column_maybe_subscripted is a variant<column_value*, subscript*> that
existed for two reasons:
1. evaluation of subscripts and of columns took different paths.
2. calculation of the type of column or column[sub] took different paths.
Now that all evaluations go through evaluate(), and the types are
present in the expression itself, there is no need for column_maybe_subscripted
and it is replaced with plain expressions.
Some functions accept the right-hand-side as the first argument
and the left-hand-side as the second argument. This is now confusing,
but at least safe-ish, as the arguments have different types. It's
going to become dangerous when we switch to expressions for both sides,
so let's rationalize it by always starting with lhs.
Some parameters were annotated with _lhs/_rhs when it was not clear.
The grammar only allows comparing tuples of clustering columns, which
are non-null, but let's not rely on that deep in expression evaluation
as it can be relaxed.
is_satisfied_by() used an internal column_value_eval_bag type that
was more awkwardly named (and more awkward to use due to more nesting)
than evaluation_inputs. Drop it and use evaluation_inputs throughout.
The thunk is_satisified_by(evaluation_inputs) that just called
is_satisified_by(column_value_eval_bag) is dropped.
Currently, evaluate() accepts only query_options, which makes
it not useful to evaluate columns. As a result some callers
(column_condition) have to call it directly on the right-hand-side
of binary expressions instead of evaluating the binary expression
itself.
Change it to accept evaluation_input as a parameter, but keep
the old signature too, since it is called from many places that
don't have rows.
is_satisfied_by() rearranges the static and regular columns from
query::result_row_view form (which is a use-once iterator) to
std::vector<managed_bytes_opt> (which uses the standard value
representation, and allows random access which expression
evaluation needs). Doing it in is_saitisfied_by() means that it is
done every time an expression is evaluated, which is wasteful. It's
also done even if the expression doesn't need it at all.
Push it out to callers, which already eliminates some calls.
We still pass cql3::expr::selection, which is a layering violation,
but that is left to another time.
Note that in view.cc's check_if_matches(), we should have been
able to move static_and_regular_columns calculation outside the
loop. However, we get crashes if we do. This is likely due to a
preexisting bug (which the zero iterations loop avoids). However,
in selection.cc, we are able to avoid the computation when the code
claims it is only handling partition keys or clustering keys.
Callers are converted, but the internals are kept using the old
conventions until more APIs are converted.
Although the new API allows passing no query_options, the view code
keeps passing dummy query_options and improvement is left as a FIXME.
An expression may refer to values provided externally: the partition
and clusterinng keys, the static and regular row (all providing
column values), and the query options (providing values for bind
variables). Currently, different evaluation functions
(evaluate(), get_value(), and is_satisfied_by()) receive different
subsets of these values.
As a first step towards unifying the various ways to evaluate an
expression, collect the parameters in a single structure. Since
different evaluation contexts have different subsets, make everything
optional (via a pointer). Note that callers are expected to verify
using the grammar or prepare phase that they don't refer to values
that are not provided.
The cql3::selection::selection parameter is provided to translate
from query::result_row_view to schema column indexes. This is pretty
bad since it means the translation needs to be done for every
evaluation and is therefore a candidate for removal, but is kept here
since that's how it's currently done.
Marking a test as flaky allows to keep running it in CI rather than disable it when it's discovered that a test is flaky.
Flaky tests, if they fail, show up as flaky in the output, but don't fail the CI.
```
kostja@hulk:~/work/scylla/scylla$ ./test.py cdc_with --repeat=30 --verbose
Found 30 tests.
================================================================================
[N/TOTAL] SUITE MODE RESULT TEST
------------------------------------------------------------------------------
[1/30] cql debug [ FLKY ] cdc_with_lwt_test.2 9.36s
[2/30] cql debug [ FLKY ] cdc_with_lwt_test.1 9.53s
[3/30] cql debug [ PASS ] cdc_with_lwt_test.7 9.37s
[4/30] cql debug [ PASS ] cdc_with_lwt_test.8 9.41s
[5/30] cql debug [ PASS ] cdc_with_lwt_test.10 9.76s
[6/30] cql debug [ FLKY ] cdc_with_lwt_test.9 9.71s
```
Closes#10721
* github.com:scylladb/scylla:
test.py: add support for flaky tests
test.py: make Test hierarchy resettable
test.py: proper suite name in the log
test.py: shutdown cassandra-python connection before exit
The idea is that a flaky test can be marked as flaky
rather than disabled to make sure it passes in CI.
This reduces chances of a regression being added
while the flakiness is being resolved and the number
of disabled tests doesn't grow.
