Port the bug fix terra-money#76 to upstream. This is critical for ethermint json-rpc to work.
fix: prevent duplicate tx index if it succeeded before
fix: use CodeTypeOk instead of 0
fix: handle duplicate txs within the same block
Co-authored-by: jess jesse@soob.co
ref: #5281
Co-authored-by: M. J. Fromberger <fromberger@interchain.io>
This test was made flakey by #8839. The cooldown period means that the node in the test will not try to reconnect as quickly as the test expects. This change makes the cooldown shorter in the test so that the node quickly reconnects.
I think we were leaving this library public because the SDK dependend
upon it, but the function the SDK was using was one that we'd removed
because *we* weren't using it any more, and I made a PR agasint the
SDK to clean that up.
ref: https://github.com/cosmos/cosmos-sdk/pull/12368
These timeouts default to 'do not time out' if they are not set. This times up resources, potentially indefinitely. If node on the other side of the the handshake is up but unresponsive, the[ handshake call](edec79448a/internal/p2p/router.go (L720)) will _never_ return.
These are proposed values that have not been validated. I intend to validate them in a production setting.
The dial routines perform network i/o, which is a blocking call into the kernel. These routines are completely unable to do anything else while the dial occurs, so for most of their lifecycle they are sitting idle waiting for the tcp stack to hand them data. We should increase this value by _a lot_ to enable more concurrent dials. This is unlikely to cause CPU starvation because these routines sit idle most of the time. The current value causes dials to occur _way_ too slowly.
Below is a graph demonstrating the before and after of this change in a testnetwork with many dead peers. You can observe that the rate that we connect to new, valid peers, is _much_ higher than previously. Change was deployed around the 31 minute mark on the graph.
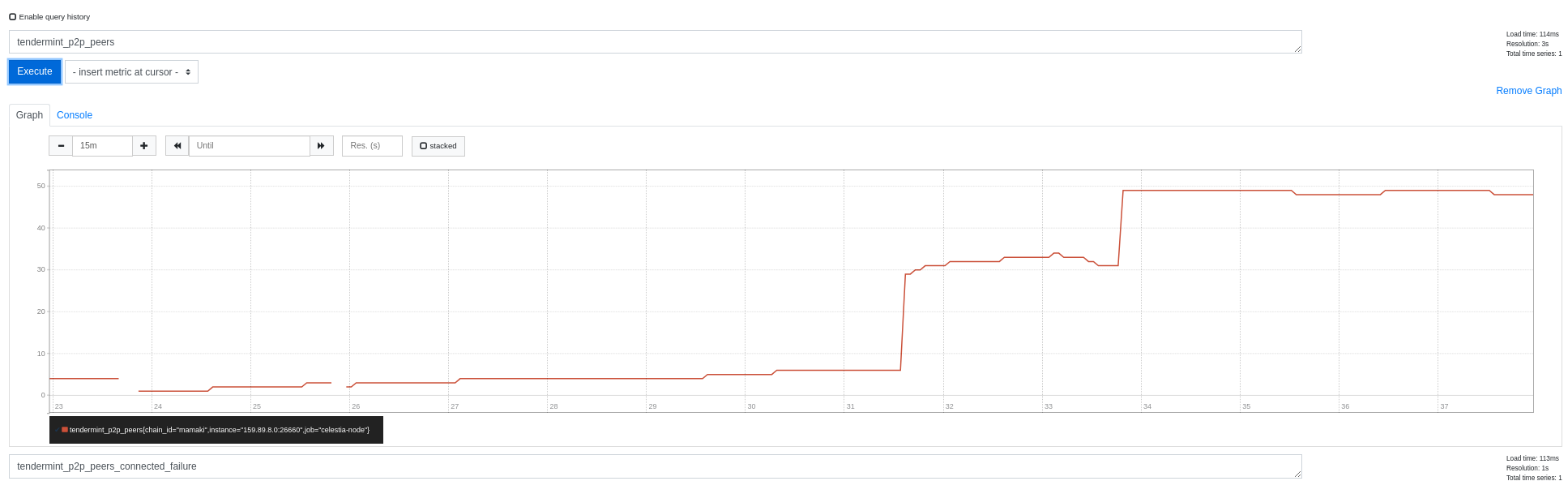
Closes#8069
* Type `ABCIResponses` was just wrapping type `ResponseFinalizeBlock`. This patch removes the former.
* Did some renaming to avoid confusion on the data structure we are working with.
* We also remove any stale ABCIResponses we may have in the state store at the time of pruning
**IMPORTANT**: There is an undesirable side-effect of the unwrapping. An empty `ResponseFinalizeBlock` yields a 0-length proto-buf serialized buffer. This was not the case with `ABCIResponses`. I have added an interim solution, but open for suggestions on more elegant ones.
* abci:mempoolError from ResponseCheckTx
* responseCheckTx returns an error if Tendermint decides not to accept an app after CheckTx
*updated spec, upgrading.md and changelog.md
This pull requests adds the protocol buffer field for the `ABCI.VoteExtensionsEnableHeight` parameter. This proto field is threaded throughout all of the relevant places where consensus params are used and referenced.
This PR also adds validation of the consensus param updates. Previous consensus param changes didn't depend on _previous_ versions of the params, so this change adds a method for validating against the old params as well.
closes: #8453
This PR makes vote extensions optional within Tendermint. A new ConsensusParams field, called ABCIParams.VoteExtensionsEnableHeight, has been added to toggle whether or not extensions should be enabled or disabled depending on the current height of the consensus engine. Related to: #8453
Closes: #8575
This PR aims to fix the `LastCommitRound can only be negative for initial height 0` issue we see in the e2e tests by initializing the `state` object before starting the receive routines in the consensus reactor. This is somewhat inelegant, but it should fix the issue.
* Fix lock sequencing in socket client request tracking.
It is not safe to check base service state (IsRunning) while holding the lock
for the client state. If we do, then during shutdown we may deadlock with the
invocation of the OnStop handler, which the base service executes while holding
the service lock.
* Enqueue pending requests before sending them to the server.
If we don't do this, the server can reply before the request lands in the
queue. That will cause the receiver to terminate early for an unsolicited
response. So enqueue first: This is safe because we're doing it in the same
routine as services the channel, so we won't take another message till we are
safely past that point.
* Document what we did.
* Fix socket paths in tests.
{kind=link}