Recently we noticed a regression where with certain versions of the fmt
library,
SELECT value FROM system.config WHERE name = 'experimental_features'
returns string numbers, like "5", instead of feature names like "raft".
It turns out that the fmt library keep changing their overload resolution
order when there are several ways to print something. For enum_option<T> we
happen to have to conflicting ways to print it:
1. We have an explicit operator<<.
2. We have an *implicit* convertor to the type held by T.
We were hoping that the operator<< always wins. But in fmt 8.1, there is
special logic that if the type is convertable to an int, this is used
before operator<<()! For experimental_features_t, the type held in it was
an old-style enum, so it is indeed convertible to int.
The solution I used in this patch is to replace the old-style enum
in experimental_features_t by the newer and more recommended "enum class",
which does not have an implicit conversion to int.
I could have fixed it in other ways, but it wouldn't have been much
prettier. For example, dropping the implicit convertor would require
us to change a bunch of switch() statements over enum_option (and
not just experimental_features_t, but other types of enum_option).
Going forward, all uses of enum_option should use "enum class", not
"enum". tri_mode_restriction_t was already using an enum class, and
now so does experimental_features_t. I changed the examples in the
comments to also use "enum class" instead of enum.
This patch also adds to the existing experimental_features test a
check that the feature names are words that are not numbers.
Fixes#11003.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#11004
Scylla's coding standard requires that each header is self-sufficient,
i.e., it includes whatever other headers it needs - so it can be included
without having to include any other header before it.
We have a test for this, "ninja dev-headers", but it isn't run very
frequently, and it turns out our code deviated from this requirement
in a few places. This patch fixes those places, and after it
"ninja dev-headers" succeeds again.
Fixes#10995
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10997
Currently, applying schema mutations involves flushing all schema
tables so that on restart commit log replay is performed on top of
latest schema (for correctness). The downside is that schema merge is
very sensitive to fdatasync latency. Flushing a single memtable
involves many syncs, and we flush several of them. It was observed to
take as long as 30 seconds on GCE disks under some conditions.
This patch changes the schema merge to rely on a separate commit log
to replay the mutations on restart. This way it doesn't have to wait
for memtables to be flushed. It has to wait for the commitlog to be
synced, but this cost is well amortized.
We put the mutations into a separate commit log so that schema can be
recovered before replaying user mutations. This is necessary because
regular writes have a dependency on schema version, and replaying on
top of latest schema satisfies all dependencies. Without this, we
could get loss of writes if we replay a write which depends on the
latest schema on top of old schema.
Also, if we have a separate commit log for schema we can delay schema
parsing for after the replay and avoid complexity of recognizing
schema transactions in the log and invoking the schema merge logic.
I reproduced bad behavior locally on my machine with a tired (high latency)
SSD disk, load driver remote. Under high load, I saw table alter (server-side part) taking
up to 10 seconds before. After the patch, it takes up to 200 ms (50:1 improvement).
Without load, it is 300ms vs 50ms.
Fixes#8272Fixes#8309Fixes#1459Closes#10333
* github.com:scylladb/scylla:
config: Introduce force_schema_commit_log option
config: Introduce unsafe_ignore_truncation_record
db: Avoid memtable flush latency on schema merge
db: Allow splitting initiatlization of system tables
db: Flush system.scylla_local on change
migration_manager: Do not drop system.IndexInfo on keyspace drop
Introduce SCHEMA_COMMITLOG cluster feature
frozen_mutation: Introduce freeze/unfreeze helpers for vectors of mutations
db/commitlog: Improve error messages in case of unknown column mapping
db/commitlog: Fix error format string to print the version
db: Introduce multi-table atomic apply()
Convert most use sites from `co_return coroutine::make_exception`
to `co_await coroutine::return_exception{,_ptr}` where possible.
In cases this is done in a catch clause, convert to
`co_return coroutine::exception`, generating an exception_ptr
if needed.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Closes#10972
"
The option controlls the IO bandwidth of the compaction sched class.
