Main problem:
If we're draining the last node in a DC, we won't have a chance to
evaluate candidates and notice that constraints cannot be satisfied (N
< RF). Draining will succeed and node will be removed with replicas
still present on that node. This will cause later draining in the same
DC to fail when we will have 2 replicas which need relocaiton for a
given tablet.
The expected behvior is for draining to fail, because we cannot keep
the RF in the DC. This is consistent, for example, with what happens
when removing a node in a 2-node cluster with RF=2.
Fixes#21826
Secondary problem:
We allowed tablet_draining transition to be exited with undrained nodes, leaving replicas on nodes in the "left" state.
Third problem:
We removed DOWN nodes from the candidate node set, even when draining. This is not safe because it may lead to overload. This also makes the "main problem" more likely by extending it to the scenario when the DC is DOWN.
The overload part in not a problem in practice currently, since migrations will block on global topology barrier if there are DOWN nodes.
Closesscylladb/scylladb#21928
* github.com:scylladb/scylladb:
tablets: load_balancer: Fail when draining with no candidate nodes
tablets: load_balancer: Ignore skip_list when draining
tablets: topology_coordinator: Keep tablet_draining transition if nodes are not drained
This change is related to the unification of enterprise and open-source repositories.
The Sphinx configuration is updated to build documentation either for `docs.scylladb.com/manual` or `opensource.docs.scylladb.com`, depending on the flag passed to Sphinx.
By default, it will build docs for `docs.scylladb.com/manual`. If the `opensource` flag is passed, it will build docs for `opensource.docs.scylladb.com`, with a different set of versions.
This change will prepare the configuration to publish to `docs.scylladb.com/manual` while allowing the option to keep publishing and editing docs with a different multiversion configuration.
Note that this change will continue publishing docs to `opensource.docs.scylladb.com` for now since the `opensource` flag is being passed in the `gh-pages.yml` branch.
chore: remove comment
chore: update project name
Closesscylladb/scylladb#22089
Replace usages of `boost::algorithm::join()` with `fmt::join()` to improve
performance and reduce dependency on Boost. `fmt::join()` allows direct
formatting of ranges and tuples with custom separators without creating
intermediate strings.
When formatting comma-separated values into another string, fmt::join()
avoids the overhead of temporary string creation that
`boost::algorithm::join()` requires. This change also helps streamline
our dependencies by leveraging the existing fmt library instead of
Boost.Algorithm.
To avoid the ambiguity, some caller sites were updated to call
`seastar::format()` explicitly.
See also
- boost::algorithm::join():
https://www.boost.org/doc/libs/1_87_0/doc/html/string_algo/reference.html#doxygen.join_8hpp
- fmt::join():
https://fmt.dev/11.0/api/#ranges-api
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22082
Currently task_manager_module::is_aborted checks the tasks local
to caller's shard on a given shard.
Fix the method to check the task map local to the given shard.
Fixes: #22156.
Closesscylladb/scylladb#22161
in order to prevent future inclusion of unused headers, let's include
- mutation_writer
- node_ops
- redis
- replica
subdirectories to CLEANER_DIR, so that this workflow can identify the
regressions in future.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22050
The recent pull request https://github.com/scylladb/scylladb/pull/22031 introduced some regressions into the test/alternator framework. For a long time now, tests can create their own CQL roles for testing role-based features. But the new service levels test changed the "run" script and test.py's "suite.yaml" to create a new role and service level just for one test. This is not only ugly (the test code is now split to two places) and unnecessary, this setup also means that you can't run this test against an already-running copy of Scylla which wasn't prepared with the "right" role and service level. Even worse - the code that was added test/alternator/run was plain wrong - it used an outdated keyspace name (the code in suite.yaml was fine).
So in this patch I remove that extra run and suite.yaml code, and replace it by code inside the service level test to create the role and service level that it wants to test rather than assume it already exists.
While at it, I also removed a lot of duplicate and unnecessary code from this test.
After this patch, test/alternator/run returns to work correctly, after #22031 broke it.
This patch fixes a recent testing-framework regression, so doesn't need to be backported (unless that regression is backported).
Fixes#22047.
