Now every tests starts by deferring a call to
await_background_jobs. That can be verified with:
$ git grep -B 1 await_background test/boost/sstable_3_x_test.cc | grep THREAD | wc -l
90
$ git grep -A 1 SEASTAR_THREAD_TEST_CASE test/boost/sstable_3_x_test.cc | grep await_background | wc -l
90
Thanks to Raphael Carvalho for noticing it.
Refs #6624
Signed-off-by: Rafael Ávila de Espíndola <espindola@scylladb.com>
Reviewed-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20200619220048.1091630-1-espindola@scylladb.com>
after e40aa042a7, auto compaction is explicitly disabled on all
tables being populated and only enabled later on in the boot
process. we forgot to update cql_test_env to also reenable
auto compaction, so unit tests based on cql_test_env were not
compacting at all.
database_test, for example, was running out of file descriptors
because the number kept growing unboundly due to lack of compaction.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20200618225621.15937-1-raphaelsc@scylladb.com>
The call to `verify_owner_and_mode` from `flush_upload_dir`
fell between the cracks in b34c0c2ff6
(distributed_loader: rework uploading of SSTables).
It causes https://jenkins.scylladb.com/view/master/job/scylla-master/job/dtest-release/528/testReport/nodetool_additional_test/TestNodetool/nodetool_refresh_with_wrong_upload_modes_test/
to fail like this:
```
/Directory cannot be accessed .* write/ not found in 'Nodetool command '/jenkins/workspace/scylla-master/dtest-release/scylla/.ccm/scylla-repository/7351db7cab7bbf907172940d0bbf8b90afde90ba/scylla-tools-java/bin/nodetool -h 127.0.87.1 -p 7187 refresh -- keyspace1 standard1' failed; exit status: 1; stdout: nodetool: Scylla API server HTTP POST to URL '/storage_service/sstables/keyspace1' failed: Failed to load new sstables: std::filesystem::__cxx11::filesystem_error (error system:13, filesystem error: remove failed: Permission denied [/jenkins/workspace/scylla-master/dtest-release/scylla/.dtest/dtest-rqzo7km7/test/node1/data/keyspace1/standard1-8a57a660b29611eabf0c000000000000/upload/mc-3-big-TOC.txt])
```
Reenable it in this patch makes the dtest pass again.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20200621140439.85843-1-bhalevy@scylladb.com>
We already have a docker image option to enable alternator on an unencrypted
port, "--alternator-port", but we forgot to also allow the similar option
for enabling alternator on an encrypted (HTTPS) port: "--alternator-https-port"
so this patch adds the missing option, and documents how to use it.
Note that using this option is not enough. When this option is used,
Alternator also requires two files, /etc/scylla/scylla.crt and
/etc/scylla/scylla.key, to be inserted into the image. These files should
contain the SSL certificate, and key, respectively. If these files are
missing, you will get an error in the log about the missing file.
Fixes#6583.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20200621125219.12274-1-nyh@scylladb.com>
"
This patchset adds a reshape operation to each compaction strategy;
that is a strategy-specific way of detecting if SSTables are in-strategy
or off-strategy, and in case they are offstrategy moving them to in-strategy.
Often times the number of SSTables in a particular slice of the sstable set
matters for that decision (number of SSTables in the same time window for TWCS,
number of SSTables per tier for STCS, number of L0 SSTables for LCS). We want
to be more lenient for operations that keep the node offline, like reshape at
boot, but more forgiving for operations like upload, which run in maintenance
mode. To accomodate for that the threshold for considering a slice of the SSTable
set offstrategy is passed as a parameter
Once this patchset is applied, the upload directory will reshape the SSTables
before moving them to the main directory (if needed). One side effect of it
is that it is no longer necessary to take locks for the refresh operation nor
disable writes in the table.
With the infrastructure that we have built in the upload directory, we can
apply the same set of steps to populate_column_family. Using the sstable_directory
to scan the files we can reshard and reshape (usually if we resharded a reshape
will be necessary) with the node still offline. This has the benefit of never
adding shared SSTables to the table.
Applying this patchset will unlock a host of cleanups:
- we can get rid of all testing for shared sstables, sstable_need_rewrite, etc.
- we can remove the resharding backlog tracker.
and many others. Most cleanups are deferred for a later patchset, though.
"
* 'reshard-reshape-v4' of github.com:glommer/scylla:
distributed_loader: reshard before the node is made online
distributed_loader: rework uploading of SSTables
sstable_directory: add helper to reshape existing unshared sstables
compaction_strategy: add method to reshape SSTables
compaction: add a new compaction type, Reshape
compaction: add a size and throught pretty printer.
compaction: add default implementation for some pure functions
tests: fix fragile database tests
distributed_loader.cc: add a helper function to extract the highest SSTable version found
distributed_loader.cc : extract highest_generation_seen code
compaction_manager: rename run_resharding_job
distributed_loader: assume populate_column_families is run in shard 0
api: do not allow user to meddle with auto compaction too early
upload: use custom error handler for upload directory
sstable_directory: fix debug message
This patch moves the resharding process to use the new
directory_with_sstables_handler infrastructure. There is no longer
a clear reshard step, and that just becomes a natural part of
populate_column_family.