It's not set to be 16MB/s, but is unused. This set makes it 0 by
default (which means unlimited), live-updateable and plugs it to the
seastar sched group IO throttling.
branch: https://github.com/xemul/scylla/tree/br-compaction-throttling-3
tests: unit(dev),
v2: https://jenkins.scylladb.com/job/releng/job/Scylla-CI/1010/ ,
v2: manual config update
"
* 'br-compaction-throttling-3-a' of https://github.com/xemul/scylla:
compaction_manager: Add compaction throughput limit
updateable_value: Support dummy observing
serialized_action: Allow being observer for updateable_value
config: Tune the config option
The node now refuses to boot if schema tables were truncated.
This adds a config option to ignore truncation records as a
workaround if user truncated them manually.
Currently, applying schema mutations involves flushing all schema
tables so that on restart commit log replay is performed on top of
latest schema (for correctness). The downside is that schema merge is
very sensitive to fdatasync latency. Flushing a single memtable
involves many syncs, and we flush several of them. It was observed to
take as long as 30 seconds on GCE disks under some conditions.
This patch changes the schema merge to rely on a separate commit log
to replay the mutations on restart. This way it doesn't have to wait
for memtables to be flushed. It has to wait for the commitlog to be
synced, but this cost is well amortized.
We put the mutations into a separate commit log so that schema can be
recovered before replaying user mutations. This is necessary because
regular writes have a dependency on schema version, and replaying on
top of latest schema satisfies all dependencies. Without this, we
could get loss of writes if we replay a write which depends on the
latest schema on top of old schema.
Also, if we have a separate commit log for schema we can delay schema
parsing for after the replay and avoid complexity of recognizing
schema transactions in the log and invoking the schema merge logic.
One complication with this change is that replay_position markers are
commitlog-domain specific and cannot cross domains. They are recorded
in various places which survive node restart: sstables are annotated
with the maximum replay position, and they are present inside
truncation records. The former annotation is used by "truncate"
operation to drop sstables. To prevent old replay positions from being
interpreted in the context in the new schema commitlog domain, the
change refuses to boot if there are truncation records, and also
prohibits truncation of schema tables.
The boot sequence needs to know whether the cluster feature associated
with this change was enabled on all nodes. Fetaures are stored in
system.scylla_local. Because we need to read it before initializing
schema tables, the initialization of tables now has to be split into
two phases. The first phase initializes all system tables except
schema tables, and later we initialize schema tables, after reading
stored cluster features.
The commitlog domain is switched only when all nodes are upgraded, and
only after new node is restarted. This is so that we don't have to add
risky code to deal with hot-switching of the commitlog domain. Cold
switching is safer. This means that after upgrade there is a need for
yet another rolling restart round.
Fixes#8272Fixes#8309Fixes#1459
It's not needed anymore because system.IndexInfo is a virtual table
calculated from view info.
The drop accesses a table which is outside system_schema keyspace
so crosses commit log domain. This will trigger an internal from
database::apply() on schema merge once the code switches to use
the schema commit log and require that all mutations which are
part of the schema change belong to a single commit log domain.
We could theoretically move system.IndexInfo to the schema commit log
domain. It's not easy though because table initialization at boot
needs to be split, and current functions for initailization work
at keyspace granularity, not table granularity.
Adds measuring the apparent delta vector of footprint added/removed within
the timer time slice, and potentially include this (if influx is greater
than data removed) in threshold calculation. The idea is to anticipate
crossing usage threshold within a time slice, so request a flush slightly
earlier, hoping this will give all involved more time to do their disk
work.
Obviously, this is very akin to just adjusting the threshold downwards,
but the slight difference is that we take actual transaction rate vs.
segment free rate into account, not just static footprint.
Note: this is a very simplistic version of this anticipation scheme,
we just use the "raw" delta for the timer slice.
A more sophisiticated approach would perhaps do either a lowpass
filtered rate (adjust over longer time), or a regression or whatnot.
