Add a struct called subscript, which will be used in expression
variant to represent subscripted values e.g col[x], val[sub].
It will replace the sub field of column_value.
Having a separate struct in AST for this purpose
is cleaner and allows to express subscripting
values other than column_value.
It is not added to the expression variant yet, because
that would require immediately implementing all visitors.
The following commits will implement individual visitors
and then subscript will finally be added to expression.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
We add a `peers()` method to `discovery` which returns the peers
discovered until now (including seeds). The caller of functions which
return an output -- `tick` or `request` -- is responsible for persisting
`peers()` before returning the output of `tick`/`request` (e.g. before
sending the response produced by `request` back). The user of
`discovery` is also responsible for restoring previously persisted peers
when constructing `discovery` again after a restart (e.g. if we
previously crashed in the middle of the algorithm).
The `persistent_discovery` class is a wrapper around `discovery` which
does exactly that.
For storage we use a simple local table.
A simple bugfix is also included in the first patch.
* kbr/discovery-persist-v3:
service: raft: raft_group0: persist discovered peers and restore on restart
db: system_keyspace: introduce discovery table
service: raft: discovery: rename `get_output` to `tick`
service: raft: discovery: stop returning peer_list from `request` after becoming leader
cached_page::on_evicted() is invoked in the LSA allocator context, set in the
reclaimer callback installed by the cache_tracker. However,
cached_pages are allocated in the standard allocator context (note:
page content is allocated inside LSA via lsa_buffer). The LSA region
will happily deallocate these, thinking that they these are large
objects which were delegated to the standard allocator. But the
_non_lsa_memory_in_use metric will underflow. When it underflows
enough, shard_segment_pool.total_memory() will become 0 and memory
reclamation will stop doing anything, leading to apparent OOM.
The fix is to switch to the standard allocator context inside
cached_page::on_evicted(). evict_range() was also given the same
treatment as a precaution, it currently is only invoked in the
standard allocator context.
The series also adds two safety checks to LSA to catch such problems earlier.
Fixes#10056
\cc @slivne @bhalevy
Closes#10130
* github.com:scylladb/scylla:
lsa: Abort when trying to free a standard allocator object not allocated through the region
lsa: Abort when _non_lsa_memory_in_use goes negative
tests: utils: cached_file: Validate occupancy after eviction
test: sstable_partition_index_cache_test: Fix alloc-dealloc mismatch
utils: cached_file: Fix alloc-dealloc mismatch during eviction
"
Problem statement
=================
Today, compaction can act much more aggressive than it really has to, because
the strategy and its definition of backlog are completely decoupled.
The backlog definition for size-tiered, which is inherited by all
strategies (e.g.: LCS L0, TWCS' windows), is built on the assumption that the
world must reach the state of zero amplification. But that's unrealistic and
goes against the intent amplification defined by the compaction strategy.
For example, size tiered is a write oriented strategy which allows for extra
space amplification for compaction to keep up with the high write rate.
It can be seen today, in many deployments, that compaction shares is either
close to 1000, or even stuck at 1000, even though there's nothing to be done,
i.e. the compaction strategy is completely satisfied.
When there's a single sstable per tier, for example.
This means that whenever a new compaction job kicks in, it will act much more
aggressive because of the high shares, caused by false backlog of the existing
tables. This translates into higher P99 latencies and reduced throughput.
Solution
========
This problem can be fixed, as proposed in the document "Fixing compaction
aggressiveness due to suboptimal definition of zero backlog by controller" [1],
by removing backlog of tiers that don't have to be compacted now, like a tier
that has a single file. That's about coupling the strategy goal with the
backlog definition. So once strategy becomes satisfied, so will the controller.
Low-efficiency compaction, like compacting 2 files only or cross-tier, only
happens when system is under little load and can proceed at a slower pace.
Once efficient jobs show up, ongoing compactions, even if inefficient, will get
more shares (as efficient jobs add to the backlog) so compaction won't fall
behind.
With this approach, throughput and latency is improved as cpu time is no longer
stolen (unnecessarily) from the foreground requests.
