Add task manager's task covering resharding compaction.
A struct and some functions are moved from replica/distributed_loader.cc
to compaction/task_manager_module.cc.
`gossiper::remove_endpoint` performs `on_remove` callbacks for all
endpoint change subscribers. This was done in the background (with a
discarded future) due the following reason:
```
// We can not run on_remove callbacks here because on_remove in
// storage_service might take the gossiper::timer_callback_lock
```
however, `gossiper::timer_callback_lock` no longer exists, it was
removed in 19e8c14.
Today it is safe to perform the `storage_service::on_remove` callback in
the foreground -- it's only taking the token metadata lock, which is
also taken and then released earlier by the same fiber that calls
`remove_endpoint` (i.e. `storage_service::handle_state_normal`).
Furthermore, we want to perform it in the foreground. First, there
already was a comment saying:
```
// do subscribers first so anything in the subscriber that depends on gossiper state won't get confused
```
it's not too precise, but it argues that subscriber callbacks should be
serialized with the rest of `remove_endpoint`, not done concurrently
with it.
Second, we now have a concrete reason to do them in the foreground. In
issue #14646 we observed that the subcriber callbacks are racing with
the bootstrap procedure. Depending on scheduling order, if
`storage_service::on_remove` is called too late, a bootstrapping node
may try to wait for a node that was earlier replaced to become UP which
is incorrect. By putting the `on_remove` call into foreground of
`remove_endpoint`, we ensure that a node that was replaced earlier will
not be included in the set of nodes that the bootstrapping node waits
for (because `storage_service::on_remove` will clear it from
`token_metadata` which we use to calculate this set of nodes).
We also get rid of an unnecessary `seastar::async` call.
Fixes#14646Closes#14741
The feature check in `enable_features_on_startup` loads the list
of features that were enabled previously, goes over every one of them
and checks whether each feature is considered supported and whether
there is a corresponding `gms::feature` object for it (i.e. the feature
is "registered"). The second part of the check is unnecessary
and wrong. A feature can be marked as supported but its `gms::feature`
object not be present anymore: after a feature is supported for long
enough (i.e. we only support upgrades from versions that support the
feature), we can consider such a feature to be deprecated.
When a feature is deprecated, its `gms::feature` object is removed and
the feature is always considered enabled which allows to remove some
legacy code. We still consider this feature to be supported and
advertise it in gossip, for the sake of the old nodes which, even
though they always support the feature, they still check whether other
nodes support it.
The problem with the check as it is now is that it disallows moving
features to the disabled list. If one tries to do it, they will find
out that upgrading the node to the new version does not work:
`enable_features_on_startup` will load the feature, notice that it is
not "registered" (there is no `gms::feature` object for it) and fail
to boot.
This commit fixes the problem by modifying `enable_features_on_startup`
not to look at the registered features list at all. In addition to
this, some other small cleanups are performed:
- "LARGE_COLLECTION_DETECTION" is removed from the deprecated features
list. For some reason, it was put there when the feature was being
introduced. It does not break anything because there is
a `gms::feature` object for it, but it's slightly confusing
and therefore is removed.
- The comment in `supported_feature_set` that invites developers to add
features there as they are introduced is removed. It is no longer
necessary to do so because registered features are put there
automatically. Deprecated features should still be put there,
as indicated as another comment.
Fortunately, this issue does not break any upgrades as of now - since
we added enabled cluster feature persisting, no features were
deprecated, and we only add registered features to the persisted feature
list.
An error injection and a regression test is added.
Closes#14701
* github.com:scylladb/scylladb:
topology_custom: add deprecated features test
feature_service: add error injection for deprecated cluster feature
feature_service: move error injection check to helper function
feature_service: handle deprecated features correctly in feature check
Move `merger` to its own header file. Leave the logic of applying
commands to `group0_state_machine`. Remove `group0_state_machine`
dependencies from `merger` to make it an independent module.
