std_deque implementation was broken, with __len__() and __iter__()
disagreeing about the size of the container. Turns out both are wrong in
certain situations. Fix the iteration logic and re-base both __len__()
and __iter__() on the same node iteration code to prevent future
disagreements.
This new test suite is expected to gather all kinds of permissions
tests - granting, revoking, authorizing, and so on.
Right now it contains a single minimal test which ensures that
the default superuser can be granted applicable permissions,
which they already have anyway.
The test suite added in this pull request will also be useful
when developing #10633 - permissions for UDF/UDA infrastructure.
Closes#10991
* github.com:scylladb/scylla:
cql-pytest: add initial permissions test suite
cql-pytest: enable CassandraAuthorizer for Scylla and Cassandra
There was a bug which caused incorrect results of limits()
for columns with reversed clustering order.
Such columns have reversed_type as their type and this
needs to be taken into account when comparing them.
It was introduced in 6d943e6cd0.
This commit replaced uses of get_value_comparator
with type_of. The difference between them is that
get_value_comparator applied ->without_reversed()
on the result type.
Because the type was reversed, comparisons like
1 < 2 evaluated to false.
This caused the test testIndexOnKeyWithReverseClustering
to fail, but sadly it wasn't caught by CI because
the CI itself has a bug that makes it skip some tests.
The test passes now, although it has to be run manually
to check that.
Fixes: #10918
Signed-off-by: cvybhu <jan.ciolek@scylladb.com>
Closes#10994
Scylla's coding standard requires that each header is self-sufficient,
i.e., it includes whatever other headers it needs - so it can be included
without having to include any other header before it.
We have a test for this, "ninja dev-headers", but it isn't run very
frequently, and it turns out our code deviated from this requirement
in a few places. This patch fixes those places, and after it
"ninja dev-headers" succeeds again.
Fixes#10995
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10997
Currently, applying schema mutations involves flushing all schema
tables so that on restart commit log replay is performed on top of
latest schema (for correctness). The downside is that schema merge is
very sensitive to fdatasync latency. Flushing a single memtable
involves many syncs, and we flush several of them. It was observed to
take as long as 30 seconds on GCE disks under some conditions.
This patch changes the schema merge to rely on a separate commit log
to replay the mutations on restart. This way it doesn't have to wait
for memtables to be flushed. It has to wait for the commitlog to be
synced, but this cost is well amortized.
We put the mutations into a separate commit log so that schema can be
recovered before replaying user mutations. This is necessary because
regular writes have a dependency on schema version, and replaying on
top of latest schema satisfies all dependencies. Without this, we
could get loss of writes if we replay a write which depends on the
latest schema on top of old schema.
Also, if we have a separate commit log for schema we can delay schema
parsing for after the replay and avoid complexity of recognizing
schema transactions in the log and invoking the schema merge logic.
I reproduced bad behavior locally on my machine with a tired (high latency)
SSD disk, load driver remote. Under high load, I saw table alter (server-side part) taking
up to 10 seconds before. After the patch, it takes up to 200 ms (50:1 improvement).
Without load, it is 300ms vs 50ms.
Fixes#8272Fixes#8309Fixes#1459Closes#10333
* github.com:scylladb/scylla:
config: Introduce force_schema_commit_log option
config: Introduce unsafe_ignore_truncation_record
db: Avoid memtable flush latency on schema merge
db: Allow splitting initiatlization of system tables
db: Flush system.scylla_local on change
migration_manager: Do not drop system.IndexInfo on keyspace drop
Introduce SCHEMA_COMMITLOG cluster feature
frozen_mutation: Introduce freeze/unfreeze helpers for vectors of mutations
db/commitlog: Improve error messages in case of unknown column mapping
db/commitlog: Fix error format string to print the version
db: Introduce multi-table atomic apply()
Convert most use sites from `co_return coroutine::make_exception`
to `co_await coroutine::return_exception{,_ptr}` where possible.
In cases this is done in a catch clause, convert to
`co_return coroutine::exception`, generating an exception_ptr
if needed.
Signed-off-by: Benny Halevy <bhalevy@scylladb.com>
Closes#10972
This new test suite is expected to gather all kinds of permissions
tests - granting, revoking, authorizing, and so on.