In main.cc, a couple of changes are necessary to make that happen.
The first one obviously is to stop calling reshard. We also need to
make sure that:
- The compaction manager is started much earlier, so we can register
resharding jobs with it.
- auto compactions are disabled in the populate method, so resharding
doesn't have to fight for bandwidth with auto compactions.
Now that we are resharding through the sstable_directory, the old
resharding code can be deleted. There is also no need to deal with
the resharding backlog either, because the SSTables are not yet
added to the sstable set at this point.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
Uploading of SSTables is problematic: for historical reasons it takes a
lock that may have to wait for ongoing compactions to finish, then it
disables writes in the table, and then it goes loading SSTables as if it
knew nothing about them.
With the sstable_directory infrastructure we can do much better:
* we can reshard and reshape the SSTables in place, keeping the number
of SSTables in check. Because this is an background process we can be
fairly aggressive and set the reshape mode to strict.
* we can then move the SSTables directly into the main directory.
Because we know they are few in number we can call the more elegant
add_sstable_and_invalidate_cache instead of the open coding currently
done by load_new_sstables
* we know they are not shared (if they were, we resharded them),
simplifying the load process even further.
The major changes after this patch is applied is that all compactions
(resharding and reshape) needed to make the SSTables in-strategy are
done in the streaming class, which reduces the impact of this operation
on the node. When the SSTables are loaded, subsequent reads will not
suffer as we will not be adding shared SSTables in potential high
numbers, nor will we reshard in the compaction class.
There is also no more need for a lock in the upload process so in the
fast path where users are uploading a set of SSTables from a backup this
should essentially be instantaneous. The lock, as well as the code to
disable and enable table writes is removed.
A future improvement is to bypass the staging directory too, in which
case the reshaping compaction would already generate the view updates.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
Before moving SSTables to the main directory, we may need to reshape them
into in-strategy. This patch provides helper code that reshapes the SSTables
that are known to be unshared local in the sstable directory, and updates the
sstable directory with the result.
Rehaping can be made more or less aggressive by passing a reshape mode
(relaxed or strict), which will influence the amount of SSTables reshape
can tolerate to consider a particular slice of the SSTable set
offstrategy.
Because the compaction expects an std::vector everywhere, we changed
our chunked vector for the unshared sstables to a std::vector so we
can more easily pass it around without conversions.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
Some SSTable sets are considered to be off-strategy: they are in a shape
that is at best not optimal and at worst adversarial to the current
compaction strategy.
This patch introduces the compaction strategy-specific method
get_reshaping_job(). Given an SSTable set, it returns one compaction
that can be done to bring the table closer to being in-strategy. The
caller can then call this repeatedly until the table is fully
in-strategy.
As an example of how this is supposed to work, consider TWCS: some
SSTables will belong to a single window -> in which case they are
already in-strategy and don't need to be compacted, and others span
multiple windows in which case they are considered off-strategy and
have to be compacted.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
From the point of view of selecting SSTables and its expected output,
Reshaping really is just a normal compaction. However, there are some
key differences that we would like to uphold:
- Reshaping is done separately from the main SSTable set. It can be
done with the node offline, or it can be done in a separate priority
class. Either way, we don't want those SSTables to count towards
backlog. For reads, because the SSTables are not yet registered in
the backlog tracker (if offline or coming from upload), if we were
to deduct compaction charges from it we would go negative. For writes,
we don't want to deal with backlog management here because we will add
the SSTable at once when reshaping is finished.
- We don't need to do early replacements.
- We would like to clearly mark the Reshaping compactions as such in the
logs
For the reasons above, it is nicer to add a new Reshape compaction type,
a subclass of compaction, that upholds such properties.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
This is so we don't always use MB. Sometimes it is best
to report GB, TB, and their equivalent throughput metrics.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
* seastar b515d63735...a6c8105443 (15):
> Merge "Move thread_wake_task out of line" from Rafael
> future: Fix result_of_apply instantiation
> future: Move the function in then/then_wrapped only once
> io-queue: Dont leak desc
> fair-queue: Keep request queues self-consistent
> app: Do not coredump on missing options
> future: promise: mark set_value as noexcept
> future: future_state: mark set as noexcept
> fair_queue_perf: Remove unused captures
> file_io_test: Add missing override
> Merge "tmp_dir: handle remove failure in do_with_thread" from Benny
> api-level: Add missing api_v4 namespace
> future: Fix CanApplyTuple
> http: use logger instead of stderr for erro reporting
> sstring: Generalize make_sstring a bit
There are some functions that are today pure that have an obvious
implementation (for example on_new_partition, do nothing). We'll add
default implementations to the compaction class, which reduces the
boilerplate needed to add a new compaction type.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
This test wants to make sure that an SSTable with generation number 4,
which is incomplete, gets deleted.