[1]: https://docs.google.com/document/d/1EQnXXGWg6z7VAwI4u8AaUX1vFduClaf6WOMt2wem5oQ
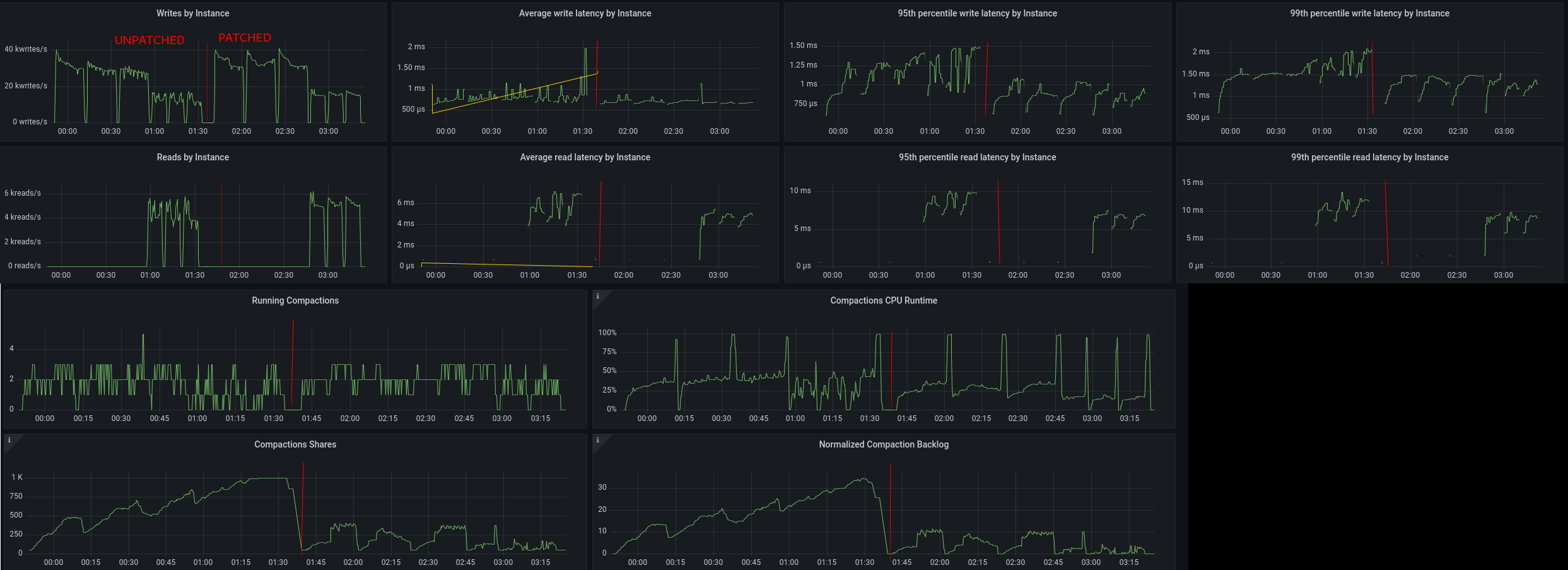
Results
=======
Test sequentially populates 3 tables and then run a mixed workload on them,
where disk:memory ratio (usage) reaches ~30:1 at the peak.
Please find graphs here:
https://user-images.githubusercontent.com/1409139/153687219-32368a35-ac63-461b-a362-64dbe8449a00.png
1) Patched version started at ~01:30
2) On population phase, throughput increase and lower P99 write latency can be
clearly observed.
3) On mixed phase, throughput increase and lower P99 write and read latency can
also be clearly observed.
4) Compaction CPU time sometimes reach ~100% because of the delay between each
loader.
5) On unpatched version, it can be seen that backlog keeps growing even when
though strategies become satisfied, so compaction is using much more CPU time
in comparison. Patched version correctly clears the backlog.
Can also be found at:
github.com/raphaelsc/scylla.git compaction-controller-v5
tests: UNIT(dev, debug).
"
* 'compaction-controller-v5' of https://github.com/raphaelsc/scylla:
tests: Add compaction controller test
test/lib/sstable_utils: Set bytes_on_disk for fake SSTables
compaction/size_tiered_backlog_tracker.hh: Use unsigned type for inflight component
compaction: Redefine compaction backlog to tame compaction aggressiveness
compaction_backlog_tracker: Batch changes through a new replacement interface
table: Disable backlog tracker when stopping table
compaction_backlog_tracker: make disable() public
compaction_backlog_tracker: Clear tracker state when disabled
compaction: Add normalized backlog metric
compaction: make size_tiered_compaction_strategy static
tri_compare_opt can avoid casting bool to int for spaceshipping
int - int <=> 0 looks nicer and shorter as int <=> int
data_type::compare from serialized_tri_compare already returns strong_ordering
tests: unit(dev)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20220224125556.13138-1-xemul@scylladb.com>
This patch adds metrics to the Alternator TTL feature (aka the "expiration
service").
