As part of #18750, we added a CQL statement CREATE ROLE WITH SALTED HASH that prevented hashing a password when creating a role, effectively leading to inserting a hash given by the user directly into the database. In #21350, we noticed that Cassandra had implemented a CQL statement of similar semantics but different syntax. We decided to rename Scylla's statement to be compatible with Cassandra. Unfortunately, we didn't notice one more difference between what we had in Scylla and what was part of Cassandra.
Scylla's statement was originally supposed to only be used when restoring the schema and the user needn't have to be aware of its existence at all: the database produced a sequence of CQL statements that the user saved to a file and when a need to restore the schema arose, they would execute the contents of the file. That's why that although we documented the feature, it was only done in the necessary places. Those that weren't related to the backup & restore procedure were deliberately skipped.
Cassandra, on the other hand, added the statement for a different purpose (for details, see the relevant issue) and it was supposed to be used by the user by design. The statement is also documented as such.
Since we want to preserve compatibility with Cassandra, we document the statement and its semantics in the user documentation, explicitly implying that it can be used by the user.
We also add a test verifying that logging in works correctly.
Fixesscylladb/scylladb#21691
Backport: not needed. The relevant code didn't make it to 6.2 or any previous version of OSS.
Closesscylladb/scylladb#21752
* github.com:scylladb/scylladb:
docs: Update documentation on CREATE ROLE WITH HASHED PASSWORD
test/boost: Add test for creating roles with hashed passwords
The "--experimental" option was removed in commit f6cca741ea. Using this
deprecated option now causes Scylla to fail with the error:
```
error: the argument ('on') for option '--experimental-features' is invalid
```
So, in this change, let's update the docker entry point script to use
`--experimental-features` command line option instead. The related
document is updated accordingly.
Fixesscylladb/scylladb#22207
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22283
In Scylla there are two options that control IO bandwidth limit -- the /storage_service/(compaction|stream)_throughput REST API endpoints. The endpoints are partially implemented and have no counterparts in the nodetool.
This set implements the missing bits and adds tests for new functionality.
Closesscylladb/scylladb#21877
* github.com:scylladb/scylladb:
nodetool: Implement [gs]etstreamthroughput commands
nodetool: Implement [gs]etcompationthroughput commands
test: Add validation of how IO-updating endpoints work
api: Implement /storage_service/(stream|compaction)_throughput endpoints
api: Disqualify const config reference
api: Implement /storage_service/stream_throughput endpoint
api: Move stream throughput set/get endpoints from storage service block
api: Move set_compaction_throughput_mb_per_sec to config block
util: Include fmt/ranges.h in config_file.hh
Said fields in statistics are of type
`disk_array<uint32_t, disk_string<uint16_t>>` and currently are handled
as array of regular strings. However these fields store exploded
clustering keys, so the elements store binary data and converting to
string can yield invalid UTF-8 characters that certain JSON parsers (jq,
or python's json) can choke on. Fix this by treating them as binary and
using `to_hex()` to convert them to string. This requires some massaging
of the json_dumper: passing field offset to all visit() methods and
using a caller-provided disk-string to sstring converter to convert disk
strings to sstring, so in the case of statistics, these fields can be
intercepted and properly handled.
While at it, the type of these fields is also fixed in the
documentation.
Before:
"min_column_names": [
"��Z���\u0011�\u0012ŷ4^��<",
"�2y\u0000�}\u007f"
],
"max_column_names": [
"��Z���\u0011�\u0012ŷ4^��<",
"}��B\u0019l%^"
],
After:
"min_column_names": [
"9dd55a92bc8811ef12c5b7345eadf73c",
"80327900e2827d7f"
],
"max_column_names": [
"9dd55a92bc8811ef12c5b7345eadf73c",
"7df79242196c255e"
],
Fixes: #22078Closesscylladb/scylladb#22225
Fixes https://github.com/scylladb/scylla-enterprise/issues/5016#issuecomment-2558464631
EAR - encryption at rest. Allows on-disk file encryption of sstables and commitlog data.
Introduces OpenSSL based file level encrypted storage, managed via a set of providers
ranging from local files to cloud KMS providers.
For a more comprehensive explanation, see the included docs (or if possible, original
source tree).
Manual bulk merge of EAR feature from enterprise repo to main scylla repo.
Breaks some features apart, but main EAR is still a humongous commit, because to separate this
I would have to mess with code incrementally, adding time and risk.
This PR includes the local file gen tool, tests and also p11 validation.
Note: CI will not execute the full tests unless master CI is set to provide the same environment
as the enterprise one. Not sure about the status of this ATM.
Note: Includes code to compile against cryptsoft kmipc SDK, but not the SDK. If you happen to
check out this tree in the scylla folder and configure, it will be linked against and KMIP functionality
will be enabled, otherwise not.
