After compiling to WASM, UDFs become much larger than the
source code. When they're included in test_wasm.py, it
becomes difficult to navigate in the file. Moving them
to another place does not make understanding the test
scripts harder, because the source code is still included.
This problem will become even more severe when testing
UDFs using WASI.
Signed-off-by: Wojciech Mitros <wojciech.mitros@scylladb.com>
Closes#10934
By default, Docker uses SELinux to prevent malicious code in the container
from "escaping" and touching files outside the container: The container
is only allowed to touch files with a special SELinux label, which the
outside files simply do not have. However, this means that if you want
to "mount" outside files into the container, Docker needs to add the
special label to them. This is why one needs to use the ":z" option
when mounting an outside file inside docker - it asks docker to "relabel"
the directory to be usable in Docker.
But this relabeling process is slow and potentially harmful if done to
large directories such as your home directory, where you may theoretically
have SELinux labels for other reasons. The relabling is also unnecessary -
we don't really need the SELinux protection in dbuild. Dbuild was meant
to provide a common toolchain - it was never meant to protect the build
host from a malicious build script.
The alternative we use in this patch is "--security-opt label=disable".
This allows the container to access any file in the host filesystem,
but as usual - only if it's explicitly "mounted" into the container.
All ":z" we added in the past can be removed.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10945
This PR removes some restrictions classes and replaces them with expression.
* `single_column_restriction` has been removed altogether.
* `partition_key_restrictions` field inside `statement_restrictions` has been replaced with `expression`
`clustering_key_restrictions` are not replaced yet, but this PR already has 30 commits so it's probably better to merge this before adding any more changes.
Luckily most of these commits are implementations of small helper functions.
`single_column_restriction` was pretty easy to remove. This class holds the `expression` that describes the restriction and `column_definition` of the restricted column.
It inherits from `restriction` - the base class of all restrictions.
I wasn't able to replace it with plain `expression` just yet, because a lot of times a `shared_ptr<single_column_restriction>` is being cast to `shared_ptr<restriction>`.
Instead I replaced all instances of `single_column_restriction` with `restriction`.
To decide if a `restriction` is a `single_column_restriction` we can use a helper method that works on expressions.
Same with acquiring the restricted `column_definition`.
This change has two advantages:
* One less restriction class -> moving towards 0
* Preparing towards one generic `restriction/expression` type and using functions to distinguish the type of expression that we're dealing with.
`partition_key_restrictions` is a class used to keep restrictions on the partition key inside `statement_restrictions`.
Removing it required two major steps.
First I had to implement taking all the binary operators and making sure that they are valid together.
Before the change this was the `merge_to` method. It ensures that for example there are no token and regular restrictions occurring at the same time.
This has been implemented as `statement_restrictions::add_restriction`.
It detects which case it's dealing with and mimics `merge_to` from the right restrictions class.
Then I implemented all methods of `partition_key_restrictions` but operating on plain `expressions`.
While doing that I was able to gradually shift the responsibility to the brand new functions.
Finally `partition_key_restrictions` wasn't used anywhere at all and I was able to remove it.
Here's the inheritance tree of all restriction classes for context:
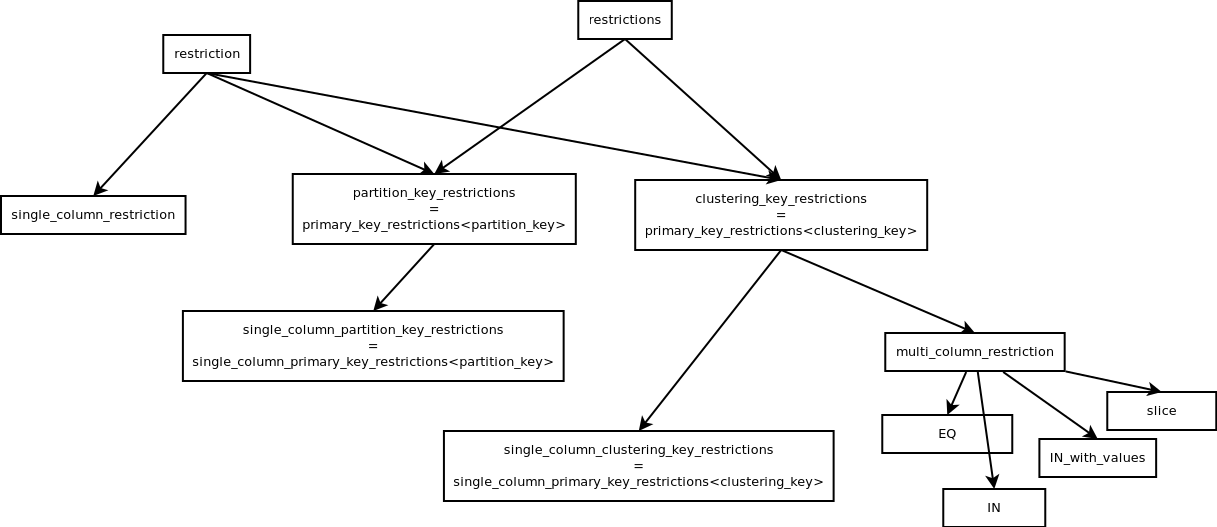
For now this is marked as a draft.