I put these metrics deliberately in their own object in ttl.{hh,cc}, and
also with their own prefix ("expiration_*") - and *not* together with the
rest of the Alternator metrics (alternator/stats.{hh,cc}). This is
because later we may want to use the expiration service not only in
Alternator but also in CQL - to support per-item expiration with CDC
events also in CQL. So the implementation of this feature should not be
too tangled with that of Alternator.
The patch currently adds four metrics, and opens the path to easily add
more in the future. The metrics added now are:
1. scylla_expiration_scan_passes: The number of scan passes over the
entire table. We expect this to grow by 1 every
alternator_ttl_period_in_seconds seconds.
2. scylla_expiration_scan_table: The number of table scans. In each scan
pass, we scan all the tables that have the Alternator TTL feature
enabled. Each scan of each table is counted by this counter.
3. scylla_expiration_items_deleted: Counts the number of items that
the expiration service expired (deleted). Please remember that
each item is considered for expiration - and then expired - on
only one node, so each expired item is counted only once - not
RF times.
4. scylla_expiration_secondary_ranges_scanned: If this counter is
incremented, it means this node took over some other node's
expiration scanning duties while the other node was down.
This patch also includes a couple of unrelated comment fixes.
I tested the new metrics manually - they aren't yet tested by the
Alternator test suite because I couldn't make up my mind if such
tests would belong in test_ttl.py or test_metrics.py :-)
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20220224092419.1132655-1-nyh@scylladb.com>
The flush of hints and batchlog are needed only for the table with
tombstone_gc_mode set to repair mode. We should skip the flush if the
tombstone_gc_mode is not repair mode.
Fixes#10004Closes#10124
This patch adds a reproducing test for issue #10081. That issue is about
a conditional (LWT) UPDATE operation that chose a non-existent row via WHERE,
and its condition refers to both static and regular columns: In that case,
the code incorrectly assumes that because it didn't read any row, all columns
are null - and forgets that the static column is *not* null.
The test, test_lwt.py::test_lwt_missing_row_with_static
passes on Cassandra but fails on Scylla, so is marked xfail.
Refs #10081
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20220215215243.660087-1-nyh@scylladb.com>
The background scan for expired Alternator items (the TTL feature)
should bypass the cache to avoid poluting it with the entire content
of the table being scanned.
I tested that the flag added in this patch really works by adding a printout
to the code in table.cc which creates the reader. Although we do have a
metric for uses of BYPASS CACHE, unfortunately this metric counts usage
of "BYPASS CACHE" in CQL statements - and not does not account the low-
level calls that we use in the ttl scanner.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
The document docs/alternator/compatibility.md suggested that Alternator
does not support the TTL feature at all. The real situation is more
optimistic - this feature is supported, but as experimental feature.
So let's update compatibility.md with the real status of this feature.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Before this patch, the experimental TTL (expiration time) feature in
Alternator scans tables for expiration in a tight loop - starting the
next scan one second after the previous one completed.
In this patch we introduce a new configuration option,
alternator_ttl_period_in_seconds, which determines how frequently
to start the scan. The default is 24 hours - meaning that the next
scan is started 24 hours after the previous one started.
The tests (test/alternator/run) change this configuration back to one
second, so that expiration tests finish as quickly as possible.
Please note that the scan is *not* slowed down to fill this 24 hours -
if it finishes in one hour, it will then sleep for 23 hours. Additional
work would be needed to slow down the scan to not finish too quickly.
One idea not yet implemented is to move the expiration service from
the "maintenance" scheduling group which it uses today to a new
scheduling group, and modifying the number of shares that this group
gets.
Another thing worth noting about the configurable period (which defaults
to 24 hours) is that when TTL is enabled on an Alternator table, it can
take that amount of time until its scan starts and items start expiring
from it.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
allocated through the region
It indicates alloc-dealloc mismatch, and can cause other problems in
the systems like unable to reclaim memory. We want to catch this at
the deallocation site to be able to quickly indentify the offender.
Misbehavior of this sort can cause fake OOMs due to underflow of
_non_lsa_memory_in_use. When it underflows enough,
shard_segment_pool.total_memory() will become 0 and memory reclamation
will stop doing anything.
Refs #10056
There's no automated test for controller, it's time to have one.
Let's start with a basic one that verifies the assumption that
perfectly compacted tiers should produce 0 backlog.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Not precise, as bytes_on_disk accounts for all components, but good enough
for testing purposes.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Today, compaction can act much more aggressive than it really has to, because
the strategy and its definition of backlog are completely decoupled.