Closesscylladb/scylladb#22233
* github.com:scylladb/scylladb:
docs: Add EAR docs
main/build: Add p11-kit and initialize
tools: Add local-file-key-generator tool
tests: Add EAR tests
tmpdir: shorten test tempdir path
EAR: port the ear feature from enterprise
cql_test_env: Add optional query timeout
schema/migration_manager: Add schema validate
sstables: add get_shared_components accessor
config/config_file: Add exports and definitions of config_type_for<>
This PR extends authentication with 2 mechanisms:
- a new role_manager subclass, which allows managing users via
LDAP server,
- a new authenticator, which delegates plaintext authentication
to a running saslauthd daemon.
The features have been ported from the enterprise repository
with their test.py tests and the documentation as part of
changing license to source available.
Fixes: scylladb/scylla-enterprise#5000Fixes: scylladb/scylla-enterprise#5001Closesscylladb/scylladb#22030
remove the "ScyllaDB Enterprise" labels in document. because
there is no need to differentiate ScyllaDB Enterprise from its OSS
variant, let's stop adding the "ScyllaDB Enterprise" labels to
enterprise-only features. this helps to reduce the confusion.
as we are still in the process of porting the enterprise features
to this repo, this change does not fixscylladb/scylladb#22175.
we will review the document again when completing the migration.
we also take this opportunity to stop referencing "Enterprise" in
the changed paragraph.
Refs scylladb/scylladb#22175
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22177
in 047ce136, we cherry-picked the change adding
garbage-collection-ics.rst to the document. but it was still
referencing the git sha1 and version number in enterprise.
this change updates kb/garbage-collection-ics.rst, so that it
* references the git commit sha1 in this repo
* do not reference the version introducing this feature, as
per Anna Stuchlik
> As a rule, we should avoid documenting when something was
> introduced or set as a default because our documentation
> was versioned. Per-version information should be listed in
> the release notes.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#22195
This change is related to the unification of enterprise and open-source repositories.
The Sphinx configuration is updated to build documentation either for `docs.scylladb.com/manual` or `opensource.docs.scylladb.com`, depending on the flag passed to Sphinx.
By default, it will build docs for `docs.scylladb.com/manual`. If the `opensource` flag is passed, it will build docs for `opensource.docs.scylladb.com`, with a different set of versions.
This change will prepare the configuration to publish to `docs.scylladb.com/manual` while allowing the option to keep publishing and editing docs with a different multiversion configuration.
Note that this change will continue publishing docs to `opensource.docs.scylladb.com` for now since the `opensource` flag is being passed in the `gh-pages.yml` branch.
chore: remove comment
chore: update project name
Closesscylladb/scylladb#22089
ICS is a compaction strategy that inherits size tiered properties --
therefore it's write optimized too -- but fixes its space overhead of
100% due to input files being only released on completion. That's
achieved with the concept of sstable run (similar in concept to LCS
levels) which breaks a large sstable into fixed-size chunks (1G by
default), known as run fragments. ICS picks similar-sized runs
for compaction, and fragments of those runs can be released
incrementally as they're compacted, reducing the space overhead
to about (number_of_input_runs * 1G). This allows user to increase
storage density of nodes (from 50% to ~80%), reducing the cost of
ownership.
NOTE: test_system_schema_version_is_stable adjusted to account for batchlog
using IncrementalCompactionStrategy
contains:
compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh)
compaction/CMakeLists.txt: include ICS cc files
configure.py: changes for ICS files, includes test
db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported
db/system_keyspace: pick ICS for some system tables
schema/schema.hh: ICS becomes default
test/boost: Add incremental_compaction_test.cc
test/boost/sstable_compaction_test.cc: ICS related changes
test/cqlpy/test_compaction_strategy_validation.py: ICS related changes
docs/architecture/compaction/compaction-strategies.rst: changes to ICS section
docs/cql/compaction.rst: changes to ICS section
docs/cql/ddl.rst: adds reference to ICS options
docs/getting-started/system-requirements.rst: updates sentence mentioning ICS
docs/kb/compaction.rst: changes to ICS section
docs/kb/garbage-collection-ics.rst: add file
docs/kb/index.rst: add reference to <garbage-collection-ics>
docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section
some relevant commits throughout the ICS history:
commit 434b97699b39c570d0d849d372bf64f418e5c692
Merge: 105586f747 30250749b8
Author: Paweł Dziepak <pdziepak@scylladb.com>
Date: Tue Mar 12 12:14:23 2019 +0000
Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael
"
Introduce new compaction strategy which is essentially like size tiered
but will work with the existing incremental compaction. Thus incremental
compaction strategy.
It works like size tiered, but each element composing a tier is a sstable
run, meaning that the compaction strategy will look for N similar-sized
sstable runs to compact, not just individual sstables.
Parameters:
* "sstable_size_in_mb": defines the maximum sstable (fragment) size
composing
a sstable run, which impacts directly the disk space requirement which is
improved with incremental compaction.
The lower the value the lower the space requirement for compaction because
fragments involved will be released more frequently.