I just put all this together in a readable way and wanted to put it out for you to see.
I will have another look at the code and maybe do some improvements.
Closes#10910
* github.com:scylladb/scylla:
cql3: Remove _new from _new_partition_key_restrictions
cql3: Remove _partition_key_restrictions from statement_restrictions
cql3: Use expression for index restrictions
cql3: expr: Add contains_multi_column_restriction
cql3: Add expr::value_for
cql3: Use the new restrictions map in another place
cql3: use the new map in get_single_column_partition_key_restrictions
cql3: Keep single column restrictions map inside statement restrictions
cql3: Use expression instead of _partition_key_restrictions in the remaining code
cql3: Replace partition_key_restrictions->has_supporting_index()
cql3: Replace statement_restrictions->get_column_defs()
cql3: Replace partition_key_restrictions->needs_filtering()
cql3: Replace partition_key_restrictions->size()
cql3: Replace partition_key_restrictions->is_all_eq()
cql3: Replace parition_key_restriction->has_unrestricted_components()
cql3: Replace parition_key_restrictions->empty()
cql3: Keep restrictions as expressions inside statement_restrictions
cql3: Handle single value INs inside prepare_binary_operator
cql3: Add get_columns_in_commons
cql3: expr: Add is_empty_restriction
cql3: Replicate column sorting functionality using expressions
cql3: Remove single_column_restriction class
cql3: Replace uses of single_column_restriction with restriction
cql3: expr: Add get_the_only_column
cql3: expr: Add is_single_column_restriction
cql3: expr: Add for_each_expression
cql3: Remove some unsued methods
_new_partition_key_restrictions was a temporary name
used during the transition from restrictions to expressions.
Now that restrictions aren't used anymore it can be changed
back to _partition_key_restrictions.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Now that all functionality of partition_key_restrictions
has been implemented using expressions we can remove
this field from statement_restrictions.
_new_partition_key_restrictions will be used for
everything instead.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Restrictions that might be used by an index
are currently being kept as shared_ptr<restrictions>.
This stand in the way of replacing _parition_key_restrictions
with an expression as an expression can't be cast to
shared_ptr<restriction>.
Change shared_ptr<restriction> to expression everywhere
where necessary in index operations.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
value_for is a method from the restriction class
which finds the value for a given column.
Under the hood it makes use of possible_lhs_values.
It will be needed to implement some functionality
that was implemented using restrictions before.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Some parts of the code make use of a map keeping single column restrictions
for each partition key column. One of this places is inside do_filter,
so it could be a performance problem to create such a map from scratch
each time.
After adding all restrictions from the where clause the new
map is created and can be used for various purposes.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
There are still some places that use partition_key_restrictions
instead of _new_partition_key_restrictions in statement_restrictions.
Change them to use the new representation
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
To remove partition_key_restrictions all of its
methods have to be implemented using the new expression
representation.
The first to go is empty() as it's easy to implement.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Currently restrictions on partition, clustering and nonprimary columns
are kept inside special purpose restriction objects.
We want to remove all the restrictions classes so these objects
will be removed as well.
In the future each of these restrictions will be kept in
an expression.
Add new fields to statement_restrictions class which
will keep the right restrictions.