The backlog definition for size-tiered, which is inherited by all
strategies (e.g.: LCS L0, TWCS' windows), is built on the assumption that the
world must reach the state of zero amplification. But that's unrealistic and
goes against the intent amplification defined by the compaction strategy.
For example, size tiered is a write oriented strategy which allows for extra
space amplification for compaction to keep up with the high write rate.
It can be seen today, in many deployments, that compaction shares is either
close to 1000, or even stuck at 1000, even though there's nothing to be done,
i.e. the compaction strategy is completely satisfied.
When there's a single sstable per tier, for example.
This means that whenever a new compaction job kicks in, it will act much more
aggressive because of the high shares, caused by false backlog of the existing
tables. This translates into higher P99 latencies and reduced throughput.
Solution
========
This problem can be fixed, as proposed in the document "Fixing compaction
aggressiveness due to suboptimal definition of zero backlog by controller" [1],
by removing backlog of tiers that don't have to be compacted now, like a tier
that has a single file. That's about coupling the strategy goal with the
backlog definition. So once strategy becomes satisfied, so will the controller.
Low-efficiency compaction, like compacting 2 files only or cross-tier, only
happens when system is under little load and can proceed at a slower pace.
Once efficient jobs show up, ongoing compactions, even if inefficient, will get
more shares (as efficient jobs add to the backlog) so compaction won't fall
behind.
With this approach, throughput and latency is improved as cpu time is no longer
stolen (unnecessarily) from the foreground requests.
[1]: https://docs.google.com/document/d/1EQnXXGWg6z7VAwI4u8AaUX1vFduClaf6WOMt2wem5oQFixes#4588.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
This new interface allows table to communicate multiple changes in the
SSTable set with a single call, which is useful on compaction completion
for example.
With this new interface, the size tiered backlog tracker will be able to
know when compaction completed, which will allow it to recompute tiers
and their backlog contribution, if any. Without it, tiered tracker
would have to recompute tiers for every change, which would be terribly
expensive.
The old remove/add interface are being removed in favor of the new one.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Backlog tracker is managed by compaction strategy, and we'd like to
have it disabled in table::stop(), to make sure that all state is
cleared. For example, a reference to a shared sstable, in the
tracker implementation, could prevent the sstable manager from being
stopped as it relies on all sstables managed by it being closed
first. By calling tracker's disable() method, table::stop() will
guarantee that state is cleared by completion.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
If the tracker is disabled, we never get to access the underlying
implementation anymore. It makes sense to clear _impl on
disable(). So table::stop() can call its backlog tracker's disable
method, clearing all its state. This is important for clean
shutdown, as any sstable in tracker state may cause sstable
manager to hang when being stopped.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Normalized backlog metric is important for understanding the controller
behavior as the controller acts on normalized backlog for yielding an
output, not the raw backlog value in bytes.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
on_evicted() is invoked in the LSA allocator context, set in the
reclaimer callback instaled by the cache_tracker. However,
cached_pages are allocated in the standard allocator context (note:
page content is allocated inside LSA via lsa_buffer). The LSA region
will happilly deallocate these, thinking that they these are large
objects which were delegated to the standard allocator. But the
_non_lsa_memory_in_use metric will underflow. When it underflows
enough, shard_segment_pool.total_memory() will become 0 and memory
reclamation will stop doing anything, leading to apparent OOM.
The fix is to switch to the standard allocator context inside
cached_page::on_evicted(). evict_range() was also given the same
treatment as a precaution, it currently is only invoked in the
standard allocator context.
Fixes#10056
More and more places are using the repair[uuid]: format for logging
repair jobs with the uuid. Convert more places to use the new format to
unify the log format.
This makes it easier to grep a specific repair job in the log.
Closes#10125
Memtables are a replica-side entity, and so are moved to the
replica module and namespace.
Memtables are also used outside the replica, in two places:
- in some virtual tables; this is also in some way inside the replica,
(virtual readers are installed at the replica level, not the
cooordinator), so I don't consider it a layering violation
- in many sstable unit tests, as a convenient way to create sstables
with known input. This is a layering violation.
We could make memtables their own module, but I think this is wrong.
Memtables are deeply tied into replica memory management, and trying
to make them a low-level primitive (at a lower level than sstables) will
be difficult. Not least because memtables use sstables. Instead, we
should have a memtable-like thing that doesn't support merging and
doesn't have all other funky memtable stuff, and instead replace
the uses of memtables in sstable tests with some kind of
make_flat_mutation_reader_from_unsorted_mutations() that does
the sorting that is the reason for the use of memtables in tests (and
live with the layering violation meanwhile).