But again, the default persiod of 10s is something of an eternity,
so maybe that is superfluous...
Closes#10651
* github.com:scylladb/scylla:
commitlog: Add (internal) measurement of byte rates add/release/flush-req
commitlog: Add counters for # bytes released/flush requested
commitlog: Keep track of last flush high position to avoid double request
commitlog: Fix counter descriptor language
"
On stop there's a rather long log-less gap in the middle of
storage_service::drain_on_shutdown(). This set adds log in
interesting places and while at it tosses the patched code.
refs: #10941
"
* 'br-shutdown-logging' of https://github.com/xemul/scylla:
batchlog_manager: Add drain and stop logging
batchlog_manager: Coroutinize drain and stop
batchlog_manager: Drain it with shared future
commitlog: Add shutdown message
database: Move flushing logging
compaction_manager: Add logging around drain
compaction_manager: Coroutinize drain
storage_service: Sanitize stop_transport()
This is not identical change, if drain() resolves with exception we end
up skipping the gate closing, but since it's stop why bother
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The .drain() method can be called from several places, each needs to
wait for its completion. Now this is achieved with the help of a gate,
but there's a simpler way
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
It happens in database::drain(), we know when it starts after keyspaces
are flushed, now it's good to know when it completes
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
This PR removes some restrictions classes and replaces them with expression.
* `single_column_restriction` has been removed altogether.
* `partition_key_restrictions` field inside `statement_restrictions` has been replaced with `expression`
`clustering_key_restrictions` are not replaced yet, but this PR already has 30 commits so it's probably better to merge this before adding any more changes.
Luckily most of these commits are implementations of small helper functions.
`single_column_restriction` was pretty easy to remove. This class holds the `expression` that describes the restriction and `column_definition` of the restricted column.
It inherits from `restriction` - the base class of all restrictions.
I wasn't able to replace it with plain `expression` just yet, because a lot of times a `shared_ptr<single_column_restriction>` is being cast to `shared_ptr<restriction>`.
Instead I replaced all instances of `single_column_restriction` with `restriction`.
To decide if a `restriction` is a `single_column_restriction` we can use a helper method that works on expressions.
Same with acquiring the restricted `column_definition`.
This change has two advantages:
* One less restriction class -> moving towards 0
* Preparing towards one generic `restriction/expression` type and using functions to distinguish the type of expression that we're dealing with.
`partition_key_restrictions` is a class used to keep restrictions on the partition key inside `statement_restrictions`.
Removing it required two major steps.
First I had to implement taking all the binary operators and making sure that they are valid together.
Before the change this was the `merge_to` method. It ensures that for example there are no token and regular restrictions occurring at the same time.
This has been implemented as `statement_restrictions::add_restriction`.
It detects which case it's dealing with and mimics `merge_to` from the right restrictions class.
Then I implemented all methods of `partition_key_restrictions` but operating on plain `expressions`.
While doing that I was able to gradually shift the responsibility to the brand new functions.
Finally `partition_key_restrictions` wasn't used anywhere at all and I was able to remove it.