Currently restrictions from where clause are
added one by one using merge_to method of
the restrictions class.
This functionality will be replaced by statement_restrictions::add_restriction.
Functions for adding restrictions perform validation and
add new restrictions to the right field inside the class.
The checks that are done in add_*_restriction methods
correspond to the checks performed by merge_to
in respective restriction classes.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Currently expr::to_restriction is the only place where
prepare_binary_operator is called.
In case of a single-value IN restriction like:
mycol IN (1)
this expression is converted to
mycol = 1
by expr::to_restriction.
Once restriction is removed expr::to_restriction
will be removed as well so its functionality has to
be moved somewhere else.
Move handling single value INs inside
prepare_binary_operator.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Add a function that finds common columns
between two expressions.
It's used in error messages in the original
restrictions code so it must be included
in the new code as well for compatibility.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Restrictions code keeps restrictions for each column
in a map sorted by their position in the schema.
Then there are methods that allow to access
the restricted column in the correct order.
To replicate this in upcoming code
we need functions that implement this functionality.
The original comparator can be found in:
cql3/restrictions/single_column_restrictions.hh
For primary key columns this comparator compares their
positions in the schema.
For non-primary columns the position is assumed to
be clustering_key_size(), which seems pretty random.
To avoid passing the schema to the comparator
for nonprimary columns I just assume the
position is u32::max(). This seems to be
as good of a choice as clustering_key_size().
Orignally Cassandra used -1:
bc8a260471/src/java/org/apache/cassandra/config/ColumnDefinition.java (L79-L86)
We never end up comparing columns of different kind using this comparator anyway.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Now that all uses of this class have been
replaced by the generic restriction
the class is not used anywhere and can be removed.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
single_column_restriction is a class used to represent
restrictions in a single column.
The class is very simple - it's basically an expression
with some additional information.
As a step towards removing all restriction classes
all uses of this class are replaced by uses of
the generic restriction class.
All functionality of this class has been implemented
using free standing functions operating on expressions.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Add a function that gets the only column
from a single column restriction expression.
The code would be very similiar to
is_single_column_restriction, so a new
function is introducted to reduce duplication.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Add a function that checks whether an expression
contains restrictions on exactly one column.
This a "single_column_restriction"
in the same way that instances of
"class single_column_restriction" are.
It will be used later to distinguish cases
later once this class is removed
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
To call a UDF that is using WASI, we need to properly
configure the wasmtime instance that it will be called
on. The configuration was missing from udf_cache::load(),
so we add it here.
The free function does not return any value, so we should use
a calling method that does not expect any returns.
This patch adds such a method and uses it.
A test that did not pass without this fix and does pass after
is added.
Signed-off-by: Wojciech Mitros <wojciech.mitros@scylladb.com>
Closes#10935
cookie only when reading CQL tables' from Botond Dénes
Recently, we added full position-in-partition support to alternator's
paging cookie, so it can support stopping at arbitrary positions. This
support however is only really needed when tables have range tombstones
and alternator tables never have them. So to avoid having to make the
new fields in 'ExclusiveStartKey' reserved, we avoid filling these in
when reading an alternator table, as in this case it is safe to assume
the position is `after_key($clustring_key)`. We do include these new
members however when reading CQL tables through alternator. As this is
only supported for system tables, we can also be sure that the elaborate
names we used for these fields are enough to avoid naming clashes.
Fixes: https://github.com/scylladb/scylla/issues/10903Closes#10920
* github.com:scylladb/scylla:
alternator: use position-in-partition in paging cookie only when reading CQL tables
alternator: make is_alternator_keyspace() a standalone method
test/scylla-gdb tests Scylla's gdb debugging tools, and cannot work if
Scylla was compiled without debug information (i.e, the "dev" build mode).
In the past, test/scylla-gdb/run detected this case and printed a clear error:
Scylla executable was compiled without debugging information (-g)
so cannot be used to test gdb. Please set SCYLLA environment variable.
Unfortunately, since recently this detection fails, because even when
Scylla is compiled without debug information we link into it a library
(libwasmtime.a) which has *some* debug information. As a result, instead
of one clear error message, we get all scylla-gdb tests running -
and each of them failing separately. This is ugly and unhelpful.
