This PR removes some restrictions classes and replaces them with expression. * `single_column_restriction` has been removed altogether. * `partition_key_restrictions` field inside `statement_restrictions` has been replaced with `expression` `clustering_key_restrictions` are not replaced yet, but this PR already has 30 commits so it's probably better to merge this before adding any more changes. Luckily most of these commits are implementations of small helper functions. `single_column_restriction` was pretty easy to remove. This class holds the `expression` that describes the restriction and `column_definition` of the restricted column. It inherits from `restriction` - the base class of all restrictions. I wasn't able to replace it with plain `expression` just yet, because a lot of times a `shared_ptr<single_column_restriction>` is being cast to `shared_ptr<restriction>`. Instead I replaced all instances of `single_column_restriction` with `restriction`. To decide if a `restriction` is a `single_column_restriction` we can use a helper method that works on expressions. Same with acquiring the restricted `column_definition`. This change has two advantages: * One less restriction class -> moving towards 0 * Preparing towards one generic `restriction/expression` type and using functions to distinguish the type of expression that we're dealing with. `partition_key_restrictions` is a class used to keep restrictions on the partition key inside `statement_restrictions`. Removing it required two major steps. First I had to implement taking all the binary operators and making sure that they are valid together. Before the change this was the `merge_to` method. It ensures that for example there are no token and regular restrictions occurring at the same time. This has been implemented as `statement_restrictions::add_restriction`. It detects which case it's dealing with and mimics `merge_to` from the right restrictions class. Then I implemented all methods of `partition_key_restrictions` but operating on plain `expressions`. While doing that I was able to gradually shift the responsibility to the brand new functions. Finally `partition_key_restrictions` wasn't used anywhere at all and I was able to remove it. Here's the inheritance tree of all restriction classes for context: 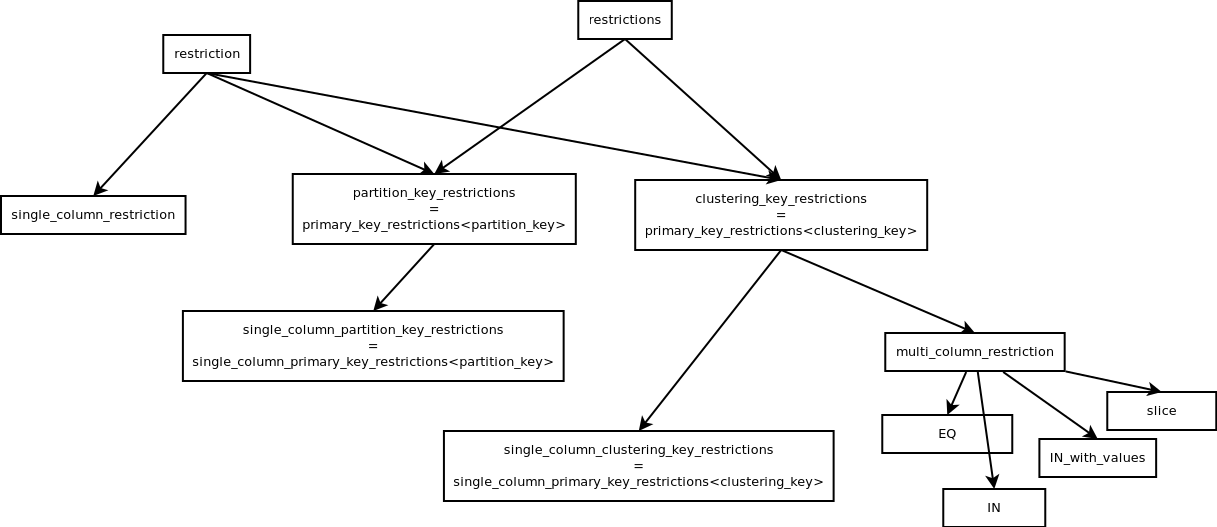 For now this is marked as a draft. I just put all this together in a readable way and wanted to put it out for you to see. I will have another look at the code and maybe do some improvements. Closes #10910 * github.com:scylladb/scylla: cql3: Remove _new from _new_partition_key_restrictions cql3: Remove _partition_key_restrictions from statement_restrictions cql3: Use expression for index restrictions cql3: expr: Add contains_multi_column_restriction cql3: Add expr::value_for cql3: Use the new restrictions map in another place cql3: use the new map in get_single_column_partition_key_restrictions cql3: Keep single column restrictions map inside statement restrictions cql3: Use expression instead of _partition_key_restrictions in the remaining code cql3: Replace partition_key_restrictions->has_supporting_index() cql3: Replace statement_restrictions->get_column_defs() cql3: Replace partition_key_restrictions->needs_filtering() cql3: Replace partition_key_restrictions->size() cql3: Replace partition_key_restrictions->is_all_eq() cql3: Replace parition_key_restriction->has_unrestricted_components() cql3: Replace parition_key_restrictions->empty() cql3: Keep restrictions as expressions inside statement_restrictions cql3: Handle single value INs inside prepare_binary_operator cql3: Add get_columns_in_commons cql3: expr: Add is_empty_restriction cql3: Replicate column sorting functionality using expressions cql3: Remove single_column_restriction class cql3: Replace uses of single_column_restriction with restriction cql3: expr: Add get_the_only_column cql3: expr: Add is_single_column_restriction cql3: expr: Add for_each_expression cql3: Remove some unsued methods
{kind=link}
Scylla
![]()

What is Scylla?