* all others available in size tiered compaction strategy
HOWTO
=====
To change an existing table to use it, do:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy'};
Set fragment size:
ALTER TABLE mykeyspace.mytable WITH compaction =
{'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 }
"
commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1
Merge: dca89ce7a5 e08ef3e1a3
Author: Avi Kivity <avi@scylladb.com>
Date: Tue Sep 8 11:31:52 2020 +0300
Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael
"
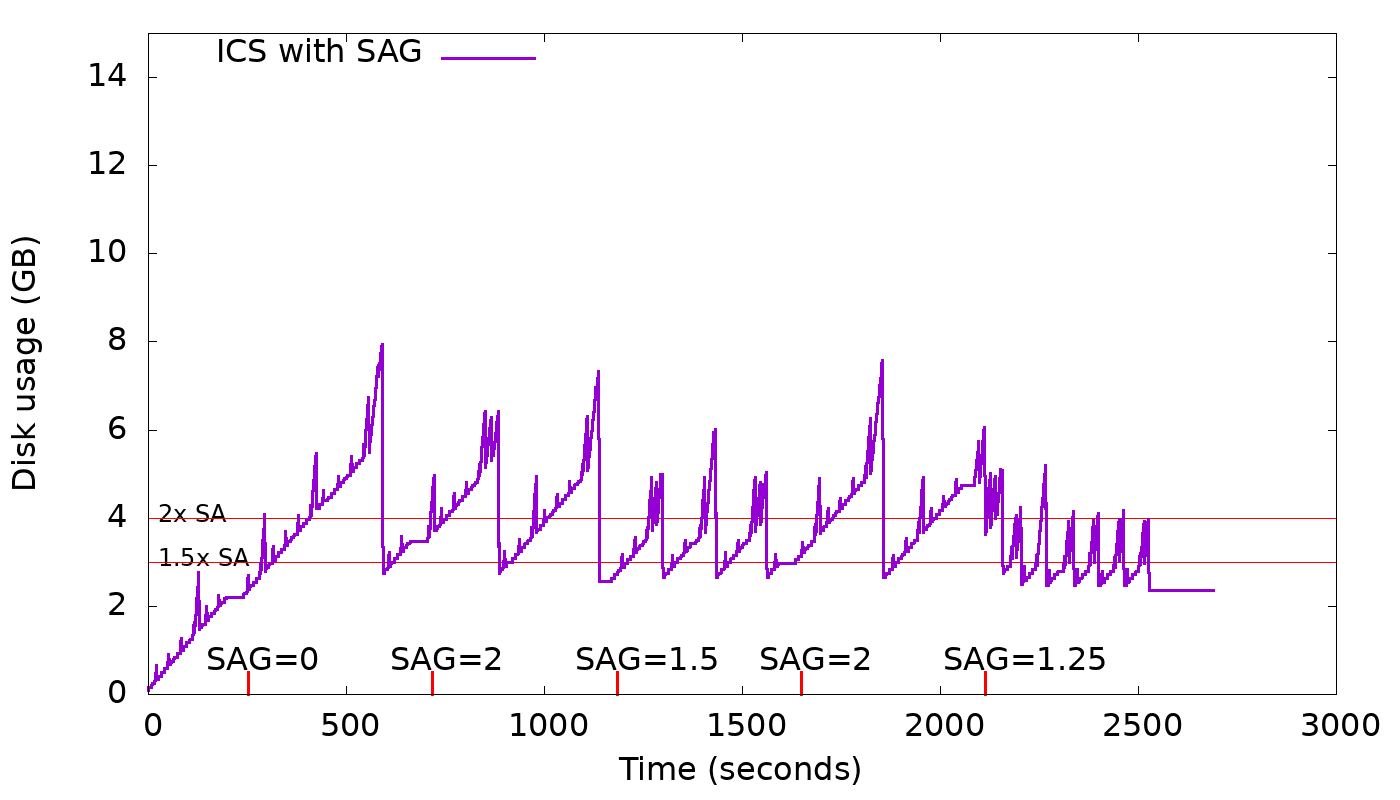
A new option, space_amplification_goal (SAG), is being added to ICS. This option
will allow ICS user to set a goal on the space amplification (SA). It's not
supposed to be an upper bound on the space amplification, but rather, a goal.
This new option will be disabled by default as it doesn't benefit write-only
(no overwrites) workloads and could hurt severely the write performance.
The strategy is free to delay triggering this new behavior, in order to
increase overall compaction efficiency.
The graph below shows how this feature works in practice for different values
of space_amplification_goal:
https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png
When strategy finds space amplification crossed space_amplification_goal, it
will work on reducing the SA by doing a cross-tier compaction on the two
largest tiers. This feature works only on the two largest tiers, because taking
into account others, could hurt the compaction efficiency which is based on
the fact that the more similar-sized sstables are compacted together the higher
the compaction efficiency will be.
With SAG enabled, min_threshold only plays an important role on the smallest
tiers, given that the second-largest tier could be compacted into the largest
tier for a space_amplification_goal value < 2.
By making the options space_amplification_goal and min_threshold independent,
user will be able to tune write amplification and space amplification, based on
the needs. The lower the space_amplification_goal the higher the write
amplification, but by increasing the min threshold, the write amplification
can be decreased to a desired amount.
"
commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1
Author: Raphael S. Carvalho <raphaelsc@scylladb.com>
Date: Sat Oct 16 13:41:46 2021 -0300
compaction: ICS: Add garbage collection
Today, ICS lacks an approach to persist expired tombstones in a timely manner,
which is a problem because accumulation of tombstones are known to affecting
latency considerably.