Introduce reset() hierarchy, which is similar to __init__(),
i.e. allows to reset test execution state before retrying it.
Useful for retrying flaky tests.
Use a nice suite name rather than an internal Python
object key in the log. Fixes a regression introduced
when addressing a style-related review remark.
Shutdown cassandra-python connections before exit, to avoid
warnings/exceptions at shutdown.
Cassandra-python runs a thread pool and if
connections are not shut down before exit, there could
be a warning that the thread pool is not destroyed
before exiting main.
CDC tables use a custom partitioner, which is not reflected in schema dumps (`CREATE TABLE ...`) and currently it is not possible to fix this properly, as we have no syntax to set the partitioner for a table. To work around this, the schema loader determines whether a table is a cdc table based on its name (does it end with `_scylla_cdc_table`) and sets the partitioner manually if it is the case.
Fixes: https://github.com/scylladb/scylla/issues/9840Closes#10774
* github.com:scylladb/scylla:
tools/schema_loader: add support for CDC tables
cdc/log.hh: expose is_log_name()
Change port type passed to Cassandra Python driver to int to avoid format errors in exceptions.
Manually shutdown connections to avoid reconnects after tests are done (required by upcoming async pytests).
Tests: (dev)
Closes#10722
* github.com:scylladb/scylla:
test.py: shutdown connection manually
test.py: fix port type passed to Cassandra driver
CDC tables use a custom partitioner, which is not reflected in schema
dumps (`CREATE TABLE ...`) and currently it is not possible to fix this
properly, as we have no syntax to set the partitioner for a table.
To work around this, the schema loader determines whether a table is a
cdc table based on its name (does it end with `_scylla_cdc_table`) and
sets the partitioner manually if it is the case.
Allow outside code to use it to determine whether a table is cdc or not.
This is currently the most reliable method if the custom partitioner is
not set on the schema of the investigated table.
"
This series is a consequence of the work started by:
"compaction: LCS: Fix inefficiency when pushing SSTables to higher levels"
9de7abdc80
"Redefine Compaction Backlog to tame compaction aggressiveness" d8833de3bb
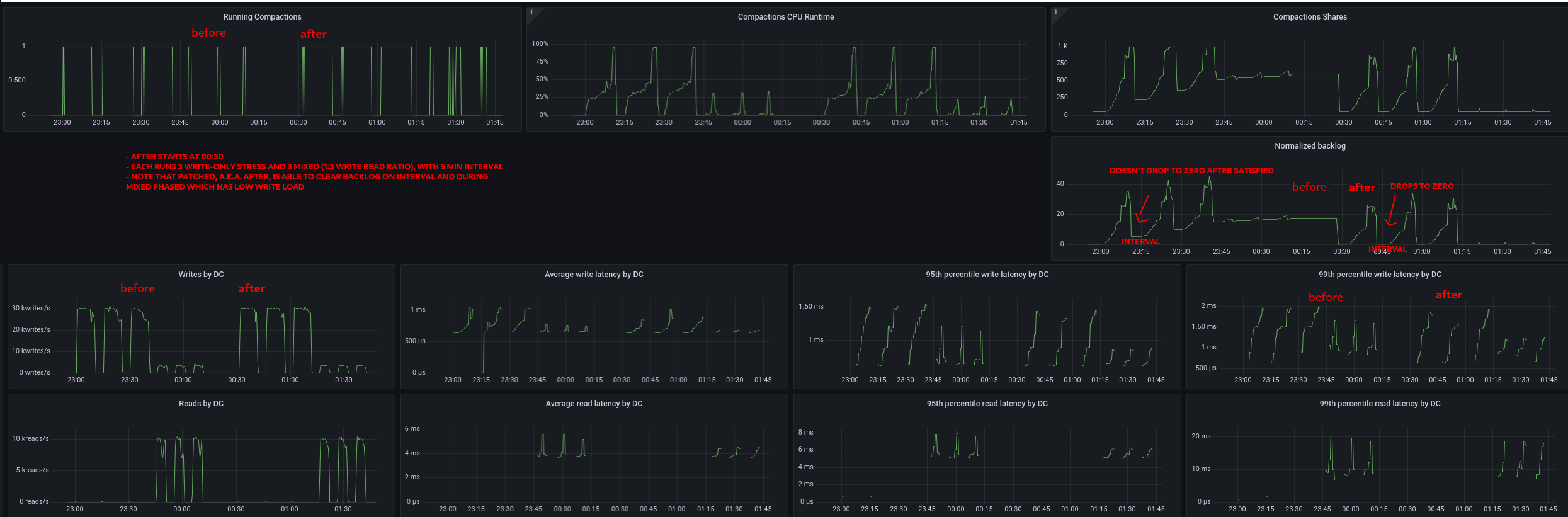
The backlog definition for leveled is incorrectly built on the assumption that
the world must reach the state of zero amplification, i.e. everything in the
last level. The actual goal is space amplification of 1.1.