Add a test that checks if `group0_state_machine_merger` preserves
timeuuid monotonicity. `last_id()` should be equal to the largest
timeuuid, based on its timestamps.
This test combines two commands in the reverse order of their timeuuids.
The timeuuids yield different results when compared in both timeuuid
order and uuid order. Consequently, the resulting command should have a
more recent timeuuid.
Fixes#14568Closes#14682
* github.com:scylladb/scylladb:
raft: group0_state_machine_merger: add test for timeuuid ordering
raft: group0_state_machine: extract merger to its own header
Fixes#10447
This issue is an expected behavior. However, `abort_requested_exception` is not handled properly.
-- Why this issue appeared
1. The node is drained.
2. `migration_manager::drain` is called and executes `_as.request_abort();`.
3. The coordinator sends read RPCs to the drained replica. On the replica side, `storage_proxy::handle_read` calls `migration_manager::get_schema_for_read`, which is defined like this:
```cpp
future<schema_ptr> migration_manager::get_schema_for_write(/* ... */) {
if (_as.abort_requested()) {
co_return coroutine::exception(std::make_exception_ptr(abort_requested_exception()));
}
/* ... */
```
So, `abort_requested_exception` is thrown.
4. RPC doesn't preserve information about its type, and it is converted to a string containing its error message.
5. It is rethrown as `std::runtime_error` on the coordinator side, and `abstract_resolve_reader::error()` logs information about it. However, we don't want to report `abort_requested_exception` there. This exception should be catched and ignored:
```cpp
void error(/* ... */) {
/* ... */
else if (try_catch<abort_requested_exception>(eptr)) {
// do not report aborts, they are trigerred by shutdown or timeouts
}
/* ... */
```
-- Proposed solution
To fix this issue, we can add `abort_requested_exception` to `replica::exception_variant` and make sure that if it is thrown by `migration_manager::get_schema_for_write`, `storage_proxy::handle_read` correctly encodes it. Thanks to this change, `abstract_read_resolver::error` can correctly handle `abort_requested_exception` thrown on the replica side by not reporting it.
-- Side effect of the proposed solution
If the replica supports it, the coordinator doesn't, and all nodes support `feature_service::typed_errors_in_read_rpc`, the coordinator will fail to decode `abort_requested_exception` and it will be decoded to `unknown_exception`. It will still be rethrown as `std::runtime_error`, however the message will change from *abort requested* to *unknown exception*.
-- Another issue
Moreover, `handle_write` reports abort requests for the same reason. This also floods the logs (this time on the replica side) for the same reason. I don't think it is intended, so I've changed it too. This change is in the last commit.
Closes#14681
* github.com:scylladb/scylladb:
service: storage_proxy: do not report abort requests in handle_write
service: storage_proxy: encode abort_requested_exception in handle_read
service: storage_proxy: refactor encode_replica_exception_for_rpc
replica: add abort_requested_exception to exception_variant
This is a translation of Cassandra's CQL unit test source file
BatchTest.java into our cql-pytest framework.
This test file an old (2014) and small test file, with only a few minimal
testing of mostly error paths in batch statements. All test tests pass in
both Cassandra and Scylla.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#14733
test.py with --x-log2-compaction-groups option rotted a little bit.
Some boost tests added later didn't use the correct header which
parses the option or they didn't adjust suite.yaml.
Perhaps it's time to set up a weekly (or bi-weekly) job to verify
there are no regressions with it. It's important as it stresses
the data plane for tablets reusing the existing tests available.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closes#14732
by default, up to 3 temporary directories are kept by pytest.
but we run only a single time for each of the $TMPDIR. per
our recent observation, it takes a lot more time for jenkins
to scan the tempdir if we use it for scylla's rundir.
so, to alleviate this symptom, we just keep up to one failed
session in the tempdir. if the test passes, the tempdir
created by pytest will be nuked. normally it is located at
scylladb/testlog/${mode}/pytest-of-$(whoami).
see also
https://docs.pytest.org/en/7.3.x/reference/reference.html#confval-tmp_path_retention_policy
Refs #14690
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closes#14735
[xemul: Withdrawing from PR's comments
object_store is the only test which
is using tmpdir fixture
starts / stops scylla by itself
and put the rundir of scylla in its own tmpdir
we don't register the step of cleaning up [the temp dir] using the utilities provided by
cql-pytest. we rely on pytest to perform the cleanup. while cql-pytest performs the
cleanup using a global registry.