For an expired tombstone to be purged, it has to reach the top of the LSM tree
and hope that older overlapping data wasn't introduced at the bottom.
The condition are there and must be satisfied to avoid data resurrection.
STCS, today, has an inefficient garbage collection approach because it only
picks a single sstable, which satisfies the tombstone density threshold and
file staleness. That's a problem because overlapping data either on same tier
or smaller tiers will prevent tombstones from being purged. Also, nothing is
done to push the tombstones to the top of the tree, for the conditions to be
eventually satisfied.
Due to incremental compaction, ICS can more easily have an effecient GC by
doing cross-tier compaction of relevant tiers.
The trigger will be file staleness and tombstone density, which threshold
values can be configured by tombstone_compaction_interval and
tombstone_threshold, respectively.
If ICS finds a tier which meets both conditions, then that tier and the
larger[1] *and* closest-in-size[2] tier will be compacted together.
[1]: A larger tier is picked because we want tombstones to eventually reach the
top of the tree.
[2]: It also has to be the closest-in-size tier as the smaller the size
difference the higher the efficiency of the compaction. We want to minimize
write amplification as much as possible.
The staleness condition is there to prevent the same file from being picked
over and over again in a short interval.
With this approach, ICS will be continuously working to purge garbage while
not hurting overall efficiency on a steady state, as same-tier compactions are
prioritized.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com>
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Closesscylladb/scylladb#22063
This series introduces workload prioritization: an extension of the service levels feature which allows specifying "shares" per service level. The number of shares determines the priority of the user which has this service level attached (if multiple are attached then the one with the lowest shares wins).
Different service levels will be isolated in the following way:
- Each service level gets its own scheduling group with the number of shares (corresponding to the service level's number of shares), which controls the priority of the CPU and I/O used for user operations running on that service level.
- Each service level gets two reader concurrency semaphores, one for user reads and the other for read-before-write done for view updates.
- Each service level gets its own TCP connections for RPC to prevent priority inversion issues.
Because of the mandatory use of scheduling groups, which are a globally limited resource, the number of service levels is now limited to 7 user created service levels + 1 created by default that cannot be removed.
This feature has been previously only available in ScyllaDB Enterprise but has been made available for the source available ScyllaDB. The series was created by comparing the master branch with source-available-workbranch / enterprise branch and taking the workload prioritization related parts from the diff, then molding the resulting diff into a proper series. Some very minor changes were made such as fixing whitespace, removing unused or unnecessary code, adding some boilerplate (in api/) which was missing, but otherwise no major changes have been made.
No backport is required.
Closesscylladb/scylladb#22031
* github.com:scylladb/scylladb:
tracing: record scheduling group in trace event record
qos: un-shared-from-this standard_service_level_distributed_data_accessor
alternator: execute under scheduling group for service level
test.py: support multiple commands in prepare_cql in suite.yml
docs: add documentation for workload prioritization
docs/dev: describe workload prioritization features in service_levels
test/auth_cluster: test workload prioritization in service level tests
cqlpy/test_service_levels: add workload prioritization tests
api: introduce service levels specific API
api/cql_server_test: add information about scheduling group
db/virtual_tables: add scheduling group column to system.clients
test/boost: update service_level_controller_test for workload prio
qos: include number of shares in DESCRIBE
cql3/statements: update SL statements for workload prioritization
transport/server: use scheduling group assigned to current user
messaging_service: use separate set of connections per service levels
replica/database: add reader concurrency semaphore groups
qos: manage and assign scheduling groups to service levels
qos: use the shares field in service level reads/writes
qos: add shares to service_level_options
qos: explicitly specify columns when querying service level tables
db/system_distributed_keyspace: add shares column and upgrade code
db/system_keyspace: adjust SL schema for workload prioritization
gms: introduce WORKLOAD_PRIORITIZATION cluster feature
build: increase the max number of scheduling groups
qos: return correct error code when SL does not exist
This adds to the grammar the option to SELECT a specific element in a collection (map/set/list).
For example:
`SELECT map['key'] FROM table`
`SELECT map['key1']['key2'] FROM table`
This feature was implemented in Cassandra 4.0 and was requested by scylla users.
The behavior is mostly compatible with Cassandra, except:
1. in SELECT, we allow list subscript in a selector, while cassandra allows only map and set.
2. in UPDATE, we allow set subscript in a column condition, while cassandra allows only map and list.
3. the slice syntax `SELECT m[a..b]` is not implemented yet
4. null subscript - `SELECT m[null]` returns null in scylla, while cassandra returns error
Fixes#7751
backport was requested for a user to be able to use it
Closesscylladb/scylladb#22051
* github.com:scylladb/scylladb:
cql3: allow SELECT of specific collection key
cql3: allow set subscript
This is a forward port (from scylla-enterprise) of additional compression options (zstd, dictionaries shared across messages) for inter-node network traffic. It works as follows:
After the patch, messaging_service (Scylla's interface for all inter-node communication)
compresses its network traffic with compressors managed by
the new advanced_rpc_compression::tracker. Those compressors compress with lz4,
but can also be configured to use zstd as long as a CPU usage limit isn't crossed.
