"
Stopping transport (cql, thrift, messaging, etc.) can happen from
several places -- drain, decommission, stop, isolation. Some of
them can even run in parallel. This patch makes transport stopping
bulletproof.
tests: unit(dev)
start-stop (dev)
start-drain-stop (dev)
fixes: #8911
"
* 'br-stop-transport-races' of https://github.com/xemul/scylla:
storage_service: Indentation fix
storage_service: Make stop_transport re-entrable
storage_service: Stop transport on decommission
Storage service install disk error handlers in constructor and these
connections are not unregistered. It's not a problem in real life,
because storage service is not stopped, but in some tests this can
lead to use-after-frees.
The sstables_datafile_test runs some of the testcases in cql_test_env
which starts and (!) stops the storage service. Other testcases are
run in a lightweight sstables_test_env which does not mess with the
storage service at all. Now, if a case of the 2nd kind is run after
the one of the 1st and (for whatever reason) generates a disk error
it will trigger use-after-free -- after the 1st testcase the storage
service disk error registration would remain, but the storage service
itself would already be stopped, thus triggering the disk error will
try to access stopped sharded storage service inside the .isolate().
The fix is to keep the scoped connection on the storage service list
of various listeners. On stop it will go away automagically.
tests: unit(dev), sstables_datafile_test with forced disk error
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20210625062648.27812-1-xemul@scylladb.com>
std::copy_if runs without yielding.
See https://github.com/scylladb/scylla/issues/8897#issuecomment-867522480
Also, eliminate extraneous loop on merge
first1 will point to the inserted value which is a copy of *first2.
Since list2 is sorted in ascending order, the next item from list2
will never be less than the one we've just inserted,
so we waste an iteration to merely increment first1 again.
