It's an adpator between seastar::file and cached_file. It gives a
seastar::file which will serve reads using a given cached_file as a
read-through cache.
We want buffers to be accounted only when they are used outside
cached_file. Cached pages should not be accounted because they will
stay around for longer than the read after subsequent commits.
In preparation for tracking different kinds of objects, not just
rows_entry, in the LRU, switch to the LRU implementation form
utils/lru.hh which can hold arbitrary element type.
The LRU can link objects of different types, which is achieved by
having a virtual base class called "evictable" from which the linked
objects should inherit. Whe the object is removed from the LRU,
evictable::on_evicted() is called.
The container is non-owning.
We never want to listen on port 0, even if configured so.
When the listen port is set to 0, the OS will choose the
port randomly, which makes it useless for communicating
with other nodes in the cluster, since we don't support that.
Also, it causes the listen_ports_conf_test internode_ssl_test
to fail since it expects to disable listening on storage_port
or ssl_storage_port when set to 0, as seen in
https://github.com/scylladb/scylla-dtest/issues/2174.
Fixes#8957
Test: unit(dev)
DTest: listen_ports_conf_test (modified)
Closes#8956
* github.com:scylladb/scylla:
messaging_service: do_start_listen: improve info log accuracy
messaging_service: never listen on port 0
The replication factor passed to NetworkTopologyStrategy (which we call
by the confusing name "auto expand") may or may not be used (see
explanation why in #8881), but regardless, we should validate that it's
a legal number and not some non-numeric junk, and we should report the error.
Before this patch, the two commands
CREATE KEYSPACE name WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 }
ALTER KEYSPACE name WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'replication_factor' : 'foo' }
succeed despite the invalid replication factor "foo". After this patch,
the second command fails.
The problem fixed here is reproduced by the existing test
test_keyspace.py::test_alter_keyspace_invalid when switching it to use
NetworkTopologyStrategy, as suggested by issue #8638.
Fixes#8880
Refs #8881
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20210620100442.194610-1-nyh@scylladb.com>
Make sure to log the info message when we actually
start listening.
Also, print a log message when listening on the
broadcast address.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
We never want to listen on port 0, even if configured so.
When the listen port is set to 0, the OS will choose the
port randomly, which makes it useless for communicating
with other nodes in the cluster, since we don't support that.
Also, it causes the listen_ports_conf_test internode_ssl_test
to fail since it expects to disable listening on storage_port
or ssl_storage_port when set to 0, as seen in
https://github.com/scylladb/scylla-dtest/issues/2174.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Scylla doesn't allow unencrypted connections over encrypted CQL ports
(Cassandra does allow this, by setting "optional: true", but it's not
secure and not recommended). Here we add a test that in indeed, we can't
connect to an SSL port using an unencrypted connection.
The test passes on Scylla, and also on Cassandra (run it on Cassandra
with "test/cql-pytest/run-cassandra --ssl" - for which we added support
in a recent patch).
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20210629121514.541042-1-nyh@scylladb.com>
Fixtures in conftest.py (e.g., the test_keyspace fixture) can be shared by
all tests in all source files, so they are marked with the "session"
scope: All the tests in the testing session may share the same instance.
This is fine.
Some of test files have additional fixtures for creating special tables
needed only in those files. Those were also, unnecessarily, marked
"session" scope as well. This means that these temporary tables are
only deleted at the very end of test suite, event though they can be
deleted at the end of the test file which needed them - other test
source files don't have access to it anyway. This is exactly what the
"module" fixture scope is, so this patch changes all the fixtures that
are private to one test file to use the "module" scope.
After this patch, the teardown of the last test in the suite goes down
from 0.26 seconds to just 0.06 seconds.
Another benefit is that the peak disk usage of the test suite is
lower, because some of the temporary tables are deleted sooner.
This patch does not change any test functionality, and also does not
make any test faster - it just changes the order of the fixture
teardowns.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#8932
Previously, the disk block alignment of segments was hardcoded (due to
really old code). Now we use the value as declared in the actual file
opened. If we are using a previously written file (i.e. o_dsync), we
can even use the sometimes smaller "read" alignment.