While that works today, the way the test verifies that is fragile
because new SSTables can and will be created, especially in the local
directory that sees a lot of activity on startup.
It works if generations don't go that far, but with SMP, even a single
SSTable in the right shard can end up having generation 4. In practice
this isn't an issue today because the code calls
cf.update_sstables_known_generation() as soon as it sees a file, before
deciding whether or not the file has to be deleted. However this
behavior is not guaranteed and is changing.
The best way to fix this would be to check if the file is the same,
including its inode. But given that this is just a unit test (which
is almost always if not always single node), I am just moving to use
the peers table instead. Again, we could have created a user table,
but it's just not worth the hassle.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
Using a map reduce in a shared sstable directory, finds the highest
version seen across all shards.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
It will be used to run any custom job where the caller provides a
function. One such example is indeed resharding, but reshaping SSTables
can also fall here.
The semaphore is also renamed, and we'll allow only one custom job at a
time (across all possible types).
We also remove the assumption of the scheduling group. The caller has to
have already placed the code in the correct CPU scheduling group. The
I/O priority class comes from the descriptor.
To make sure that we don't regress, we wrap the entire reshard-at-boot
code in the compaction class. Currently the setup would be done in the
main group, and the actual resharding in the compaction group. Note that
this is temporary, as this code is about to change.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
This is already the case, since main.cc calls it from shard 0 and
relies on it to spread the information to the other shards. We will
turn this branch - which is always taken - into an assert for the
sake of future-proofing and soon add even more code that relies on this
being executed in shard 0.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
We are about to use the auto compaction property during the
populate/reshard process. If the user toggles it, the database can be
left in a bad state.
There should be no reason why a user would want to set that up this
early. So we'll disallow it.
To do that property, it is better if the check of whether or not
the storage service is ready to accomodate this request is local
to the storage service itself. We then move the logic of set_tables_autocompaction
from api to the storage service. The API layer now merely translates
the table names and pass it along.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
The seastar api v4 changes the return type of when_all_succeed. This
patch adds discard_result when that is best solution to handle the
change.
This doesn't do the actual update to v4 since there are still a few
issues left to fix in seastar. A patch doing just the update will
follow.
Signed-off-by: Rafael Ávila de Espíndola <espindola@scylladb.com>
Message-Id: <20200617233150.918110-1-espindola@scylladb.com>
This patch aim to make the implementation and usage of the
approx_exponential_histogram clearer.
The approx_exponential_histogram Uses a combination of Min, Max,
Precision and number of buckets where the user needs to pick 3.