Fixes#8897
Test: unit(dev), stall_free_test(debug)
DTest: repair_additional_test.py:RepairAdditionalTest.{repair_same_row_diff_value_3nodes_diff_shard_count_test,repair_disjoint_row_3nodes_diff_shard_count_test} (dev)
Closes#8925
* github.com:scylladb/scylla:
utils: merge_to_gently: eliminate extraneous loop on merge
utils: merge_to_gently: prevent stall in std::copy_if
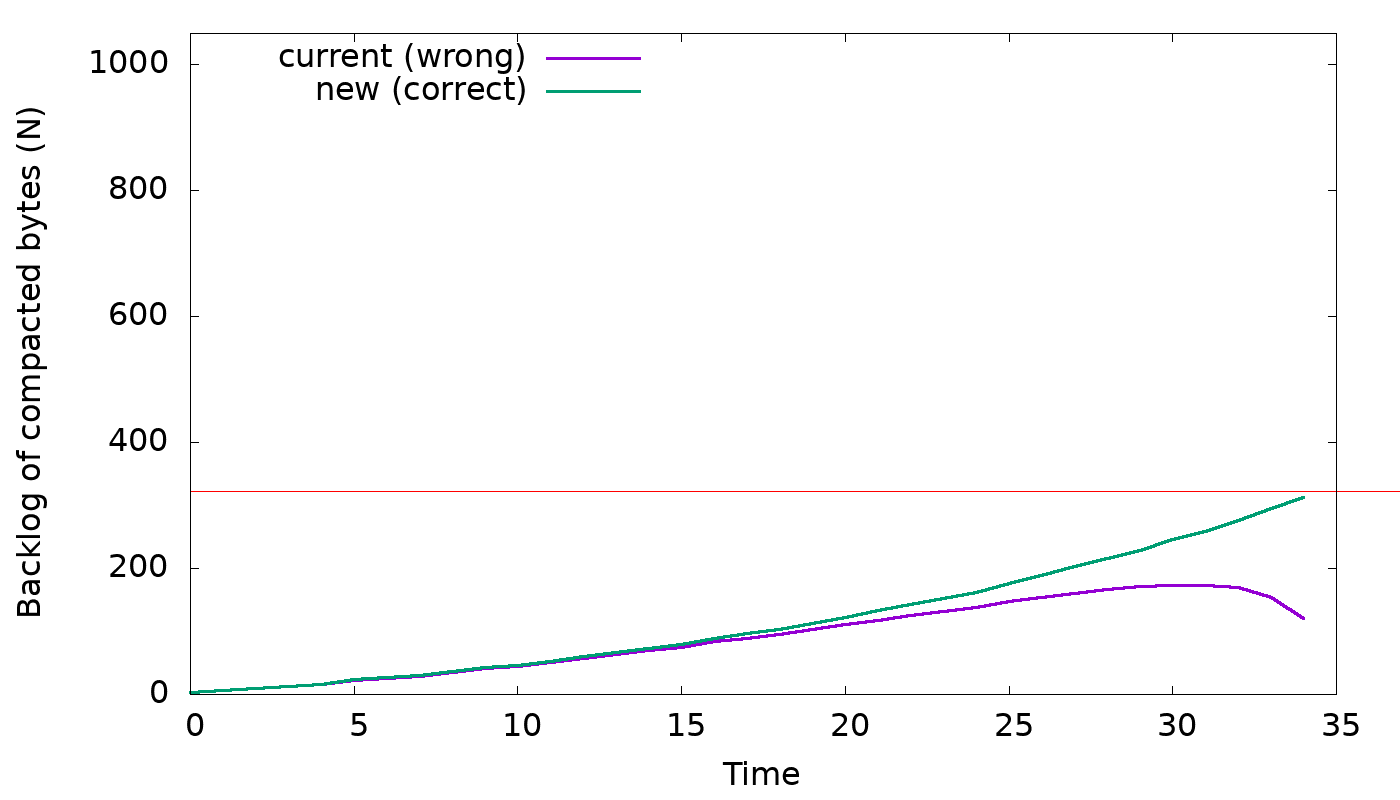
It was observed that as compaction progresses the backlog of compacting SSTable
is being reduced very slowly, which causes shares to be higher than needed, and
consequently compaction acts much more aggressively than it has to.
https://user-images.githubusercontent.com/1409139/120237819-93dfc080-c232-11eb-9042-68114e285ea0.png
The graph above shows the amount of backlog that is reduced from a SSTable
being compacted. The red line denotes the total backlog of the SSTable, before
it's selected for compaction. The expectation is that the more a SSTable is
compacted the more backlog will be reduced from it. However, in the current
implementation, it can be seen that the backlog to be reduced, from the SSTable
being compacted, starts being inversely proportional to the amount of data
already compacted.
Turns out that this problem happens because the implementation of backlog
formula becomes incorrect when the SSTable is being compacted.
Backlog for a sstable is currently defined as:
Bi = Ei * log (T / Ei)
where Ei = Si - Ci (bytes left to be compacted)
and Si = size of SStable
and Ci = total bytes compacted
and T = total size of table
The formula above can also be rewritten as follows:
Bi = Ei * log (T) - Ei * log (Ei)
the second term `Ei * log (Ei)` can be rewritten as:
= (Si - Ci) * log (Ei)
= Si * log (Ei) - Ci * log (Ei)
However, digging backlog implementation, turns out that we're incorrectly
implementing that second term as:
= Si * log (Si) - Ci * log (Ei)
Given that Si > Ei, for a SSTable being compacted, the backlog will be higher
than it should.