Here's the inheritance tree of all restriction classes for context:
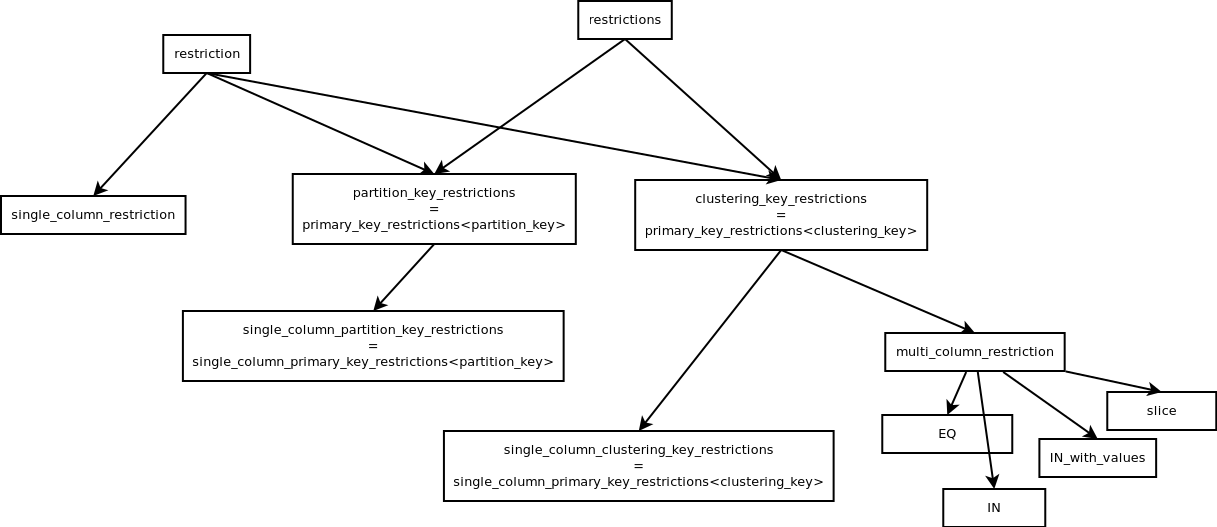
For now this is marked as a draft.
I just put all this together in a readable way and wanted to put it out for you to see.
I will have another look at the code and maybe do some improvements.
Closes#10910
* github.com:scylladb/scylla:
cql3: Remove _new from _new_partition_key_restrictions
cql3: Remove _partition_key_restrictions from statement_restrictions
cql3: Use expression for index restrictions
cql3: expr: Add contains_multi_column_restriction
cql3: Add expr::value_for
cql3: Use the new restrictions map in another place
cql3: use the new map in get_single_column_partition_key_restrictions
cql3: Keep single column restrictions map inside statement restrictions
cql3: Use expression instead of _partition_key_restrictions in the remaining code
cql3: Replace partition_key_restrictions->has_supporting_index()
cql3: Replace statement_restrictions->get_column_defs()
cql3: Replace partition_key_restrictions->needs_filtering()
cql3: Replace partition_key_restrictions->size()
cql3: Replace partition_key_restrictions->is_all_eq()
cql3: Replace parition_key_restriction->has_unrestricted_components()
cql3: Replace parition_key_restrictions->empty()
cql3: Keep restrictions as expressions inside statement_restrictions
cql3: Handle single value INs inside prepare_binary_operator
cql3: Add get_columns_in_commons
cql3: expr: Add is_empty_restriction
cql3: Replicate column sorting functionality using expressions
cql3: Remove single_column_restriction class
cql3: Replace uses of single_column_restriction with restriction
cql3: expr: Add get_the_only_column
cql3: expr: Add is_single_column_restriction
cql3: expr: Add for_each_expression
cql3: Remove some unsued methods
There are still some places that use partition_key_restrictions
instead of _new_partition_key_restrictions in statement_restrictions.
Change them to use the new representation
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
The option is used, but is not implemented. If attaching implementation
to it right a once the compaction will slow down to 16MB/s on all nodes.
Make it zero (unbound) by default and mard live-updateable while at it.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Currently, for users who have permissions_cache configs set to very high
values (and thus can't wait for the configured times to pass) having to restart
the service every time they make a change related to permissions or
prepared_statements cache (e.g. Adding a user and changing their permissions)
can become pretty annoying.
This patch series make permissions_validity_in_ms, permissions_update_interval_in_ms
and permissions_cache_max_entries live updateable so that restarting the
service is not necessary anymore for these cases.