Closesscylladb/scylladb#22172
* github.com:scylladb/scylladb:
test/alternator: fix mistakes introduced with test_service_levels.py
test/alternator: move "cql" fixture to test/alternator/conftest.py
since Python 3.13, passing count to `re.sub()` as positional argument
has been deprecated. and when runnint `test.py` with Python 3.13, we
have following warning:
```
/home/kefu/dev/scylladb/./test.py:1540: DeprecationWarning: 'count' is passed as positional argument
args.modes = re.sub(r'.* List configured modes\n(.*)\n', r'\1',
```
see also https://github.com/python/cpython/issues/56166
in order to silence this distracting warning, let's pass
`count` using kwarg.
this change was created in the same spirit of c3be4a36af.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22085
Previously, `api/service_levels.hh` includes `api/api.hh` for
accessing symbols like `api/http_context`. but these symbols are
already available in a "smaller" header -- `api/api_init.hh`. so,
in order to improve the build efficiency, let's include smaller
headers in favor of "larger" ones.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22178
test.py: Only check existence of Scylla executable
Previously, we had inconsistent behavior around missing executables:
- 561e88f0 added early failure if any executable was missing
- 8b7a5ca8 added a partial skip for combined_test, but didn't properly
handle build paths and artifacts
This change:
1. Moves executable existence check to PythonTestSuite class
2. Only adds combined_test suite when the executable exists
3. Eliminates redundant os.access() checks
4. Corrects the path to combined_test when checking for its existence
This allows running tests with a partial build while properly handling
missing executables, particularly for the combined_test suite.
Fixesscylladb/scylladb#22086
---
no need to backport, because the offending commit (8b7a5ca88d) is not included by any LTS branches yet.
Closesscylladb/scylladb#22163
* github.com:scylladb/scylladb:
test.py: Fix path checking for combined_test executable
test.py: Throw only if scylla executable is not found
This patch undoes multiple mistakes done when introducing the test
for service levels in pull request #22031:
1. The PR introduced in test/alternator/run and test/alternator/suite.yaml
a permanent role and service level that the service-level test is
supposed to use. This was a mistake - the test can create the service
level for its own use, using CQL, it does not need to assume such a
service level already exists.
It's important to fix this to allow the service level test to run
against an installation of Scylla not set up by our own scripts.
Moreover, while the code in suite.yaml was correct, the code in
"run" was incorrect (used an outdated keyspace name). This patch
removes that incorrect code.
2. The PR introduced a duplicate "cql" fixture, copied verbatim
from test_cql_rbac.py (including a comment that was correct only
in the latter file :-)). Let's de-duplicate it, using the fixture
that I moved to conftest.py in the previous patch.
3. The PR used temporary_grant(). This needelessly complicated the test
and added even more duplicate code, and this patch removes all that
stuff. This test is about service levels, not RBAC and "grant".
This test should just use a superuser role that has the permissions
to do everything, and don't need to be granted specific permissions.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Most Alternator test use only the DynamoDB API, not CQL. Tests in
test_cql_rbac.py did need CQL to set up roles and RBAC, so this file
introduced a "cql" fixture to make CQL requests.
A recently-introduced test/alternator/test_service_levels.py also
needs access to CQL - it currently uses it for misguided reasons but