the following table shows how the backlog of a SSTable being compacted behaves
now versus how it's supposed to behave:
https://gist.github.com/raphaelsc/42e14be0d7d4ed264e538c2d217c8f95
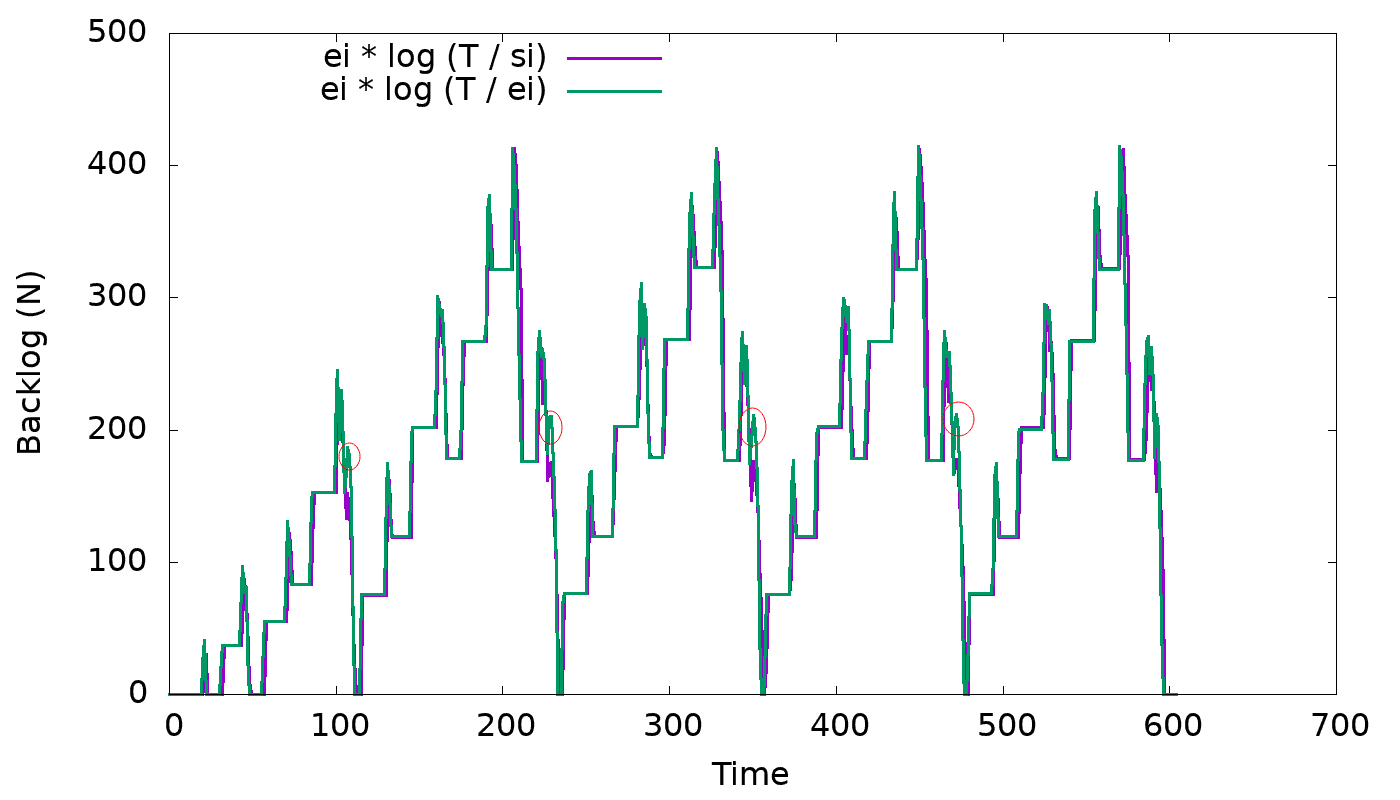
Turns out that this is not the only problem. It was a mistake to change the
formula from `Ei * log(T / Si)` to `Ei * log(T / Ei)`, when fixing the
shrinking table issue, because that also causes the backlog of a compacting
SSTable to be incorrectly reduced.
With the formula rewritten as follows:
Bi = Ei * log (T) - Ei * log (Ei)
It becomes clear that the more a SSTable is compacted, the slower it becomes
for backlog to be reduced, as T / Ei can increase considerably over time.
So we're reverting the formula back to `Ei * log(T / Si)`.