A precomputed compression dictionary can be fed to the tracker. Each connection
handled by the tracker will then start a negotiation with the other end to switch
to this dictionary, and when it succeeds, the connection will start being compressed using that dictionary.
All traffic going through the tracker is passed as a single merged "stream" through dict_sampler.
dictionary_service has access to the dict_sampler.
On chosen nodes (in the "usual" configuration: the Raft leader), it uses the sampler to maintain
a random multi-megabyte sample of the sampler's stream. Every several minutes,
it copies the sample, trains a compression dictionary on it (by calling zstd's
training library via the alien_worker thread) and publishes the new dictionary
to system.dicts via Raft's write_mutation command.
This update triggers (eventually) a callback on all nodes, which feeds the new dictionary
to advanced_rpc_compression::tracker, and this switches (eventually) all inter-node connections
to this dictionary.
Closesscylladb/scylladb#22032
* github.com:scylladb/scylladb:
messaging_service: use advanced_rpc_compression::tracker for compression
message/dictionary_service: introduce dictionary_service
service: make Raft group 0 aware of system.dicts
db/system_keyspace: add system.dicts
utils: add advanced_rpc_compressor
utils: add dict_trainer
utils: introduce reservoir_sampling
utils: introduce alien_worker
utils: add stream_compressor
This adds to the grammar the option to SELECT a specific key in a
collection column using subscript syntax.
For example:
SELECT map['key'] FROM table
SELECT map['key1']['key2'] FROM table
The key can also be parameterized in a prepared query. For this we need
to pass the query options to result_set_builder where we process the
selectors.
Fixesscylladb/scylladb#7751
This patch sets up an `alien_worker`, `advanced_rpc_compression::tracker`,
`dict_sampler` and `dictionary_service` in `main()`, and wires them to each other
and to `messaging_service`.
`messaging_service` compresses its network traffic with compressors managed by
the `advanced_rpc_compression::tracker`. All this traffic is passed as a single
merged "stream" through `dict_sampler`.
`dictionary_service` has access to `dict_sampler`.
On chosen nodes (by default: the Raft leader), it uses the sampler to maintain
a random multi-megabyte sample of the sampler's stream. Every several minutes,
it copies the sample, trains a compression dictionary on it (by calling zstd's
training library via the `alien_worker` thread) and publishes the new dictionary
to `system.dicts` via Raft.
This update triggers a callback into `advanced_rpc_compression::tracker` on all nodes,
which updates the dictionary used by the compressors it manages.
Adds glue needed to pass lz4 and zstd with streaming and/or dictionaries
as the network traffic compressors for Seastar's RPC servers.
The main jobs of this glue are:
1. Implementing the API expected by Seastar from RPC compressors.
2. Expose metrics about the effectiveness of the compression.
3. Allow dynamically switching algorithms and dictionaries on a running
connection, without any extra waits.
The biggest design decision here is that the choice of algorithm and dictionary
is negotiated by both sides of the connection, not dictated unilaterally by the
sender.
The negotiation algorithm is fairly complicated (a TLA+ model validating
it is included in the commit). Unilateral compression choice would be much simpler.
However, negotiation avoids re-sending the same dictionary over every
connection in the cluster after dictionary updates (with one-way communication,
it's the only reliable way to ensure that our receiver possesses the dictionary
we are about to start using), lets receivers ask for a cheaper compression mode
if they want, and lets them refuse to update a dictionary if they don't think
they have enough free memory for that.
In hindsight, those properties probably weren't worth the extra complexity and
extra development effort.
Zstd can be quite expensive, so this patch also includes a mechanism which
temporarily downgrades the compressor from zstd to lz4 if zstd has been
using too much CPU in a given slice of time. But it should be noted that
this can't be treated as a reliable "protection" from negative performance
effects of zstd, since a downgrade can happen on the sender side,
and receivers are at the mercy of senders.
There are two of those -- the POST /storage_service/keyspace that loads
and streams new sstables from /upload and POST /storage_service/restore
that does the same, but gets sstables from object store.
The new optional parameter allow users to tun the streaming phase
behavior. The test/pylib client part is also updated here.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Where the grammar supports IN, we add NOT IN. This includes the WHERE
clause and LWT IF clause.
Evaluation of NOT IN follows from IN.
In statement_restrictions analysis, they are different, as NOT IN
doesn't enable any clever query plan and must filter.
Some tests are added. An error message was changed ('in' changed to 'IN'),
so some tests are adjusted.
Closesscylladb/scylladb#21992
As part of #18750, we added a CQL statement CREATE ROLE WITH SALTED HASH
that prevented hashing a password when creating a role, effectively leading
to inserting a hash given by the user directly into the database. In #21350,
we noticed that Cassandra had implemented a CQL statement of similar semantics
but different syntax. We decided to rename Scylla's statement to be compatible
with Cassandra. Unfortunately, we didn't notice one more difference between
what we had in Scylla and what was part of Cassandra.