the next patch will need it for creating a role and a service level.
So instead of duplicating this fixture, let's move this fixture into
test/alternator/conftest.py that all Alternator tests can share.
The next patch will clean up this duplication in test_service_levels.py
and the other mistakes it introduced.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
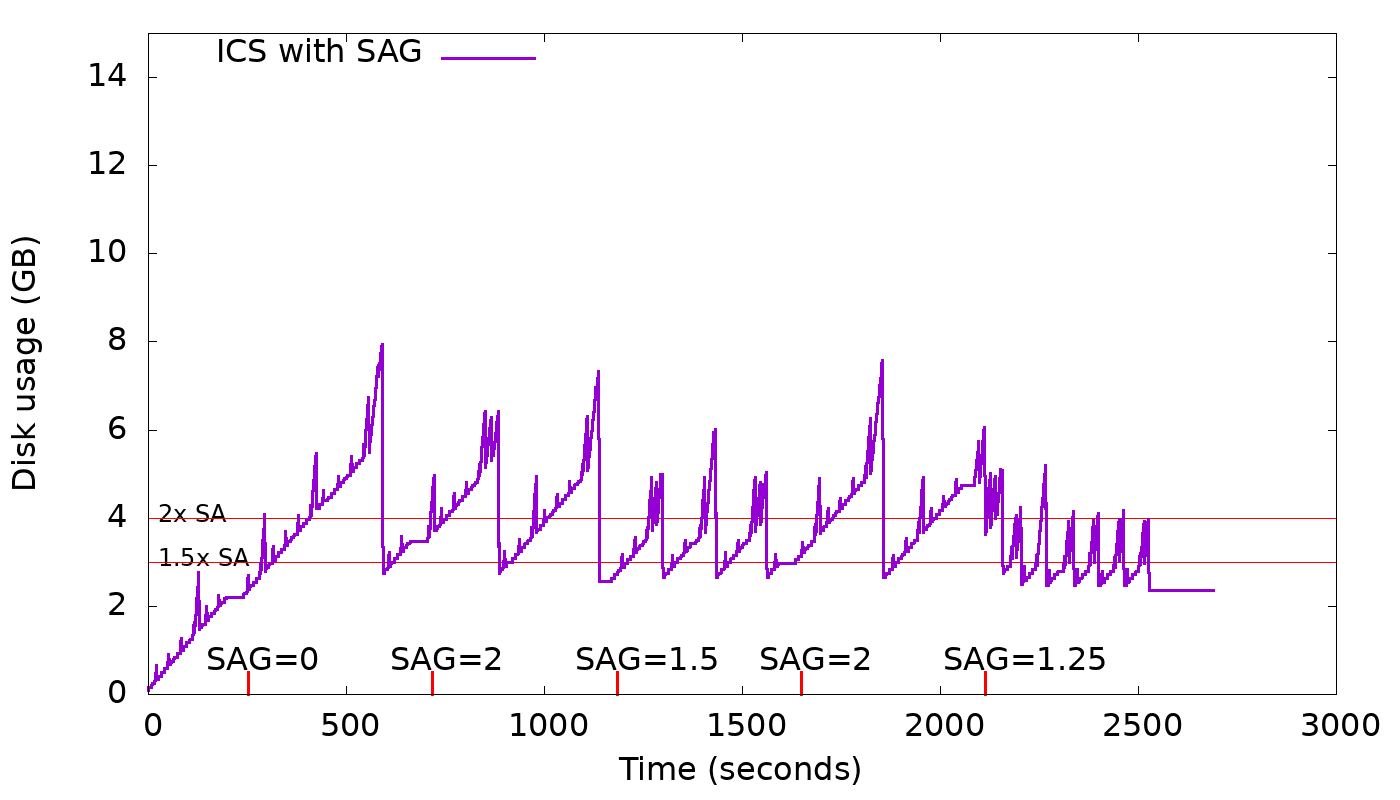
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
Previously in 8b7a5ca88d, we checked for combined_test existence
without the "build" component in the path. This caused the test
suite to never find the executable, preventing the test cases'
cache from being populated.
Changes:
1. Use path_to() to check executable existence, which:
- Includes the "build" component in path
- Handles both CMake and configure.py build paths
2. Move existence check out of _generate_cache() for clarity
This ensures combined_test and its included tests are properly
discovered and run.
Fixesscylladb/scylladb#22086
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Previously, we had inconsistent behavior around missing executables:
- 561e88f0 added early failure if any executable was missing
- 8b7a5ca8 added a partial skip for combined_test, but didn't properly
handle build paths and artifacts
This change:
1. Moves executable existence check to PythonTestSuite class
3. Eliminates redundant os.access() checks
This allows running tests with a partial build while properly handling
missing executables, particularly for the combined_test suite.
In a succeeding change, we will correct the check for combined_tests.
Refs scylladb/scylladb#19489
Refs scylladb/scylladb#22086
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
- utils: phased_barrier: advance_and_await: allocate new gate only when needed
- utils: phased_barrier: add close() method
- and use in existing services
* Improvement. No backport needed
Closesscylladb/scylladb#22018
* github.com:scylladb/scylladb:
utils: phased_barrier: add close() method
utils: phased_barrier: advance_and_await: allocate new gate only when needed
This series introduces workload prioritization: an extension of the service levels feature which allows specifying "shares" per service level. The number of shares determines the priority of the user which has this service level attached (if multiple are attached then the one with the lowest shares wins).
Different service levels will be isolated in the following way:
- Each service level gets its own scheduling group with the number of shares (corresponding to the service level's number of shares), which controls the priority of the CPU and I/O used for user operations running on that service level.
- Each service level gets two reader concurrency semaphores, one for user reads and the other for read-before-write done for view updates.
- Each service level gets its own TCP connections for RPC to prevent priority inversion issues.
Because of the mandatory use of scheduling groups, which are a globally limited resource, the number of service levels is now limited to 7 user created service levels + 1 created by default that cannot be removed.
This feature has been previously only available in ScyllaDB Enterprise but has been made available for the source available ScyllaDB. The series was created by comparing the master branch with source-available-workbranch / enterprise branch and taking the workload prioritization related parts from the diff, then molding the resulting diff into a proper series. Some very minor changes were made such as fixing whitespace, removing unused or unnecessary code, adding some boilerplate (in api/) which was missing, but otherwise no major changes have been made.