In reality, LCS just wants that for every level L, level L is fan_out=10 times
larger than L-1. See more in commit 9de7abdc80 which adjusts LCS to conform
to this goal.
If level 3 = 1000G, level 2 = 100G, level 1 = 10G, level 0 = 1G, that should
return zero backlog as space amplification is (1000+100+10+1)/1000 = ~1.1
But today, LCS calculates high backlog for the layout above, as it will only be
satisfied once everything is promoted to the maximum level. That's completely
disconnected from what the strategy actually wants. Therefore, a mismatch.
With today's definition, the backlog for any SSTable is:
sizeof(sstable) * (Lmax - levelof(sstable)) * fan_out
where Lmax = maximum level,
and fan_out = LCS' fan out which is 10 by default
That's essentially calculating the total cost for data in the SSTable to climb
up to the maximum level. Of course, if a SSTable is at the maximum level,
(Lmax - levelof(sstable)) returns zero, therefore backlog for it is zero.
Take a look at this example:
If L0 sstable is 0.16G, then its backlog = 0.16G * (3 - 0) * 10 = 4.8G
0.16G = LCS' default fragment size
Maximum level (Lmax in formula) can be easily 3 as:
log10 of (30G/0.16G=~187 sstables)) = ~2.27
~2.27 means that data has exceeded level 2 capacity and so needs 3 levels.
So 3 L0 sstables could add ~15G of backlog. With 1G memory per shard (30:1 disk
memory ratio), that's normalized backlog of ~15, which translates into
additional ~500 shares. That's halfway to full compaction speed.
With more files in higher levels, we can easily get to a normalized backlog
above 30, resulting in 1k shares.
The suboptimal backlog definition causes either table using LCS or coexisting
tables to run with more shares than needed, causing compaction to steal
resources, resulting in higher latency and reduced throughput.
To solve this problem, a new formula is used which will basically calculate
the amount of work needed to achieve the layout goal. We no longer want to
promote everything to the last level, but instead we'll incrementally calculate
the backlog in each level L, which is the amount of work needed such that the
next level L + 1 is at least fan_out times bigger.
Fixes#10583.
Results
=====
image:
https://user-images.githubusercontent.com/1409139/168713675-d5987d09-7011-417c-9f91-70831c069382.png
The patched version correctly clears the backlog, meaning that once LCS is
satisfied, backlog is 0. Therefore, next compaction either from this table or
another won't run unnecessarily aggressive.
p99 read and write latency have clearly improved. throughput is also more
stable.
"
* 'LCS_backlog_revamp' of https://github.com/raphaelsc/scylla:
tests: sstable_compaction_test: Adjust controller unit test for LCS
compaction: Redefine Leveled compaction backlog
The controller unit test for LCS was only creating level 0 SSTables.
As level 0 falls back to STCS controller, it means that we weren't actually
testing LCS controller.
So let's adjust the unit test to account for LCS fan_out, which is 10
instead of 4, and also allow creation of SSTables on higher levels.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
The backlog definition for leveled is incorrectly built on the assumption that
the world must reach the state of zero amplification, i.e. everything in the
last level. The actual goal is space amplification of 1.1.
In reality, LCS just wants that for every level L, level L is fan_out=10 times
larger than L-1. See more in commit 9de7abdc80 which adjusts LCS to conform
to this goal.
If level 3 = 1000G, level 2 = 100G, level 1 = 10G, level 0 = 1G, that should
return zero backlog as space amplification is (1000+100+10+1)/1000 = ~1.1
But today, LCS calculates high backlog for the layout above, as it will only be
satisfied once everything is promoted to the maximum level. That's completely
disconnected from what the strategy actually wants. Therefore, a mismatch.
With today's definition, the backlog for any SSTable is:
sizeof(sstable) * (Lmax - levelof(sstable)) * fan_out
where Lmax = maximum level,
and fan_out = LCS' fan out which is 10 by default
That's essentially calculating the total cost for data in the SSTable to climb
up to the maximum level. Of course, if a SSTable is at the maximum level,
(Lmax - levelof(sstable)) returns zero, therefore backlog for it is zero.
