This is (#8446) pulled from the `main/libp2p` branch but without any
of the libp2p content, and is perhaps the easiest first step to enable
pluggability at the peer layer, and makes it possible hoist shims
(including for, say 0.34) into tendermint without touching the reactors.
This test was made flakey by #8839. The cooldown period means that the node in the test will not try to reconnect as quickly as the test expects. This change makes the cooldown shorter in the test so that the node quickly reconnects.
These timeouts default to 'do not time out' if they are not set. This times up resources, potentially indefinitely. If node on the other side of the the handshake is up but unresponsive, the[ handshake call](edec79448a/internal/p2p/router.go (L720)) will _never_ return.
These are proposed values that have not been validated. I intend to validate them in a production setting.
The dial routines perform network i/o, which is a blocking call into the kernel. These routines are completely unable to do anything else while the dial occurs, so for most of their lifecycle they are sitting idle waiting for the tcp stack to hand them data. We should increase this value by _a lot_ to enable more concurrent dials. This is unlikely to cause CPU starvation because these routines sit idle most of the time. The current value causes dials to occur _way_ too slowly.
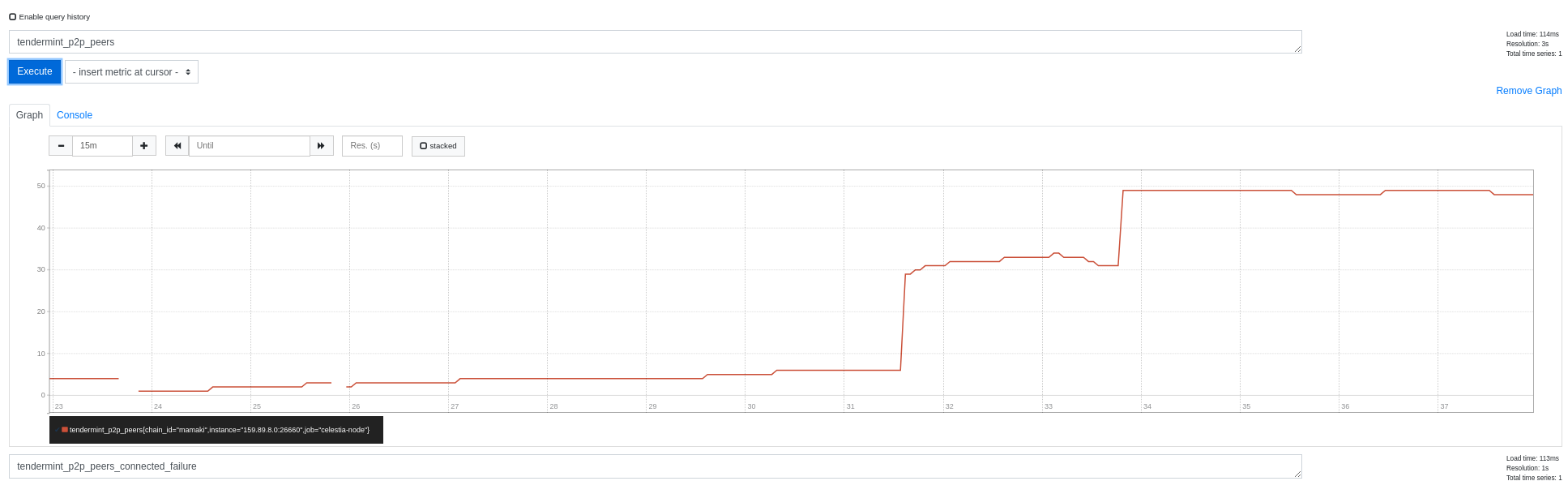
Below is a graph demonstrating the before and after of this change in a testnetwork with many dead peers. You can observe that the rate that we connect to new, valid peers, is _much_ higher than previously. Change was deployed around the 31 minute mark on the graph.
## What does this change do?
This pull request completes the change to the `metricsgen` metrics. It adds `go generate` directives to all of the files containing the `Metrics` structs.
Using the outputs of `metricsdiff` between these generated metrics and `master`, we can see that there is not a diff between the two sets of metrics when run locally.
```
[william@sidewinder] tendermint[wb/metrics-gen-transition]:. ◆ ./scripts/metricsgen/metricsdiff/metricsdiff metrics_master metrics_generated
[william@sidewinder] tendermint[wb/metrics-gen-transition]:. ◆
```
This change also adds parsing for a `metrics:` key in a field comment. If a comment line begins with `//metrics:` the rest of the line is interpreted to be the metric help text. Additionally, a bug where lists of labels were not properly quoted in the `metricsgen` rendered output was fixed.
The p2p/conn library was using a build patch to work around an old issue with
the net.Conn type that has not existed since Go 1.10. Remove the workaround and
update usage to use the standard net.Pipe directly.
This contains two major changes:
- Remove the legacy test logging method, and just explicitly call the
noop logger. This is just to make the test logging behavior more
coherent and clear.
- Move the logging in the light package from the testing.T logger to
the noop logger. It's really the case that we very rarely need/want
to consider test logs unless we're doing reproductions and running a
narrow set of tests.
In most cases, I (for one) prefer to run in verbose mode so I can
watch progress of tests, but I basically never need to consider
logs. If I do want to see logs, then I can edit in the testing.T
logger locally (which is what you have to do today, anyway.)
The message handling in this reactor is all under control of the reactor
itself, and does not call out to callbacks or other externally-supplied code.
It doesn't need to check for panics.
- Remove an irrelevant channel ID check.
- Remove an unnecessary panic recovery wrapper.
The PEX reactor has a simple feedback control mechanism to decide how often to
poll peers for peer address updates. The idea is to poll more frequently when
knowledge of the network is less, and decrease frequency as knowledge grows.
This change solves two problems:
1. It is possible in some cases we may poll a peer "too often" and get dropped
by that peer for spamming.
2. The first successful peer update with any content resets the polling timer
to a very long time (10m), meaning if we are unlucky in getting an
incomplete reply while the network is small, we may not try again for a very
long time. This may contribute to difficulties bootstrapping sync.
The main change here is to only update the interval when new information is
added to the system, and not (as before) whenever a request is sent out to a
peer. The rate computation is essentially the same as before, although the code
has been a bit simplified, and I consolidated some of the error handling so
that we don't have to check in multiple places for the same conditions.
Related changes:
- Improve error diagnostics for too-soon and overflow conditions.
- Clean up state handling in the poll interval computation.
- Pin the minimum interval avert a chance of PEX spamming a peer.
This is a little coarse, but the idea is that we'll send information
about the channels a peer has upon the peer-up event that we send to
reactors that we can then use to reject peers (if neeeded) from reactors.
This solves the problem where statesync would hang in test networks
(and presumably real) where we would attempt to statesync from seed
nodes, thereby hanging silently forever.
{kind=link}