No backport is required.
Closesscylladb/scylladb#22031
* github.com:scylladb/scylladb:
tracing: record scheduling group in trace event record
qos: un-shared-from-this standard_service_level_distributed_data_accessor
alternator: execute under scheduling group for service level
test.py: support multiple commands in prepare_cql in suite.yml
docs: add documentation for workload prioritization
docs/dev: describe workload prioritization features in service_levels
test/auth_cluster: test workload prioritization in service level tests
cqlpy/test_service_levels: add workload prioritization tests
api: introduce service levels specific API
api/cql_server_test: add information about scheduling group
db/virtual_tables: add scheduling group column to system.clients
test/boost: update service_level_controller_test for workload prio
qos: include number of shares in DESCRIBE
cql3/statements: update SL statements for workload prioritization
transport/server: use scheduling group assigned to current user
messaging_service: use separate set of connections per service levels
replica/database: add reader concurrency semaphore groups
qos: manage and assign scheduling groups to service levels
qos: use the shares field in service level reads/writes
qos: add shares to service_level_options
qos: explicitly specify columns when querying service level tables
db/system_distributed_keyspace: add shares column and upgrade code
db/system_keyspace: adjust SL schema for workload prioritization
gms: introduce WORKLOAD_PRIORITIZATION cluster feature
build: increase the max number of scheduling groups
qos: return correct error code when SL does not exist
Previously fatal errors like missing Minio executable were logged at INFO level,
which could be filtered out by log settings. Switch to ERROR level to ensure
these critical issues are always visible to developers.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22084
we updated tools/java/build.xml recently to only build for java-11. so
if
- the `java` executable in `$PATH` points to a java which is neither
java-8 nor java-11.
- java-8 is installed
java-8 is used to execute the cassandra-stress tool. and we would have
following failure:
```
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/apache/cassandra/stress/Stress has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recogniz
es class file versions up to 52.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:756)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:473)
at java.net.URLClassLoader.access$100(URLClassLoader.java:74)
at java.net.URLClassLoader$1.run(URLClassLoader.java:369)
at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:621)
```
in order to be compatible with the bytecode targeting java-11, let's run
cassandra-stress with java-11. we do not need to support java-8, because
the new tools/java is now building cassandra-stress targeting java-11 jre.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22142
attribute server_broken_reason into the server was introduced, to store the raw information
regarding why the server was broken
additional information was added in the error messages in case of "server
broken"
fixes: #21630Closesscylladb/scylladb#22074
This string conversion functions are not in any fast path. Deinlining
them moves a <boost/lexical_cast.hpp> include out of a common header file.
Some files accessed on boost::iterator_range via lexical_cast.hpp,
so they gain a new dependency.
Closesscylladb/scylladb#21950
We have a "thread" field (unfortunately not yet displayed
in cqlsh, but visible in the table) that records the shard
on which a particular event was recorded. Record the scheduling
group as well, as this can be useful to understand where the
query came from.
(cherry picked from commit 3c03b5f66376dca230868e54148ad1c6a1ad0ee2)
Update `test_connections_parameters_auto_update` to also check that the
scheduling group of given connections is appropriately changed when a
different service level is assigned to the user that the connection uses
for authentication.
Apart from that, more tests are added:
- Check for the logic that forbids setting shares for a service level
until all nodes in the cluster are upgraded
- Test for handling the case when there are more scheduling groups than
it is allowed (it might happen after upgrade from a non-workload-prio
version)
- Regression test for a bug where less scheduling groups could have been
created than allowed due to some metrics not being renamed on
scheduling group name change.
Adjust existing cqlpy tests and add more in order to test the workload
prioritization feature:
- The DESCRIBE test is updated to check that generated statements
contain information about shares
- Two tests for shares in the LIST EFFECTIVE SERVICE LEVEL statement
- Regression test which checks that we can create as many service levels
as promised in the documentation (currently 7), but no more
- Test which checks that NULL shares in the service levels table are
treated as the default 1000 shares
Introduces two endpoints with operations specific to service levels:
- switch_tenants: updates the scheduling group of all connections to be
aligned with the service level specific to the logged in user. This is
mostly legacy API, as with service levels on raft this is done
automatically.
- count_connections: for each user and for each scheduling group, counts
how many connections are assigned to that user and scheduling group.
This API is used in tests.
Adjust some of the existing tests in service_level_controller_test.cc
and add some more in order to test the workload prioritization features,
i.e. the service level shares.