It also adds an API for flushing the cache to make it easier for users who
don't want to modify their permissions_cache config.
branch: https://github.com/igorribeiroduarte/scylla/tree/make_permissions_cache_live_updateable
CI: https://jenkins.scylladb.com/job/releng/job/Scylla-CI/1005/
dtests: https://github.com/igorribeiroduarte/scylla-dtest/tree/test_permissions_cache
* https://github.com/igorribeiroduarte/scylla/make_permissions_cache_live_updateable:
loading_cache_test: Test loading_cache::reset and loading_cache::update_config
api: Add API for resetting authorization cache
authorization_cache: Make permissions cache and authorized prepared statements cache live updateable
auth_prep_statements_cache: Make aut_prep_statements_cache accept a config struct
utils/loading_cache.hh: Add update_config method
utils/loading_cache.hh: Rename permissions_cache_config to loading_cache_config and move it to loading_cache.hh
utils/loading_cache.hh: Add reset method
Currently, for users who have permissions_cache configs set to very high
values (and thus can't wait for the configured times to pass) having to restart
the service every time they make a change related to permissions or
prepared_statements cache(e.g.: Adding a user) can become pretty annoying.
This patch make permissions_validity_in_ms, permissions_update_interval_in_ms
and permissions_cache_max_entries live updateable so that restarting the
service is not necessary anymore for these cases.
Signed-off-by: Igor Ribeiro Barbosa Duarte <igor.duarte@scylladb.com>
Fixes#9367
The CL counters pending_allocations and requests_blocked_memory are
exposed in graphana (etc) and often referred to as metrics on whether
we are blocking on commit log. But they don't really show this, as
they only measure whether or not we are blocked on the memory bandwidth
semaphore that provides rate back pressure (fixed num bytes/s - sortof).
However, actual tasks in allocation or segment wait is not exposed, so
if we are blocked on disk IO or waiting for segments to become available,
we have no visible metrics.
While the "old" counters certainly are valid, I have yet to ever see them
be non-zero in modern life.
Closes#9368
This series decouples the staging sstables from the table's sstable set.
The current behavior keeps the sstables in the staging directory until view building is done. They are readable as any other sstable, but fenced off from compaction, so they don't go away in the meanwhile.
Currently, when views are built, the sstables are moved into the main table directory where they will then be compacted normally.
The problem with this design is that the staging sstables are never compacted, in particular they won't get cleaned up or scrubbed.
The cleanup scenario open a backdoor for data resurrection when the staging sstables are moved after view building while possibly containing stale partitions (#9559) which will not be cleaned up until next time cleanup compaction is performed.
With this series, SSTables that are created in or moved to the staging sub-directory are "cloned" into the base table directory by hard-linking the components there and creating a new sstable object which loads the cloned files.
The former, in the staging directory is used solely for view building and is not added to the table's sstable set, while the latter, its clone, behaves like any other sstable and is added either to the regular or maintenance set and is read and compacted normally.
When view building is done, instead of moving the staging sstable into the table's base directory, it is simply unlinked.
If its "clone" wasn't compacted away yet, then it will just remain where it is, exactly like it would be after it was moved there in the present state of things. If it was already compacted and no longer exists, then unlinking will then free its storage.
Note that snapshot is based on the sstables listed by the table, which do not include the staging sstables with this change.
But that shouldn't matter since even today, the sstables in the snapshot has no notion of "staging" directory and it is expected that the MV's are either updated view `nodetool refresh` if restoring sstables from snapshot using the uploads dir, or if restoring the whole table from backup - MV's are effectively expected to be rebuilt from scratch (they are not included in automatic snapshots anyway since we don't have snapshot-coherency across tables).
A fundamental infrastructure change was done to achieve that which is to change the sstable_list which was a std::unordered_set<shared_sstable> into a std::unordered_map<generation_type, shared_sstable> that keeps the shared_sstable objects indexed by generation number (that must be unique). With this model, sstables are supposed to be searched by the generation number, not by their pointer, since when the staging sstable is clones, there will be 2 shared_sstable objects with the same generation (and different `dir()`) and we must distinguish between them.
Special care was taken to throw a runtime_error exception if when looking up a shared sstable and finding another one with the same generation, since they must never exist in the same sstable_map.