Right now it contains a single minimal test which ensures that
the default superuser can be granted applicable permissions,
which they already have anyway.
In order to be able to test permissions, an authorizer different
than AllowAllAuthorizer (default) must be set.
CassandraAuthorizer is thus enabled - it works on default user/password
pair, so it doesn't introduce any regressions to the test suite.
"
The option controlls the IO bandwidth of the compaction sched class.
It's not set to be 16MB/s, but is unused. This set makes it 0 by
default (which means unlimited), live-updateable and plugs it to the
seastar sched group IO throttling.
branch: https://github.com/xemul/scylla/tree/br-compaction-throttling-3
tests: unit(dev),
v2: https://jenkins.scylladb.com/job/releng/job/Scylla-CI/1010/ ,
v2: manual config update
"
* 'br-compaction-throttling-3-a' of https://github.com/xemul/scylla:
compaction_manager: Add compaction throughput limit
updateable_value: Support dummy observing
serialized_action: Allow being observer for updateable_value
config: Tune the config option
The node now refuses to boot if schema tables were truncated.
This adds a config option to ignore truncation records as a
workaround if user truncated them manually.
Currently, applying schema mutations involves flushing all schema
tables so that on restart commit log replay is performed on top of
latest schema (for correctness). The downside is that schema merge is
very sensitive to fdatasync latency. Flushing a single memtable
involves many syncs, and we flush several of them. It was observed to
take as long as 30 seconds on GCE disks under some conditions.
This patch changes the schema merge to rely on a separate commit log
to replay the mutations on restart. This way it doesn't have to wait
for memtables to be flushed. It has to wait for the commitlog to be
synced, but this cost is well amortized.
We put the mutations into a separate commit log so that schema can be
recovered before replaying user mutations. This is necessary because
regular writes have a dependency on schema version, and replaying on
top of latest schema satisfies all dependencies. Without this, we
could get loss of writes if we replay a write which depends on the
latest schema on top of old schema.
Also, if we have a separate commit log for schema we can delay schema
parsing for after the replay and avoid complexity of recognizing
schema transactions in the log and invoking the schema merge logic.
One complication with this change is that replay_position markers are
commitlog-domain specific and cannot cross domains. They are recorded
in various places which survive node restart: sstables are annotated
with the maximum replay position, and they are present inside
truncation records. The former annotation is used by "truncate"
operation to drop sstables. To prevent old replay positions from being
interpreted in the context in the new schema commitlog domain, the
change refuses to boot if there are truncation records, and also
prohibits truncation of schema tables.
The boot sequence needs to know whether the cluster feature associated
with this change was enabled on all nodes. Fetaures are stored in
system.scylla_local. Because we need to read it before initializing
schema tables, the initialization of tables now has to be split into
two phases. The first phase initializes all system tables except
schema tables, and later we initialize schema tables, after reading
stored cluster features.
The commitlog domain is switched only when all nodes are upgraded, and
only after new node is restarted. This is so that we don't have to add
risky code to deal with hot-switching of the commitlog domain. Cold
switching is safer. This means that after upgrade there is a need for
yet another rolling restart round.
Fixes#8272Fixes#8309Fixes#1459
It's not needed anymore because system.IndexInfo is a virtual table
calculated from view info.
The drop accesses a table which is outside system_schema keyspace
so crosses commit log domain. This will trigger an internal from
database::apply() on schema merge once the code switches to use
the schema commit log and require that all mutations which are
part of the schema change belong to a single commit log domain.
We could theoretically move system.IndexInfo to the schema commit log
domain. It's not easy though because table initialization at boot
needs to be split, and current functions for initailization work
at keyspace granularity, not table granularity.
Leader which ceases to be a leader as a result of a
execute_modify_config cannot wait for a dummy record to be
committed because io_fiber aborts current waiters as soon as it
detects a lost of leadership.
This commit excludes dummy entries from the configuration change
procedure. A special promise is set on io_fiber when it gets a
non-joint configuration, and set_configuration just waits for
the corresponding future instead of a dummy record.
Fixes: #10010Closes#10905
This reverts commit aa8f135f64, reversing
changes made to 9a88bc260c. The patch
causes hangs during flush.