Scylla's statement was originally supposed to only be used when restoring
the schema and the user needn't have to be aware of its existence at all:
the database produced a sequence of CQL statements that the user saved to
a file and when a need to restore the schema arose, they would execute
the contents of the file. That's why that although we documented the feature,
it was only done in the necessary places. Those that weren't related to
the backup & restore procedure were deliberately skipped.
Cassandra, on the other hand, added the statement for a different purpose
(for details, see the relevant issue) and it was supposed to be used by
the user by design. The statement is also documented as such.
Since we want to preserve compatibility with Cassandra, we document
the statement and its semantics in the user documentation, explicitly
implying that it can be used by the user.
Fixesscylladb/scylladb#21691
They exist in the original documentation, but are not yet implemented.
Now it's possible to do it.
It slightly more complex that its compaction counterpart in a sense than
get method reports megabits/s by default and has an option to convert to
MiBs.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
This commit removes the information about the recommended way of upgrading
ScyllaDB images - by updating ScyllaDB and OS packages in one step. This upgrade
procedure is not supported (it was implemented, but then reverted).
Refs https://github.com/scylladb/scylladb/issues/15733Closesscylladb/scylladb#21876
Currently truncating a table works by issuing an RPC to all the nodes which call `database::truncate_table_on_all_shards()`, which makes sure that older writes are dropped.
It works with tablets, but is not safe. A concurrent replication process may bring back old data.
This change makes makes TRUNCATE TABLE a topology operation, so that it excludes with other processes in the system which could interfere with it. More specifically, it makes TRUNCATE a global topology request.
Backporting is not needed.
Fixes#16411Closesscylladb/scylladb#19789
* github.com:scylladb/scylladb:
docs: docs: topology-over-raft: Document truncate_table request
storage_proxy: fix indentation and remove empty catch/rethrow
test: add tests for truncate with tablets
storage_proxy: use new TRUNCATE for tablets
truncate: make TRUNCATE a global topology operation
storage_service: move logic of wait_for_topology_request_completion()
RPC: add truncate_with_tablets RPC with frozen_topology_guard
feature_service: added cluster feature for system.topology schema change
system.topology_requests: change schema
storage_proxy: propagate group0 client and TSM dependency
The goal of merge is to reduce the tablet count for a shrinking table. Similar to how split increases the count while the table is growing. The load balancer decision to merge is implemented today (came with infrastructure introduced for split), but it wasn't handled until now.
Initial tablet count is respected while the table is in "growing mode". For example, the table leaves it if there was a need to split above the initial tablet count. After the table leaves the mode, the average size can be trusted to determine that the table is shrinking. Merge decision is emitted if the average tablet size is 50% of the target. Hysteresis is applied to avoid oscillations between split and merges.
Similar to split, the decision to merge is recorded in tablet map's resize_type field with the string "merge". This is important in case of coordinator failover, so new coordinator continues from where the old left off.
Unlike split, the preparation phase during merge is not done by the replica (with split compactions), but rather by the coordinator by co-locating sibling tablets in the same node's shard. We can define sibling tablets as tablets that have contiguous range and will become one after merge. The concept is based on the power-of-two constraint and token contiguity. For example, in a table with 4 tablets, tablets of ids 0 and 1 are siblings, 2 and 3 are also siblings.
The algorithm for co-locating sibling tablets is very simple. The balancer is responsible for it, and it will emit migrations so that "odd" tablet will follow the "even" one. For example, tablet 1 will be migrated to where tablet 0 lives. Co-location is low in priority, it's not the end of the world to delay merge, but it's not ideal to delay e.g. decommission or even regular load balancing as that can translate into temporary unbalancing, impacting the user activities. So co-location migrations will happen when there is no more important work to do.
While regular balancing is higher in priority, it will not undo the co-location work done so far. It does that by treating co-located tablets as if they were already merged. The load inversion convergence check was adjusted so balancer understand when two tablets are being migrated instead of one, to avoid oscillations.
When balancer completes co-location work for a table undergoing merge, it will put the id of the table into the resize_plan, which is about communicating with the topology coordinator that a table is ready for it. With all sibling tablets co-located, the coordinator can resize the tablet map (reduce it by a factor of 2) and record the new map into group0. All the replicas will react to it (on token metadata update) by merging the storage (memtable(s) + sstables) of sibling tablets into one.
Fixes#18181.
system test details:
test: https://github.com/pehala/scylla-cluster-tests/blob/tablets_split_merge/tablets_split_merge_test.py
yaml file: https://github.com/pehala/scylla-cluster-tests/blob/tablets_split_merge/test-cases/features/tablets/tablets-split-merge-test.yaml
instance type: i3.8xlarge
nodes: 3
target tablet size: 0.5G (scaled down by 10, to make it easier to trigger splits and merges)
description: multiple cycles of growing and shrinking the data set in order to trigger splits and merges.
data_set_size: ~100G
initial_tablets: 64, so it grew to 128 tablets on split, and back to 64 on merge.