Scylla is the real-time big data database that is API-compatible with Apache Cassandra and Amazon DynamoDB. Scylla embraces a shared-nothing approach that increases throughput and storage capacity to realize order-of-magnitude performance improvements and reduce hardware costs.
For more information, please see the ScyllaDB web site.
Build Prerequisites
Scylla is fairly fussy about its build environment, requiring very recent versions of the C++20 compiler and of many libraries to build. The document HACKING.md includes detailed information on building and developing Scylla, but to get Scylla building quickly on (almost) any build machine, Scylla offers a frozen toolchain, This is a pre-configured Docker image which includes recent versions of all the required compilers, libraries and build tools. Using the frozen toolchain allows you to avoid changing anything in your build machine to meet Scylla's requirements - you just need to meet the frozen toolchain's prerequisites (mostly, Docker or Podman being available).
Building Scylla
Building Scylla with the frozen toolchain dbuild is as easy as:
$ git submodule update --init --force --recursive
$ ./tools/toolchain/dbuild ./configure.py
$ ./tools/toolchain/dbuild ninja build/release/scylla
For further information, please see:
- Developer documentation for more information on building Scylla.
- Build documentation on how to build Scylla binaries, tests, and packages.
- Docker image build documentation for information on how to build Docker images.
Running Scylla
To start Scylla server, run:
$ ./tools/toolchain/dbuild ./build/release/scylla --workdir tmp --smp 1 --developer-mode 1
This will start a Scylla node with one CPU core allocated to it and data files stored in the tmp directory.
The --developer-mode is needed to disable the various checks Scylla performs at startup to ensure the machine is configured for maximum performance (not relevant on development workstations).
Please note that you need to run Scylla with dbuild if you built it with the frozen toolchain.
For more run options, run:
$ ./tools/toolchain/dbuild ./build/release/scylla --help
Testing
See test.py manual.
Scylla APIs and compatibility
By default, Scylla is compatible with Apache Cassandra and its APIs - CQL and Thrift. There is also support for the API of Amazon DynamoDB™, which needs to be enabled and configured in order to be used. For more information on how to enable the DynamoDB™ API in Scylla, and the current compatibility of this feature as well as Scylla-specific extensions, see Alternator and Getting started with Alternator.
Documentation
Documentation can be found here. Seastar documentation can be found here. User documentation can be found here.
Training
Training material and online courses can be found at Scylla University. The courses are free, self-paced and include hands-on examples. They cover a variety of topics including Scylla data modeling, administration, architecture, basic NoSQL concepts, using drivers for application development, Scylla setup, failover, compactions, multi-datacenters and how Scylla integrates with third-party applications.
Contributing to Scylla
If you want to report a bug or submit a pull request or a patch, please read the contribution guidelines.
If you are a developer working on Scylla, please read the developer guidelines.
Contact
- The users mailing list and Slack channel are for users to discuss configuration, management, and operations of the ScyllaDB open source.
- The developers mailing list is for developers and people interested in following the development of ScyllaDB to discuss technical topics.