Take a look at this example:
If L0 sstable is 0.16G, then its backlog = 0.16G * (3 - 0) * 10 = 4.8G
0.16G = LCS' default fragment size
Maximum level (Lmax in formula) can be easily 3 as:
log10 of (30G/0.16G=~187 sstables)) = ~2.27
~2.27 means that data has exceeded level 2 capacity and so needs 3 levels.
So 3 L0 sstables could add ~15G of backlog. With 1G memory per shard (30:1 disk
memory ratio), that's normalized backlog of ~15, which translates into
additional ~500 shares. That's halfway to full compaction speed.
With more files in higher levels, we can easily get to a normalized backlog
above 30, resulting in 1k shares.
The suboptimal backlog definition causes either table using LCS or coexisting
tables to run with more shares than needed, causing compaction to steal
resources, resulting in higher latency and reduced throughput.
To solve this problem, a new formula is used which will basically calculate
the amount of work needed to achieve the layout goal. We no longer want to
promote everything to the last level, but instead we'll incrementally calculate
the backlog in each level L, which is the amount of work needed such that the
next level L + 1 is at least fan_out times bigger.
Fixes#10583.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Since commit 3dc9a81d02 (repair: Repair
table by table internally), a table is always repaired one after
another. This means a table will be repaired in a continuous manner.
Unlike before a table will be repaired again after other tables have
finished the same range.
```
for range in ranges
for table in tables
repair(range, table)
```
The wait interval can be large so we can not utilize the assumption if
there is no repair traffic, the whole table is finished.
After commit 3dc9a81d02, we can utilize
the fact that a table is repaired continuously property and trigger off
strategy automatically when no repair traffic for a table is present.
This is especially useful for decommission operation with multiple
tables. Currently, we only notify the peer node the decommission is done
and ask the peer to trigger off strategy compaction. With this
patch, the peer node will trigger automatically after a table is
finished, reducing the number of temporary sstables on disk.
Refs #10462Closes#10761
messaging_service.hh is a switchboard - it includes many things,
and many things include it. Therefore, changes in the things it
includes affect many translation units.
Reduce the dependencies by forward-declaring as much as possible.
This isn't pretty, but it reduces compile time and recompilations.
Other headers adjusted as needed so everything (including
`ninja dev-headers`) still compile.
Closes#10755
Currently, preparing the left-hand-side of a binary operator and the
right-hand-side use different code paths. The left-hand-side derives
the type of the expression from the expression itself, while the
right-hand-side imposes the type on the expression (allowing the types
of bind variables to be inferred).
This series unifies the two, by making the imposed type (the "receiver")
optional, and by allowing prepare to fail gracefully if we were not able
to infer the type. The old prepare_binop_lhs() is removed and replaced
with prepare_expression, already used for the right hand side.
There is one step remaining, and that is to replace prepare_binary_operator
with prepare_expression, but that is more involved and is left for a follow-up.
Closes#10709
* github.com:scylladb/scylla:
cql3: expr: drop prepare_binop_lhs()
cql3: expr: move implementation of prepare_binop_lhs() to try_prepare_expression()
cql3: expr: use recursive descent when preparing subscripts
cql3: expr: allow prepare of tuple_constructor with no receiver
cql3: expr: drop no longer used printable_relation parameter from prepare_binop_lhs()
cql3: expr: print only column name when failing to resolve column
cql3: expr: pass schema to prepare_expression
cql3: expr: prepare_binary_operator: drop unused argument ctx
cql3: expr: stub type inference for prepare_expression
cql3: expr: introduce type_of() to fetch the type of an expression
cql3: expr: keep type information in casts
cql3: expr: add type field to subscript, field_selection, and null expressions
cql3: expr: cast: use data_type instead of cql3_type for the prepared form
It turns out that DynamoDB forbids requesting the same item more than
once in a GetBatchItem request. Trying to do it would obviously be a
waste, but DynamoDB outright refuses it - and Alternator currently
doesn't (refs #10757).
The test currently passes on DynamoDB and fails on Alternator, so it
is marked xfail.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10758
As seen in https://github.com/scylladb/scylla/issues/10738,
compaction::setup might stall when processing a large number of sstables.
Make it a coroutine and maybe_yield to prevent those stalls.
Closes#10750
* github.com:scylladb/scylla:
compaction: setup: reserve space for _input_sstable_generations
compaction: coroutinize setup and maybe yield
This series converts try/catch blocks in coroutines for multishard_mutation_query to use coroutine::as_future to get and handle errors, reducing exception handling costs (that are expected on timeouts).
It was previously sent to the mailing list.