Most of the changes in the patch are about documenting the class and
method, but following the review there are two functionality changes:
1. The user would pick: Min, Max and Precision and the number of buckets
will be calculated from these values.
2. The template restrictions are now state in a requires so voiolation
will be stop at compile time.
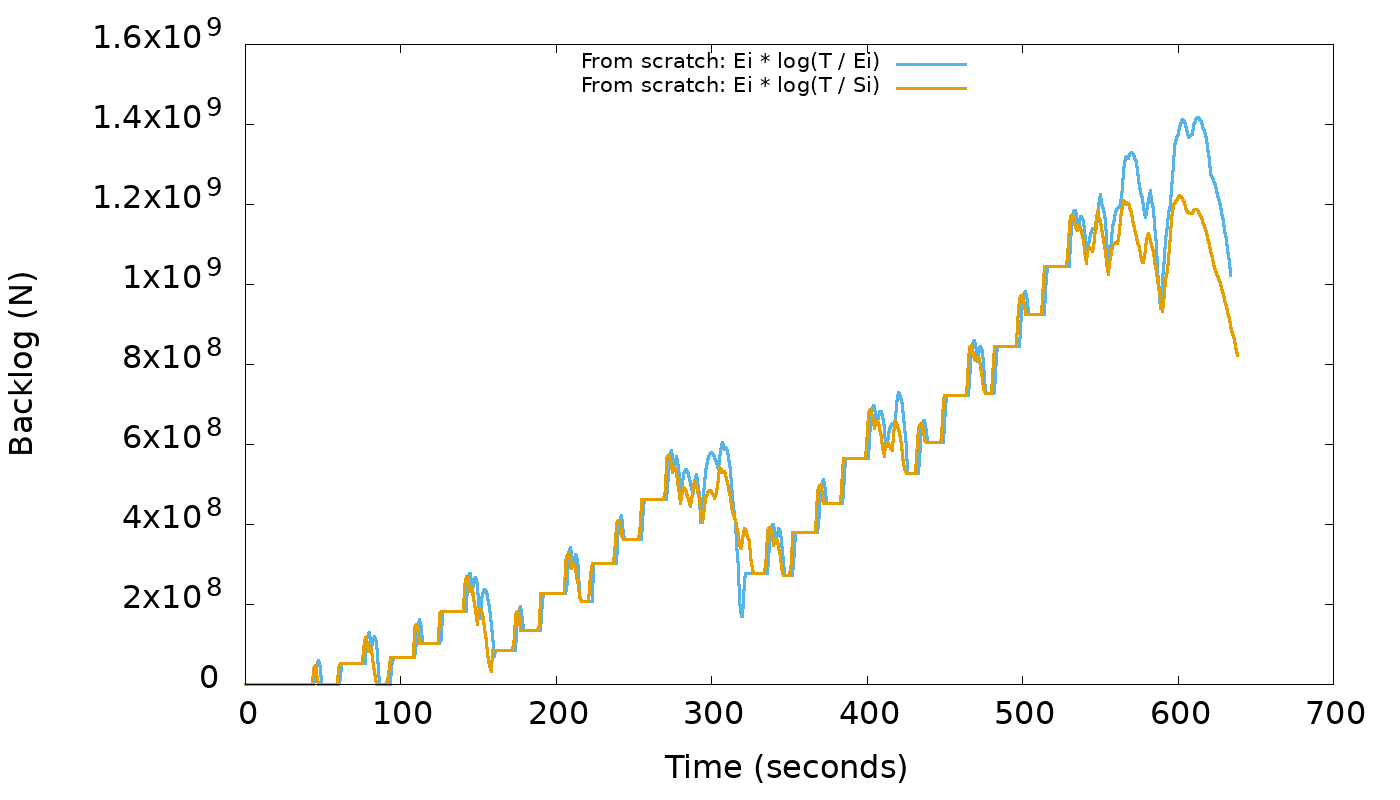
When debugging this for first time c412a7a, I thought the problem,
which causes backlog to be negative, was a bug in the implementation of the
formula, but it turns out that the bug is actually in the formula itself.
Not limiting the scope of this bug to STCS because its tracker is inherited
by the trackers of other strategies, meaning they're also affected by this.
The backlog for a SSTable is known to be
Bi = Ei * log(T / Si)
Where T = total Size minus compacted bytes for a table,
Ci = Compacted Bytes for a SSTable,
Si = Size of a SStable
Ei = Ci - Si
The problem was that we were assuming T > Si, but it can happen that T
is lower than Si if the table in question is decreasing in size.
If we rewrite SSTable backlog as
Bi = Ei * log (T) - Ei * log(Si)
It becomes even clearer why T cannot be lower than Si whatsoever,
or the backlog calculation can go wrong because first term becomes
lower than the second.
Fixing the formula consists of changing it to
Bi = Ei * log (T / Ei)
Bi = Ei * log (T) - Ei * log (Si - Ci)
After this change, the backlog still behave in a very similar way
as before, which can be confirmed via this graph:
https://user-images.githubusercontent.com/1409139/79627762-71afdf80-8111-11ea-9ebc-0831c4e3d9c6.pngFixes#6021.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20200616174712.16505-1-raphaelsc@scylladb.com>
"
This patch series attempts to decouple package build and release
infrastructure, which is internal to Scylla (the company). The goal of
this series is to make it easy for humans and machines to build the full
Scylla distribution package artifacts, and make it easy to quickly
verify them.
The improvements to build system are done in the following steps.
1. Make scylla.git a super-module, which has git submodules for
scylla-jmx and scylla-tools. A clone of scylla.git is now all that
is needed to access all source code of all the different components
that make up a Scylla distribution, which is a preparational step to
adding "dist" ninja build target. A scripts/sync-submodules.sh helper
script is included, which allows easy updating of the submodules to the
latest head of the respective git repositories.
2. Make builds reproducible by moving the remaining relocatable package
specific build options from reloc/build_reloc.sh to the build system.
After this step, you can build the exact same binaries from the git
repository by using the dbuild version from scylla.git.
3. Add a "dist" target to ninja build, which builds all .rpm and .deb
packages with one command. To build a release, run:
$ ./tools/toolchain/dbuild ./configure.py --mode release
$ ./tools/toolchain/dbuild ninja-build dist
and you will now have .rpm and .deb packages to all the components of
a Scylla distribution.
4. Add a "dist-check" target to ninja build for verification of .rpm and
.deb packages in one command. To verify all the built packages, run:
$ ninja-build dist-check
Please note that you must run this step on the host, because the
target uses Docker under the hood to verify packages by installing
them on different Linux distributions.