]
Some minor fixes reported by `mypy`.
Closes#14693
* github.com:scylladb/scylladb:
test/pylib: fix function attribute
test/pylib: check cmd is defined before using it
test/pylib: fix return type hint
test/pylib: remove redundant method
for faster build times and clear inter-module dependencies, we
should not #includes headers not directly used. instead, we should
only #include the headers directly used by a certain compilation
unit.
in this change, the source files under "/compaction" directories
are checked using clangd, which identifies the cases where we have
an #include which is not directly used. all the #includes identified
by clangd are removed. because some source files rely on the incorrectly
included header file, those ones are updated to #include the header
file they directly use.
if a forward declaration suffice, the declaration is added instead.
see also https://clangd.llvm.org/guides/include-cleaner#unused-include-warningCloses#14740
* github.com:scylladb/scylladb:
treewide: remove #includes not use directly
size_tiered_backlog_tracker: do not include remove header
Fixes#9405
`sync_point` API provided with incorrect sync point id might allocate
crazy amount of memory and fail with `std::bad_alloc`.
To fix this, we can check if the encoded sync point has been modified
before decoding. We can achieve this by calculating a checksum before
encoding, appending it to the encoded sync point, and compering it with
a checksum calculated in `db::hints::decode` before decoding.
Closes#14534
* github.com:scylladb/scylladb:
db: hints: add checksum to sync point encoding
db: hints: add the version_size constant
for faster build times and clear inter-module dependencies, we
should not #includes headers not directly used. instead, we should
only #include the headers directly used by a certain compilation
unit.
in this change, the source files under "/compaction" directories
are checked using clangd, which identifies the cases where we have
an #include which is not directly used. all the #includes identified
by clangd are removed. because some source files rely on the incorrectly
included header file, those ones are updated to #include the header
file they directly use.
if a forward declaration suffice, the declaration is added instead.
see also https://clangd.llvm.org/guides/include-cleaner#unused-include-warning
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
By making it independent of the number of units the view update
generator's registration semaphore is created with. We want to increase
this number significantly and that would destabilize this test
significantly. To prevent this, detach the test from the number of units
completely, while stil preserving the original intent behind it, as best
as it could be determined.
Closes#14727
in order to identify the problems caused by integer type promotion when comparing unsigned and signed integers, in this series, we
- address the warnings raised by `-Wsign-compare` compiler option
- add `-Wsign-compare` compiler option to the building systems
Closes#14652
* github.com:scylladb/scylladb:
treewide: use unsigned variable to compare with unsigned
treewide: compare signed and unsigned using std::cmp_*()
This series is based on top of the seastar relabel config API.
The series adds a REST API for the configuration, it allows to get and set it.
The API is registered under the V2 prefix and uses the swagger 2.0 definition.