Also allow config to completely override this with a disk alignment
config option (not exposed to global config yet, but can be).
v2:
* Use overwrite alignment if doing only overwrite
* Ensure to adjust actual alignment if/when doing file wrapping
v3:
* Kill alignment config param. Useless and unsafe.
Closes#8935
This patch adds support for the "--ssl" option in run-cassandra, which
will now be able, like run (which runs Scylla), to run Cassandra with
listening to a *SSL-encrypted* CQL connection. The "--ssl" option is also
passed to the tests, so they know to encrypt their CQL connections.
We already had support for this feature in the test/cql-pytest/run
script - which runs Scylla. Adding this also to the run-cassandra
script can help verify that a behavior we notice in Scylla's SSL support
and we want to add to a test - is also shared by Cassandra.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20210629082532.535229-1-nyh@scylladb.com>
Add architecture name for relocatable packages, to support distributing
both x86_64 version and aarch64 version.
Also create symlink from new filename to old filename to keep
compatibility with older scripts.
Fixes#8675Closes#8709
[update tools/python3 submodule:
* tools/python3 ad04e8e...afe2e7f (1):
> reloc: add arch to relocatable package filename
]
* seastar 0e48ba883...eaa00e761 (3):
> memory: reduce statistics TLS initialization even more
> Merge "Sanitize io-topology creation on start" from Pavel E
> doc/prometheus: note that metric family is passed by query name
The permit creation path enters the semaphore's permit gate in
on_permit_created(). Entering this gate can throw so this method is not
noexcept. Remove the noexcept specifier accordingly.
Also enter the gate before adding the permit to the permit list, to save
some work when this fails.
Fixes: #8933
Tests: unit(dev)
Signed-off-by: Botond Dénes <bdenes@scylladb.com>
Message-Id: <20210628074941.32878-1-bdenes@scylladb.com>
Now that all supported versions write mc/md sstables, we can deprecate the MC_SSTABLE feature bit and consider it implicitly true, and with it the ability to write la/ka sstables.
We still need to support reading them, e.g. from restoring old snapshots or migrating data from legacy clusters.
Test: unit(dev, debug)
Fixes#8352Closes#8884
* github.com:scylladb/scylla:
compress: Remove unused make_compressed_file_k_l_format_output_stream
sstables: move sstable_writer to separate header
sstable_writer: remove get_metadata_collector
sstables: stop including metadata_collector.hh in sstables.hh
sstables: Remove duplicated friend declaration
sstables: remove unused KL writer
sstables: Always use MC/MD writer
sstable_datafile_test: switch tests to use latest sstables format
sstable_datafile_test: switch compaction_with_fully_expired_table to latest sstable version
test_offstrategy_sstable_compaction: test all writable sstables
compaction_with_fully_expired_table: Remove some LA specific code
sstable_mutation_test: test latest sstable format instead of LA
sstable_test: Test MX sstables instead of KA/LA
sstable_datafile_test: Fix schema used by check_compacted_sstables
sstables: Remove LA/KA sstable writting tests that check exact format
sstables: define writable_sstable_versions
features: assume MC_SSTABLE and UNBOUNDED_RANGE_TOMBSTONES are always enabled
"
query_singular() accepts a partition_range_vector, corresponding to an IN
query. But such queries are rare compared to single-partition queries.
Co-routinise the code and special case non-IN queries by avoiding
the call to map_reduce. Also replace executers array with small_vector
to avoid an allocation in the common case.
perf_simple_query --smp 1 --operations-per-shard 1000000 --task-quota-ms 10:
before: median 204545.04 tps ( 81.1 allocs/op, 15.1 tasks/op, 48828 insns/op)
after: median 219769.97 tps ( 74.1 allocs/op, 12.1 tasks/op, 46495 insns/op)
So, a ~7% improvement in tps and 5% improvement in instructions per op.
Also large reduction in tasks and allocations.
This is an alternative proposal to https://github.com/scylladb/scylla/pull/8909.
The benefit of this one is that it does not duplicate any code (almost).