Also reverts parts of 411231da75 that impacted the unit test.
Fixes#10897.
In a large cluster, a node would receive frequent and periodic gossip
application state updates like CACHE_HITRATES or VIEW_BACKLOG from peer
nodes. Those states are not critical. They should not be counted for the
_msg_processing counter which is used to decide if gossip is settled.
This patch fixes the long settle on every restart issue reported by
users.
Refs #10337Closes#10892
Re-use eisting compaction_throughput_mb_per_sec option, push it down to
compaction manager via config and update the nderlying compaction sched
class when the option is (live)updated.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
An updateable_value() may come without source attached. One of the
options how this can happen is if the value sits on a service config.
It's a good option to make the config have some default initialization
for the option, but in this case observe()ing an option by the service
would step on null pointer dereference.
Said that, if a value without source is tried to be observed -- assume
that it's OK, but the value would never change, so a dummy observer is
to be provided.
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Live-updating an option may involve running some action when the option
changes, not just getting its new value into somewhere. The action is
nice to be run as serialized action to batch config updates.
Said that, here's a sugar to write
serialized_action _foo = [this] { return foo(); };
observer<> _o = option.observe(_foo.make_observer());
instead of
serialized_action _foo = [this] { return foo(); };
observer<> _o = option.observe([this] {
// waited with .join on stop
(void)_foo.trigger();
});
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Native types were parsed directly to data_type, where varchar and text were
parsed to utf8_type. To get the name of the type there was a call to
the data_type method thus getting the name of the varchar type returns "text".
To fix this, added new nonterminal type_unreserved_keyword, which parse native
types to their names. It replaced native_or_internal_type in unreserved_function_keyword.
unreserved_function_keyword is also used to parse usernames, keyspace names, index names,
column identifieres, service levels and role names, so this bug was repaired also in them.
Fixes: #10642Closes#10960
Recently a change to Scylla's expression implementation changed the standard
error message copied from Cassandra:
Cannot execute this query as it might involve data filtering and thus
may have unpredictable performance. If you want to execute this query
despite the performance unpredictability, use ALLOW FILTERING
In the special case where the filter is on the partition key, we changed
the message to:
Only EQ and IN relation are supported on the partition key (unless you
use the token() function or allow filtering)
We had a cql-pytest test translated from Cassandra's unit test that checked
the old message, and started to fail. Unfortunately nobody noticed because
a bug in test.py caused it to stop running these translated unit tests.
So in this patch, we trivially fix the test to pass again. Instead of
insisting on the old message, we check jsut for the string "allow
filtering", in lowercase or uppercase. After this patch, the tests
passes as expected on both Scylla and Cassandra.
Refs #10918 (this test failing is one of the failures reported there)
Refs #10962 (test.py stopped running this test)
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10964
Current debug log is bit difficult to collect in CI, to find the debug log
we must know which script caused Exception.
Because the filename does not include prefix, and also specified
directory is shared with other programs.
To make things more easily, let's change debug log directory to /var/tmp/scylla.
Closes#10730
This mini-series adds an _async_gate to storage_service that is closed on stop()
and it performs restore_replica_count under this gate so it can be orderly waited on in stop()
Fixes#10672Closes#10922
* github.com:scylladb/scylla:
storage_service: handle_state_removing: restore_replica_count under _async_gate
storage_service: add async_gate for background work
A recent change added `--security-opt label:disable` to the docker
options. There are examples of this syntax on the web, but podman
and docker manuals don't mention it and it doesn't work on my machine.
Fix it into `--security-opt label=disable`, as described by the manuals.
Closes#10965
Adds measuring the apparent delta vector of footprint added/removed within
the timer time slice, and potentially include this (if influx is greater
than data removed) in threshold calculation. The idea is to anticipate
crossing usage threshold within a time slice, so request a flush slightly
earlier, hoping this will give all involved more time to do their disk
work.
Obviously, this is very akin to just adjusting the threshold downwards,
but the slight difference is that we take actual transaction rate vs.
segment free rate into account, not just static footprint.
Note: this is a very simplistic version of this anticipation scheme,
we just use the "raw" delta for the timer slice.
A more sophisiticated approach would perhaps do either a lowpass
filtered rate (adjust over longer time), or a regression or whatnot.