Currently only CentOS 7 verification is supported.
All these improvements are done so that backward compatibility is
retained. That is, any existing release infrastructure or other build
scripts are completely unaffacted.
Future improvements to consider:
- Package repository generation: add a "ninja repo" command to generate
a .rpm and .deb repositories, which can be uploaded to a web site.
This makes it possible to build a downloadable Scylla distribution
from scylla.git. The target requires some configuration, which user
has to provide. For example, download URL locations and package
signing keys.
- Amazon Machine Image (AMI) support: add a "ninja ami" command to
simplify the steps needed to generate a Scylla distribution AMI.
- Docker image support: add a "ninja docker" command to simplify the
steps needed to generate a Scylla distribution Docker image.
- Simplify and unify package build: simplify and unify the various shell
scripts needed to build packages in different git repositories. This
step will break backward compatiblity and can be done only after
relevant build scripts and release infrastructure is updated.
"
* 'penberg/packaging/v5' of github.com:penberg/scylla:
docs: Update packaging documentation
build: Add "dist-check" target
scripts/testing: Add "dist-check" for package verification
build: Add "dist" target
reloc: Add '--builddir' option to build_deb.sh
build: Add "-ffile-prefix-map" to cxxflags
docs: Document sync-submodules.sh script in maintainer.md
sync-submodules.sh: Add script for syncing submodules
Add scylla-tools submodule
Add scylla-jmx submodule
Intersection was previously not tested for singular ranges. This
ensures it will always work for singular ranges, too.
Tests: unit(dev)
Signed-off-by: Dejan Mircevski <dejan@scylladb.com>
"
The "promoted index" is how the sstable format calls the clustering key index within a given partition.
Large partitions with many rows have it. It's embedded in the partition index entry.
Currently, lookups in the promoted index are done by scanning the index linearly so the lookup
is O(N). For large partitions that's inefficient. It consumes both a lot of CPU and I/O.
We could do better and use binary search in the index. This patch series switches the mc-format
index reader to do that. Other formats use the old way.
The "mc" format promoted index has an extra structure at the end of the index called "offset map".
It's a vector of offsets of consecutive promoted index entries. This allows us to access random
entries in the index without reading the whole index.
The location of the offset entry for a given promoted index entry can be derived by knowing where
the offset vector ends in the index file, so the offset map also doesn't have to be read completely
into the memory.
The most tricky part is caching. We need to cache blocks read from the index file to amortize the
cost of binary search:
- if the promoted index fits in the 32 KiB which was read from the index when looking for
the partition entry, we don't want to issue any additional I/O to search the promoted index.
- with large promoted indexes, the last few bisections will fall into the same I/O block and we
want to reuse that block.
- we don't want the cache to grow too big, we don't want to cache the whole promoted index
as the read progresses over the index. Scanning reads may skip multiple times.
This series implements a rather simple approach which meets all the
above requirements and is not worse than the current state of affairs:
- Each index cursor has its own cache of the index file area which corresponds to promoted index
This is managed by the cached_file class.
- Each index cursor has its own cache of parsed blocks. This allows the upper bound estimation to
reuse information obtained during lower bound lookup. This estimation is used to limit
read-aheads in the data file.
- Each cursor drops entries that it walked past so that memory footprint stays O(log N)
- Cached buffers are accounted to read's reader_permit.
Later, we could have a single cache shared by many readers. For that, we need to come up with eviction
policy.
Fixes#4007.
TESTING RESULTS
* Point reads, large promoted index:
Config: rows: 10000000, value size: 2000
Partition size: 20 GB
Index size: 7 MB
Notes:
- Slicing read into the middle of partition (offset=5000000, read=1) is a clear win for the binary search:
time: 1.9ms vs 22.9ms
CPU utilization: 8.9% vs 92.3%
I/O: 21 reqs / 172 KiB vs 29 reqs / 3'520 KiB
It's 12x faster, CPU utilization is 10x times smaller, disk utilization is 20x smaller.
- Slicing at the front (offset=0) is a mixed bag.
time is similar: 1.8ms
CPU utilization is 6.7x smaller for bsearch: 8.5% vs 57.7%
disk bandwidth utilization is smaller for bsearch but uses more IOs: 4 reqs / 320 KiB (scan) vs 17 reqs / 188 KiB (bsearch)
bsearch uses less bandwidth because the series reduces buffer size used for index file I/O.
scan is issuing:
2 * 128 KB (index page)
2 * 32 KB (data file)
bsearch is issuing:
1 * 64 KB (index page)
15 * 4 KB (promoted index)
1 * 64 KB (data file)
The 1 * 64 KB is chosen dynamically by seastar. Sometimes it chooses 2 * 32 KB (with read-ahead).