"
* 'query_singular-coroutine' of github.com:scylladb/scylla-dev:
storage_proxy: avoid map_reduce in storage_proxy::query_singular if only one pk is queried
storage_proxy: use small_vector in storage_proxy::query_singular to store executors
storage_proxy: co-routinize storage_proxy::query_singular()
This class is used in only few places and does not have to be included
everywhere sstable class is needed.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
This function is only called internally so it does not have to be
exposed and can be inlined instead.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
Previous two patches removed the usage of KL writer so the code is now
dead and can be safely removed.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
Previous patch made MC the lowest sstables format in use so
the removed check is always true now and we can remove the else
part.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
instead of LA. Ability to write LA and KA sstables will be removed
by the following patches so we need to switch all the tests to write
newer sstables.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
"
Stopping transport (cql, thrift, messaging, etc.) can happen from
several places -- drain, decommission, stop, isolation. Some of
them can even run in parallel. This patch makes transport stopping
bulletproof.
tests: unit(dev)
start-stop (dev)
start-drain-stop (dev)
fixes: #8911
"
* 'br-stop-transport-races' of https://github.com/xemul/scylla:
storage_service: Indentation fix
storage_service: Make stop_transport re-entrable
storage_service: Stop transport on decommission
Storage service install disk error handlers in constructor and these
connections are not unregistered. It's not a problem in real life,
because storage service is not stopped, but in some tests this can
lead to use-after-frees.
The sstables_datafile_test runs some of the testcases in cql_test_env
which starts and (!) stops the storage service. Other testcases are