Each of the tests fail because our "gdb" test fixture tries to load
scylla-gdb.py and fails when the symbols it needs (e.g., "size_t")
cannot be found. So in this patch, we check once for the existance
of this symbol - and if missing we exit pytest instead of failing each
individual test.
Moreover, if loading scylla-gdb.py fails for some other unexpected
reason, let's exit the test as well, instead of failing each individual
test.
Fixes#10863.
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10937
Closes#10930
* github.com:scylladb/scylla:
test: perf_row_cache_update: Flush std output after each line
test: perf_row_cache_update: Drain background cleaner before starting the test
test: perf_row_cache_update: Measure memtable filling time
test: perf_row_cache_update: Respect preemption when applying mutations
test: perf_row_cache_update: Drop unused pk variable
Recently, we added full position-in-partition support to alternator's
paging cookie, so it can support stopping at arbitrary positions. This
support however is only really needed when tables have range tombstones
and alternator tables never have them. So to avoid having to make the
new fields in 'ExclusiveStartKey' reserved, we avoid filling these in
when reading an alternator table, as in this case it is safe to assume
the position is `after_key($clustring_key)`. We do include these new
members however when reading CQL tables through alternator. As this is
only supported for system tables, we can also be sure that the elaborate
names we used for these fields are enough to avoid naming clashes.
The condition in the code implementing this is actually even more
general: it only includes the region/weight members when the position
differs from that of a normal alternator one.
for_each_expression is a function that
can be used to iterate over all expressions
inside an expression recursively and perform
some operation on each of them.
For example:
for_each_expression<column_vaue>(e, [](const column_value& cval) {std::cout << cval << '\n';});
Will print all column values in an expression
It's awkward to do this using recurse_until or find_in_expression
because these functions are meant for slightly different purposes.
Having a dedicated function for this purpose will make the code
cleaner and easier to understand.
Signed-off-by: Jan Ciolek <jan.ciolek@scylladb.com>
Before this patch, the test cql-pytest/test_tools.py left behind
a temporary file in /tmp. It used pytest's "tmp_path_factory" feature,
but it doesn't remove temporary files it creates.
This patch removes the temporary file when the fixture using it ends,
but moreover, it puts the temporary file not in /tmp but rather next
to Scylla's data directory. That directory will be eventually removed
entirely, so even if we accidentally leave a file there, it will
eventually be deleted.
Fixes#10924
Signed-off-by: Nadav Har'El <nyh@scylladb.com>
Closes#10929
There is a bug introduced in e74c3c8 (4.6.0) which makes memtable
reader skip one a range tombstone for a certain pattern of deletions
and under certain sequence of events.
_rt_stream contains the result of deoverlapping range tombstones which
had the same position, which were sipped from all the versions. The
result of deoverlapping may produce a range tombstone which starts
later, at the same position as a more recent tombstone which has not
been sipped from the partition version yet. If we consume the old
range tombstone from _rt_stream and then refresh the iterators, the
refresh will skip over the newer tombstone.
The fix is to drop the logic which drains _rt_stream so that
_rt_stream is always merged with partition versions.
For the problem to trigger, there have to be multiple MVCC versions
(at least 2) which contain deletions of the following form:
[a, c] @ t0
[a, b) @ t1, [b, d] @ t2
c > b
The proper sequence for such versions is (assuming d > c):
[a, b) @ t1,
[b, d] @ t2
Due to the bug, the reader will produce:
[a, b) @ t1,
[b, c] @ t0
The reader also needs to be preempted right before processing [b, d] @
t2 and iterators need to get invalidated so that
lsa_partition_reader::do_refresh_state() is called and it skips over
[b, d] @ t2. Otherwise, the reader will emit [b, d] @ t2 later. If it
does emit the proper range tombstone, it's possible that it will violate
fragment order in the stream if _rt_stream accumulated remainders
(possible with 3 MVCC versions).
The problem goes away once MVCC versions merge.
Fixes#10913Fixes#10830Closes#10914
The commits here were extracted from PR https://github.com/scylladb/scylla/pull/10835 which implements upgrade procedure for Raft group 0.