latency of reads and writes that happened in parallel to split and merge:
```
$ for i in scylla-bench*; do cat $i | grep "Mode\|99th:\|99\.9th:"; done
Mode: write
99.9th: 3.145727ms
99th: 1.998847ms
99.9th: 3.145727ms
99th: 2.031615ms
Mode: read
99.9th: 3.145727ms
99th: 2.031615ms
99.9th: 3.145727ms
99th: 2.031615ms
Mode: write
99.9th: 3.047423ms
99th: 1.933311ms
99.9th: 3.047423ms
99th: 1.933311ms
Mode: read
99.9th: 3.145727ms
99th: 1.900543ms
99.9th: 3.145727ms
99th: 1.900543ms
Mode: write
99.9th: 5.079039ms
99th: 3.604479ms
99.9th: 35.389439ms
99th: 25.624575ms
Mode: write
99.9th: 3.047423ms
99th: 1.998847ms
99.9th: 3.047423ms
99th: 1.998847ms
Mode: read
99.9th: 3.080191ms
99th: 2.031615ms
99.9th: 3.112959ms
99th: 2.031615ms
```
Closesscylladb/scylladb#20572
* github.com:scylladb/scylladb:
docs: Document tablet merging
tests/boost: Add test to verify correctness of balancer decisions during merge
tests/topology_experimental_raft: Add tablet merge test
service: Handle exception when retrying split
service: Co-locate sibling tablets for a table undergoing merge
gms: Add cluster feature for tablet merge
service: Make merge of resize plan commutative
replica: Implement merging of compaction groups on merge completion
replica: Handle tablet merge completion
service: Implement tablet map resize for merge
locator: Introduce merge_tablet_info()
service: Rename topology::transition_state::tablet_split_finalization
service: Respect initial_tablet_count if table is in growing mode
service: Wire migration_tablet_set into the load balancer
locator: Add tablet_map::sibling_tablets()
service: Introduce sorted_replicas_for_tablet_load()
locator/tablets: Extend tablet_replica equality comparator to three-way
service: Introduce alias to per-table candidate map type
service: Add replication constraint check variant for migration_tablet_set
service: Add convergence check variant for migration_tablet_set
service: Add migration helpers for migration_tablet_set
service/tablet_allocator: Introduce migration_tablet_set
service: Introduce migration_plan::add(migrations_vector)
locator/tablets: Introduce tablet_map::for_each_sibling_tablets()
locator/tablets: Introduce tablet_map::needs_merge()
locator/tablets: Introduce resize_decision::initial_decision()
locator/tablets: Fix return type of three-way comparison operators
service: Extract update of node load on migrations
service: Extract converge check for intra-node migration
service: Extract erase of tablet replicas from candidate list
scripts/tablet-mon: Allow visualization of tablet id
Although `crc_check_chance` is accepted as a configuration option in ScyllaDB,
the value is currently ignored during runtime. This change makes this behavior
explicit in the documentation to prevent potential user misunderstandings.
Changes:
- Explicitly document that the option is currently a no-op
- Provide clear guidance on the current implementation
- Prevent confusion about the option's actual functionality
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21794
Small adjustments and improvements to the documentation in the raft
section.
Fixing Markdown lint warnings:
- MD004/ul-style: Unordered list style [Expected: dash; Actual: asterisk]
- MD007/ul-indent: Unordered list indentation [Expected: 0; Actual: 2]
- MD032/blanks-around-lists: Lists should be surrounded by blank lines
- MD036/no-emphasis-as-heading: Emphasis used instead of a heading
- MD046/code-block-style: Code block style [Expected: fenced; Actual: indented]
Closesscylladb/scylladb#21780
With commits ed7d352e7d and bb1867c7c7, we now have input streams for both compressed and uncompressed SSTables that provide seamless checksum and digest checking. The code for these was based on `validate_checksums()`, which implements its own validation logic over raw streams. This has led to some duplicate code.
This PR deduplicates the uncompressed case by modifying `validate_checksums()` to use a checksummed input stream instead of a raw stream. The same cannot be done for compressed SSTables though. The reason is that `validate_checksums()` needs to examine the whole data file, even if an invalid chunk is encountered. In the checksummed case we support that by offloading the error handling logic from the data source via a function parameter. In the compressed data source we cannot do that because it needs to return decompressed data and decompression may fail if the data are invalid.
This PR also enables `validate_checksums()` to partially verify SSTables with just the per-chunk checksums if the digest is missing.
In more detail, this PR consists of:
* Port of some integrity checks from `do_validate_uncompressed()` to the checksummed data source. It should now be able to detect corruption due to truncated or appended chunks (expected number of chunks is retrieved from the CRC component).
* Introduction of `error_handler` parameter in checksummed data source and `data_stream()`.
* Refactoring of `validate_checksums()`. The JSON response of `sstable validate-checksums` was also modified to report a missing digest.
* Tests for `validate_checksums()` against SSTables with truncated data, appended data, invalid digests, or no digest.
Refs #19058.
This PR is a hybrid of cleanup and feature. No backport is needed.