Test: unit (dev)
Closes#10120
This PR propagates the read coordinator logic so that read timeout and read failure exceptions are propagated without throwing on the coordinator side.
This PR is only concerned with exceptions which were originally thrown by the coordinator (in read resolvers). Exceptions propagated through RPC and RPC timeouts will still throw, although those exceptions will be caught and converted into exceptions-as-values by read resolvers.
This is a continuation of work started in #10014.
Results of `perf_simple_query --smp 1 --operations-per-shard 1000000` (read workload), compared with merge base (10880fb0a7):
```
BEFORE:
125085.13 tps ( 80.2 allocs/op, 12.2 tasks/op, 49010 insns/op)
125645.88 tps ( 80.2 allocs/op, 12.2 tasks/op, 49008 insns/op)
126148.85 tps ( 80.2 allocs/op, 12.2 tasks/op, 49005 insns/op)
126044.40 tps ( 80.2 allocs/op, 12.2 tasks/op, 49005 insns/op)
125799.75 tps ( 80.2 allocs/op, 12.2 tasks/op, 49003 insns/op)
AFTER:
127557.21 tps ( 80.2 allocs/op, 12.2 tasks/op, 49197 insns/op)
127835.98 tps ( 80.2 allocs/op, 12.2 tasks/op, 49198 insns/op)
127749.81 tps ( 80.2 allocs/op, 12.2 tasks/op, 49202 insns/op)
128941.17 tps ( 80.2 allocs/op, 12.2 tasks/op, 49192 insns/op)
129276.15 tps ( 80.2 allocs/op, 12.2 tasks/op, 49182 insns/op)
```
The PR does not introduce additional allocations on the read happy-path. The number of instructions used grows by about 200 insns/op. The increase in TPS is probably just a measurement error.
Closes#10092
* github.com:scylladb/scylla:
indexed_table_select_statement: return some exceptions as exception messages
result_combinators: add result_wrap_unpack
select_statement: return exceptions as errors in execute_without_checking_exception_message
select_statement: return exceptions without throwing in do_execute
select_statement: implement execute_without_checking_exception_message
select_statement: introduce helpers for working with failed results
query_pager: resultify relevant methods
storage_proxy: resultify (do_)query
storage_proxy: resultify query_singular
storage_proxy: propagate failed results through query_partition_key_range
storage_proxy: resultify query_partition_key_range_concurrent
storage_proxy: modify handle_read_error to also handle exception containers
abstract_read_executor: return result from execute()
abstract_read_executor: return and handle result from has_cl()
storage_proxy: resultify handling errors from read-repair
abstract_read_executor::reconcile: resultise handling of data_resolver->done()
abstract_read_executor::execute: resultify handling of data_resolver->done()
result_combinators: add result_discard_value
abstract_read_executor: resultify _result_promise
abstract_read_executor: return result from done()
abstract_read_resolver: fail promises by passing exception as value
abstract_read_resolver: resultify promises
exceptions: make it possible to return read_{timeout,failure}_exception as value
result_try: add as_inner/clone_inner to handle types
result_try: relax ConvertWithTo constraint
exception_container: switch impl to std::shared_ptr and make copyable
result_loop: add result_repeat
result_loop: add result_do_until
result_loop: add result_map_reduce
utils/result: add utilities for checking/creating rebindable results
Refs #10087
Add validation of all params for the keyspace_scrub api.
The validation method is generic and should be used by all apis eventually,
but I'm leaving that as follow-up work.
While at it, fixed the exception types thrown on invalid `scrub_mode` or `quarantine_mode` values from `std::runtime_error` to `httpd::bad_param_exception` so to generate the `bad_request` http status.
And added unit tests to verify that, and the handling of an unknown parameter.
Test: unit(dev)
DTest: nodetool_additional_test.py::TestNodetool::{test_scrub_with_one_node_expect_data_loss,test_scrub_with_multi_nodes_expect_data_rebuild,test_scrub_sstable_with_invalid_fragment,test_scrub_ks_sstable_with_invalid_fragment,test_scrub_segregate_sstable_with_invalid_fragment,test_scrub_segregate_ks_sstable_with_invalid_fragment}
Closes#10090
* github.com:scylladb/scylla:
api: storage_service: scrub: validate parameters
api: storage_service: refactor parse_tables
api: storage_service: refactor validate_keyspace
test: rest_api: add test_storage_service_keyspace_scrub tests
api: storage_service: scrub: throw httpd::bad_param_exception for invalid param values
In CQL table names must be composed only of letters, digits, or underscores,
but some Cassandra documentation is unclear whether these "letters" refer only
to the Latin alphabet, or maybe UTF-8 names composed of letters in other
alphabets should be allowed too.