The graph below shows a better backlog behavior when table is shrinking:
https://user-images.githubusercontent.com/1409139/123495186-06a54700-d5f9-11eb-9386-3fcf4dd8e4d3.png
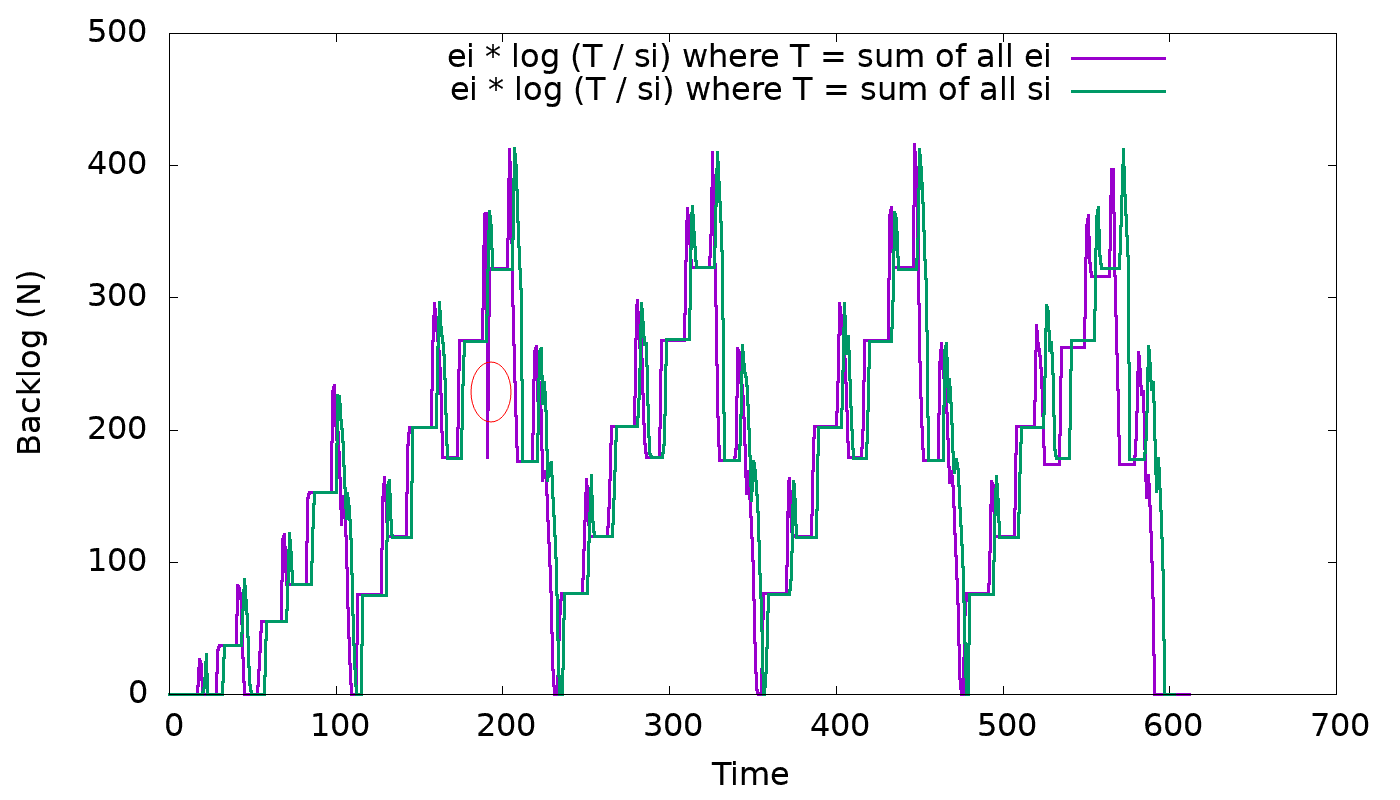
While analyzing the problem when table is shrinking, realized that it's because
T in the formula is implemented as the effective size (total + partial -
compacted).