32 KB is the minimum I/O currently.
Disk utilization could be further improved by changing the way seastar's dynamic I/O adjustments work
so that it uses 1 * 4 KB when it suffices. This is left for the follow-up.
Command:
perf_fast_forward --datasets=large-part-ds1 \
--run-tests=large-partition-slicing-clustering-keys -c1 --test-case-duration=1
Before:
offset read time (s) iterations frags frag/s mad f/s max f/s min f/s avg aio aio (KiB) blocked dropped idx hit idx miss idx blk c hit c miss c blk cpu mem
0 1 0.001836 172 1 545 9 563 175 4.0 4 320 2 2 0 1 1 0 0 0 57.7% 0
0 32 0.001858 502 32 17220 126 17776 11526 3.2 3 324 2 1 0 1 1 0 0 0 56.4% 0
0 256 0.002833 339 256 90374 427 91757 85931 7.0 7 776 3 1 0 1 1 0 0 0 41.1% 0
0 4096 0.017211 58 4096 237984 2011 241802 233870 66.1 66 8376 59 2 0 1 1 0 0 0 21.4% 0
5000000 1 0.022952 42 1 44 1 45 41 29.2 29 3520 22 2 0 1 1 0 0 0 92.3% 0
5000000 32 0.023052 43 32 1388 14 1414 1331 31.1 32 3588 26 2 0 1 1 0 0 0 91.7% 0
5000000 256 0.024795 41 256 10325 129 10721 9993 43.1 39 4544 29 2 0 1 1 0 0 0 86.4% 0
5000000 4096 0.038856 27 4096 105414 398 106918 103162 95.2 95 12160 78 5 0 1 1 0 0 0 61.4% 0
After (v2):
offset read time (s) iterations frags frag/s mad f/s max f/s min f/s avg aio aio (KiB) blocked dropped idx hit idx miss idx blk c hit c miss c blk cpu mem
0 1 0.001831 248 1 546 21 581 252 17.6 17 188 2 0 0 1 1 0 0 0 8.5% 0
0 32 0.001910 535 32 16751 626 17770 13896 17.9 19 160 3 0 0 1 1 0 0 0 8.8% 0
0 256 0.003545 266 256 72207 2333 89076 62852 26.9 24 764 7 0 0 1 1 0 0 0 9.7% 0
0 4096 0.016800 56 4096 243812 524 245430 239736 83.6 83 8700 64 0 0 1 1 0 0 0 16.6% 0
5000000 1 0.001968 351 1 508 19 538 380 21.3 21 172 2 0 0 1 1 0 0 0 8.9% 0
5000000 32 0.002273 431 32 14077 436 15503 11551 22.7 22 268 3 0 0 1 1 0 0 0 8.9% 0
5000000 256 0.003889 257 256 65824 2197 81833 57813 34.0 37 652 18 0 0 1 1 0 0 0 11.2% 0
5000000 4096 0.017115 54 4096 239324 834 241310 231993 88.3 88 8844 65 0 0 1 1 0 0 0 16.8% 0
After (v1):
offset read time (s) iterations frags frag/s mad f/s max f/s min f/s avg aio aio (KiB) blocked dropped idx hit idx miss idx blk c hit c miss c blk cpu mem
0 1 0.001886 259 1 530 4 545 261 18.0 18 376 2 2 0 1 1 0 0 0 9.1% 0
0 32 0.001954 513 32 16381 93 16844 15618 19.0 19 408 3 2 0 1 1 0 0 0 9.3% 0
0 256 0.003266 318 256 78393 1820 81567 61663 30.8 26 1272 7 2 0 1 1 0 0 0 10.4% 0
0 4096 0.017991 57 4096 227666 855 231915 225781 83.1 83 8888 55 5 0 1 1 0 0 0 15.5% 0
5000000 1 0.002353 232 1 425 2 432 232 23.0 23 396 2 2 0 1 1 0 0 0 8.7% 0
5000000 32 0.002573 384 32 12437 47 12571 429 25.0 25 460 4 2 0 1 1 0 0 0 8.5% 0
5000000 256 0.003994 259 256 64101 2904 67924 51427 37.0 35 1484 11 2 0 1 1 0 0 0 10.6% 0
5000000 4096 0.018567 56 4096 220609 448 227395 219029 89.8 89 9036 59 5 0 1 1 0 0 0 15.1% 0
* Point reads, small promoted index (two blocks):
Config: rows: 400, value size: 200
Partition size: 84 KiB
Index size: 65 B
Notes:
- No significant difference in time
- the same disk utilization
- similar CPU utilization
Command:
perf_fast_forward --datasets=large-part-ds1 \
--run-tests=large-partition-slicing-clustering-keys -c1 --test-case-duration=1
Before:
offset read time (s) iterations frags frag/s mad f/s max f/s min f/s avg aio aio (KiB) blocked dropped idx hit idx miss idx blk c hit c miss c blk cpu mem
0 1 0.000279 470 1 3587 31 3829 478 3.0 3 68 2 1 0 1 1 0 0 0 21.1% 0
0 32 0.000276 3498 32 116038 811 122756 104033 3.0 3 68 2 1 0 1 1 0 0 0 24.0% 0
0 256 0.000412 2554 256 621044 1778 732150 559221 2.0 2 72 2 0 0 1 1 0 0 0 32.6% 0
0 4096 0.000510 1901 400 783883 4078 819058 665616 2.0 2 88 2 0 0 1 1 0 0 0 36.4% 0
200 1 0.000339 2712 1 2951 8 3001 2569 2.0 2 72 2 0 0 1 1 0 0 0 17.8% 0
200 32 0.000352 2586 32 91019 266 92427 83411 2.0 2 72 2 0 0 1 1 0 0 0 20.8% 0
200 256 0.000458 2073 200 436503 1618 453945 385501 2.0 2 88 2 0 0 1 1 0 0 0 29.4% 0