This version (v2) is just a rebase of the v1 series,
with one patch dropped as it was already merged to master independentally.
Closes#10727
* github.com:scylladb/scylla:
multishard_mutation_query: do_query: couroutinize save_readers lambda
multishard_mutation_query: do_query: prevent exceptions using coroutine::as_future
multishard_mutation_query: read_page: prevent exceptions using coroutine::as_future
multishard_mutation_query: save_readers: fixup indentation
multishard_mutation_query: coroutinize save_readers
multishard_mutation_query: lookup_readers: make noexcept
multishard_mutation_query: optimize lookup_readers
We know in advance the maximum number of
sstable generations to track, so reserve space for it
to prevent vector reallocation for large number of sstables.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Optimize error handling by preventing
exception try/catch using coroutine::as_future
to get query::consume_page's result.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
And use smp::invoke_on_all rather than a home-brewed
version of parallel_for_each over all shard ids.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Sot it can be co_awaited efficiently using coroutine::as_future,
othwise, any exceptions will escape `as_future`.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
No need to call _db.invoke_on inside a parallel_for_each
loop over all shards. Just use _db.invoke_on_all instead.
Besides that, there's no need for a .then continuation
for assigning the per-shard reader in _readers[shard].
It can be done by the functor running on each db shard.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Found with scylla --blocked-reactor-notify-ms 1 during replace operation with rbno turned on.
The stalls showed without this patch were gone after this path set.
Closes#10737
* github.com:scylladb/scylla:
repair: Avoid stall in working_row_hashes
repair: Avoid stall in apply_rows_on_master_in_thread
* seastar 2be9677d6e...1424d34c93 (22):
> Use tls socket to retrieve distinguished name
> perftune.py: remove duplicates in 'append' parameters when we dump an options file
> rpc: add an option for an asynchronous connection isolation function
> Merge "Add more facilities to RPC tester" from Pavel E
> json: wait for writing final characters of a json document
> Revert "Use tls socket to retrieve distinguished name"
> future.hh: drop unused parameters
> core/scollected: initialize _buf explicitly
> rpc: remove recursion in do_unmarshall()
> coroutine: Fix generator clang compilation
> core: Reduce the default blocked-reactor-notify-ms to 25ms
> build: group "CMAKE_CXX_*" options together
> doc: s/c++dialect/c++-standard/
> test: coroutines: adjust coroutine generator test for gcc
> Use tls socket to retrieve distinguished name
> coroutine: add an async generator
> net/api: s/server_socket::is_listening()/operator bool()/
> net/api: let "server_socket::local_address()" always return an addr
> tls_test: Remove unsupported prio string from test case
> Merge 'abort_source: assert request_abort called exactly once' from Benny Halevy
> coroutines/all: stop using std::aligned_union_t
> coroutines/all: ensure the template argument deduction work with clang-15
Closes#10739
The issue is about handling errors when the user specifies something strange instead of a type, e.g. CREATE TABLE try1 (a int PRIMARY KEY, b list<zzz>):
* the error message only talks about collections, while zzz could also be an UDT;
* the same error message is given even when zzz is not a valid collection or UDT name.
The first point has already been fixed, now Scylla says 'Non-frozen user types or collections are not allowed inside collections: list<zzz>'. This commit fixes the second.
Whether the type is a valid UDT or not is checked in cql3_type::raw_ut::prepare_internal, but 'non-frozen' check triggers first in cql3_type::raw_collection::prepare_internal, before we recursively get to the argument types of the collection. The patch reverses the order here, first thing we recurse and ensure that the collection argument types are valid, and only then we apply the collection checks. A side effect of this is that the error messages of the checks in raw_collection will include the keyspace name, because it will now be assigned in raw_ut::prepare_internal before them.
The patch affects the validation order, so in case of list<zzz<xxx>> the message could be different, but it doesn't seem to be possible according to the Cql grammar.
Examples:
create type ut2 (a int, b list<ut1>); --> error('Unknown type ks.ut1')
create type ut1 (a int);
create type ut2 (a int, b list<ut1>); --> error('Non-frozen user types or collections are not allowed inside collections: list<ks.ut1>')
create type ut2 (a int, b list<frozen<ut1>>); --> OK
Fixes: scylladb#3541
Closes#10726
In 69af7a830b ("tools: toolchain: prepare: build arch images in parallel"),
we added parallel image generation. But it turns out that buildah can
do this natively (with the --platform option to specify architectures
and --jobs parameter to allow parallelism). This is simpler and likely
has better error handling than an ad-hoc bash script, so switch to it.
Closes#10734
{kind=link}