With the new formula rewritten as follows:
Bi = Ei * log (T) - Ei * log (Si)
It becomes clearer that T cannot be lower than Si whatsoever, otherwise the
backlog becomes negative. Also, while table is shrinking, it can happen that
the backlog will be so low that compaction will barely make any progress.
To fix both issues, let's implement T as total size (sum of all Si) rather than
effective size (sum of all Ei).
The graph below shows that this change prevents the backlog from going negative
while still providing similar and expected behavior as before, see:
https://user-images.githubusercontent.com/1409139/123495185-060cb080-d5f9-11eb-89f7-ed445729702a.pngFixes#8768.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20210626003133.3011007-1-raphaelsc@scylladb.com>
It may happen that disk error opccurs and subsequent isolation runs
in parallel with drain or decommission or shutdown. In this case the
stop_transport method would be running two times in parallel. Also
the drain after decommission is not disabled, so it may happen that
stop_transport will be called two times in a row (however -- not in
parallel).
Using shared_promise solves all the possible reentrances.
(the indentation is deliberately left broken)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The stop_transport sequence is:
- stop client services (cql, thrift, alternator)
- stop gossiping
- stop messaging
- stop stream manager
The decommissioning goes very similarly
- stop client services
- stop batchlog manager
- stop gossiping
- stop messaging
So this change makes decommission stop all networking _before_
batchlog, like it's already done on drain, and additionally stop
the streaming manager.
This change is prerequisite for fixing race between transport
stop and isolation (on disk error).
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The netw command tries to access the netw::_the_messaging_service that
was removed long ago. The correct place for the messaging service is
in debug:: namespace.
The scylla-gdb test checks that, but the netw command sees that the ptr
in question is not initialized, thinks it's not yet sharded::start()-ed
and exits without errors.
tests: unit(gdb)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20210624135107.12375-1-xemul@scylladb.com>
DateTieredCompactionStrategy (DTCS) has been un-recommended for a long time
(users should use TimeWindowCompactionStrategy, TWCS, instead). This
patch adds a new configuration option - restrict_dtcs - which can be used
to restrict the ability to use DTCS in CREATE TABLE or ALTER TABLE
statements. This is part of a "safe mode" effort to allow an installation
to restrict operations which are un-recommended or dangerous.
The new restrict_dtcs option has three values: "true", "false", and "warn":
For the time being, "false" is still the default, and means DTCS is not
restricted and can still be used freely. We can easily change this
default in a followup patch.
Setting a value of "true" means that DTCS *is* restricted -
trying to create a a table or alter a table with it will fail with an error.
Setting a value of "warn" will allow the create or alter operation, but
will warn the user - both with a warning message which will immediately
appear in cqlsh (for example), and with a log message.
Fixes#8914.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Message-Id: <20210624122411.435361-1-nyh@scylladb.com>
first1 will point to the inserted value which is a copy of *first2.
Since list2 is sorted in ascending order, the next item from list2
will never be less than the one we've just inserted,
so we waste an iteration to merely increment first1 again.
Note that the standard states that no iterators or references are invalidated
on insert so we can safely keep looking at `first1` after inserting a copy of
`*first2` before it.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Check if the timeout has expired before issuing I/O.
Note that the sstable reader input_stream is not closed
when the timeout is detected. The reader must be closed anyhow after
the error bubbles up the chain of readers and before the
reader is destroyed. This might already happen if the reader
times out while waiting for reader_concurrency_semaphore admission.
Test: unit(dev), auth_test.test_alter_with_timeouts(debug)
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20210624073232.551735-1-bhalevy@scylladb.com>
The bootstrap procedure starts by "waiting for range setup", which means
waiting for a time interval specified by the `ring_delay` parameter (30s
by default) so the node can receive the tokens of other nodes before
introducing its own tokens.
However it may sometimes happen that the node doesn't receive the
tokens. There are no explicit checks for this. But the code may crash in
weird ways if the tokens-received assuption is false, and we are lucky
if it does crash (instead of, for example, allowing the node to
incorrectly bootstrap, causing data loss in the process).