But again, the default persiod of 10s is something of an eternity,
so maybe that is superfluous...
Closes#10651
* github.com:scylladb/scylla:
commitlog: Add (internal) measurement of byte rates add/release/flush-req
commitlog: Add counters for # bytes released/flush requested
commitlog: Keep track of last flush high position to avoid double request
commitlog: Fix counter descriptor language
"
On stop there's a rather long log-less gap in the middle of
storage_service::drain_on_shutdown(). This set adds log in
interesting places and while at it tosses the patched code.
refs: #10941
"
* 'br-shutdown-logging' of https://github.com/xemul/scylla:
batchlog_manager: Add drain and stop logging
batchlog_manager: Coroutinize drain and stop
batchlog_manager: Drain it with shared future
commitlog: Add shutdown message
database: Move flushing logging
compaction_manager: Add logging around drain
compaction_manager: Coroutinize drain
storage_service: Sanitize stop_transport()
Google group started replacing sender email with the group email
recently. Here's the list of spoiled entries combined from seastar
and scylla repos
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20220701160252.11967-1-xemul@scylladb.com>
This is not identical change, if drain() resolves with exception we end
up skipping the gate closing, but since it's stop why bother
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
The .drain() method can be called from several places, each needs to
wait for its completion. Now this is achieved with the help of a gate,
but there's a simpler way
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
It happens in database::drain(), we know when it starts after keyspaces
are flushed, now it's good to know when it completes
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Now it happens before calling database::drain() but drain is not only
flushing it does lots of other things. More elaborated logging is better
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
with several Java versions
The test/cql-pytest/run-cassandra script runs our cql-pytest tests against
Cassandra. Today, Cassandra can only run correctly on Java 8 or 11
(see https://issues.apache.org/jira/browse/CASSANDRA-16895) but recent
Linux distributions have switched to newer versions of Java - e.g., on
my Fedora 36 installation, the default "java" is Java 17. Which can't
run Cassandra.
So what I do in this patch is to check if "java" has the right version,
and if it doesn't, it looks at several additional locations if it can
find a Java of the right version. By the way, we are sure that Java 8
must be installed because our install-dependencies.sh installs it.
After this patch, test/cql-pytest/run-cassandra resumes working on
Fedora 36.
Fixes#10946
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10947
Method reponsible for creating a token of given values is not meant to be
used with empty optionals. Thus, having requested a token of the columns
containing null values resulted with an exception being thrown. This kind
of behaviour was not compatible with the one applied in cassandra.
To fix this, before the computation of a token, it is checked whether
no null value is contained. If any value in the processed vector is null,
null value is returned.
Fixes: #10594Closes#10942
If a single-patch pull request fails cherry-picking, it's still possible
to recover it (if it's a simple conflict). Give the maintainer the option
by opening a subshell and instructing them to either complete the cherry-pick
or abort it.
Closes#10949
* seastar 9c016aeebf...7d8d846b26 (16):
> Merge 'coroutine: exception: retain exception_ptr type' from Benny Halevy
> core: log in on_internal_error even when throwing
> sched_group: Report the sched group that exceeded the limit
Fixes#8226.
> Add .mailmap
> prometheus: make the help string optional
> core: lw_shared_ptr: allow defining `lw_shared_ptr<T>` class member without knowing the definition of `T`
> ci: build and test in debug and dev modes
> Merge 'Added summaries, remove empty, and aggregation to Prometheus' from Amnon Heiman
> Merge 'net/tls: vec_push: call on_internal_error if _output_pending already failed' from Benny Halevy
Fixes#10127
> Merge 'CI: build and test with both gcc and clang ' from Beni Peled
> Merge "Initialize lowres_clock::_now earlier" from Pavel E
Ref #10743
> reactor: don't count make_exception_future etc. in cpp_exceptions metric
> file: Deprecate file lifetime hint calls
> foreign_ptr: fix doc.
> cmake: fix mention of FindLibUring.cmake in install target
> semaphore: derive named_semaphore_aborted exception from semaphore_aborted
Fixes#10666.