Fixes#9559Closes#10657
* github.com:scylladb/scylla:
table: clone staging sstables into table dir
view_update_generator: discover_staging_sstables: reindent
table: add get_staging_sstables
view_update_generator: discover_staging_sstables: get shared table ptr earlier
distributed_loader: populate table directory first
sstables: time_series_sstable_set: insert: make exception safe
sstables: move_to_new_dir: fix debug log message
Due to its sharded and token-based architecture, Scylla works best when the user workload is more or less uniformly balanced across all nodes and shards. However, a common case when this assumption is broken is the "hot partition" - suddenly, a single partition starts getting a lot more reads and writes in comparison to other partitions. Because the shards owning the partition have only a fraction of the total cluster capacity, this quickly causes latency problems for other partitions within the same shard and vnode.
This PR introduces per-partition rate limiting feature. Now, users can choose to apply per-partition limits to their tables of choice using a schema extension:
```
ALTER TABLE ks.tbl
WITH per_partition_rate_limit = {
'max_writes_per_second': 100,
'max_reads_per_second': 200
};
```
Reads and writes which are detected to go over that quota are rejected to the client using a new RATE_LIMIT_ERROR CQL error code - existing error codes didn't really fit well with the rate limit error, so a new error code is added. This code is implemented as a part of a CQL protocol extension and returned to clients only if they requested the extension - if not, the existing CONFIG_ERROR will be used instead.
Limits are tracked and enforced on the replica side. If a write fails with some replicas reporting rate limit being reached, the rate limit error is propagated to the client. Additionally, the following optimization is implemented: if the coordinator shard/node is also a replica, we account the operation into the rate limit early and return an error in case of exceeding the rate limit before sending any messages to other replicas at all.
The PR covers regular, non-batch writes and single-partition reads. LWT and counters are not covered here.
Results of `perf_simple_query --smp=1 --operations-per-shard=1000000`:
- Write mode:
```
8f690fdd47 (PR base):
129644.11 tps ( 56.2 allocs/op, 13.2 tasks/op, 49785 insns/op)
This PR:
125564.01 tps ( 56.2 allocs/op, 13.2 tasks/op, 49825 insns/op)
```
- Read mode:
```
8f690fdd47 (PR base):
150026.63 tps ( 63.1 allocs/op, 12.1 tasks/op, 42806 insns/op)
This PR:
151043.00 tps ( 63.1 allocs/op, 12.1 tasks/op, 43075 insns/op)
```
Manual upgrade test:
- Start 3 nodes, 4 shards each, Scylla version 8f690fdd47
- Create a keyspace with scylla-bench, RF=3
- Start reading and writing with scylla-bench with CL=QUORUM
- Manually upgrade nodes one by one to the version from this PR
- Upgrade succeeded, apart from a small number of operations which failed when each node was being put down all reads/writes succeeded
- Successfully altered the scylla-bench table to have a read and write limit and those limits were enforced as expected
Fixes: #4703Closes#9810
* github.com:scylladb/scylla:
storage_proxy: metrics for per-partition rate limiting of reads
storage_proxy: metrics for per-partition rate limiting of writes
database: add stats for per partition rate limiting
tests: add per_partition_rate_limit_test
config: add add_per_partition_rate_limit_extension function for testing
cf_prop_defs: guard per-partition rate limit with a feature
query-request: add allow_limit flag
storage_proxy: add allow rate limit flag to get_read_executor
storage_proxy: resultize return type of get_read_executor
storage_proxy: add per partition rate limit info to read RPC
storage_proxy: add per partition rate limit info to query_result_local(_digest)
storage_proxy: add allow rate limit flag to mutate/mutate_result
storage_proxy: add allow rate limit flag to mutate_internal
storage_proxy: add allow rate limit flag to mutate_begin
storage_proxy: choose the right per partition rate limit info in write handler
storage_proxy: resultize return types of write handler creation path
storage_proxy: add per partition rate limit to mutation_holders
storage_proxy: add per partition rate limit info to write RPC
storage_proxy: add per partition rate limit info to mutate_locally
database: apply per-partition rate limiting for reads/writes
database: move and rename: classify_query -> classify_request
schema: add per_partition_rate_limit schema extension
db: add rate_limiter
storage_proxy: propagate rate_limit_exception through read RPC
gms: add TYPED_ERRORS_IN_READ_RPC cluster feature
storage_proxy: pass rate_limit_exception through write RPC
replica: add rate_limit_exception and a simple serialization framework
docs: design doc for per-partition rate limiting
transport: add rate_limit_error
clone staging sstables so their content may be compacted while
views are built. When done, the hard-linked copy in the staging
subdirectory will be simply unlinked.