Introduce an explicit check-and-throw-if-false: a bootstrapping node now
checks that there's at least one NORMAL token in the token ring, which
means that it had to have contacted at least one existing node
in the cluster, which means that it received the gossip application
states of all nodes from that node; in particular the tokens of all
nodes.
Also add an assert in CDC code which relies on that assumption
(and would cause weird division-by-zero errors if the assumption
was false; better to crash on assert than this).
Ref #8889.
Closes#8896
1) Start node n1, n2, n3
2) Bootstrap n4 and kill n4 in the middle of bootstrap
3) Wipe data on n4 and start n4 again
After step 2, n1, n2 and n3 will remove n4 from gossip after
fat_client_timeout and put n4 in quarantine for quarantine_delay().
If n4 bootstraps again in step 3 before the quarantine finishes, n1, n2
and n3 will ignore gossip updates from n4, and n4 will not learn gossip
updates from the cluster.
After PR #8896, the bootstrap will be rejected.
This patch promotes the gossip quarantine over log to info level, so
that dtest can wait for the log to bootstrap the node again.
Refs #8889
Refs #8890Closes#8905
Make some improvements to docs/alternator.md as suggested by a user who
had trouble understanding the previous version, and also a few other
random cleanups.
Closes#8910
* github.com:scylladb/scylla:
docs/alternator/alternator.md: improve "Running Alternator" section
docs/alternator/alternator.md: correct minor typos
docs/alternator/alternator.md: fix link format
Fixes#8270
If we have an allocation pattern where we leave large parts of segments "wasted" (typically because the segment has empty space, but cannot hold the mutation being added), we can have a disk usage that is below threshold, yet still get a disk footprint that is over limit causing new segment allocation to stall.
We need to take a few things into account:
1.) Need to include wasted space in the threshold check. Whether or not disk is actually used does not matter here.
2.) If we stall a segment alloc, we should just flush immediately. No point in waiting for the timer task.
3.) Need to adjust the thresholds a bit. Depending on sizes, we should probably consider start flushing once we've used up space enough to be in the last available segment, so a new one is hopefully available by the time we hit the limit.
4.) (v2) Must ensure discard/delete routines are executed. Because we can race with background disk syncs, we may need to
issue segment prunes from end_flush() so we wake up actual file deletion/recycling
5.) (v2) Shutdown must ensure discard/delete is run after we've disabled background task etc, otherwise we might fail waking up replenish and get stuck in gate
6.) (v2) Recycling or deleting segments must be consistent, regardless of shutdown. For same reason as above.
7.) (v3) Signal recycle/delete queues/promise on shutdown (with recognized marker) to handle edge case where we only have a single (allocating) segment in the list, and cannot wake up replenisher in any more civilized way.
Also fix edge case (for tests), when we have too few segment to have an active one (i.e. need flush everything).
New attempt at this, should fix intermittent shutdown deadlocks in commitlog_test.
Closes#8764
* github.com:scylladb/scylla:
commitlog_test: Add test case for usage/disk size threshold mismatch
commitlog_test: Improve test assertion
commitlog: Add waitable future for background sync/flush
commitlog: abort queues on shutdown
commitlog: break out "abort" calls into member functions
commitlog: Do explicit discard+delete in shutdown
commitlog: Recycle or not should not depend on shutdown state
commitlog: Issue discard_unused_segments on segment::flush end IFF deletable
commitlog: Flush all segments if we only have one.
commitlog: Always force flush if segment allocation is waiting
commitlog: Include segment wasted (slack) size in footprint check
commitlog: Adjust (lower) usage threshold
The helper is used to walk the tree key-by-key destroying it
in the mean time. Current implementation of this method just
uses the "regular" erasing code which actually rebalances the
tree despite the name.