Now, the CREATE statements generated for each service level by the
DESCRIBE SCHEMA WITH INTERNALS statement will account for the service
level's shares.
Introduce the "SHARES" keyword which can be used in conjunction with
existing CQL statements related to the service levels.
Adjust the CQL statements for service levels:
- CREATE/ALTER now allow to set shares (only if the cluster is fully
upgraded)
- LIST EFFECTIVE SERVICE LEVEL now return the number of shares in a new
column
- LIST SERVICE LEVEL(S) also return the number of shares, and has the
additional column "percentage of all service level shares"
Now, when the user logs in and the connection becomes authenticated, the
processing loop of the connection is switched to the scheduling group
that corresponds to the service level assigned to the logged in user.
The scheduling group is also updated when the service level assigned to
this user changes.
Starting from this commit, the scheduling groups managed by the service
level controller are actually being used by user workload.
In order to make sure that the scheduling group carries over RPC, and
also to prevent priority inversion issues between different service
levels, modify the messaging service to use separate RPC connections for
each service level in order to serve user traffic.
The above is achieved by reusing the existing concept of "tenants" in
messaging service: when a new service level (or, more accurately,
service-level specific scheduling group) is first used in an RPC, a
new tenant is created.
In addition, extend the service level controller to be able to quickly
look up the service level name of the currently active scheduling group
in order to speed up the logic for choosing the tenant.
Replace the reader concurrency semaphores for user reads and view
updates with the newly introduced reader concurrency semaphore group,
which assigns a semaphore for each service level.
Each group is statically assigned to some pool of memory on startup and
dynamically distribute this memory between the semaphores, relative to
the number of shares of the corresponding scheduling group.
The intent of having a separate reader concurrency semaphore for each
scheduling group is to prevent priority inversion issues due to reads
with different priorities waiting on the same semaphore, as well as make
memory allocation more fair between service levels due to the adjusted
number of shares.
Introduce the core logic of workload prioritization, responsible for
assigning scheduling groups to service levels.
The service level controller maintains a pool of scheduling groups for
the currently present service levels, as well as a pool of unused
scheduling groups which were previously used by some service level that
was deleted during node's lifetime.
When a new service level is created, the SL controller either assigns a
scheduling group from the unused SG pool, or creates a new one if the
pool is empty. The scheduling group is renamed to "sl:<scheduling group
name>".
When updating shares of a service level (and also when creating a new
service level), the shares of the corresponding scheduling group are
synchronized with those of the service level.
When a service level is deleted, its group is released to the
aforementioned pool of unused scheduling groups and the prefix of its
name is changed from "sl:" to "sl_deleted:".
For now, these scheduling groups are not used by any user operations.
This will be changed in subsequent commits.
Add service level shares related fields to service_level_options and
slo_effective_names structs, and adjust the existing methods of the
former (merge_with, init_effective_names) to account for them.
The service levels table is queried with a `SELECT * ...` query, by
using the `execute_internal` method which prepares and caches the query
in an special cache for internal queries, separate from the user query
cache.
During rolling upgrade from a version which does not support service
level shares to the one that does, the `shares` column is added. The
aforementioned internal query cache is _not_ invalidated on schema
change, so the cache might still contain the prepared query from the
time before the column was added, and that prepared query will fetch the
old set of column without the new `shares` column.
In order to solve this, explicitly specify the columns in the query
string, using the full set of column names from the time when the query
is executed.
Note that this is a problem only for the legacy, non-raft service
levels. Raft-based service levels use a local table for which the schema
is determined on startup.
Also note that this code only fetches values from the `shares` column
but does not make any use of it otherwise. It will be handled by later
commits in this series.
Add the "shares" column to the
system_distributed_keyspace.service_levels table, which is used by
legacy code.
Because this table is in a distributed and not local keyspace, adding
the column to an existing cluster during rolling upgrade requires a bit
of care. A callback is added to the workload prioritization cluster
feature which runs when the feature becomes enabled and adds the column
for all nodes in the cluster.
Add a "shares" column which hold the number of shares allocated to
given service level.
It is not used by the code at all right now, subsequent commits will
make good use of it.
Information about the number of shares per service level will be stored
in an additional column in the service levels table, which is managed
through group0. We will need the feature to make sure that all nodes in
the cluster know about the new column before any node starts applying
group0 commands the would touch the new column.
This feature also serves a role for the legacy service levels
implementation that uses system_distributed for storage: after all nodes
are upgraded to support workload prioritization, one of the nodes will
perform a schema change operation and will add the new column.
{kind=link}