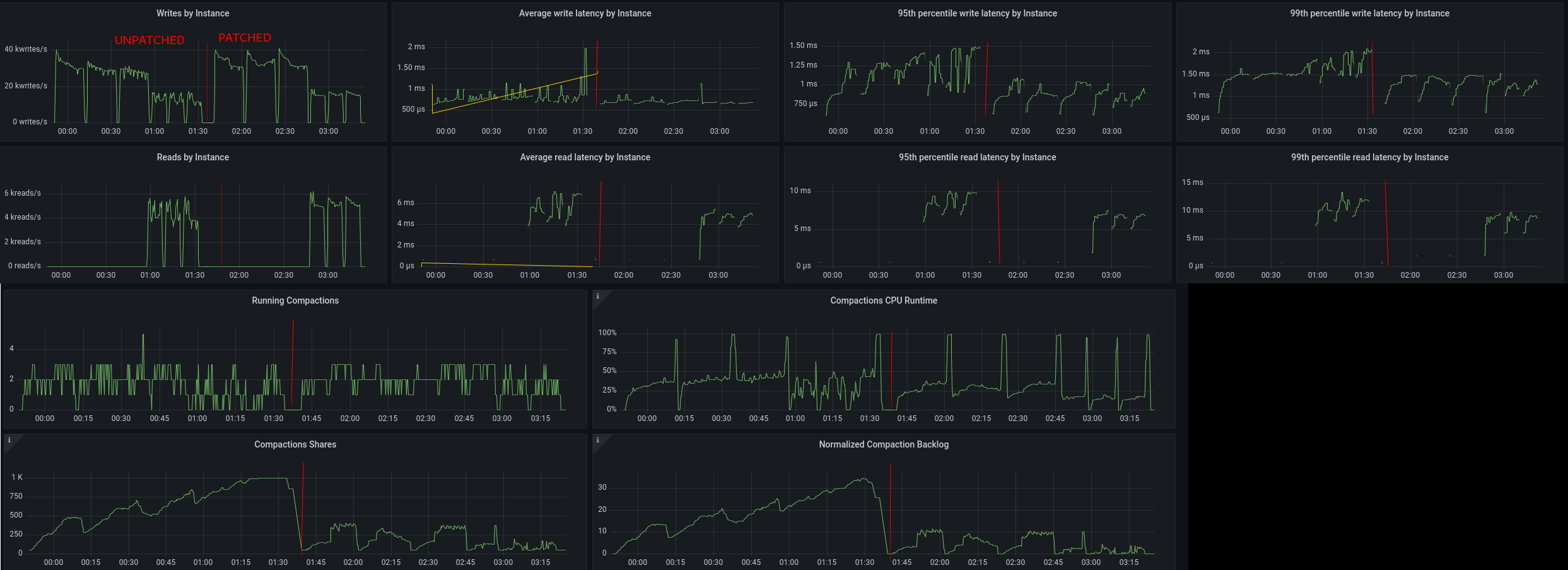
Please find graphs here:
https://user-images.githubusercontent.com/1409139/153687219-32368a35-ac63-461b-a362-64dbe8449a00.png
1) Patched version started at ~01:30
2) On population phase, throughput increase and lower P99 write latency can be
clearly observed.
3) On mixed phase, throughput increase and lower P99 write and read latency can
also be clearly observed.
4) Compaction CPU time sometimes reach ~100% because of the delay between each
loader.
5) On unpatched version, it can be seen that backlog keeps growing even when
though strategies become satisfied, so compaction is using much more CPU time
in comparison. Patched version correctly clears the backlog.
Can also be found at:
github.com/raphaelsc/scylla.git compaction-controller-v5
tests: UNIT(dev, debug).
"
* 'compaction-controller-v5' of https://github.com/raphaelsc/scylla:
tests: Add compaction controller test
test/lib/sstable_utils: Set bytes_on_disk for fake SSTables
compaction/size_tiered_backlog_tracker.hh: Use unsigned type for inflight component
compaction: Redefine compaction backlog to tame compaction aggressiveness
compaction_backlog_tracker: Batch changes through a new replacement interface
table: Disable backlog tracker when stopping table
compaction_backlog_tracker: make disable() public
compaction_backlog_tracker: Clear tracker state when disabled
compaction: Add normalized backlog metric
compaction: make size_tiered_compaction_strategy static
tri_compare_opt can avoid casting bool to int for spaceshipping
int - int <=> 0 looks nicer and shorter as int <=> int
data_type::compare from serialized_tri_compare already returns strong_ordering
tests: unit(dev)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20220224125556.13138-1-xemul@scylladb.com>
This patch adds metrics to the Alternator TTL feature (aka the "expiration
service").
I put these metrics deliberately in their own object in ttl.{hh,cc}, and
also with their own prefix ("expiration_*") - and *not* together with the
rest of the Alternator metrics (alternator/stats.{hh,cc}). This is
because later we may want to use the expiration service not only in
Alternator but also in CQL - to support per-item expiration with CDC
events also in CQL. So the implementation of this feature should not be
too tangled with that of Alternator.
The patch currently adds four metrics, and opens the path to easily add
more in the future. The metrics added now are:
1. scylla_expiration_scan_passes: The number of scan passes over the
entire table. We expect this to grow by 1 every
alternator_ttl_period_in_seconds seconds.
2. scylla_expiration_scan_table: The number of table scans. In each scan
pass, we scan all the tables that have the Alternator TTL feature
enabled. Each scan of each table is counted by this counter.
3. scylla_expiration_items_deleted: Counts the number of items that
the expiration service expired (deleted). Please remember that
each item is considered for expiration - and then expired - on
only one node, so each expired item is counted only once - not
RF times.
4. scylla_expiration_secondary_ranges_scanned: If this counter is
incremented, it means this node took over some other node's
expiration scanning duties while the other node was down.
This patch also includes a couple of unrelated comment fixes.
I tested the new metrics manually - they aren't yet tested by the
Alternator test suite because I couldn't make up my mind if such
tests would belong in test_ttl.py or test_metrics.py :-)
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20220224092419.1132655-1-nyh@scylladb.com>
{kind=link}