Fixes#9559
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
We don't have to go over all sstables in the table to select the
staging sstables out of them, we can get it directly from the
_sstables_staging map.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
It's potentially a bit more efficient since
t.get_sstables is called only once, while
t.shared_from_this() is called per staging sstable.
Also, prepare for the following patches that modify
this function further.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
"
The way dc/rack info is maintained is very intricate.
The dc/rack strings originate at snitch, get propagated via gossiper,
get notified to storage service which, in turn, stores them into the
system keyspace and token metadata. Code that needs to get dc/rack
for a given endpoint calls snitch which tries to get the data from
gossiper and if failed goes and loads it from system keyspace cache.
Also there's "internal IP" thing hanging arond that loops messaging
service in both -- updating and getting the info.
The plan is to make topology (that currently sits on token metadata)
stay the only "source of truth" regarding the endpoints' dc/rack and
internal IP info. The dc/rack mappings are put into topology already,
but it cannot yet fully replace snitch for two reasons:
- it doesn't map internal IP to endpoint
- it doesn't get data stored in system keyspace
So what this patch set does is patches most of the dc/rack getters
to call topology methods. The topology is temporarily patched to
just call the respective snitch methods. This removes a big portion
of calls for global snitch instance.
After the set the places that still explicitly rely on snitch to
provide dc/rack are
- messaging service: needs internal IP knowledge on topology
- db/consistency_level: is all "global", needs heavier patching
- tests: just later
"
* 'br-get-dc-rack-from-topology-2' of https://github.com/xemul/scylla:
proxy stats: Get rack/datacenter from topology
proxy stats: Push topology arg to get_ep_stats
api: Get rack/datacenter from topology
hints: Remove snitch dependency
hints: Get rack/datacenter from topology
alternator: Get rack/datacenter from topology
range_streamer: Get rack/datacenter from topology
repair: Get rack/datacenter from topology
view: Get rack/datacenter from topology
storage_service: Get rack/datacenter from topology
proxy: Get rack/datacenter from topology
topology: Add get_rack/_datacenter methods
Now, mutate/mutate_result accept a flag which decides whether the write
should be rate limited or not.
The new parameter is mandatory and all call sites were updated.
Adds the new `per_partition_rate_limit` schema extension. It has two
parameters: `max_writes_per_second` and `max_reads_per_second`.
In the future commits they will control how many operations of given
type are allowed for each partition in the given table.
Introduces the rate_limiter, a replica-side data structure meant for
tracking the frequence with which each partition is being accessed
(separately for reads and writes) and deciding whether the request
should be accepted and processed further or rejected.
The limiter is implemented as a statically allocated hashmap which keeps
track of the frequency with which partitions are accessed. Its entries
are incremented when an operation is admitted and are decayed
exponentially over time.
If a partition is detected to be accessed more than its limit allows,
requests are rejected with a probability calculated in such a way that,
on average, the number of accepted requests is kept at the limit.
The structure currently weights a bit above 1MB and each shard is meant
to keep a separate instance. All operations are O(1), including the
periodic timer.
Adds a CQL protocol extension which introduces the rate_limit_error. The
new error code will be used to indicate that the operation failed due to
it exceeding the allowed per-partition rate limit.