After this series to get the current relabel-config configuration:
```
curl -X GET --header 'Accept: application/json' 'http://localhost:10000/v2/metrics-config/'
```
A set config example:
```
curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' -d '[ \
{ \
"source_labels": [ \
"__name__" \
], \
"action": "replace", \
"target_label": "level", \
"replacement": "1", \
"regex": "io_que.*" \
} \
]' 'http://localhost:10000/v2/metrics-config/'
```
This is how it looks like in the UI
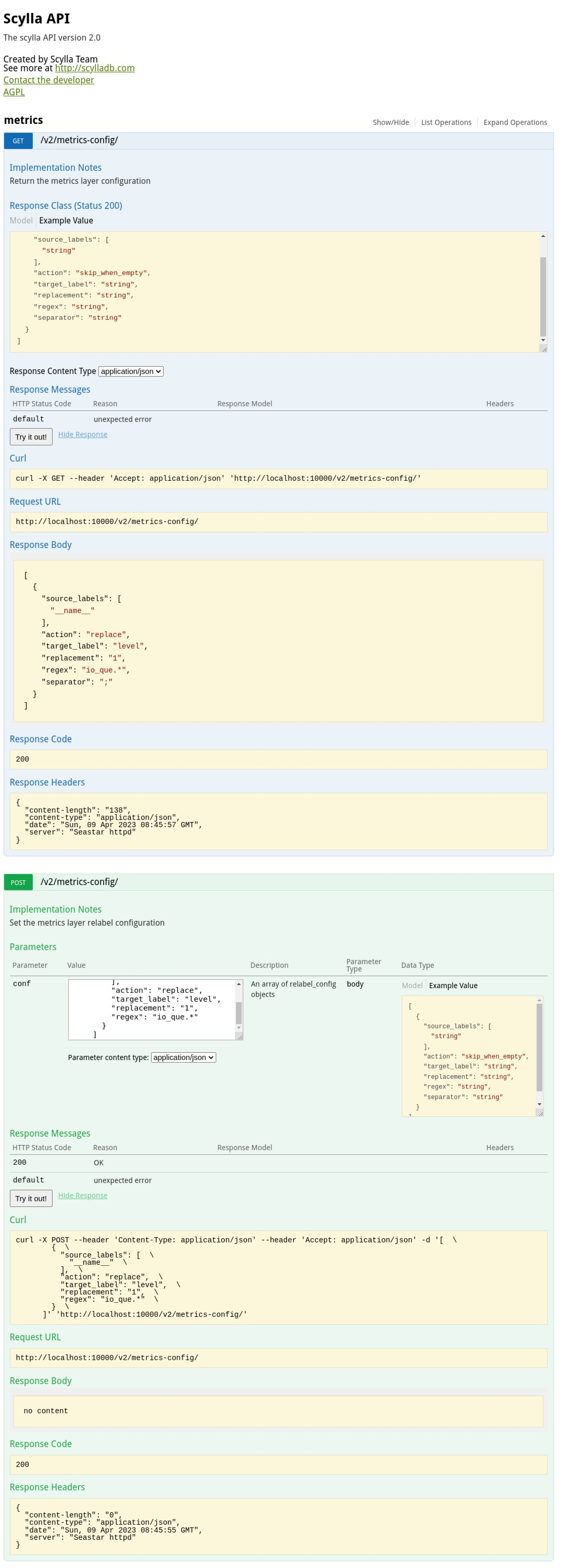
Closes#12670
* github.com:scylladb/scylladb:
api: Add the metrics API
api/config: make it optional if the config API is the first to register
api: Add the metrics.json Swagger file
Preparing for V2 API from files
this series addresses the FTBFS of tests with CMake, and also checks for the unknown parameters in `add_scylla_test()`
Closes#14650
* github.com:scylladb/scylladb:
build: cmake: build SEASTAR tests as SEASTAR tests
build: cmake: error out if found unknown keywords
build: cmake: link tests against necessary libraries
before this change, we sort sstables with compaction disabled, when we
are about to perform the compaction. but the idea of of guarding the
getting and registering as a transaction is to prevent other compaction
to mutate the sstables' state and cause the inconsistency.
but since the state is tracked on per-sstable basis, and is not related
to the order in which they are processed by a certain compaction task.
we don't need to guard the "sort()" with this mutual exclusive lock.