200 4096 0.000458 2097 200 436475 1676 458349 381558 2.0 2 88 2 0 0 1 1 0 0 0 29.0% 0
After (v1):
Testing slicing of large partition using clustering keys:
offset read time (s) iterations frags frag/s mad f/s max f/s min f/s avg aio aio (KiB) blocked dropped idx hit idx miss idx blk c hit c miss c blk cpu mem
0 1 0.000278 492 1 3598 30 3831 500 3.0 3 68 2 1 0 1 1 0 0 0 19.4% 0
0 32 0.000275 3433 32 116153 753 122915 92559 3.0 3 68 2 1 0 1 1 0 0 0 22.5% 0
0 256 0.000458 2576 256 559437 2978 728075 504375 2.1 2 88 2 0 0 1 1 0 0 0 29.0% 0
0 4096 0.000506 1888 400 790064 3306 822360 623109 2.0 2 88 2 0 0 1 1 0 0 0 36.6% 0
200 1 0.000382 2493 1 2619 10 2675 2268 2.0 2 88 2 0 0 1 1 0 0 0 16.3% 0
200 32 0.000398 2393 32 80422 333 84759 22281 2.0 2 88 2 0 0 1 1 0 0 0 19.0% 0
200 256 0.000459 2096 200 435943 1608 453989 380749 2.0 2 88 2 0 0 1 1 0 0 0 30.5% 0
200 4096 0.000458 2097 200 436410 1651 455779 382485 2.0 2 88 2 0 0 1 1 0 0 0 29.2% 0
* Scan with skips, large index:
Config: rows: 10000000, value size: 2000
Partition size: 20 GB
Index size: 7 MB
Notes:
- Similar time, slightly worse for binary search: 36.1 s (scan) vs 36.4 (bsearch)
- Slightly more I/O for bsearch: 153'932 reqs / 19'703'260 KiB (scan) vs 155'651 reqs / 19'704'088 KiB (bsearch)
Binary search reads more by 828 KB and by 1719 IOs.
It does more I/O to read the the promoted index offset map.
- similar (low) memory footprint. The danger here is that by caching index blocks which we touch as we scan
we would end up caching the whole index. But this is protected against by eviction as demonstrated by the
last "mem" column.
Command:
perf_fast_forward --datasets=large-part-ds1 \
--run-tests=large-partition-skips -c1 --test-case-duration=1
Before:
read skip time (s) iterations frags frag/s mad f/s max f/s min f/s avg aio aio (KiB) blocked dropped idx hit idx miss idx blk c hit c miss c blk cpu mem
1 1 36.103451 4 5000000 138491 38 138601 138453 153932.0 153932 19703260 153561 1 0 1 1 0 0 0 31.5% 502690
After (v2):
read skip time (s) iterations frags frag/s mad f/s max f/s min f/s avg aio aio (KiB) blocked dropped idx hit idx miss idx blk c hit c miss c blk cpu mem
1 1 37.000145 4 5000000 135135 6 135146 135128 155651.0 155651 19704088 138968 0 0 1 1 0 0 0 34.2% 0
After (v1):
read skip time (s) iterations frags frag/s mad f/s max f/s min f/s avg aio aio (KiB) blocked dropped idx hit idx miss idx blk c hit c miss c blk cpu mem
1 1 36.965520 4 5000000 135261 30 135311 135231 155628.0 155628 19704216 139133 1 0 1 1 0 0 0 33.9% 248738
Also in:
git@github.com:tgrabiec/scylla.git sstable-use-index-offset-map-v2
Tests:
- unit (all modes)
- manual using perf_fast_forward
"
* tag 'sstable-use-index-offset-map-v2' of github.com:tgrabiec/scylla:
sstables: Add promoted index cache metrics
position_in_partition: Introduce external_memory_usage()
cached_file, sstables: Add tracing to index binary search and page cache
sstables: Dynamically adjust I/O size for index reads
sstables, tests: Allow disabling binary search in promoted index from perf tests
sstables: mc: Use binary search over the promoted index
utils: Introduce cached_file
sstables: clustered_index: Relax scope of validity of entry_info
sstables: index_entry: Introduce owning promoted_index_block_position
compound_compat: Allow constructing composite from a view
sstables: index_entry: Rename promoted_index_block_position to promoted_index_block_position_view
sstables: mc: Extract parser for promoted index block
sstables: mc: Extract parser for clustering out of the promoted index block parser
sstables: consumer: Extract primitive_consumer
sstables: Abstract the clustering index cursor behavior
sstables: index_reader: Rearrange to reduce branching and optionals
This patch adds "-ffile-prefix-map" to cxxflags for all build modes.