Closes#10951
In order to allow our Scylla OSS customers the ability to select a version for their documentation, we are migrating the Scylla docs content to the Scylla OSS repository. This PR covers the following points of the [Migration Plan](https://docs.google.com/document/d/15yBf39j15hgUVvjeuGR4MCbYeArqZrO1ir-z_1Urc6A/edit#):
1. Creates a subdirectory for dev docs: /docs/dev
2. Moves the existing dev doc content in the scylla repo to /docs/dev, but keep Alternator docs in /docs.
3. Flattens the structure in /docs/dev (remove the subfolders).
4. Adds redirects from `scylla.docs.scylladb.com/<version>/<document>` to `https://github.com/scylladb/scylla/blob/master/docs/dev/<document>.md`
5. Excludes publishing docs for /docs/devs.
1. Enter the docs folder with `cd docs`.
2. Run `make redirects`.
3. Enter the docs folder and run `make preview`. The docs should build without warnings.
4. Open http://127.0.0.1:5500 in your browser. You shoul donly see the alternator docs.
5. Open http://127.0.0.1:5500/stable/design-notes/IDL.html in your browser. It should redirect you to https://github.com/scylladb/scylla/blob/master/docs/dev/IDL.md and raise a 404 error since this PR is not merged yet.
6. Surf the `docs/dev` folder. It should have all the scylla project internal docs without subdirectories.
Closes#10873
* github.com:scylladb/scylla:
Update docs/conf.py
Update docs/dev/protocols.md
Update docs/dev/README.md
Update docs/dev/README.md
Update docs/conf.py
Fix broken links
Remove source folder
Add redirections
Move dev docs to docs/dev
After compiling to WASM, UDFs become much larger than the
source code. When they're included in test_wasm.py, it
becomes difficult to navigate in the file. Moving them
to another place does not make understanding the test
scripts harder, because the source code is still included.
This problem will become even more severe when testing
UDFs using WASI.
Signed-off-by: Wojciech Mitros <wojciech.mitros@scylladb.com>
Closes#10934
By default, Docker uses SELinux to prevent malicious code in the container
from "escaping" and touching files outside the container: The container
is only allowed to touch files with a special SELinux label, which the
outside files simply do not have. However, this means that if you want
to "mount" outside files into the container, Docker needs to add the
special label to them. This is why one needs to use the ":z" option
when mounting an outside file inside docker - it asks docker to "relabel"
the directory to be usable in Docker.
But this relabeling process is slow and potentially harmful if done to
large directories such as your home directory, where you may theoretically
have SELinux labels for other reasons. The relabling is also unnecessary -
we don't really need the SELinux protection in dbuild. Dbuild was meant
to provide a common toolchain - it was never meant to protect the build
host from a malicious build script.
The alternative we use in this patch is "--security-opt label=disable".
This allows the container to access any file in the host filesystem,
but as usual - only if it's explicitly "mounted" into the container.
All ":z" we added in the past can be removed.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10945
This PR removes some restrictions classes and replaces them with expression.
* `single_column_restriction` has been removed altogether.
* `partition_key_restrictions` field inside `statement_restrictions` has been replaced with `expression`
`clustering_key_restrictions` are not replaced yet, but this PR already has 30 commits so it's probably better to merge this before adding any more changes.
Luckily most of these commits are implementations of small helper functions.
`single_column_restriction` was pretty easy to remove. This class holds the `expression` that describes the restriction and `column_definition` of the restricted column.
It inherits from `restriction` - the base class of all restrictions.
I wasn't able to replace it with plain `expression` just yet, because a lot of times a `shared_ptr<single_column_restriction>` is being cast to `shared_ptr<restriction>`.
Instead I replaced all instances of `single_column_restriction` with `restriction`.
To decide if a `restriction` is a `single_column_restriction` we can use a helper method that works on expressions.
Same with acquiring the restricted `column_definition`.
This change has two advantages:
* One less restriction class -> moving towards 0
* Preparing towards one generic `restriction/expression` type and using functions to distinguish the type of expression that we're dealing with.
`partition_key_restrictions` is a class used to keep restrictions on the partition key inside `statement_restrictions`.
Removing it required two major steps.
First I had to implement taking all the binary operators and making sure that they are valid together.
Before the change this was the `merge_to` method. It ensures that for example there are no token and regular restrictions occurring at the same time.