run in a lightweight sstables_test_env which does not mess with the
storage service at all. Now, if a case of the 2nd kind is run after
the one of the 1st and (for whatever reason) generates a disk error
it will trigger use-after-free -- after the 1st testcase the storage
service disk error registration would remain, but the storage service
itself would already be stopped, thus triggering the disk error will
try to access stopped sharded storage service inside the .isolate().
The fix is to keep the scoped connection on the storage service list
of various listeners. On stop it will go away automagically.
tests: unit(dev), sstables_datafile_test with forced disk error
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20210625062648.27812-1-xemul@scylladb.com>
std::copy_if runs without yielding.
See https://github.com/scylladb/scylla/issues/8897#issuecomment-867522480
Also, eliminate extraneous loop on merge
first1 will point to the inserted value which is a copy of *first2.
Since list2 is sorted in ascending order, the next item from list2
will never be less than the one we've just inserted,
so we waste an iteration to merely increment first1 again.
Fixes#8897
Test: unit(dev), stall_free_test(debug)
DTest: repair_additional_test.py:RepairAdditionalTest.{repair_same_row_diff_value_3nodes_diff_shard_count_test,repair_disjoint_row_3nodes_diff_shard_count_test} (dev)
Closes#8925
* github.com:scylladb/scylla:
utils: merge_to_gently: eliminate extraneous loop on merge
utils: merge_to_gently: prevent stall in std::copy_if
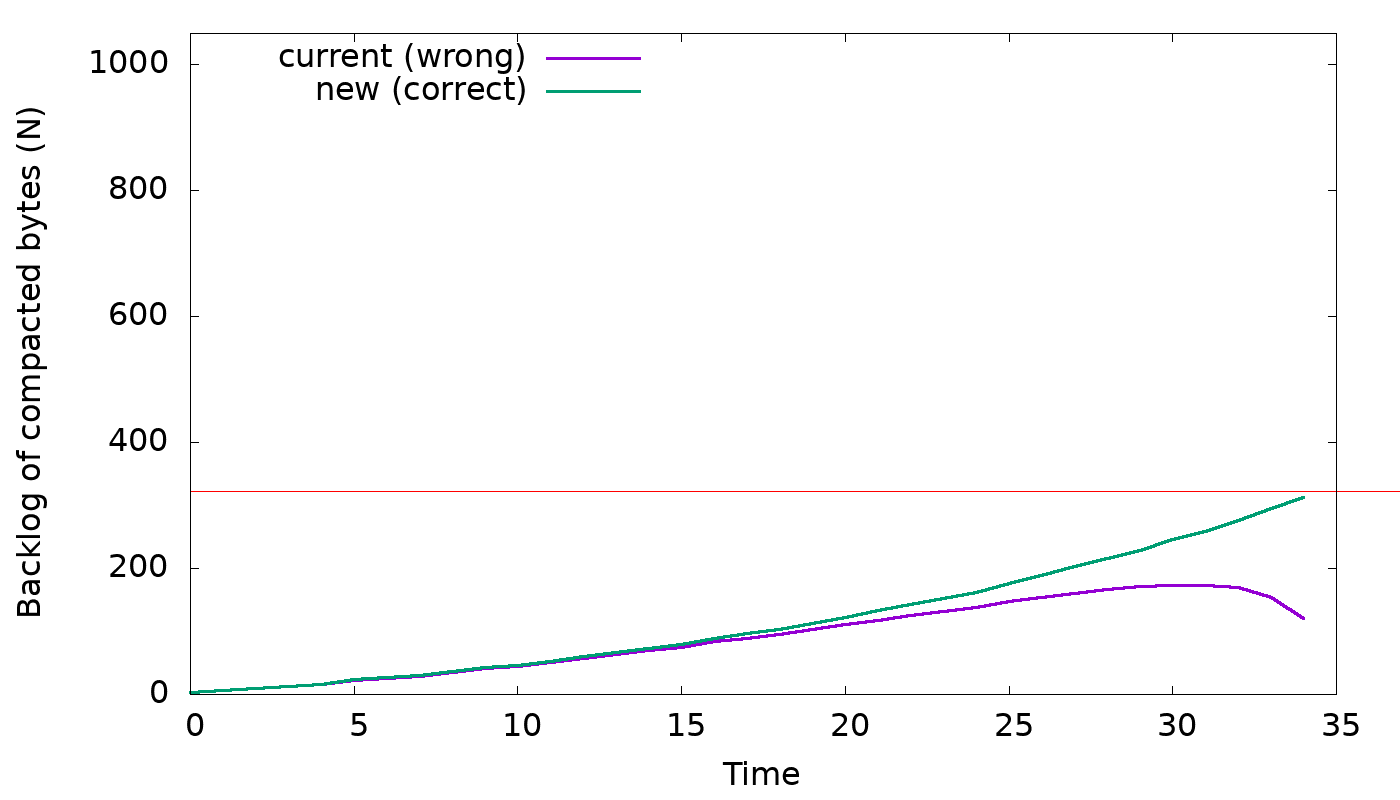
It was observed that as compaction progresses the backlog of compacting SSTable
is being reduced very slowly, which causes shares to be higher than needed, and
consequently compaction acts much more aggressively than it has to.
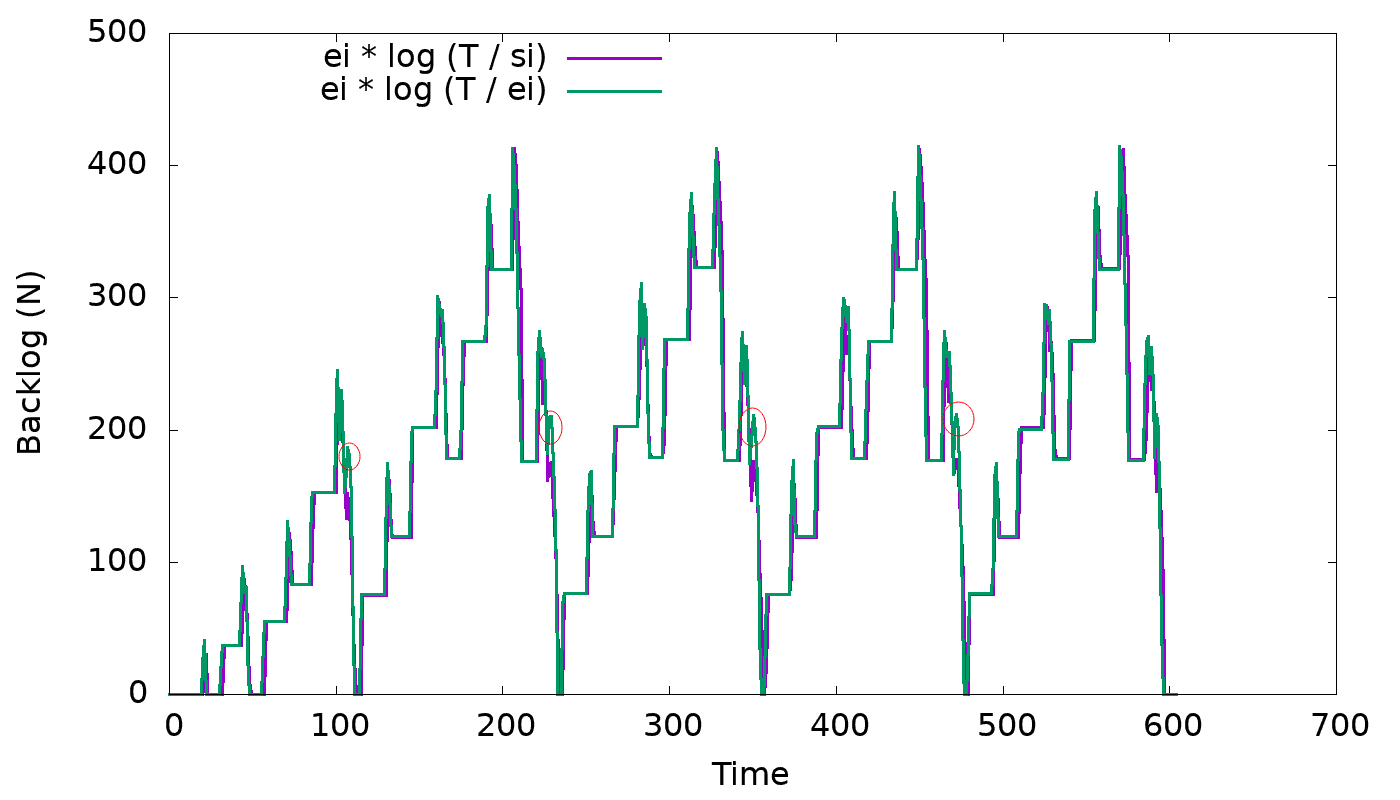
https://user-images.githubusercontent.com/1409139/120237819-93dfc080-c232-11eb-9042-68114e285ea0.png