This patch adds a test that confirms that both Scylla and Cassandra only
accept the Latin alphabet in table names, and for example UTF-8 names
with French or Hebrew letters are rejected.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20220222134220.972413-1-nyh@scylladb.com>
Add support for specifing integers in scientific format (for example 1.234e8) in INSERT JSON statement:
```
INSERT INTO table JSON '{"int_column": 1e7}';
```
Before the JSON parsing library was switched to RapidJSON from JsonCpp, this statement used to work correctly, because JsonCpp transparently casts double to integer value.
Inserting a floating-point number ending with .0 is allowed, as the fractional part is zero. Non-zero fractional part (for example 12.34) is disallowed. A new test is added to test all those behaviors.
This behavior differs from Cassandra, which disallows those types of numbers (1e7, 123.0 and 12.34), however some users rely on that behavior and JSON specification itself does not distinct between floating-point numbers and integer numbers (only a single "number" type is defined).
This PR also fixes two minor issues I noticed while looking at the code: wrong blob validation and missing `IsString()` checks that could result in assertion error.
Fixes#10100Fixes#10114Fixes#10115Closes#10101
* github.com:scylladb/scylla:
type_json: support integers in scientific format
type_json: add missing IsString() checks
type_json: fix wrong blob JSON validation
"
The table lists connected clients. For this the clients are
stored in real table when they connect, update their statuses
when needed and remove^w tombstone themselves when they
disconnect. On start the whole table is cleared.
This looks weird. Here's another approach (inspired by the
hackathon project) that makes this table a pure virtual one.
The schema is preserved so is the data returned.
The benefits of doing it virtual are
- no on-disk updates while processing clients
- no potentially failing updates on non-failing disconnect
- less usage of the global qctx thing
- less calls to global storage_proxy
- simpler support for thrift and alternator clients (today's
table implementation doesn't track them)
- the need to make virtual tables reg/unreg dynamic
branch: https://github.com/xemul/scylla/tree/br-clients-virtual-table-4
tests: manual(dev), unit(dev)
The manual test used 80-shards node and 1M connections from
1k different IP addresses.
"
* 'br-clients-virtual-table-4' of https://github.com/xemul/scylla:
test: Add cql-pytest sanity test for system.clients table
client_data: Sanitize connection_notifier
transport: Indentation fix after previous patch
code: Remove old on-disk version of system.clients table
system_keyspace: Add clients_v virtual table
protocol_server: Add get_client_data call
transport: Track client state for real
transport: Add stringifiers to client_data class
generic_server: Gentle iterator
generic_server: Type alias
docs: Add system.clients description
Adjusts the indexed_table_select_statement so that it uses the
result-aware methods in storage_proxy and propagates failed results as
result_message::exception.
Adds a helper combinator utils::result_wrap_unpack which, in contrast to
utils::result_wrap, uses futurize_apply instead of futurize_invoke to
call the wrapped callable.
In short, if utils::result_wrap is used to adapt code like this:
f.then([] {})
->
f_result.then(utils::result_wrap([] {}))
Then utils::result_wrap_unpack works for the following case:
f.then_unpack([] (arg1, arg2) {})
->
f_result.then(utils::result_wrap_unpack([] (arg1, arg2) {}))
Modifies the remaining logic of execute_without... (apart from the
do_execute call) so that the result-aware versions of storage_proxy's
methods are called and failed results are converted to
result_message::exception.
The select_statement will be able to propagate coordinator failures
without throwing, so it's important to override the default
implementations of execute and excecute_without... so that the first
calls the latter and not the other way around.
Adds:
- Includes for result-related helper methods (to be used in later
commits),
- Alias for coordinator_result,
- The wrap_result_to_error_message function - a bit similar to
utils::result_wrap. Adapts a callable T -> shared_ptr<result_message>
to take result<T> -> shared_ptr<result_message>. If the result is
failed, it converts it into result_message::exception and returns.
Adjusts do_query so that it propagates and returns failed results. The
query_result method is added which is result-aware, and the old query
method was changed to call query_result.
{kind=link}