The biggest problem with removing the rebalancing is that at
some point non-balanced tree may have the left-most key on an
inner node, so to make 100% rebalance-less unlink every other
method of the tree would have to be prepared for that. However,
there's an option to make "light rebalance" (as it's called in
this patch) that only maintains this crucial property of the
tree -- the left-most key is on the leaf.
Some more tech details. Current rebalancer starts when the
node population falls below 1/2 of its capacity and tries to
- grab a key from one of the siblings if it's balanced
- merge two siblings together if they are small enough
The light rebalance is lighter in two ways. First, it leaves
the node unbalanced until it becomes empty. And then it goes
ahead and replaces it with the next sibling.
This change removes ~60% of the keys movements on random test.
Keys still move when the sibling replace happens because in
this case the separation key needs to be placed at the right
sibling 0 position which means shifting all its keys right.
tests: unit(debug)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20210623083836.27491-1-xemul@scylladb.com>
_sstables_opened_but_not_loaded was needed because the old loader would
open sstables from all shards before loading them.
In the new loader, introduced with reshape, make_sstables_available()
is called on each shard after resharding and reshape finished, so
there's no need whatsoever for that mess.
Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com>
Message-Id: <20210618200026.1002621-1-raphaelsc@scylladb.com>
Move `raft_sys_table_storage_test` and `raft_address_map_test` to
`test/raft` folder since they naturally belong here, not in
`test/boost` folder.
Tests: unit(dev)
* manmanson/move_some_raft_tests_to_raft_folder:
test: raft: move `raft_address_map_test` to `raft` folder
test: raft: move `raft_sys_table_storage_test` to `raft` folder
configure: add extended raft testing dependencies
The process of getting a queue pointer is quite tricky here.
First, it checks if the vptr resolves into 'vtable for async_work_item'
and puts a None mark into known_vptrs dict.
Then, if the entry is present there are two options. First, if it's NOT
None, it's translated directly into the queue object. But if it's None,
then a loop over an offset starts that tries to check is the vptr + offset
maps to a queue. And here's the problem -- if no offsets were mapped to
any specific queues the last checked offset is put into the known vptrs
dict, so the next vptrs will miss the 2nd offset checking, but will go
ahead and use the "random" offset that had failed previously.
tests: unit(gdb)
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20210624085723.7156-1-xemul@scylladb.com>
A user complained that the "Running Alternator" section was confusing.
It didn't say outright which two configurations are necessary and you
had to read a few paragraph to reach it, and it mixed the YAML names
of options and the command-line names, which are subtly different.
This patch tries to improve this.
Sometimes an ability to force a leader change is needed. For instance
if a node that is currently serving as a leader needs to be brought
down for maintenance. If it will be shutdown without leadership
transfer the cluster will be unavailable for leader election timeout at
least.
* scylla-dev/raft-stepdown-v4:
raft: test: test leadership transfer timeout
raft: allow to initiate leader stepdown process
Rename `scylla_raft_dependencies` to `scylla_minimal_raft_dependencies`
and introduce `scylla_raft_dependencies` that contains
`scylla_core` (i.e., all scylla source files).
The new `scylla_raft_dependencies` variable will be used
for `raft_address_map_test` and `raft_sys_table_storage_test`,
which use a lot of machinery from scylla.
Signed-off-by: Pavel Solodovnikov <pa.solodovnikov@scylladb.com>
"
This series prevents broken_promise or dangling reader errors
when (resharding) compaction is stopped, e.g. during shutdown.
At the moment compaction just closes the reader unilaterally
and this yanks the reader from under the queue_reader_handle feet,
causing dangling queue reader and broken_promise errors
as seen in #8755.
Instead, fix queue_reader::close to set value on the
_full/_not_full promises and detach from the handle,
and return _consume_fut from bucket_writer::consume
if handle is terminated.