The graph above shows the amount of backlog that is reduced from a SSTable
being compacted. The red line denotes the total backlog of the SSTable, before
it's selected for compaction. The expectation is that the more a SSTable is
compacted the more backlog will be reduced from it. However, in the current
implementation, it can be seen that the backlog to be reduced, from the SSTable
being compacted, starts being inversely proportional to the amount of data
already compacted.
Turns out that this problem happens because the implementation of backlog
formula becomes incorrect when the SSTable is being compacted.
Backlog for a sstable is currently defined as:
Bi = Ei * log (T / Ei)
where Ei = Si - Ci (bytes left to be compacted)
and Si = size of SStable
and Ci = total bytes compacted
and T = total size of table
The formula above can also be rewritten as follows:
Bi = Ei * log (T) - Ei * log (Ei)
the second term `Ei * log (Ei)` can be rewritten as:
= (Si - Ci) * log (Ei)
= Si * log (Ei) - Ci * log (Ei)
However, digging backlog implementation, turns out that we're incorrectly
implementing that second term as:
= Si * log (Si) - Ci * log (Ei)
Given that Si > Ei, for a SSTable being compacted, the backlog will be higher
than it should.
the following table shows how the backlog of a SSTable being compacted behaves
now versus how it's supposed to behave:
https://gist.github.com/raphaelsc/42e14be0d7d4ed264e538c2d217c8f95
Turns out that this is not the only problem. It was a mistake to change the
formula from `Ei * log(T / Si)` to `Ei * log(T / Ei)`, when fixing the
shrinking table issue, because that also causes the backlog of a compacting
SSTable to be incorrectly reduced.
With the formula rewritten as follows:
Bi = Ei * log (T) - Ei * log (Ei)
It becomes clear that the more a SSTable is compacted, the slower it becomes
for backlog to be reduced, as T / Ei can increase considerably over time.
So we're reverting the formula back to `Ei * log(T / Si)`.