for better readability, and probably better performance, let's move the
sort out of the lock. and take this opportunity to use
`std::ranges::sort()` for more concise code.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closes#14699
some times we initialize a loop variable like
auto i = 0;
or
int i = 0;
but since the type of `0` is `int`, what we get is a variable of
`int` type, but later we compare it with an unsigned number, if we
compile the source code with `-Werror=sign-compare` option, the
compiler would warn at seeing this. in general, this is a false
alarm, as we are not likely to have a wrong comparison result
here. but in order to prevent issues due to the integer promotion
for comparison in other places. and to prepare for enabling
`-Werror=sign-compare`. let's use unsigned to silence this warning.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
when comparing signed and unsigned numbers, the compiler promotes
the signed number to coomon type -- in this case, the unsigned type,
so they can be compared. but sometimes, it matters. and after the
promotion, the comparison yields the wrong result. this can be
manifested using a short sample like:
```
int main(int argc, char **argv) {
int x = -1;
unsigned y = 2;
fmt::print("{}\n", x < y);
return 0;
}
```
this error can be identified by `-Werror=sign-compare`, but before
enabling this compiling option. let's use `std::cmp_*()` to compare
them.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
This patch adds a metrics API implementation.
The API supports get and set the metric relabel config.
Seastar supports metrics relabeling in runtime, following Prometheus
relabel_config.
Based on metrics and label name, a user can add or remove labels,
disable a metric and set the skip_when_empty flag.
The metrics-config API support such configuration to be done using the
RestFull API.
As it's a new API it is placed under the V2 path.
After this patch the following API will be available
'http://localhost:10000/v2/metrics-config/' GET/POST.
For example:
To get the current config:
```
curl -X GET --header 'Accept: application/json' 'http://localhost:10000/v2/metrics-config/'
```
To set a config:
```
curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' -d '[ \
{ \
"source_labels": [ \
"__name__" \
], \
"action": "replace", \
"target_label": "level", \
"replacement": "1", \
"regex": "io_que.*" \
} \
]' 'http://localhost:10000/v2/metrics-config/'
```
Until now, only the configuration API was part of the V2 API.
Now, when other APIs are added, it is possible that another API would be
the first to register. The first to register API is different in the
sense that it does not have a leading ',' to it.
This patch adds an option to mark the config API if it's the first.
This patch changes the base path of the V2 of the API to be '/'. That
means that the v2 prefix will be part of the path definition.
Currently, it only affect the config API that is created from code.
The motivation for the change is for Swagger definitions that are read
from a file. Currently, when using the swagger-ui with a doc path set
to http://localhost:10000/v2 and reading the Swagger from a file swagger
ui will concatenate the path and look for
http://localhost:10000/v2/v2/{path}
Instead, the base path is now '/' and the /v2 prefix will be added by
each endpoint definition.
From the user perspective, there is no change in current functionality.
Signed-off-by: Amnon Heiman <amnon@scylladb.com>
sync point API provided with incorrect sync point id might allocate
crazy amount of memory and fail with std::bad_alloc.
To fix this, we can check if the encoded sync point has been modified
before decoding. We can achieve this by calculating a checksum before
encoding, appending it to the encoded sync point, and compering
it with a checksum calculated in db::hints::decode before decoding.
The next commit changes the format of encoding sync points to V2. The
new format appends the checksum to the encoded sync points and its
implementation uses the checksum_size constant - the number of bytes
required to store the checksum. To increase consistency and readability,
we can additionally add and use the version_size constant.
Definitions of sync_point::decode and sync_point::encode are slightly
changed so that they don't depend on the version_size value and make
implementation of the V2 format easier.
Modify sstable_compaction_test.cc so that it does not depend on
how quick compaction manager stats are updated after compaction
is triggered.
It is required since in the following changes the context may
switch before the stats are updated.
Compaction task executors which inherit from compaction_task_impl
may stay in memory after the compaction is finished.
Thus, state switch cannot happen in destructor.
Switch state to none in perform_task defer.
This test checks if `group0_state_machine_merger` preserves timeuuid monotonicity.