They are mostly refactors which don't affect the behavior of the system, except one: the commit 4d439a16b3 causes all schema changes to be bounced to shard 0. Previously, they would only be bounced when the local Raft feature was enabled. I do that because:
1. eventually, we want this to be the default behavior
2. in the upgrade PR I remove the `is_raft_enabled()` function - the function was basically created with the mindset "Raft is either enabled or not" - which was right when we didn't support upgrade, but will be incorrect when we introduce intermediate states (when we upgrade from non-raft-based to raft-based operations); the upgrade PR introduces another mechanism to dispatch based on the upgrade state, but for the case of bouncing to shard 0, dispatching is simply not necessary.
Closes#10864
* github.com:scylladb/scylla:
service/raft: raft_group_registry: add assertions when fetching servers for groups
service/raft: raft_group_registry: remove `_raft_support_listener`
service/raft: raft_group0: log adding/removing servers to/from group 0 RPC map
service/raft: raft_group0: move group 0 RPC handlers from `storage_service`
service/raft: messaging: extract raft_addr/inet_addr conversion functions
service: storage_service: initialize `raft_group0` in `main` and pass a reference to `join_cluster`
treewide: remove unnecessary `migration_manager::is_raft_enabled()` calls
test/boost: memtable_test: perform schema operations on shard 0
test/boost: cdc_test: remove test_cdc_across_shards
message: rename `send_message_abortable` to `send_message_cancellable`
message: change parameter order in `send_message_oneway_timeout`
There effectively are several test-cases in this test, each calls the
scylla_sstable() to prepare, thus each creates a type in the same scylla
instance. The 2nd attempt ends up with the "already exists" error:
E cassandra.InvalidRequest: Error from server: code=2200 [Invalid query] message="A user type of name cql_test_1656396925652.type1 already exists"
tests: unit(dev)
https://jenkins.scylladb.com/job/releng/job/Scylla-CI/1075/fixes: #10872
Signed-off-by: Pavel Emelyanov <xemul@scylladb.com>
Message-Id: <20220628081459.12791-1-xemul@scylladb.com>
A number of improvements in test.py as requested by maintainers:
* don't capture pytest output
* stick to the specific server in control connections
* support --log-level option and pass it to logging module
* when checking if CQL is up, ignore timeout errors
* no longer force schema migration when starting the server
* use test uname, not id, in log output
* improve logging of ScyllaServer
* log what cluster is used for a test
* extend xml output with logs
On the same token, remove mypy warnings and make linter pass on test.py, as well as add some type checking.
Fixes#10871Fixes#10785Closes#10902
* github.com:scylladb/scylla:
test.py: extend xml output with logs
test.py: log what cluster is used for a test
test.py: improve logging of ScyllaServer
test.py: use test uname, not id, in log output
test.py: support --log-level option and pass it to logging module
test.py: make ScyllaServer more reliable and fast
test.py: don't capture pytest output
test.py: add type annotations
test.py: convert log_filename to pathlib
test.py: please linter
test.py: remove mypy warnings
Currently, for users who have permissions_cache configs set to very high
values (and thus can't wait for the configured times to pass) having to restart
the service every time they make a change related to permissions or
prepared_statements cache (e.g. Adding a user and changing their permissions)
can become pretty annoying.
This patch series make permissions_validity_in_ms, permissions_update_interval_in_ms
and permissions_cache_max_entries live updateable so that restarting the
service is not necessary anymore for these cases.
It also adds an API for flushing the cache to make it easier for users who
don't want to modify their permissions_cache config.
branch: https://github.com/igorribeiroduarte/scylla/tree/make_permissions_cache_live_updateable
CI: https://jenkins.scylladb.com/job/releng/job/Scylla-CI/1005/
dtests: https://github.com/igorribeiroduarte/scylla-dtest/tree/test_permissions_cache
* https://github.com/igorribeiroduarte/scylla/make_permissions_cache_live_updateable:
loading_cache_test: Test loading_cache::reset and loading_cache::update_config
api: Add API for resetting authorization cache
authorization_cache: Make permissions cache and authorized prepared statements cache live updateable
auth_prep_statements_cache: Make aut_prep_statements_cache accept a config struct
utils/loading_cache.hh: Add update_config method
utils/loading_cache.hh: Rename permissions_cache_config to loading_cache_config and move it to loading_cache.hh
utils/loading_cache.hh: Add reset method
{kind=link}