The error code is supposed to be returned only if the corresponding CQL
extension is enabled by the client - if it's not enabled, then
Config_error will be returned in its stead.
The code which applied view filtering (i.e. a condition placed
on a view column, e.g. "WHERE v = 42") erroneously used a wildcard
selection, which also assumes that static columns are needed,
if the base table contains any such columns.
The filtering code currently assumes that no such columns are fetched,
so the selection is amended to only ask for regular columns
(primary key columns are sent anyway, because they are enabled
via slice options, so no need to ask for them explicitly).
Fixes#10851Closes#10855
After previous patch hints manager class gets unused dependency on
snitch. While removing it it turns out that several unrelated places
get needed headers indirectly via host_filter.hh -> snitsh_base.hh
inclusion.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The view code already gets token metadata from global proxy instance. Do
the same to get topology object.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The sstable set param isn't being used anywhere, and it's also buggy
as sstable run list isn't being updated accordingly. so it could happen
that set contains sstables but run list is empty, introducing
inconsistency.
we're fortunate that the bug wasn't activated as it would've been
a hard one to catch. found this while auditting the code.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20220617203438.74336-1-raphaelsc@scylladb.com>
Adds measuring the apparent delta vector of footprint added/removed within
the timer time slice, and potentially include this (if influx is greater
than data removed) in threshold calculation. The idea is to anticipate
crossing usage threshold within a time slice, so request a flush slightly
earlier, hoping this will give all involved more time to do their disk
work.
Obviously, this is very akin to just adjusting the threshold downwards,
but the slight difference is that we take actual transaction rate vs.
segment free rate into account, not just static footprint.
Note: this is a very simplistic version of this anticipation scheme,
we just use the "raw" delta for the timer slice.
A more sophisiticated approach would perhaps do either a lowpass
filtered rate (adjust over longer time), or a regression or whatnot.
But again, the default period of 10s is something of an eternity,
so maybe that is superfluous...
Adds "bytes_released" and "bytes_flush_requested", representing
total bytes released from disk as a result of segment release
(as allocation bytes + overhead - not counting unused "waste"),
resp. total size we've requested flush callbacks to release data,
also counted as actual used bytes in segments we request be made
released.
These counters, together with bytes_written, should in ideal use
cases be at an equilibrium (actually equal), thus observing them
should give an idea on whether we are imbalanced in managing to
release bytes in same rate as they are allocated (i.e. transaction
rate).
Apparent mismerge or something. We already have an unused "_flush_position",
intended to keep track of the last requested high rp.
Now actually update and use it. The latter to avoid sending requests for
segments/cf id:s we've already requested external flush of. Also enables
us to ensure we don't do double bookkeep here.
A pre-scrub view snapshot cannot be attributed to user error, so no
call to bail out.
Closes#10760.
Signed-off-by: Michael Livshin <michael.livshin@scylladb.com>
Closes#10783
* github.com:scylladb/scylla:
api-doc: correct spelling
allow pre-scrub snapshots of materialized views and secondary indices
When memtable receives a tombstone it can happen under some workloads
that it covers data which is still in the memtable. Some workloads may
insert and delete data within a short time frame. We could reduce the
rate of memtable flushes if we eagerly drop tombstoned data.
One workload which benefits is the raft log. It stores a row for each
uncommitted raft entry. When entries are committed they are
deleted. So the live set is expected to be short under normal
conditions.
Fixes#652.
Closes#10807
* github.com:scylladb/scylla:
memtable: Add counters for tombstone compaction
memtable, cache: Eagerly compact data with tombstones
memtable: Subtract from flushed memory when cleaning
mvcc: Introduce apply_resume to hold state for partition version merging
test: mutation: Compare against compacted mutations
compacting_reader: Drop irrelevant tombstones
mutation_partition: Extract deletable_row::compact_and_expire()
mvcc: Apply mutations in memtable with preemption enabled
test: memtable: Make failed_flush_prevents_writes() immune to background merging
{kind=link}