Fixes#8755
Test: unit(dev)
DTest: materialized_views_test.py:TestMaterializedViews.interrupt_build_process_and_resharding_half_to_max_test(debug)
"
* tag 'propagate-reader-abort-v3' of github.com:bhalevy/scylla:
mutation_writer: bucket_writer: consume: propagate _consume_fut if queue_reader_handle is_terminated
queue_reader_handle: add get_exception method
queue_reader: close: set value on promises on detach from handle
Unfortunately the scylla.docs.scylladb.com formatter which generates
https://scylla.docs.scylladb.com/master/alternator/alternator.html
doesn't know how to recognize HTTP URLs and convert them into proper
HTML links (something which github's formatter does).
So convert the two URLs we had in alternator.md into markdown links
which both github and our formatter recognize.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Fixes#8749
if a table::clear() was issued while we were flushing a memtable,
the memtable is already gone from list. We need to check this before
erase. Otherwise we get random memory corruption via
std::vector::erase
v2:
* Make interface more set-like (tolerate non-existance in erase).
Closes#8904
Previously, hinted handoff had a hardcoded concurrency limit - at most
128 hints could be sent from a single shard at once. This commit makes
this limit configurable by adding a new configuration option:
`max_hinted_handoff_concurrency_per_shard`. This option can be updated
in runtime. Additionally, the default concurrency per shard is made
lower and is now 8.
The motivation for reducing the concurrency was to mitigate the negative
impact hints may have on performance of the receiving node due to them
not being properly isolated with respect to I/O.
Tests:
- unit(dev)
- dtest(hintedhandoff_additional_test.py)
Refs: #8624Closes#8646
Test that if leadership transfer cannot be done in configured time frame
fsm cancels the leadership transfer process. Also check that timeout_now
message is resent on each tick while leadership transfer is in progress.
Sometimes an ability to force a leader change is needed. For instance
if a node that is currently serving as a leader needs to be brought
down for maintenance. If it will be shutdown without leadership
transfer the cluster will be unavailable for leader election timeout at
least.
We already have a mechanism to transfer the leadership in case an active
leader is removed. The patch exposes it as an external interface with a
timeout period. If a node is still a leader after the timeout the
operation will fail.
This is a more informative name. Helps see that, say, group0
is a separate service and not bundle all raft services together.
Message-Id: <20210619211412.3035835-3-kostja@scylladb.com>
Fixes#8733
If a memtable flush is still pending when we call table::clear(),
we can end up doing a "discard-all" call to commitlog, followed
by a per-segment-count (using rp_set) _later_. This will foobar
our internal usage counts and quite probably cause assertion
failures.
Fixed by always doing per-memtable explicit discard call. But to
ensure this works, since a memtable being flushed remains on
memtable list for a while (why?), we must also ensure we clear
out the rp_set on discard.
v3:
* Fix table::clear to discard rp_sets before memtables
Closes#8894
Listing /etc/systemd/system/*.mount as ghost file seems incorrect,
since user may want to keep using RAID volume / coredump directory after
uninstalling Scylla, or user may want to upgrade enterprise version.
Also, we mixed two types of files as ghost file, it should handle differently:
1. automatically generated by postinst scriptlet
2. generated by user invoked scylla_setup
The package should remove only 1, since 2 is generated by user decision.
See scylladb/scylla-enterprise#1780
Closes#8810
Commitlog timer issues un-waited syncs on all segments. If such
a sync takes too long we can end up keeping a segment alive across
a shutdown, causing the file to be left on disk, even if actually
clean.
This adds a future in segment_manager that is "chained" with all
active syncs (hopefully just one), and ensures we wait for this
to complete in shutdown, before pruning and deleting segments
Currently we capture the snapshot mutation_source by reference
for calling create_underlying_reader after closing the reader.
However, if close_reader yields, the snapshot reference passed
may be gone, so capture it by value instead.
Fixes#8848
Test: unit(dev)
DTest: restore_snapshot_using_old_token_ownership_test(debug)
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Message-Id: <20210613104232.634621-1-bhalevy@scylladb.com>
{kind=link}
{kind=link}
{kind=link}