Closesscylladb/scylladb#20933
* github.com:scylladb/scylladb:
tools/scylla-sstable: Rename valid_checksums -> valid
test: Check validate_checksums() with missing digest
sstables: Allow validate_checksums() to report missing digests
sstables: Refactor validate_checksums() to use checksummed data stream
sstables: Add error_handler parameter to data_stream()
sstables: Add error handler in checksummed data source
sstables: Check for excessive chunks in checksummed data source
sstables: Check for premature EOF in checksummed data source
test: test_validate_checksums: Check SSTable with invalid digest
test: test_validate_checksums: Check SSTable with appended data
test: test_validate_checksums: Complement test for truncated SSTable
This transition state will be reused by merge completion, so let's
rename it to tablet_resize_finalization.
The completion handling path will also be reused, so let's rename
functions involved similarly.
The old name "tablet split finalization" is deprecated but still
recognized and points to the correct transition. Otherwise, the
reverse lookup would fail when populating topology system table
which last state was split finalization.
NOTE:
I thought of adding a new tablet_merge_finalization, but it would
complicate things since more than one table could be ready for
either split or merge, so you need a generic transition state
for handling resize completion.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Task status information from nodetool commands is not retained permanently:
- Status of completed tasks is only kept for `task_ttl_in_seconds`
- Status is removed after being queried, making it a one-time operation
This behavior is important for users to understand since subsequent
queries for the same completed task will not return any information.
Add documentation to make this clear to users.
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21386
Demote --scylla-data-dir and --scylla-yaml-file to schema source
helpers, rather than schema source in themselves. This practically means
that when these options are used, they won't define where the tool will
attempt to load the schema from, they will just be helpers to help locate
the schema, for whichever schema source the tool was instructed to use
(or left to choose).
--scylla-data-dir and --scylla-yaml-file being schema sources were
problematic with encryption at rest and for S3 support (not yet
implemented). With encryption, the tool needs access to the
configuration, so --scylla-yaml-file is often used to provide the path
to the configuration file, which contains encryption configuration,
needed for the tool to decrypt the sstable. Currently, using this option
implies forcing the tool to read the schema from the schema tables,
which is a problematic option for tests -- Scylla might be compacting a
schema sstable and this will make the tool fail to load the schema.
Demoting these options the schema helpers, allows providing them, while
at the same time having the option to use a different schema-source.
To allow the user to force the tool to load the schema from the schema
tables, a new --schema-tables option is added. Similarly, a
--sstable-schema option is introduced to force the tool to load the
schema from the sstable itself.
With this, each 4 schema source now has an option to force the use of
said schema source. There are various helper options to be used along
with these.
The documentation as well as the tests are updated with the changes.
The schema related documentation gets an rather extensive facelift
because it was a bit out-of-date and incomplete.
Fixes: scylladb/scylladb#20534Closesscylladb/scylladb#21678
Update the tablestats documentation to correctly describe the "Number of
partitions" metric. The previous documentation incorrectly referred to
"estimated row count" when the command actually shows estimated partition count.
Before:
```
Number of keys (estimate) | The estimated row count
```
After:
```
Number of partitions (estimate) | The estimated partition count
```
This distinction is important since a partition (identified by its partition
key) can contain multiple rows in ScyllaDB. The updated format also matches
Cassandra's nodetool output for better compatibility.
Fixesscylladb/scylladb#21586
Signed-off-by: Kefu Chai <kefu.chai@scylladb.com>
Closesscylladb/scylladb#21598
When users start an operation asynchronously with API, they are expected to check the operation's status. Hence, the status should be kept in task manager for reasonable time after the operation is done. The operations that are started internally usually don't need to stay in task manager for that long.
Add api_task_ttl that will be used for tasks started with API. By default it's 1 hour. The time for which non-API tasks stay in task manager isn't changed.
Fixes: #21499.
Refs: #21425.
No backport needed - previous versions may use task_ttl
Closesscylladb/scylladb#21505
* github.com:scylladb/scylladb:
test: add test to check user_task_ttl
tasks: api: move make_task method
docs: nodetool: update backup and restore commands docs
docs: update task manager docs
nodetool: add nodetool tasks user-ttl command
node_ops: use user task ttl for node ops virtual task
tasks: use user_task_ttl for tasks started by user
api: task_manager: add /task_manager/user_ttl to get and set user task ttl
tasks: add task_manager::task::is_user_task method
tasks: keep updateable_value of task_ttl in task manager
db: config: add user_task_ttl_seconds named value
Java tools are deprecated and slated for removal in the next ScyllaDB release.
Update the admin-tools docs and make sure all java tool documentation pages have a notice reflecting this fact.
Fixes: https://github.com/scylladb/scylladb/issues/21149
Should be backported to 6.2, so users of the latest stable version can see the notice.
Closesscylladb/scylladb#21522
* github.com:scylladb/scylladb:
docs: sstableloader.rst: add deprecation notice
docs: admin-tools: update deprecation notice for sstable{dump,metadata}
docs: tools_index.rst: remove deprecated sstablereset and sstablerepairedset tools
Stop taking snapshots of MVs and allow taking snapshot of individual tables, now one can take a snapshot of any base table, any view or index. Also add tests to cover new cases both boost test (using cc code) and pytest (using the API)
Also, update documentation to reflect the change
fixes: #21339fixes: #20760Closesscylladb/scylladb#21433
{kind=link}