This has been implemented as `statement_restrictions::add_restriction`.
It detects which case it's dealing with and mimics `merge_to` from the right restrictions class.
Then I implemented all methods of `partition_key_restrictions` but operating on plain `expressions`.
While doing that I was able to gradually shift the responsibility to the brand new functions.
Finally `partition_key_restrictions` wasn't used anywhere at all and I was able to remove it.
Here's the inheritance tree of all restriction classes for context:
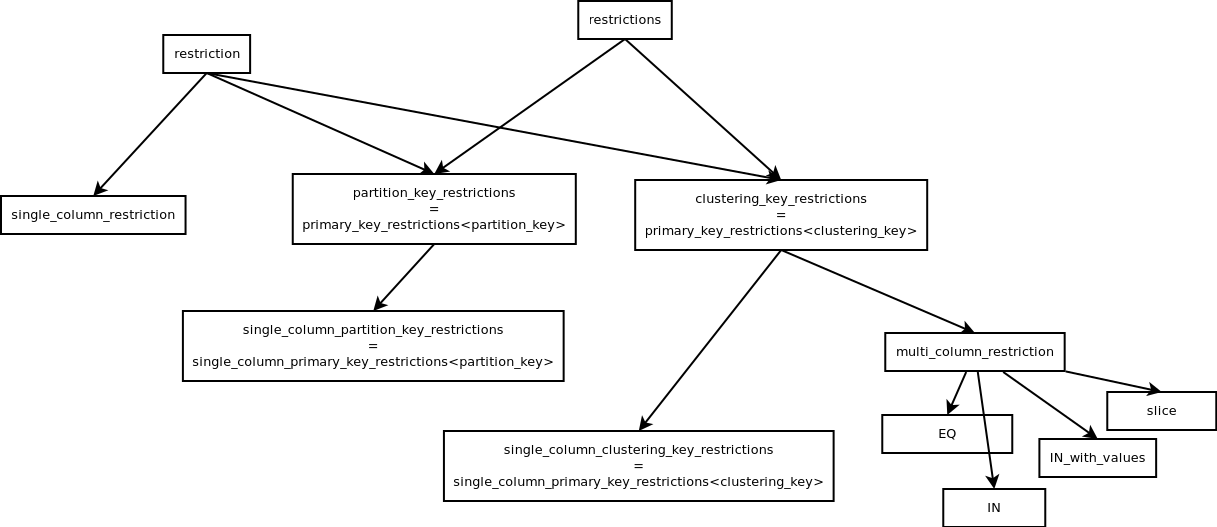
For now this is marked as a draft.
I just put all this together in a readable way and wanted to put it out for you to see.
I will have another look at the code and maybe do some improvements.
Closes#10910
* github.com:scylladb/scylla:
cql3: Remove _new from _new_partition_key_restrictions
cql3: Remove _partition_key_restrictions from statement_restrictions
cql3: Use expression for index restrictions
cql3: expr: Add contains_multi_column_restriction
cql3: Add expr::value_for
cql3: Use the new restrictions map in another place
cql3: use the new map in get_single_column_partition_key_restrictions
cql3: Keep single column restrictions map inside statement restrictions
cql3: Use expression instead of _partition_key_restrictions in the remaining code
cql3: Replace partition_key_restrictions->has_supporting_index()
cql3: Replace statement_restrictions->get_column_defs()
cql3: Replace partition_key_restrictions->needs_filtering()
cql3: Replace partition_key_restrictions->size()
cql3: Replace partition_key_restrictions->is_all_eq()
cql3: Replace parition_key_restriction->has_unrestricted_components()
cql3: Replace parition_key_restrictions->empty()
cql3: Keep restrictions as expressions inside statement_restrictions
cql3: Handle single value INs inside prepare_binary_operator
cql3: Add get_columns_in_commons
cql3: expr: Add is_empty_restriction
cql3: Replicate column sorting functionality using expressions
cql3: Remove single_column_restriction class
cql3: Replace uses of single_column_restriction with restriction
cql3: expr: Add get_the_only_column
cql3: expr: Add is_single_column_restriction
cql3: expr: Add for_each_expression
cql3: Remove some unsued methods
{kind=link}