The graph below shows a better backlog behavior when table is shrinking:
https://user-images.githubusercontent.com/1409139/123495186-06a54700-d5f9-11eb-9386-3fcf4dd8e4d3.png
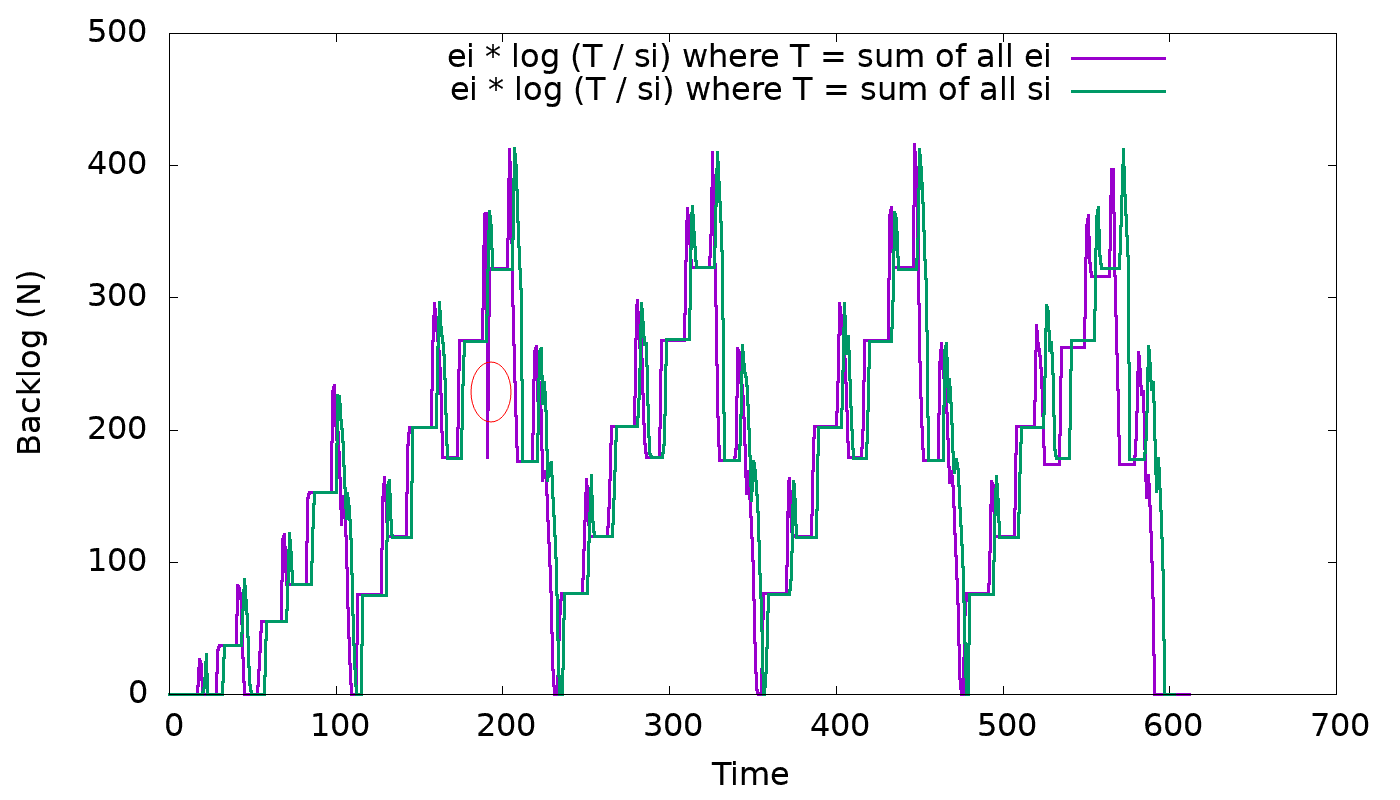
While analyzing the problem when table is shrinking, realized that it's because
T in the formula is implemented as the effective size (total + partial -
compacted).
With the new formula rewritten as follows:
Bi = Ei * log (T) - Ei * log (Si)
It becomes clearer that T cannot be lower than Si whatsoever, otherwise the
backlog becomes negative. Also, while table is shrinking, it can happen that
the backlog will be so low that compaction will barely make any progress.
To fix both issues, let's implement T as total size (sum of all Si) rather than
effective size (sum of all Ei).