This has two benefits:
1, Relocatable packages no longer have any special build flags, which
makes deeper integration with the build system possible (e.g.
targets for packages).
2 Builds are now reproducible, which makes debugging easier in case you
only have a backtrace, but no artifacts. Rafael explains:
"BTW, I think I found another argument for why we should always build
with -ffile-prefix-map=.
There was user after free test failure on next promotion. I am unable
to reproduce it locally, so it would be super nice to be able to
decode the backtrace.
I was able to do it, but I had to create a
/jenkins/workspace/scylla-master/next/ directory and build from there
to get the same results as the bot."
Acked-by: Botond Dénes <bdenes@scylladb.com>
Acked-by: Nadav Har'El <nyh@scylladb.com>
Acked-by: Rafael Avila de Espindola <espindola@scylladb.com>
This reverts commit ac7237f991. The logic
is wrong and always picks "podman" if it's installed on the system even
if user asks for "docker" with the DBUILD_TOOL environment variable.
This wreaks havoc on machines that have both docker and podman packages
installed, but podman is not configured correctly.
When a token is calculated for stream_id, we check that the key is
exactly 16 bytes long. If it's not - `minimum_token` is returned
and client receives empty result.
This used to be the expected behavior for empty keys; now it's
extended to keys of any incorrect length.
Fixes#6570
All tests that write some data and then read it back need to use
ConsistentRead=True, otherwise the test may sporadically fail on a multi-
node cluster.
In the previous patch we fixed the full_query()/full_scan() convenience
functions. In this patch, I audited the calls to the boto3 read methods -
get_item(), batch_get_item(), query(), scan(), and although most of them
did use ConsistentRead=True as needed, I found some missing and this patch
fixes them.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20200616080334.825893-1-nyh@scylladb.com>
Many of the Alternator tests use the convenience functions full_query()/
full_scan() to read from the table. Almost all these tests need to be able
to read their own writes, i.e., want ConsistentRead=True, but none of them
explicitly specified this parameter. Such tests may sporadically fail when
running on cluster with multiple nodes.
So this patch follows a TODO in the code, and makes ConsistentRead=True
the default for the full_*() functions. The caller can still override it
with ConsistentRead=False - and this is necessary in the GSI tests, because
ConsistentRead=True is not allowed in GSIs.
Note that while ConsistentRead=True is now the default for the full_*()
convenience functions, but it is still not the default for the lower level
boto3 functions scan(), query() and get_item() - so usages of those should
be evaluated as well and missing ConsistentRead=True, if any, should be
added.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20200616073821.824784-1-nyh@scylladb.com>
SSTables created for the upload directory should be using its custom error
handler.
There is one user of the custom error handler in tree, which is the current
upload directory function. As we will use a free function instead of a lambda
in our implementation we also use the opportunity to fix it for consistency.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
I just noticed while working on the reshape patches that there
is an extra format bracket in two of the debug message. As they
are debug I've seen them less often than the others and that slipped.
Signed-off-by: Glauber Costa <glauber@scylladb.com>
Merged patch series by Rafael Ávila de Espíndola:
The main advantage is that callers now don't have to construct
sstrings. It is also a 0.09% win in text size (from 41804308 to
41766484 bytes) and the tps reported by
perf_simple_query --duration 16 --smp 1 -m4G >> log 2>err
in 500 randomized runs goes up by 0.16% (from 162259 to 162517).
Rafael Ávila de Espíndola (3):
service: Pass a std::string_view to client_state::set_keyspace
cql3: Use a flat_hash_map in untyped_result_set_row
cql3: Pass std::string_view to various untyped_result_set member
functions
cql3/untyped_result_set.hh | 30 ++++++++++++++++--------------
service/client_state.hh | 2 +-
cql3/untyped_result_set.cc | 6 +++---
service/client_state.cc | 4 ++--
4 files changed, 22 insertions(+), 20 deletions(-)
{kind=link}