`last_id()` should be equal to the largest timeuuid, based on its timestamps.
This test combines two commands in the reverse order of their timeuuids.
The timeuuids yield different results when compared in both timeuuid order and
uuid order. Consequently, the resulting command should have a more recent timeuuid.
Closes#14568
Move `merger` to its own header file. Leave the logic of applying commands to
`group0_state_machine`. Remove `group0_state_machine` dependencies from `merger`
to make it an independent module. Add `static` and `const` keywords to its
methods signature. Change it to `class`. Add documentation.
With this patch, it is easier to write unit tests for the merger.
The `locator::topology::config::this_host_id` field is redundant
in all places that use `locator::topology::config`, so we can
safely remove it.
Closes#14638Closes#14723
We don't want to report aborts in storage_proxy::handle_write, because it
can be only triggered by shutdowns and timeouts.
Before this change, such reports flooded logs when a drained node still
received the write RPCs.
storage_proxy::handle_read now makes sure that abort_requested_exception
is encoded in a way that preserves its type information. This allows
the coordinator to properly deserialize and handle it.
Before this change, if a drained replica was still receiving the read
RPCs, it would flood the coordinator's logs with std::runtime_error
reports.
To properly handle abort_requested_exception thrown from
migration_manager::get_schema_for_read in storage_proxy::handle_read (we
do in the next commit) we have to somehow encode and return it. The
encode_replica_exception_for_rpc function is not suitable for that because
it requires the SourceTuple type (of a value returned by do_query()) which
we don't know when calling get_schema_for_read.
We move the part of encode_replica_exception_for_rpc responsible for
handling exceptions to a new function and rewrite it in a way that doesn't
require the SourceTuple type. As this function fits the name
encode_replica_exception_for_rpc better, we name it this way and rename
the previous encode_replica_exception_for_rpc.
With Raft-topology enabled, test_remove_garbage_group0_members has been
flaky when it should always fail. This has been discussed in #14614.
Disabling Raft-topology in the topology suite is problematic because
the initial cluster size is non-zero, so we have nodes that already use
Raft-topology at the beginning of the test. Therefore, we move
test_topology_remove_garbage_group0.py to the topology_custom suite.
Apart from disabling Raft-topology, we have to start 4 servers instead
of 1 because of the different initial cluster sizes.
Closes#14692
Fixes https://github.com/scylladb/scylladb/issues/13783
This commit documents the nodetool checkAndRepairCdcStreams
operation, which was missing from the docs.
The description is added in a new file and referenced from
the nodetool operations index.
Closes#14700
This is the first phase of providing strong exception safety guarantees by the generic `compaction_backlog_tracker::replace_sstables`.
Once all compaction strategies backlog trackers' replace_sstables provide strong exception safety guarantees (i.e. they may throw an exception but must revert on error any intermediate changes they made to restore the tracker to the pre-update state).
Once this series is merged and ICS replace_sstables is also made strongly exception safe (using infrastructure from size_tiered_backlog_tracker introduced here), `compaction_backlog_tracker::replace_sstables` may allow exceptions to propagate back to the caller rather than disabling the backlog tracker on errors.
Closes#14104
* github.com:scylladb/scylladb:
leveled_compaction_backlog_tracker: replace_sstables: provide strong exception safety guarantees
time_window_backlog_tracker: replace_sstables: provide strong exception safety guarantees
size_tiered_backlog_tracker: replace_sstables: provide strong exception safety guarantees
size_tiered_backlog_tracker: provide static calculate_sstables_backlog_contribution
size_tiered_backlog_tracker: make log4 helper static
size_tiered_backlog_tracker: define struct sstables_backlog_contribution
size_tiered_backlog_tracker: update_sstables: update total_bytes only if set changed
compaction_backlog_tracker: replace_sstables: pass old and new sstables vectors by ref
compaction_backlog_tracker: replace_sstables: add FIXME comments about strong exception safety
{kind=link}