The graph below shows that this change prevents the backlog from going negative
while still providing similar and expected behavior as before, see:
https://user-images.githubusercontent.com/1409139/123495185-060cb080-d5f9-11eb-89f7-ed445729702a.pngFixes#8768.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20210626003133.3011007-1-raphaelsc@scylladb.com>
It may happen that disk error opccurs and subsequent isolation runs
in parallel with drain or decommission or shutdown. In this case the
stop_transport method would be running two times in parallel. Also
the drain after decommission is not disabled, so it may happen that
stop_transport will be called two times in a row (however -- not in
parallel).
Using shared_promise solves all the possible reentrances.
(the indentation is deliberately left broken)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The stop_transport sequence is:
- stop client services (cql, thrift, alternator)
- stop gossiping
- stop messaging
- stop stream manager
The decommissioning goes very similarly
- stop client services
- stop batchlog manager
- stop gossiping
- stop messaging
So this change makes decommission stop all networking _before_
batchlog, like it's already done on drain, and additionally stop
the streaming manager.
This change is prerequisite for fixing race between transport
stop and isolation (on disk error).
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Following patches will switch all sstable writing tests to use
the latest sstables format. compaction_with_fully_expired_table
contains some test for a LA specific behaviour so let's remove it
to make the switch possible.
For more context see https://github.com/scylladb/scylla/issues/2620
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
Replace calls to make_compressed_file_k_l_format_input_stream
with calls to make_compressed_file_m_format_input_stream.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
check_compacted_sstables is used in compact_02 test which uses sstables
created by compact_sstables. The problem is that schema used in
check_compacted_sstables and compact_sstables is not the same.
The type of r1 column is different. This was not a problem when the
test was running on LA sstables but following patches will switch
all the tests to use MC and then sstable schema becomes validated
when reading the sstable and the test will fail such validation.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
Those tests check that created sstables have exactly the expected bytes
inside. This won't work with other sstable formats and writting LA/KA
sstables will be removed by the following patches so there's nothing
we can do with those tests but to remove them. Otherwise they will be
failing after LA/KA writting capability is removed.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
and use it instead of all_sstable_versions in tests that check
writting of sstables. Following patches remove LA/KA writer so we
want tests to be ready for that and not break by trying to write LA/KA
sstables.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
These features have been around for over 2 years and every reasonable
deployment should have them enabled.
The only case when those features could be not enabled is when the user
has used enable_sstables_mc_format config flag to disable MC sstable
format. This case has been eliminated by removing
enable_sstables_mc_format config flag.
Signed-off-by: Piotr Jastrzebski <piotr@scylladb.com>
The netw command tries to access the netw::_the_messaging_service that
was removed long ago. The correct place for the messaging service is
in debug:: namespace.
The scylla-gdb test checks that, but the netw command sees that the ptr
in question is not initialized, thinks it's not yet sharded::start()-ed
and exits without errors.
tests: unit(gdb)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20210624135107.12375-1-xemul@scylladb.com>
DateTieredCompactionStrategy (DTCS) has been un-recommended for a long time
(users should use TimeWindowCompactionStrategy, TWCS, instead). This
patch adds a new configuration option - restrict_dtcs - which can be used
to restrict the ability to use DTCS in CREATE TABLE or ALTER TABLE
statements. This is part of a "safe mode" effort to allow an installation
to restrict operations which are un-recommended or dangerous.
The new restrict_dtcs option has three values: "true", "false", and "warn":
For the time being, "false" is still the default, and means DTCS is not
restricted and can still be used freely. We can easily change this
default in a followup patch.
Setting a value of "true" means that DTCS *is* restricted -
trying to create a a table or alter a table with it will fail with an error.
Setting a value of "warn" will allow the create or alter operation, but
will warn the user - both with a warning message which will immediately
appear in cqlsh (for example), and with a log message.
Fixes#8914.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20210624122411.435361-1-nyh@scylladb.com>
first1 will point to the inserted value which is a copy of *first2.
Since list2 is sorted in ascending order, the next item from list2
will never be less than the one we've just inserted,
so we waste an iteration to merely increment first1 again.
Note that the standard states that no iterators or references are invalidated
on insert so we can safely keep looking at `first1` after inserting a copy of
`*first2` before it.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
{kind=link}
{kind=link}
{kind=link}